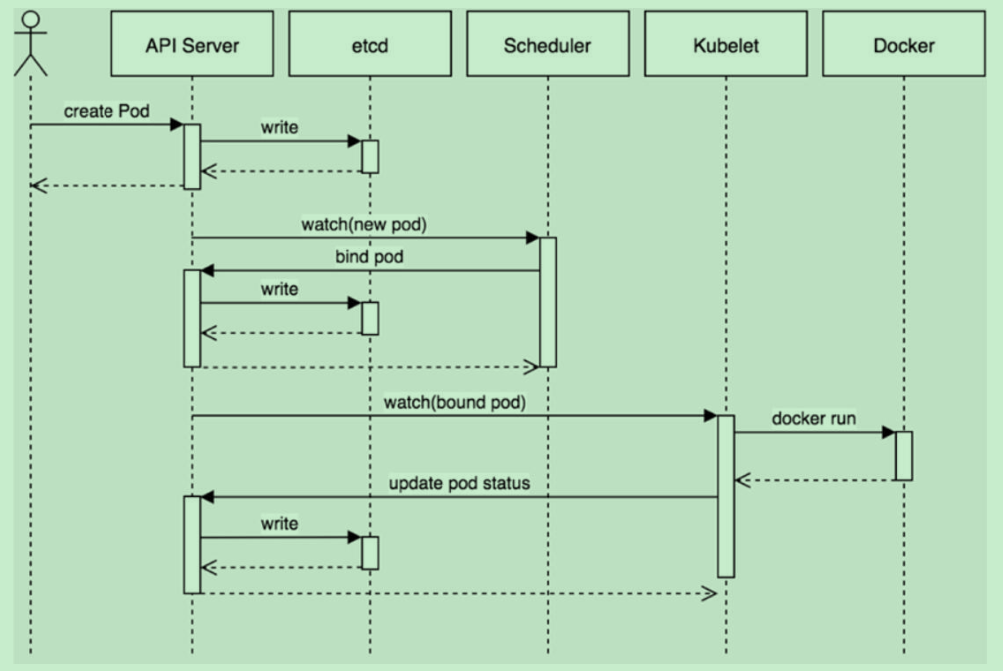
5.1 创建一个Pod的工作流程
Kubernetes基于list-watch机制的控制器架构,实现组件间交互的解耦。
5.2 Pod中影响调度的主要属性

5.3 资源限制对Pod调度的影响

容器资源限制:
- resources.limits.cpu
- resources.limits.memory
容器使用的最小资源需求,作为容器调度时资源分配的依据:
- resources.requests.cpu
- resources.requests.memory
5.4 nodeSelector & nodeAffinity
nodeSelector
nodeSelector:用于将Pod调度到匹配Label的Node上,如果没有匹配的标签会调度失败。
作用:
- 完全匹配节点标签
- 固定Pod到特定节点
给节点打标签:kubectl label nodes [node] key=value
例如:kubectl label nodes k8s-node1 disktype=ssd
查看节点标签:
<font style="background-color:#FADB14;"> kubectl label nodes k8s-node1 --list</font>
去掉节点上标签:
**<font style="background-color:#FADB14;">kubeclt label nodes [node] key-</font>**
注:node节点的‘去’操作大多数都是用‘-’操作
Pod调度到匹配的标签的Node上:

