1、PromQL基本使用
1.1 PromQL介绍
PromQL(Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力
非常丰富,支持条件查询、操作符,并且内建了大量内置函数,供我们针对监控数据的各种维度进行查
询。
1.2 瞬时查询与范围查询
参考文档:https://prometheus.io/docs/prometheus/latest/querying/examples/
目标实例状态:(获取所有监控实例是否正常,1表示正常)up查询node的CPU利用率,指标最新样本(称为瞬时向量):node_cpu_seconds_total可以通过附加一组标签来进一步过滤这些时间序列:node_cpu_seconds_total{job="Linux Server"}查询指标近5分钟内样本(称为范围向量,时间单位 s,m,h,d,w,y):node_cpu_seconds_total{job="Linux Server"}[5m]node_cpu_seconds_total{job="Linux Server"}[1h]
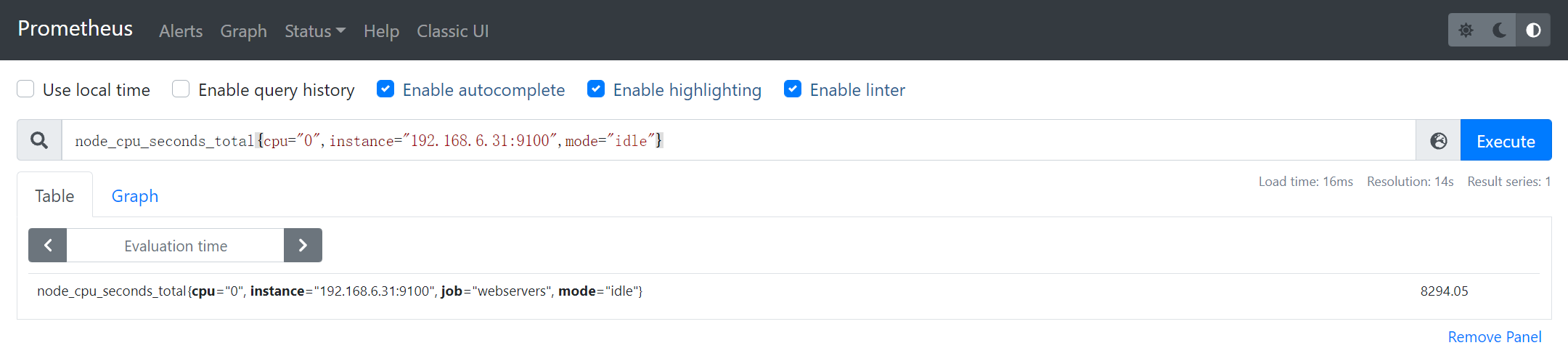
实例1:获取192.168.6.31:9100实例第0核CPU上**空闲态**CPU利用率
node_cpu_seconds_total{cpu="0",instance="192.168.6.31:9100",mode="idle"}
- mode 指定CPU状态(具体含义top命令第三行:Linux监控命令)
1.3 常见的操作符与函数
1.3.1 常用操作符
参考文档:https://prometheus.io/docs/prometheus/latest/querying/operators/

实例2:获取192.168.6.31:9100实例第0核CPU上**非空闲态**CPU利用率
node_cpu_seconds_total{cpu="0",instance="192.168.6.31:9100",mode!="idle"}
实例3:求192.168.6.31:9100实例5分钟内CPU上利用率
avg(irate(node_cpu_seconds_total{instance="192.168.6.31:9100"}[5m]))

1.3.2 函数
参考文档:https://prometheus.io/docs/querying/functions/
函数:• irate():计算指标在一定时间间隔内的变化速率示例:irate(node_cpu_seconds_total{job="Linux Server",mode="system"}[5m])
2、监控指标标签管理
2.1 标签的作用
标签作用:Prometheus中存储的数据为时间序列,是由Metric的名字和一系列的标签(键值对)唯一标识的,
不同的标签代表不同的时间序列,即通过指定标签查询指定数据。
2.2 Metadata标签
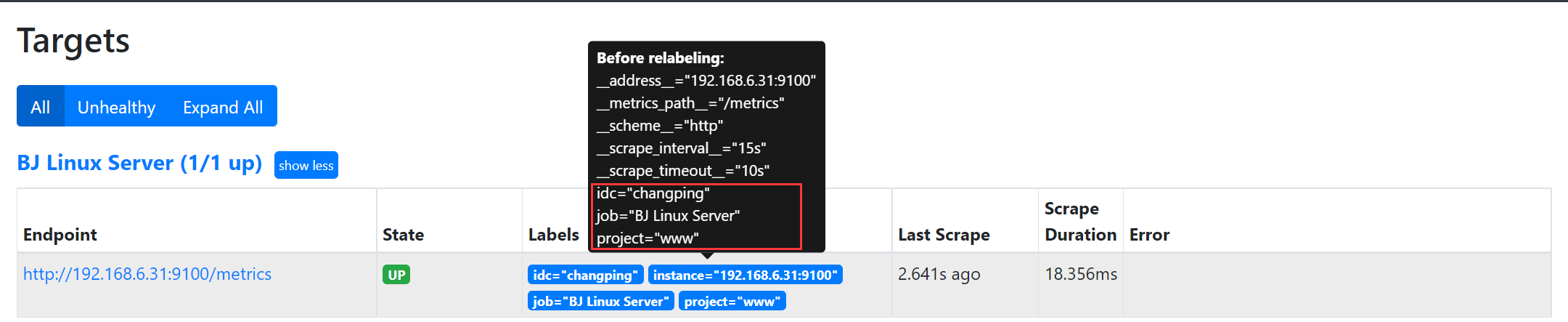
在Prometheus所有的Target实例中,都包含一些默认的Metadata标签信息。可以通过Prometheus UI的
Targets页面中查看这些实例的Metadata标签的内容:
• address:当前Target实例的访问地址
• scheme:采集目标服务访问地址的HTTP Scheme,HTTP或者HTTPS
• metrics_path:采集目标服务访问地址的访问路径
上面这些标签将会告诉Prometheus如何从该Target实例中获取监控数据。除了这些默认的标签以外,我们
还可以为Target添加自定义的标签。

2.3 自定义标签
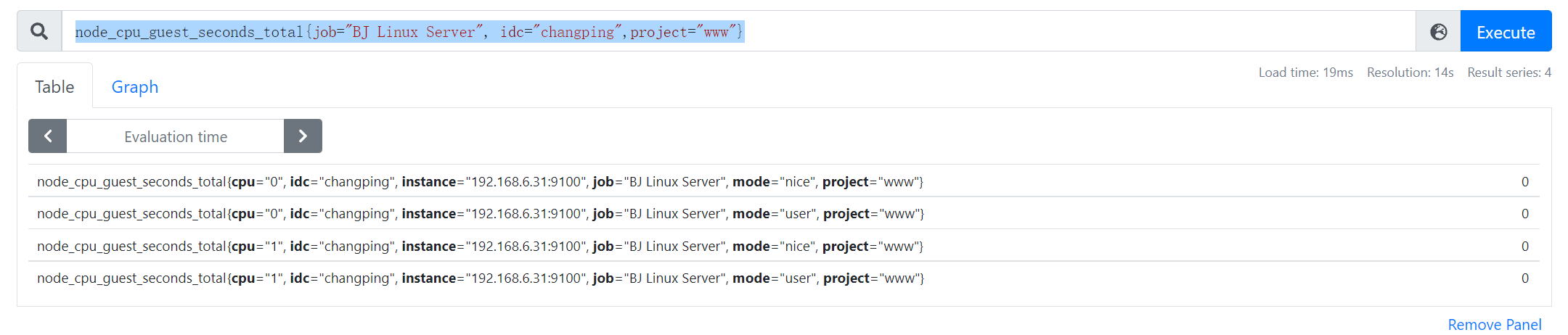
- job_name: 'BJ Linux Server'static_configs:- targets: ['192.168.6.31:9100']labels: # 自定义标签idc: changpingproject: www- job_name: 'SH Linux Server'static_configs:- targets: ['192.168.6.32:9100']labels: # 自定义标签idc: sssproject: blog
查询北京昌平区机房中www项目组的主机的CPU
node_cpu_guest_seconds_total{job="BJ Linux Server", idc="changping",project="www"}
2.4 重新标记标签
重新标记目的:为了更好的标识监控指标。
在两个阶段可以重新标记:
• relabel_configs :在采集之前
• metric_relabel_configs:在存储之前
准备抓取指标数据时,可以使用relabel_configs添加一些标签、也可以只采集特定目标或过滤目标。
