10.1 etcd备份恢复
k8s使用etcd数据库实时存储集群中的数据,安全起见,一定要备份
1、kubeadm部署方式
备份:
yum -y install etcdETCDCTL_API=3 etcdctl \snapshot save snap.db \--endpoints=https://127.0.0.1:2379 \--cacert=/etc/kubernetes/pki/etcd/ca.crt \--cert=/etc/kubernetes/pki/etcd/server.crt \--key=/etc/kubernetes/pki/etcd/server.key
恢复
- 1、先暂停kube-apiserver和etcd容器
- 2、恢复
- 3、启动kube-apiserver和etcd容器
1、先暂停kube-apiserver和etcd容器mv /etc/kubernetes/manifests /etc/kubernetes/manifests.bakmv /var/lib/etcd/ /var/lib/etcd.bak2、恢复ETCDCTL_API=3 etcdctl \snapshot restore snap.db \--data-dir=/var/lib/etcd3、启动kube-apiserver和etcd容器mv /etc/kubernetes/manifests.bak /etc/kubernetes/manifests
2、二进制部署方式
备份
ETCDCTL_API=3 etcdctl \snapshot save snap.db \--endpoints=https://192.168.31.71:2379 \--cacert=/opt/etcd/ssl/ca.pem \--cert=/opt/etcd/ssl/server.pem \--key=/opt/etcd/ssl/server-key.pem
恢复
- 1、先暂停kube-apiserver和etcd
- 2、在每个节点上恢复
- 3、启动kube-apiserver和etcd
1、先暂停kube-apiserver和etcdsystemctl stop kube-apiserversystemctl stop etcdmv /var/lib/etcd/default.etcd /var/lib/etcd/default.etcd.bak2、在每个节点上恢复ETCDCTL_API=3 etcdctl snapshot restore snap.db \--name etcd-1 \--initial-cluster="etcd-1=https://192.168.31.71:2380,etcd-2=https://192.168.31.72:2380,etcd-3=https://192.168.31.73:2380" \--initial-cluster-token=etcd-cluster \--initial-advertise-peer-urls=https://192.168.31.71:2380 \--data-dir=/var/lib/etcd/default.etcd3、启动kube-apiserver和etcdsystemctl start kube-apiserversystemctl start etcd
10.2 kubeadm进行k8s集群版本升级
Kubernetes每隔3个月发布一个小版本。
升级策略
- 始终保持最新
- 每半年升级一次,这样会落后社区1~2个小版本
- 一年升级一次,或者更长,落后版本太多
升级流程
注意事项:
- 升级前必须备份所有组件及数据,例如etcd
- 千万不能跨多个小节点升级,例如从1.16升级到1.19
版本升级
升级管理节点
- 查找最新版本号
- 升级kubeadm
- 驱逐node上的pod,且不可调度
- 检查集群是否可以升级,并获取可以升级的版本
- 执行升级
- 取消不可调度
- 升级kubectl和kubelet
- 重启kubelet
1、查找最新版本号yum list --showduplicates kubeadm --disableexcludes=kubernetes2、升级kubeadmyum install -y kubeadm-1.22.1 --disableexcludes=kubernetes3、驱逐node上的pod,且不可调度kubectl drain k8s-master --ignore-daemonsets4、检查集群是否可以升级,并获取可以升级的版本kubeadm upgrade plan5、执行升级kubeadm upgrade apply v1.22.16、取消不可调度kubectl uncordon k8s-master7、升级kubelet和kubectlyum install -y kubelet-1.22.1 kubectl-1.22.1 --disableexcludes=kubernetes8、重启kubeletsystemctl daemon-reloadsystemctl restart kubelet
升级工作节点