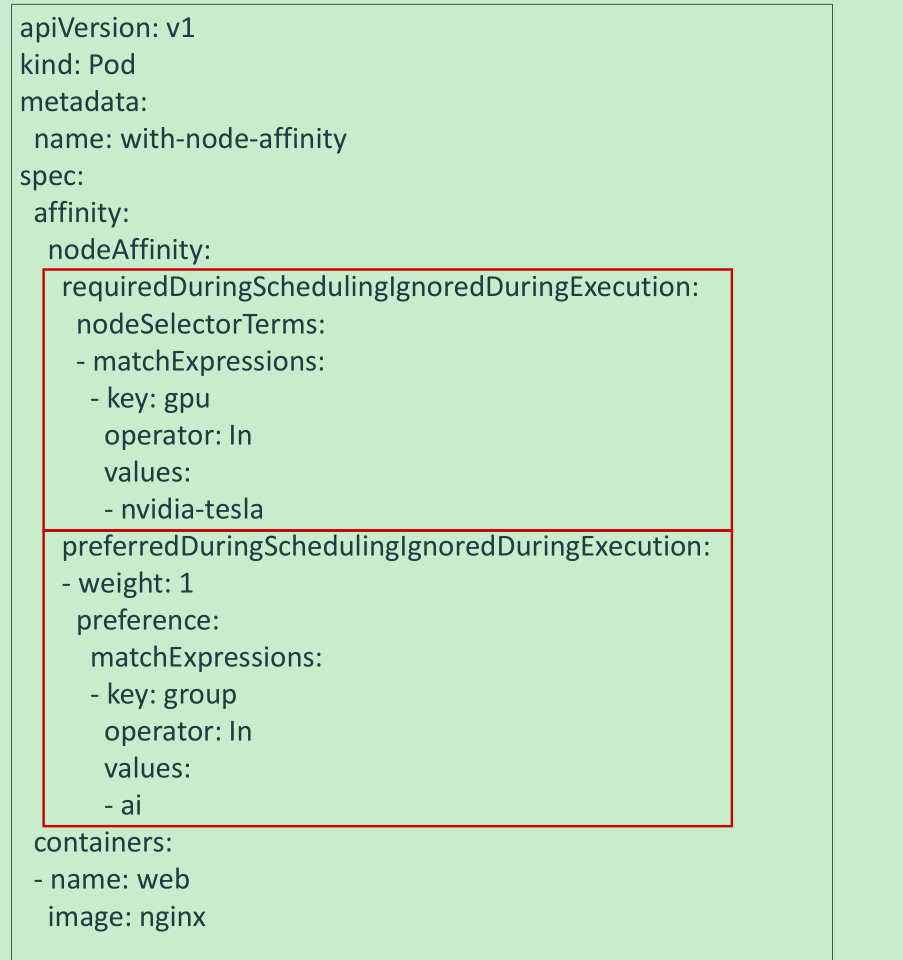
nodeAffinity
nodeAffinity:节点亲和类似于nodeSelector,可以根据节点上的标签来约束Pod可以调度到哪些节点。
相比nodeSelector:
- 匹配有更多的逻辑组合,不只是字符串的完全相等
- 调度分为软策略和硬策略,而不是硬性要求
- 硬(required):必须满足
- 软(preferred):尝试满足,但不保证
- In:label的值在某个列表中
- NotIn:label的值不在某个列表中
- Gt:label的值大于某个值
- Lt:label的值小于某个值
- Exists:某个label存在
- DoesNotExist:某个label不存在
Pod和Node进行匹配:
5.5 Taint(污点)
Taints:避免Pod调度到特定Node上
应用场景:
- 专用节点,例如配备了特殊硬件的节点
- 基于Taint的驱逐
设置污点:kubectl taint node [node] key=value:[effect]
其中[effect] 可取值:
- NoSchedule :一定不能被调度。
- PreferNoSchedule:尽量不要调度。
- NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。
去掉污点:kubectl taint node [node] key:[effect]-
5.5.1 k8s命令对node调度 cordon,drain,delete 区别
https://blog.csdn.net/erhaiou2008/article/details/104986006
此三个命令都会使node停止被调度,后期创建的pod不会继续被调度到该节点上,但操作的暴力程度不一cordon < drain < delete
只需要不可调度使用cordon 节点下线维护使用:drain (谨慎操作) 直接暴力删除节点:delete (谨慎操作)
- cordon停止调度
:::info
影响最小,只会将node调为SchedulingDisabled之后再发创建pod,不会被调度到该节点
旧有的pod不会受到影响,仍正常对外提供服务
恢复调度
kubectl uncordon node_name:::
- drain驱逐节点
:::info
首先,驱逐node上的pod,其他节点重新创建接着,将节点调为 SchedulingDisabled
恢复调度
kubectl uncordon node_name
:::
1) 封锁节点,先让节点变的不可调度
kubectl cordon <node name>2) 对节点执行维护操作之前(例如:内核升级,硬件维护等),您可以使用 kubectl drain 安全驱逐节点上面所有的 pod。
安全驱逐的方式将会允许 pod 里面的容器遵循指定的 PodDisruptionBudgets 执行优雅的中止。
注: 默认情况下,kubectl drain 会忽略那些不能杀死的系统类型的 pod,如果您想了解更多详细的内容,请参考kubectl drain
kubectl drain 返回成功表明所有的 pod (除了前面排除的那些)已经被安全驱逐(遵循期望优雅的中止期,并且没有违反任何应用程序级别的中断预算)。
然后,通过对物理机断电或者在云平台上删除节点所在的虚拟机,都能安全的将节点移除。
drain的参数
—force
当一些pod不是经 ReplicationController, ReplicaSet, Job, DaemonSet 或者 StatefulSet 管理的时候
就需要用—force来强制执行 (例如:kube-proxy)
—ignore-daemonsets
无视DaemonSet管理下的Pod
—delete-local-data
如果有mount local volumn的pod,会强制杀掉该pod并把料清除掉
另外如果跟本身的配置讯息有冲突时,drain就不会执行
- delete
:::info
首先,驱逐node上的pod,其他节点重新创建然后,从master节点删除该node,master对其不可见,失去对其控制,master不可对其恢复
恢复调度,需进入node节点,重启kubelet
基于node的自注册功能,节点重新恢复使用
systemctl restart kubelet
delete是一个比较粗暴的命令,它会将被删node上的pod直接驱逐,由其他node创建(针对replicaset),然后将被删节点从master管理范围内移除,master对其失去管理控制,若想使node重归麾下,必须在node节点重启kubelet
:::
5.5.2 Node节点平滑维护
https://cloud.tencent.com/developer/article/1796315
通常情况下,如果要对K8S集群中的一台Node节点进行平滑维护,如升级或调整配置。正确的操作:- cordon临时从K8S集群隔离出来,标识为SchedulingDisabled不可调度状态。
- drain排干该节点上的pod资源到其他node节点上。
- 对该节点展开平滑维护操作,如升级或调整配置。
- uncordon恢复,重新回到K8S集群,变回可调度状态。
- 要驱逐的pod副本数量必须大于1
- 要配置”反亲和策略”,确保被驱逐的pod被调度到不同的Node节点上
- deployment采用滚动更新,设置maxUnavailable为0,maxSurge为1
5.6 Tolerations(污点容忍)
Tolerations:允许Pod调度到持有Taints的Node上