已经抓取到指标数据时,可以使用metric_relabel_configs做最后的重新标记和过滤。

重新标记标签一般用途:
• 动态生成新标签
• 过滤采集的Target
• 删除不需要或者敏感标签
• 添加新标签
action:重新标记标签动作
• replace:默认,通过regex匹配source_label的值,使用replacement来引用表达式匹配的分组,分组使用$1,$2…引用
• keep:删除regex与连接不匹配的目标 source_labels
• drop:删除regex与连接匹配的目标 source_labels
• labeldrop:删除regex匹配的标签
• labelkeep:删除regex不匹配的标签
• labelmap:匹配regex所有标签名称,并将捕获的内容分组,用第一个分组内容作为新的标签名
- 注:source_labels尽量使用Prometheus内置标签(内置标签是在存储之前就有的)
2.4.1 重命名标签
场景1:动态生成添加标签(对已有的标签重新标记)
- job_name: 'Linux Server'static_configs:- targets: ['192.168.6.31:9100']relabel_configs: # 采集之前,存储之前则使用 metric_relabel_configs- action: replace # 指定动作,默认是replacesource_labels: ["__address__"] # 基于那个标签进行正则匹配regex: (.*):([0-9]+) # 正则匹配标签值,( )分组replacement: $1 # 引用分组匹配的内容,$1匹配的是(.*),$2匹配的是([0-9]+)也就是端口target_label: "ip"
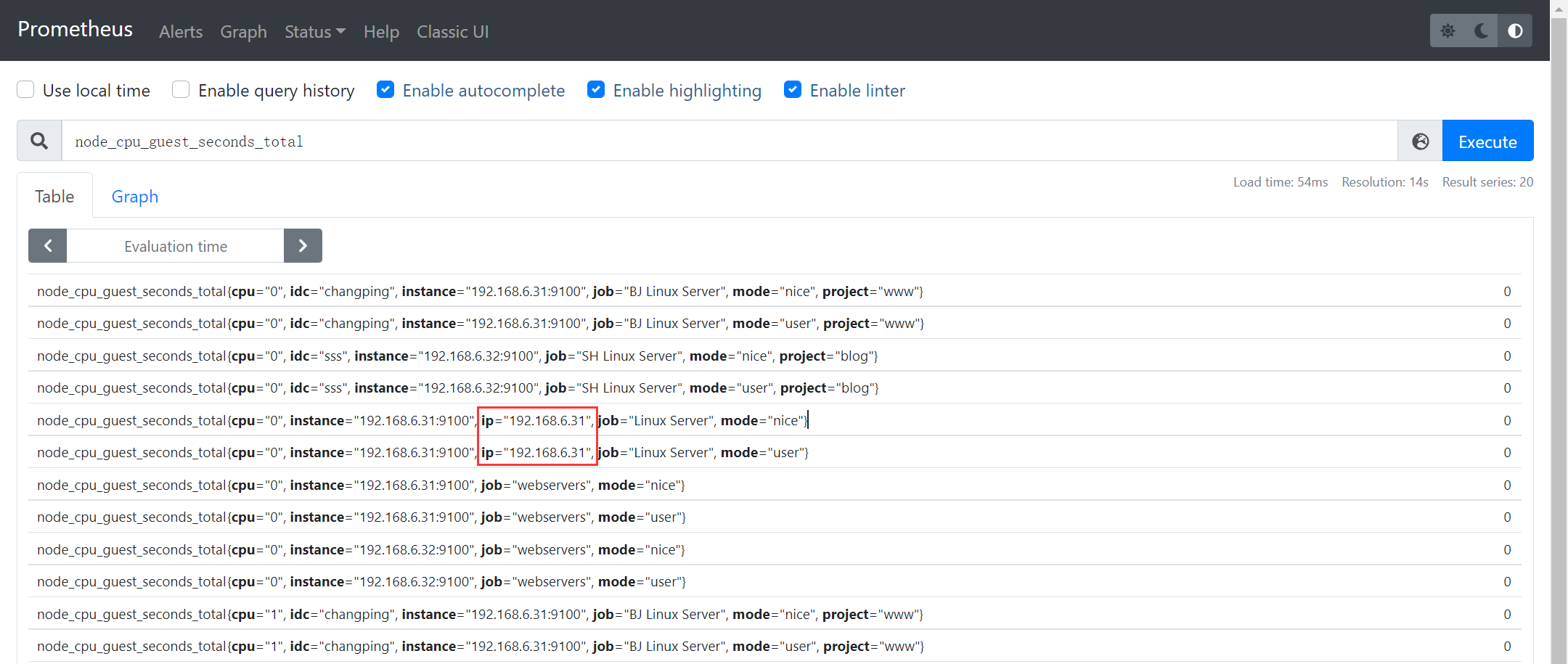
2.4.2 过滤Target
场景2:选择采集的目标
- job_name: 'Linux Server'static_configs:- targets: ['192.168.6.31:9100','192.168.6.32:9100']relabel_configs:- action: drop # 不采集正则匹配的服务数据,keep则是只采集匹配的source_labels: ["__address__"]regex: "192.168.6.32:9100"

- replacement这里也可以直接指定一个名称,自定义标签
- 给指定标签赋予绝对值
metric_relabel_configs:- action: replacereplacement: "aaaa"target_label: "instance"

2.4.3 删除标签
场景3:删除不需要或者敏感的标签,禁止某些标签入库
- job_name: 'Linux Server'static_configs:- targets: ['192.168.6.31:9100','192.168.6.32:9100']metric_relabel_configs:- action: labeldropregex: "job"
入库之前可以看到
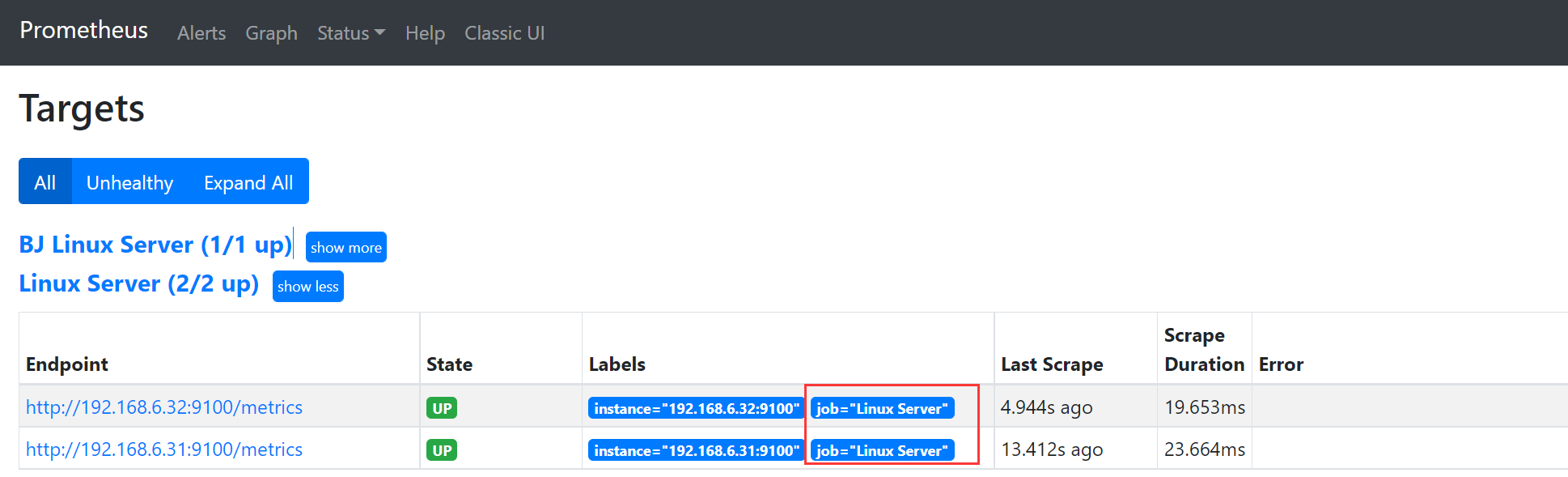
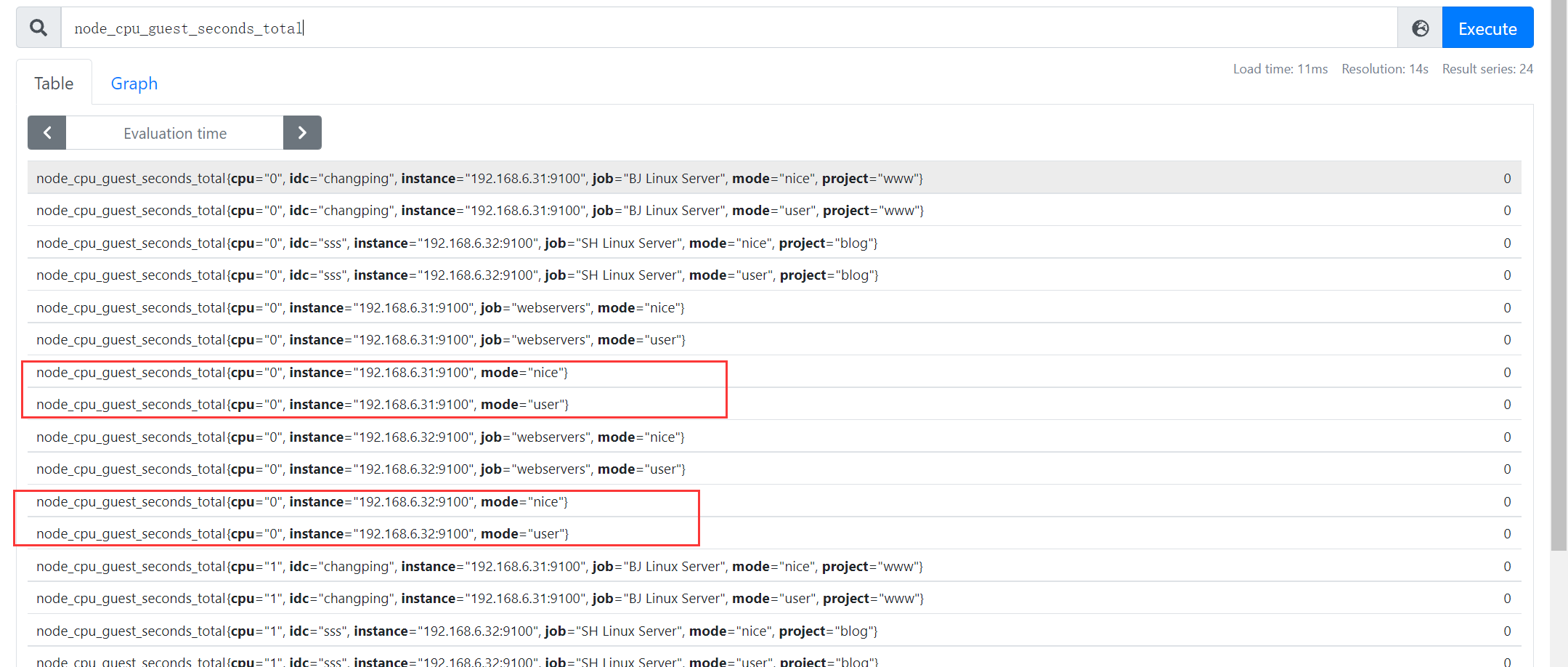
执行PromQL,查看入库之后:已经没有了job标签
3、告警监控
3.1 部署Alertmanager
安装包下载
地址1:https://prometheus.io/download/
地址2:https://github.com/prometheus/alertmanager/releases
使用步骤:
部署Alertmanager
配置告警接收人
配置Prometheus与Alertmanager通信
在Prometheus中创建告警规则
[Unit]Description=alertmanager[Service]ExecStart=/opt/monitor/alertmanager/alertmanager --config.file=/opt/monitor/alertmanager/alertmanager.ymlExecReload=/bin/kill -HUP $MAINPIDKillMode=processRestart=on-failure[Install]WantedBy=multi-user.target
ss -tnlp | grep alert
3.2 配置Prometheus与Alertmanager通信
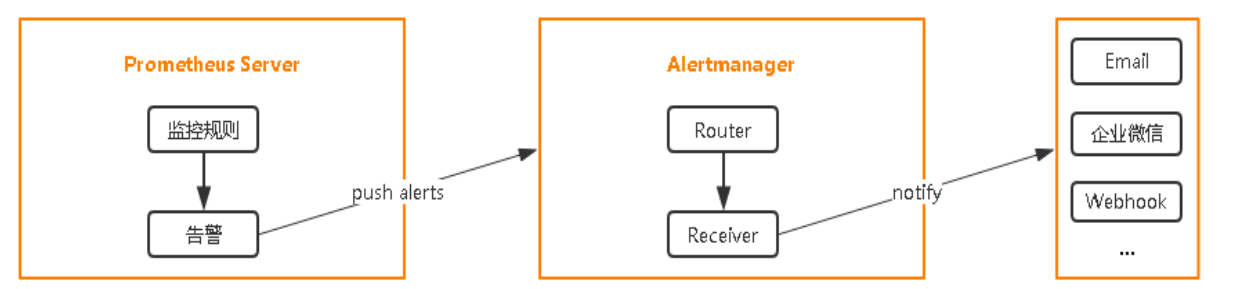
vi prometheus.yml...# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets:- 192.168.6.31:9093 # 配置发送告警事件接口rule_files:- "rules/*.yml"...