1、升级kubeadmyum install -y kubeadm-1.22.1 --disableexcludes=kubernetes2、驱逐node上的pod,且不可调度kubectl drain k8s-node1 --ignore-daemonsets3、升级kubelet配置kubeadm upgrade node4、升级kubelet和kubectlyum install -y kubelet-1.22.1 kubectl-1.22.1 --disableexcludes=kubernetes5、重启kubeletsystemctl daemon-reloadsystemctl restart kubelet6、取消不可调度,节点重新上线kubectl uncordon k8s-node1
<font style="color:rgb(204, 204, 204);background-color:rgb(80, 85, 107);">kubectl drain node02 </font><font style="color:rgb(103, 205, 204);background-color:rgb(80, 85, 107);">--</font><font style="color:rgb(204, 153, 205);background-color:rgb(80, 85, 107);">delete</font><font style="color:rgb(103, 205, 204);background-color:rgb(80, 85, 107);">-</font><font style="color:rgb(204, 204, 204);background-color:rgb(80, 85, 107);">local</font><font style="color:rgb(103, 205, 204);background-color:rgb(80, 85, 107);">-</font><font style="color:rgb(204, 204, 204);background-color:rgb(80, 85, 107);">data </font><font style="color:rgb(103, 205, 204);background-color:rgb(80, 85, 107);">--</font><font style="color:rgb(204, 204, 204);background-color:rgb(80, 85, 107);">ignore</font><font style="color:rgb(103, 205, 204);background-color:rgb(80, 85, 107);">-</font><font style="color:rgb(204, 204, 204);background-color:rgb(80, 85, 107);">daemonsets </font><font style="color:rgb(103, 205, 204);background-color:rgb(80, 85, 107);">--</font><font style="color:rgb(204, 204, 204);background-color:rgb(80, 85, 107);">force</font>参数说明:
- —delete-local-data 即使pod使用了emptyDir也删除
- —ignore-daemonsets 忽略deamonset控制器的pod,如果不忽略,deamonset控制器控制的pod被删除后可能马上又在此节点上启动起来,会成为死循环;
- --force 不加force参数只会删除该NODE上由ReplicationController, ReplicaSet, DaemonSet,StatefulSet or Job创建的Pod,加了后还会删除’裸奔的pod’(没有绑定到任何replication controller)
CoreDNS镜像拉取失败
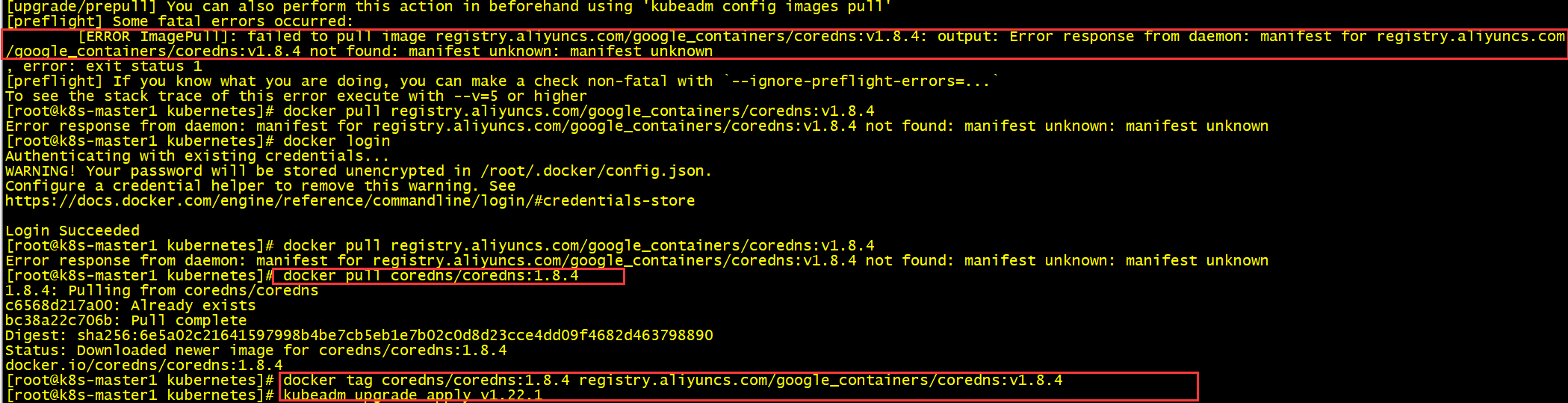
docker pull coredns/coredns:1.8.4docker tag coredns/coredns:1.8.4 registry.aliyuncs.com/google_containers/coredns:v1.8.4
10.3 k8s集群节点正确下线流程
如果你想维护某个节点或者删除节点,正确流程如下:
1、获取节点列表
kubectl get node
2、驱逐节点上的Pod并设置不可调度(cordon)
kubectl drain
3、设置可调度或者移除节点
kubectl uncordon
kubectl delete node
10.4 k8s故障排查
应用部署
kubectl describe TYPE/NAMEkubectl logs TYPE/NAME [-c CONTAINER]kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
组件不能正常工作
需要先区分部署方式:
1、kubeadm
除kubelet外,其他组件均采用静态Pod启动
2、二进制
所有组件均采用systemd管理
常见问题:
- 网络不通
- 启动失败,一般配置文件或者依赖服务
- 平台不兼容

若有收获,就点个赞吧
0 人点赞