- 这里的key就是污点的key
- effect对应的是污点的值
5.7 nodeName
nodeName:指定节点名称,用于将Pod调度到指定的Node上,不经过调度器

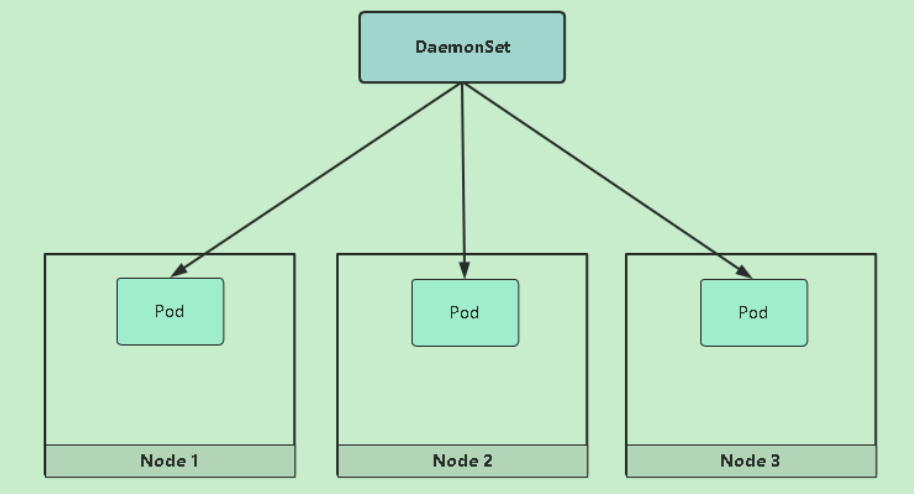
5.8 DaemonSet
DaemonSet功能:
- 在每一个Node上运行一个Pod
- 新加入的Node也同样会自动运行一个Pod
应用场景:网络插件、监控Agent、日志Agent
示例:部署一个日志采集程序

5.9 调度失败原因分析
查看调度结果:kubectl get pod <NAME> -o wide
查看调度失败原因:kubectl describe pod <NAME>
- 节点CPU/内存不足
- 有污点,没容忍
- 没有匹配到节点标签

若有收获,就点个赞吧
0 人点赞