global:resolve_timeout: 5m# 邮箱服务器 (默认使用的webhook发送告警信息)smtp_smarthost: 'smtp.163.com:25'smtp_from: 'zsg1690014753@163.com'smtp_auth_username: 'zsg1690014753@163.com'smtp_auth_password: 'UNAOCOIAGNKDFMYH' # 网易邮箱安全码(启用POP3/SMTP服务,新增授权验证码),只显示一次要记号smtp_require_tls: false# 配置路由树route:group_by: ['alertname'] # 根据告警规则组名进行分组group_wait: 15s # 分组内第一个告警等待时间,10s内如有第二个告警会合并一个告警group_interval: 15s # 发送新告警间隔时间repeat_interval: 1h # 重复告警间隔发送时间receiver: 'mail'# 接收人receivers:- name: 'mail'email_configs:- to: '1690014753@qq.com'# 抑制规则inhibit_rules:- source_match:severity: 'critical'target_match:severity: 'warning'equal: ['alertname', 'dev', 'instance']
./amtool check-config alertmanager.yml
根据指标中的标签发送不同的收件人
route:- receiver: 'default-receiver'group_wait: 30sgroup_interval: 5mrepeat_interval: 4hgroup_by: [cluster, alertname]routes:- receiver: 'database-pager'group_wait: 10smatch_re:service: mysql|cassandra- receiver: 'frontend-pager'group_by: [product, environment]match:team: frontendreceivers:- name: ‘database-pager'email_configs:- to: 'zhenliang369@163.com'- name: ‘frontend-pager'email_configs:- to: 'zhenliang369@163.com'
3.3 在Prometheus中创建告警规则
vi prometheus.yml...# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets:- 192.168.6.31:9093 # 配置发送告警事件接口rule_files:- "rules/*.yml"...
创建告警规则
vi rules/general.ymlgroups:- name: example #告警规则组名称rules:# 任何实例1分钟内无法访问发出告警- alert: InstanceDown # 告警规则名称expr: up == 0 # 基于PromQL的触发条件for: 1m # 等待评估时间labels: # 自定义标签(例如抑制所需的告警级别)severity: pageannotations: # 指定附加信息summary: " {{ $labels.instance }} 停止工作"description: "{{ $labels.instance }}:job {{ $labels.job }} 已经停止1分钟以上."
3.4 告警状态
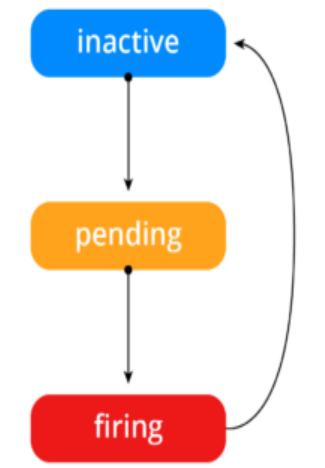
• Inactive:这里什么都没有发生。
• Pending:已触发阈值,但未满足告警持续时间
• Firing:已触发阈值且满足告警持续时间。警报发送给接受者。
3.5 告警收敛(分组、抑制、静默)
分组(group):将类似性质的警报分类为单个通知
抑制(Inhibition):当警报发出后,停止重复发送由此警报引发的其他警报
静默(Silences):是一种简单的特定时间静音提醒的机制

3.5.1 告警收敛:分组
- 分组(group):将类似性质的警报分类为单个通知
- 默认已起用
# 配置路由树route:group_by: ['alertname'] # 根据告警规则组名进行分组group_wait: 15s # 分组内第一个告警等待时间,10s内如有第二个告警会合并一个告警group_interval: 15s # 发送新告警间隔时间repeat_interval: 10m # 重复告警间隔发送时间receiver: 'mail'
3.5.2 告警收敛:抑制
- 抑制(Inhibition):当警报发出后,停止重复发送由此警报引发的其他警报
例如:一个Linux服务器上部署有1个nginx服务,当Linux和nginx都挂了,通过抑制处理,最终只发送一个Linux服务挂掉的告警
# 抑制规则inhibit_rules:- source_match:severity: 'critical' # 指定告警级别,也可以使用level: high来代替target_match:severity: 'warning' # 指定抑制告警级别equal: ['alertname', 'instance'] # 上面的两个抑制需要满足的条件,具有携带相同标签的信息
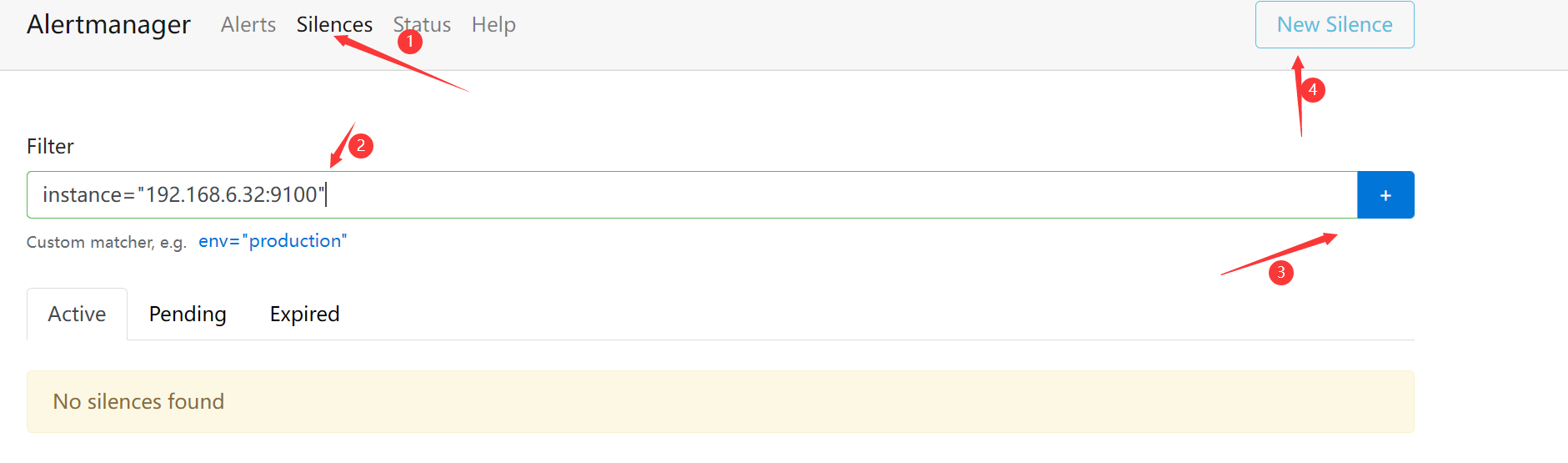
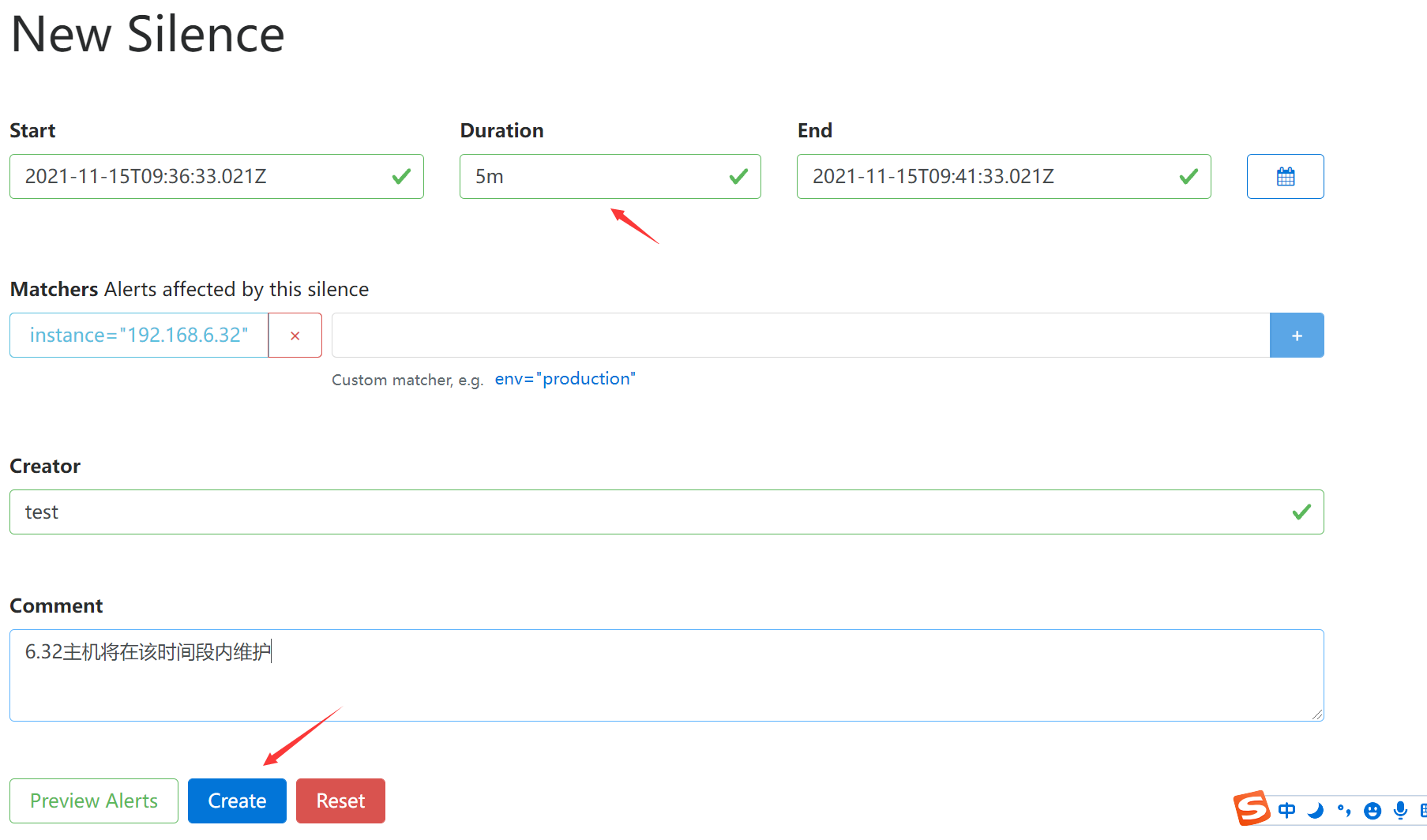
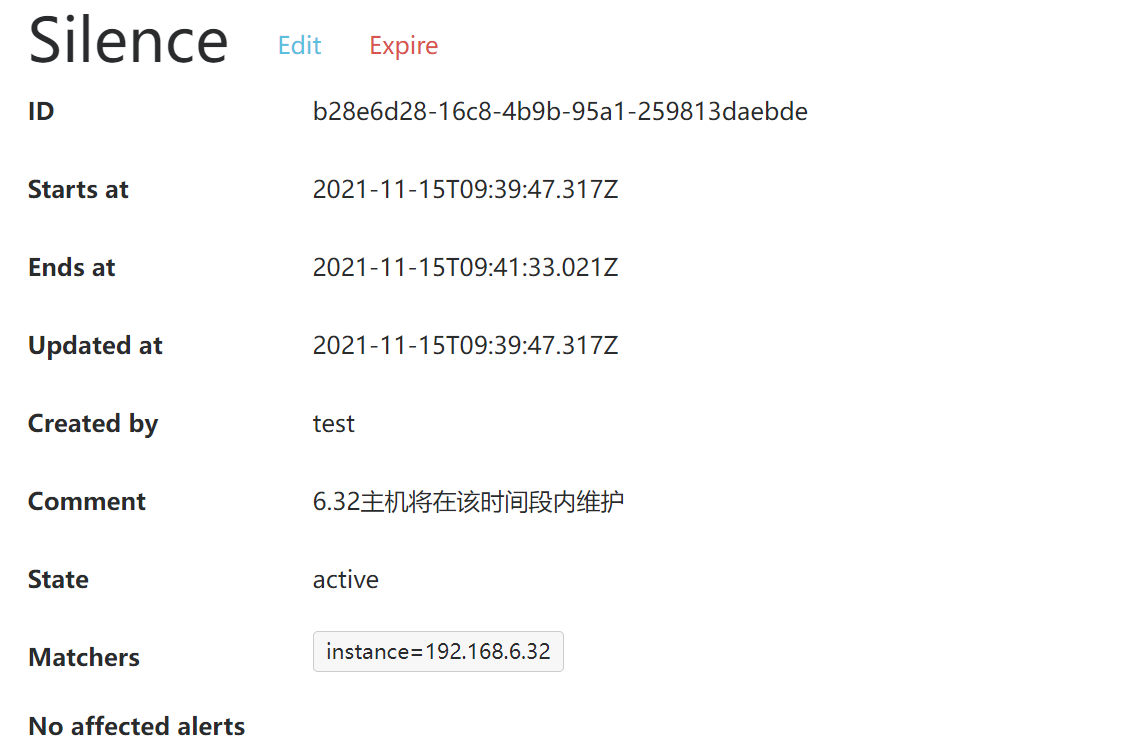
3.5.3 告警收敛:静默
- 静默(Silences):是一种简单的特定时间静音提醒的机制
例如:我们将要对服务192.168.6.32主机进行重启,我们知道将会发生告警,但是又想忽略他,可以配置静默来进行处理(将忽略带有指定标签的告警)
instance="192.168.6.32:9100"
3.6 Prometheus一条告警怎么触发?

3.7 编写告警规则案例
计算每个实例的CPU使用率
100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m]))by(instance) * 100 )
- irate(node_cpu_seconds_total{mode=”idle”}[5m]) 获取每个实例每核CPU5分钟的空闲速率
- avg(irate(node_cpu_seconds_total{mode=”idle”}[5m])) 计算获取到的所有实例的CPU空闲总速率
- avg(irate(node_cpu_seconds_total{mode=”idle”}[5m]))by(instance) 计算每个实例的空闲速率
- 100 - (avg(irate(node_cpu_seconds_total{mode=”idle”}[5m]))by(instance) * 100 ) 计算每个实例的CPU使用率
3.7.1 根据CPU的使用率触发告警
groups:- name: example #告警规则组名称rules:# 任何实例1分钟内无法访问发出告警- alert: InstanceDown # 告警规则名称expr: up == 0 # 基于PromQL的触发条件for: 1m # 等待评估时间labels: # 自定义标签severity: pageannotations: # 指定附加信息summary: " {{ $labels.instance }} 停止工作"description: "{{ $labels.instance }}:job {{ $labels.job }} 已经停止1分钟以上."# 当CPU使用率高于80%触发告警- alert: CPUUsageexpr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m]))by(instance) * 100 ) > 80for: 1m # 等待评估时间,1分钟内CPU高于80%labels: # 自定义标签level: warnningannotations: # 指定附加信息summary: " {{ $labels.instance }} CPU使用率过高"description: "{{ $labels.instance }}:CPU使用率大于80%,(当前值是 {{ $value }}%)"
3.7.2 告警规则
groups:- name: node.rulesrules:- alert: NodeFilesystemUsage # 文件系统使用率expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80for: 2mlabels:severity: warningannotations:summary: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用过高"description: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用大于 80% (当前值: {{ $value }})"- alert: NodeMemoryUsage # 内存使用率expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80for: 2mlabels:severity: warningannotations:summary: "{{$labels.instance}}: 内存使用过高"description: "{{$labels.instance}}: 内存使用大于 80% (当前值: {{ $value }})"- alert: NodeCPUUsage # CPU使用率expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80for: 2mlabels:severity: warningannotations:summary: "{{$labels.instance}}: CPU使用过高"description: "{{$labels.instance}}: CPU使用大于 80% (当前值: {{ $value }})"
表达式解析:
文件系统
100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
- fstype=~”ext4|xfs” 用于过滤文件系统类型,ext4或xfs类型的才会触发告警
内存
100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
- 内存使用率应除去空闲使用和缓存使用,就是整个使用率
4、Grafana可视化展示
4.1 Grafana部署
Grafana是一个开源的度量分析和可视化系统。
官方文档:https://grafana.com/docs/grafana/latest/
部署文档:https://grafana.com/grafana/download
访问地址:http://IP:3000
用户名/密码:admin/admin # 第一次需要重置密码
Grafana只用于展示数据,但这个数据从哪里来?
需要你根据提供数据的服务选择,支持的数据源如下
使用systemd服务管理
[Unit]Description=grafana[Service]ExecStart=/opt/monitor/grafana/bin/grafana-server -homepath=/opt/monitor/grafanaExecReload=/bin/kill -HUP $MAINPIDKillMode=processRestart=on-failure[Install]WantedBy=multi-user.target
配置文件:
# vi conf/defaults.ini[paths]data = datalogs = data/log[server]protocol = httphttp_addr =http_port = 3000[database]type = sqlite3path = grafana.db[security]admin_user = adminadmin_password = admin
4.2 自定义仪表盘
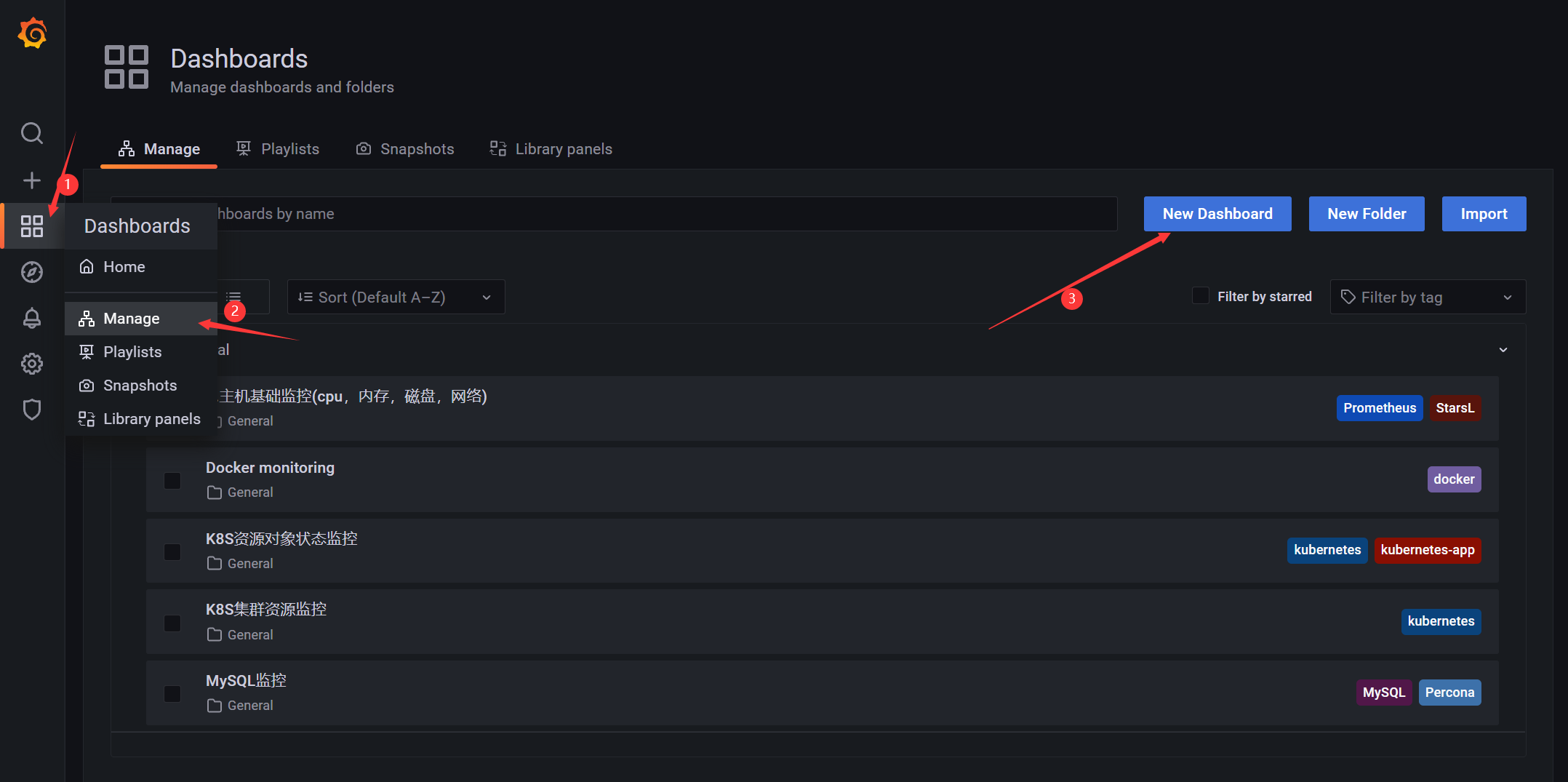
创建一个仪表盘的基本步骤:
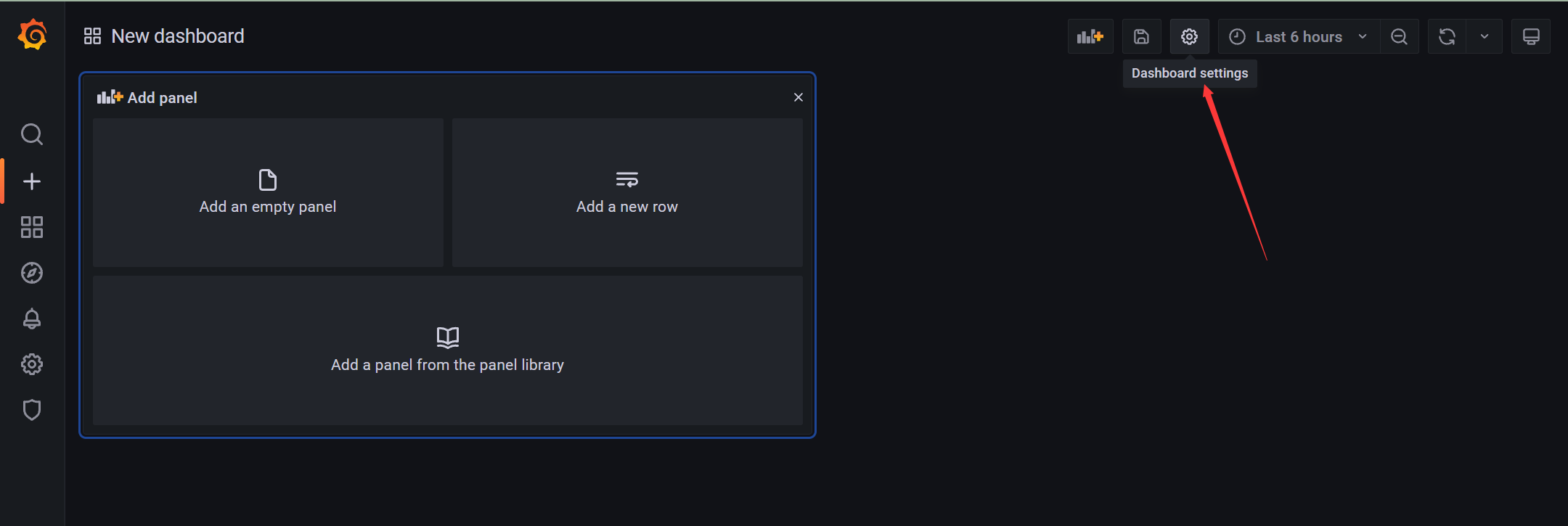
4.2.1 导航栏
- 新建仪表盘
- 导航栏 - 基本信息(分组)
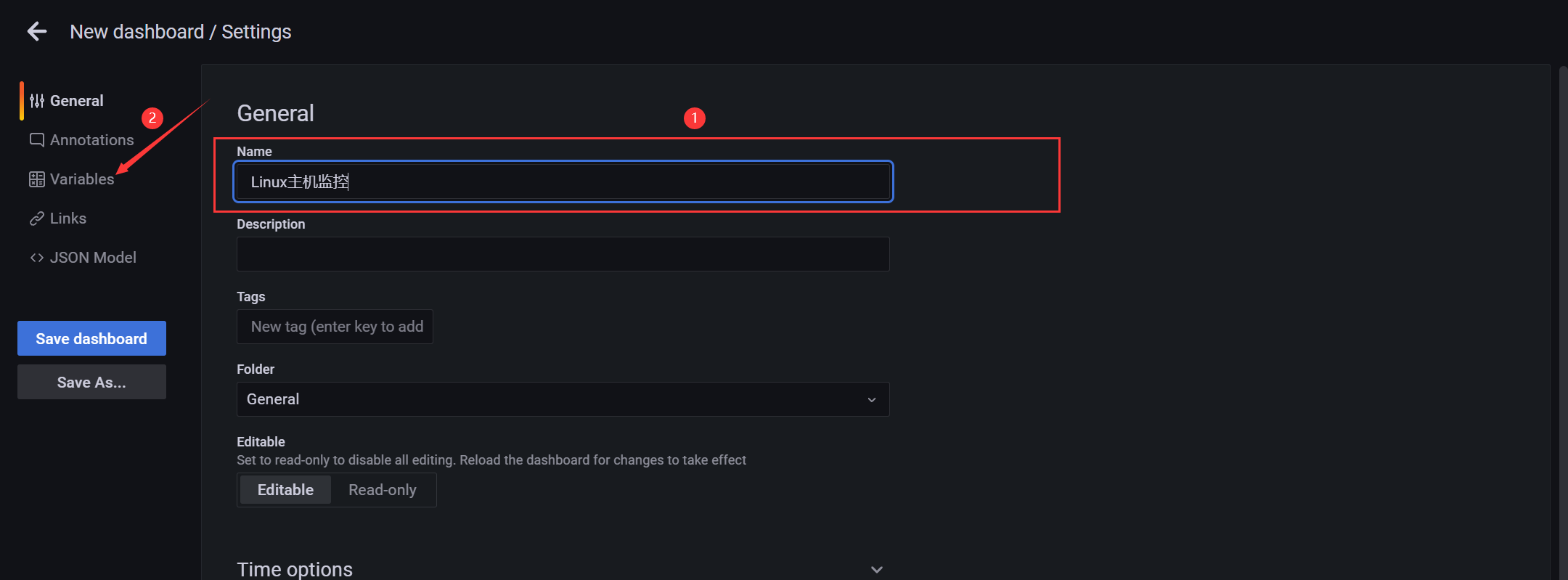
添加分组变量
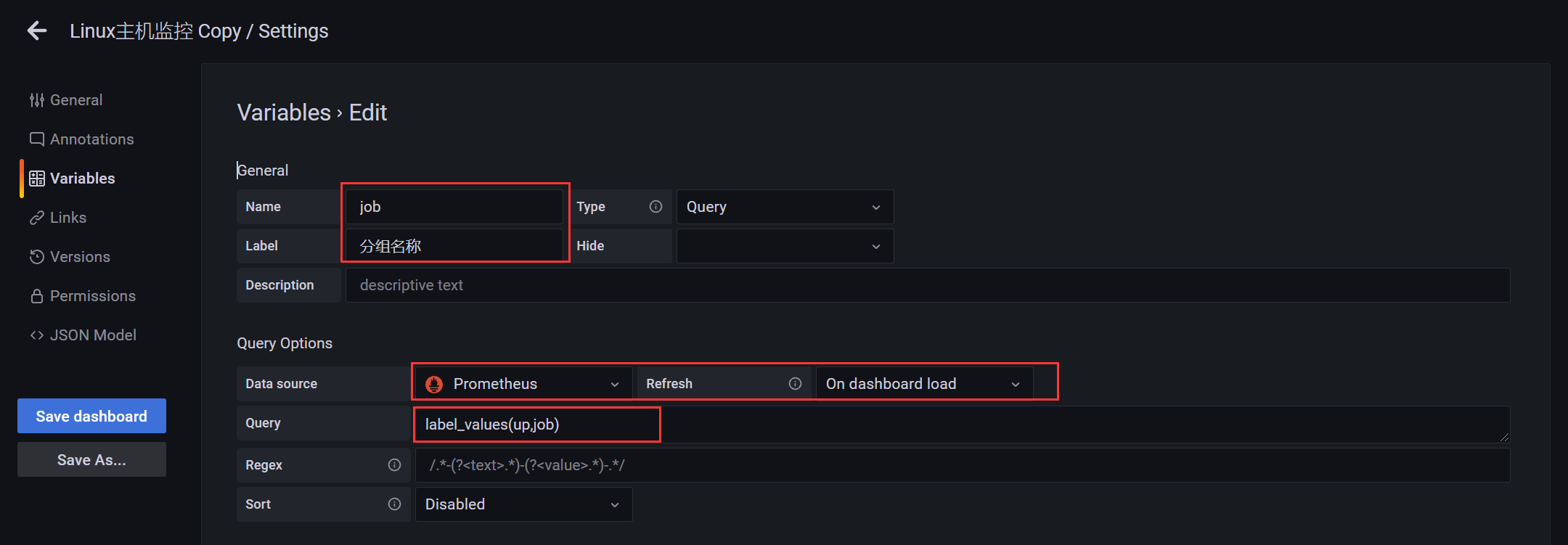
label_values(up,job)
- label_values 是grafana内置的针对Prometheus的查询函数
- 意思是根据Prometheus的up查询的实例指标,获取其中的job字段
效果如下:
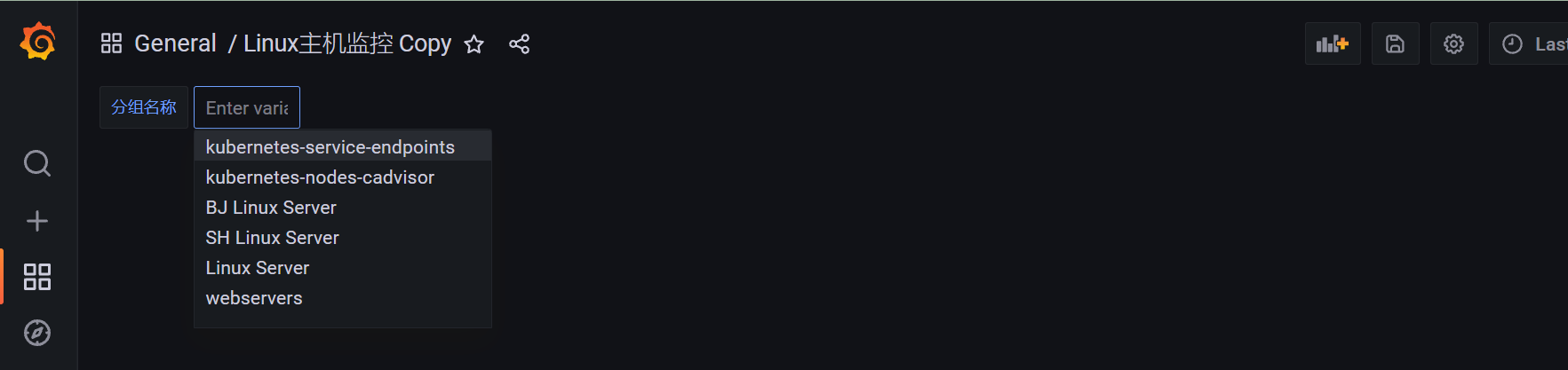
添加节点变量

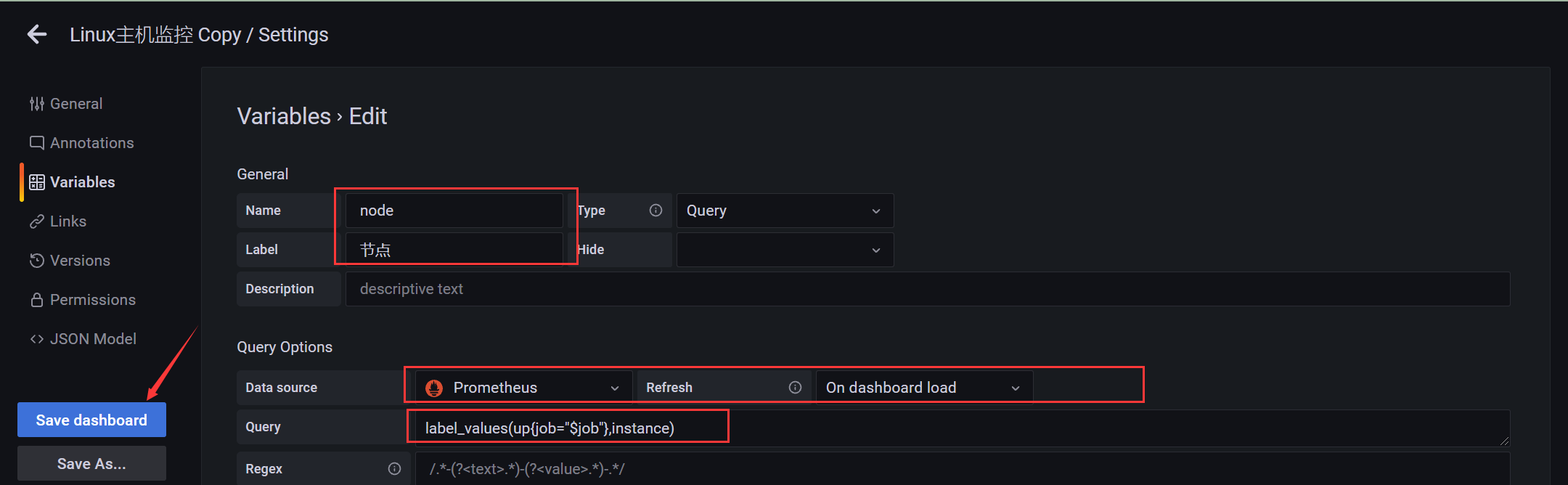
label_values(up{job="$job"},instance)
- up{job=”$job”} 使得该node和job具有级联关系,这里的获取的指标根据前面的分组获取
效果展示:

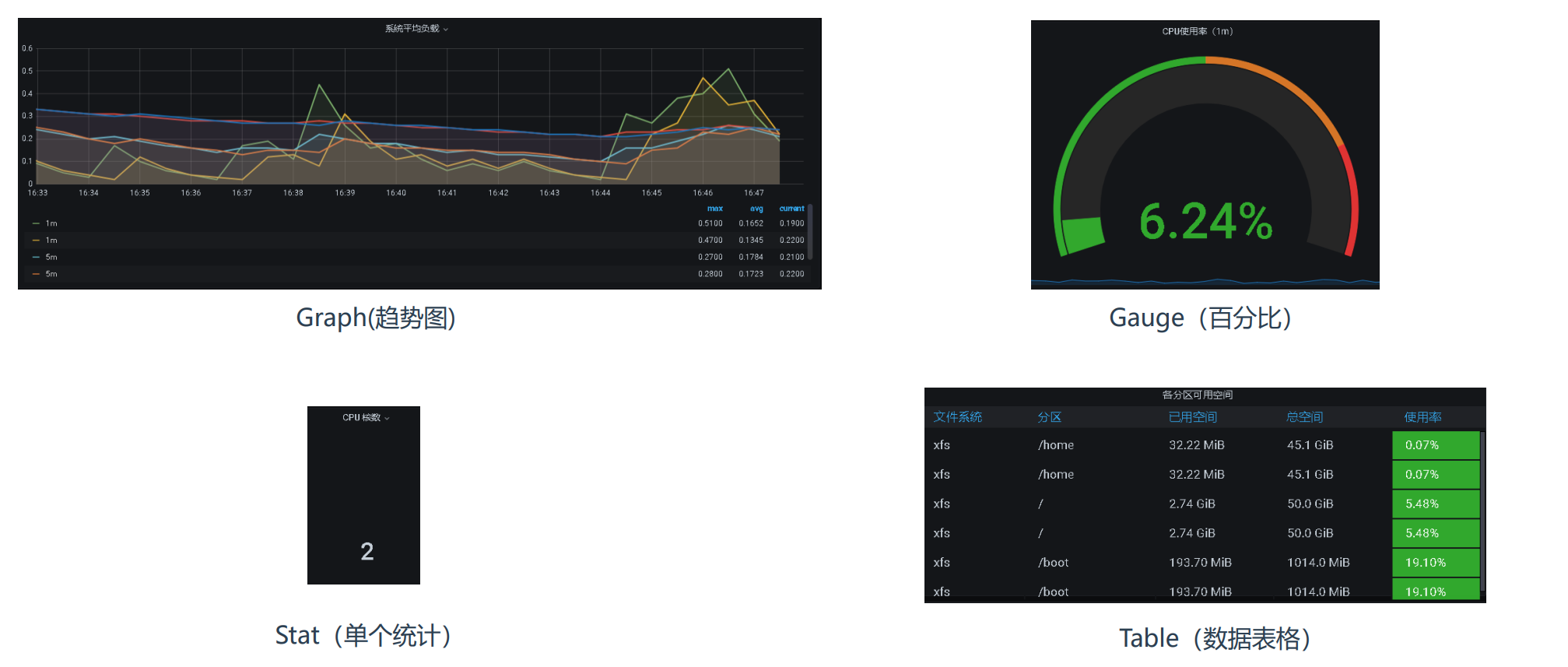
4.2.2 图表 - CPU核心数
图表的类型:
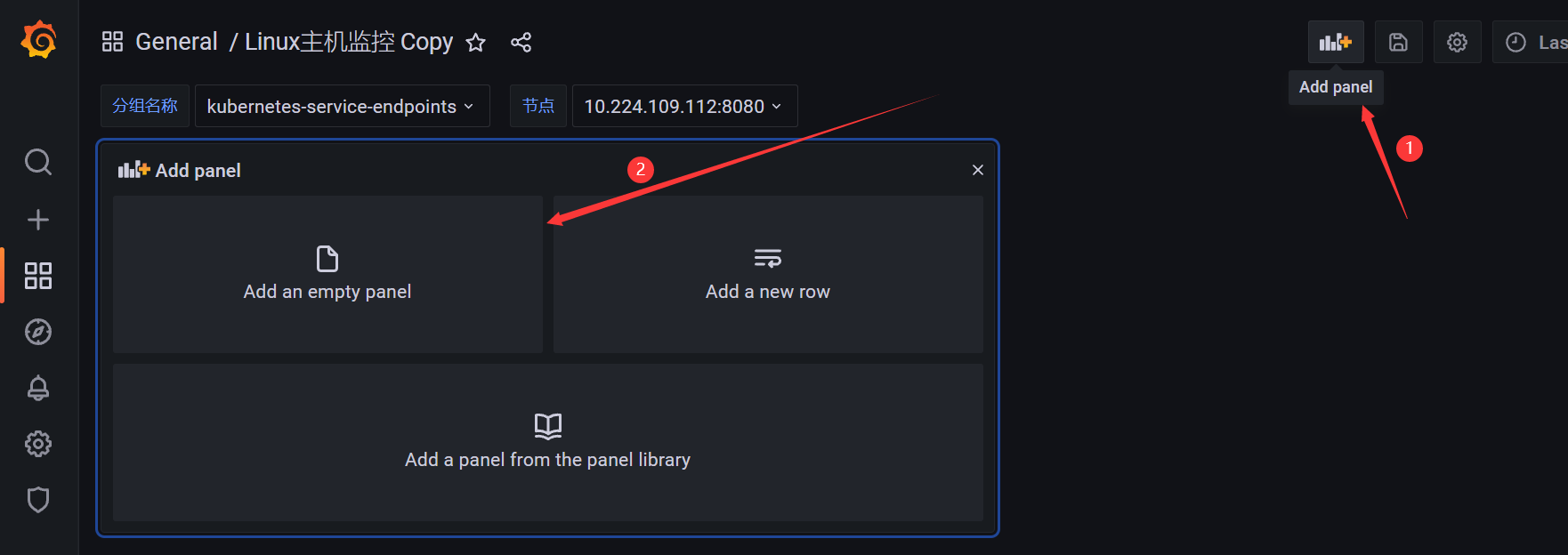
- 添加面板
默认为曲线图(这里先选择单个统计 - CPU核数)
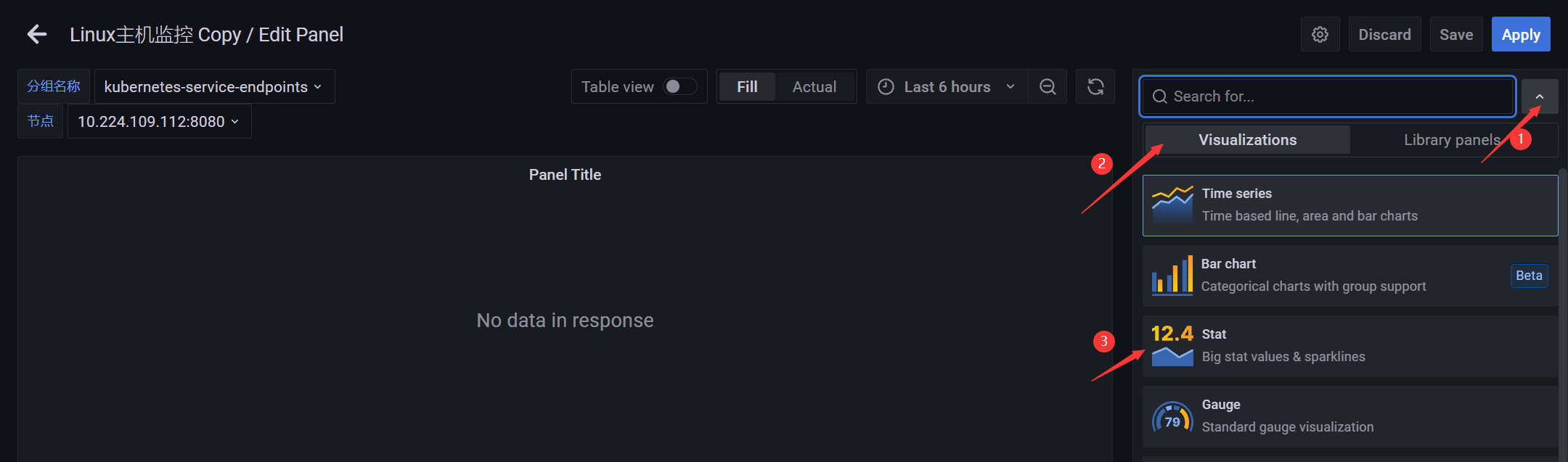
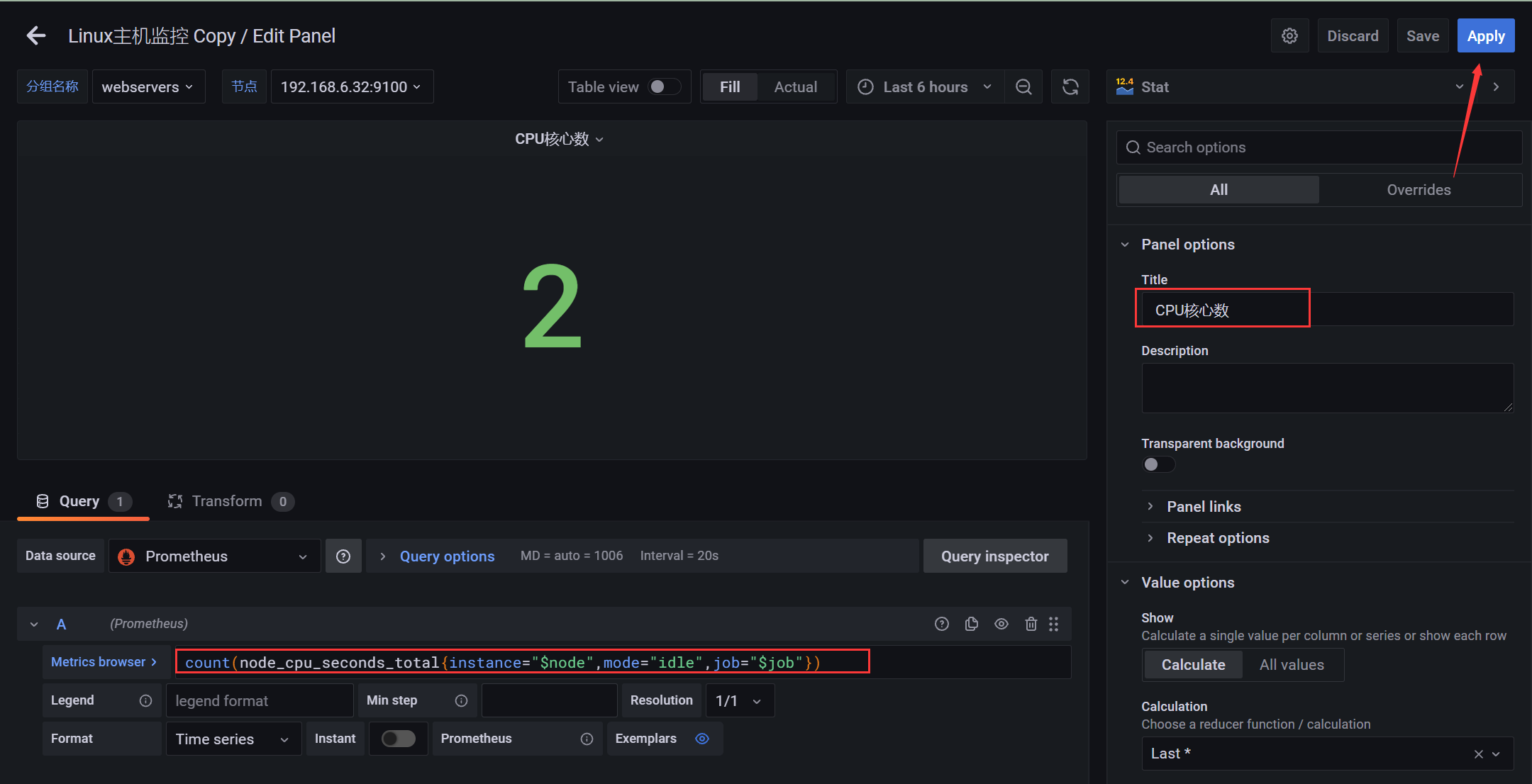
PromQL:计算实例节点的CPU核心数
count(node_cpu_seconds_total{instance="$node",mode="idle",job="$job"})
4.2.3 图表 - 内存
- Prometheus中存储的内存单位默认是字节
- node_memory_MemTotal_bytes字节=node_memory_MemTotal_bytes/1024 Kb /1024 Mb /1024 Gb
- grafana中可以通过设置字段的数据类型直接进行转化
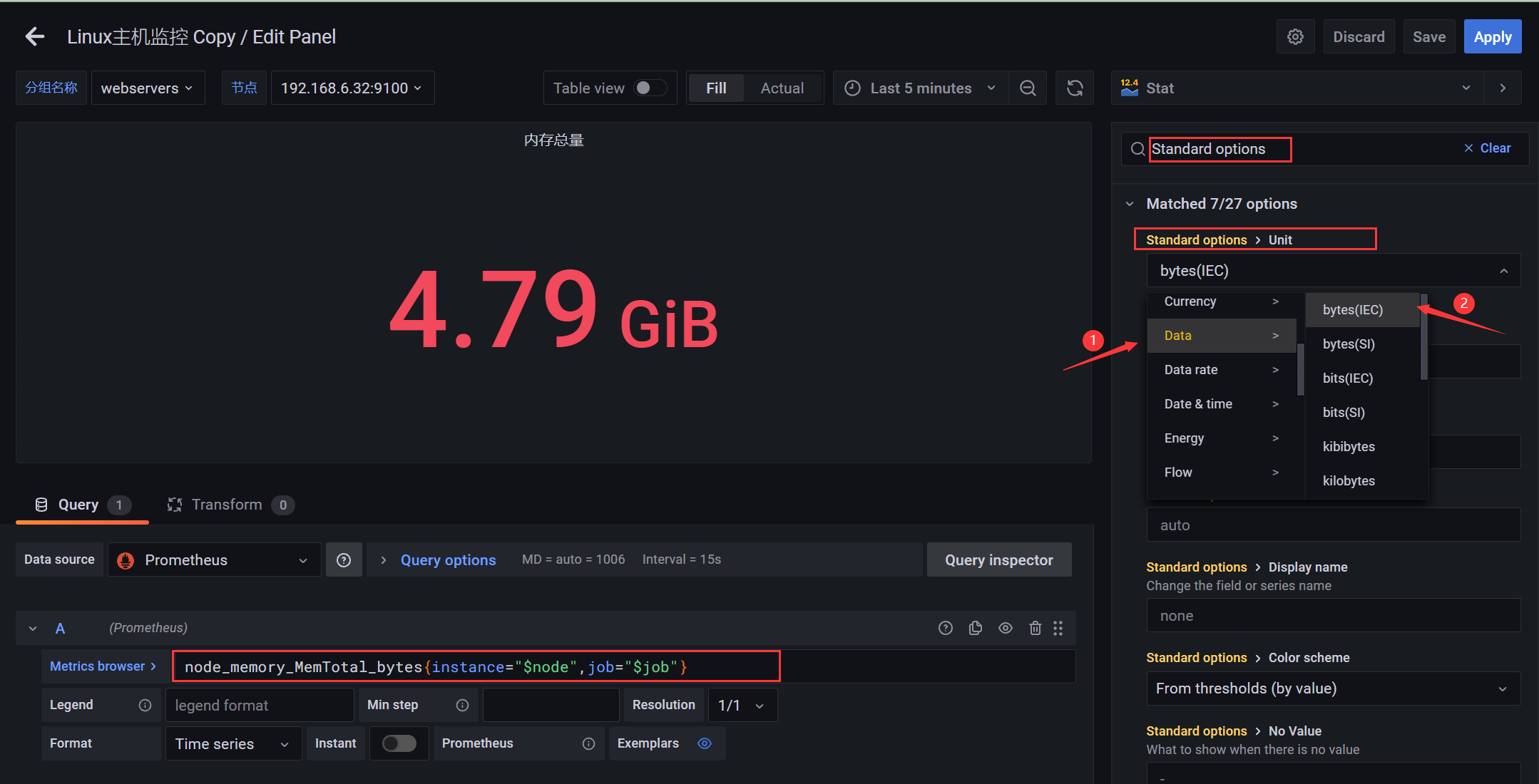
- 设置单位直接搜索Standard options,在单位(Unit)下的data中,第一个(bytes(IEC))一般就是内存的
node_memory_MemTotal_bytes{instance="$node",job="$job"}
4.2.4 图表 - CPU使用率
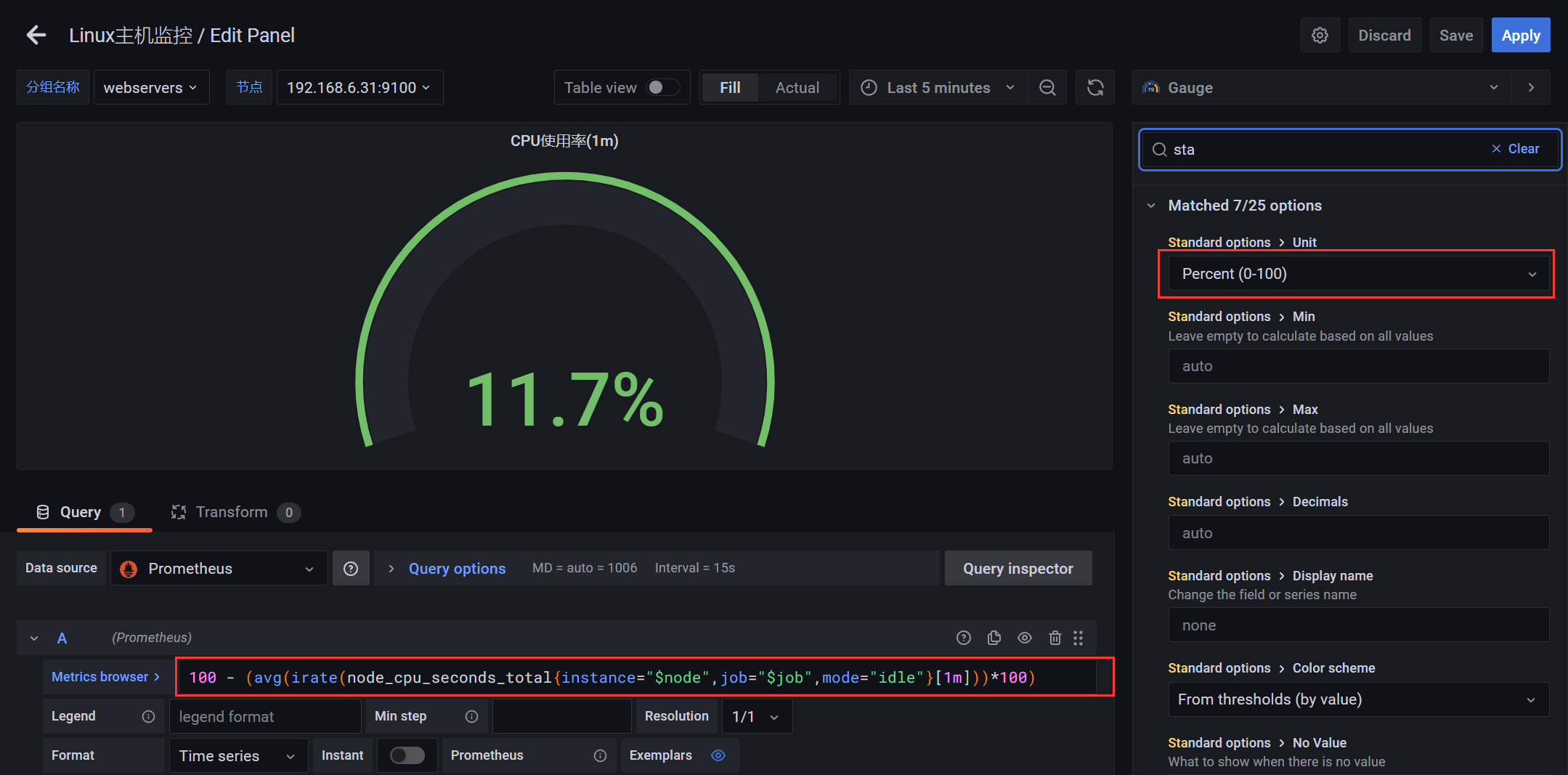
PromQL:CPU使用率
100 - (avg(irate(node_cpu_seconds_total{instance="$node",job="$job",mode="idle"}[1m]))*100)
4.2.5 图表 - 内存使用率
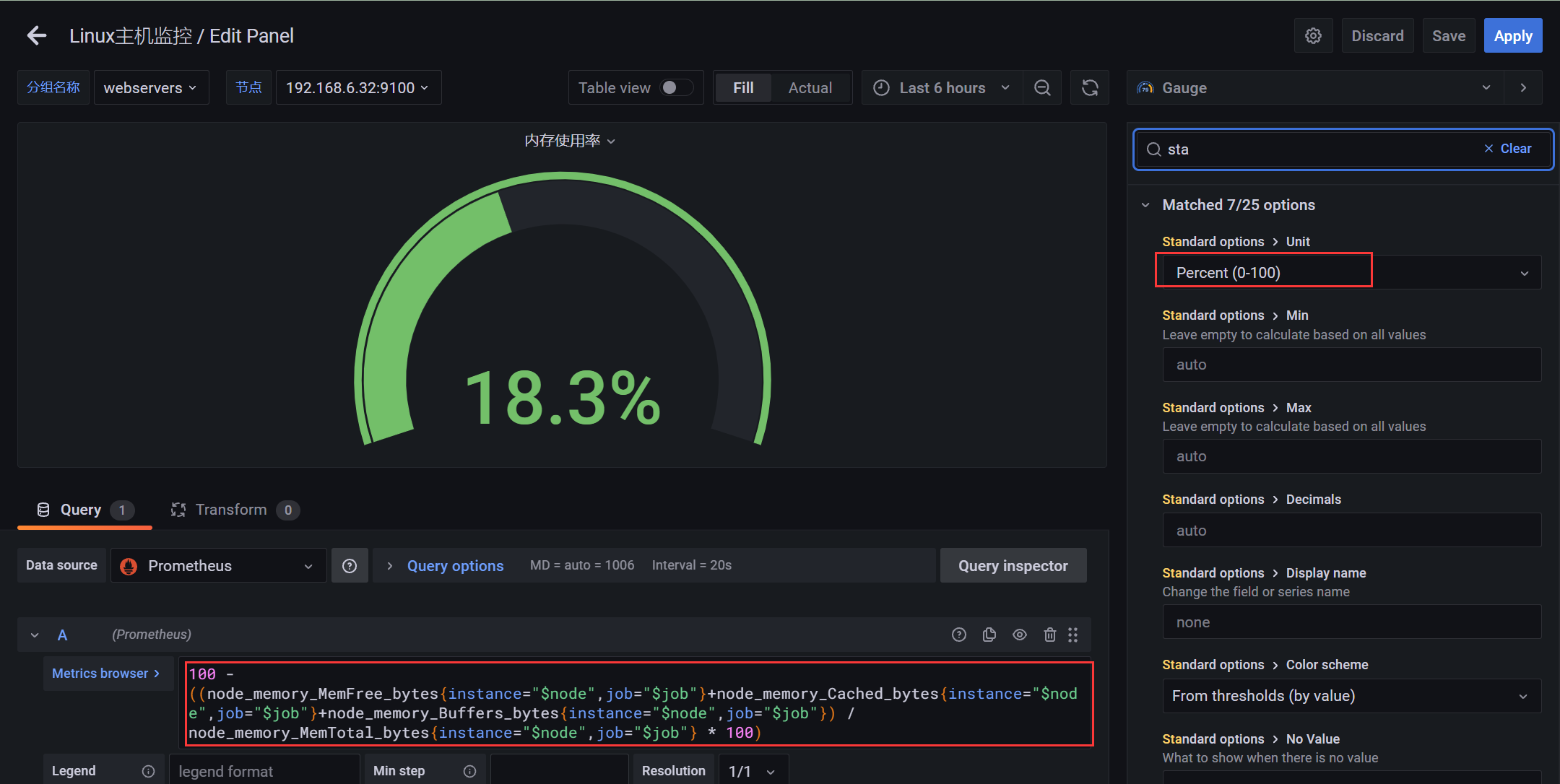
PromQL:内存使用率
100 - ((node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100)100 - ((node_memory_MemFree_bytes{instance="$node",job="$job"}+node_memory_Cached_bytes{instance="$node",job="$job"}+node_memory_Buffers_bytes{instance="$node",job="$job"}) / node_memory_MemTotal_bytes{instance="$node",job="$job"} * 100)
4.2.5 图表 - 文件系统更分区使用率
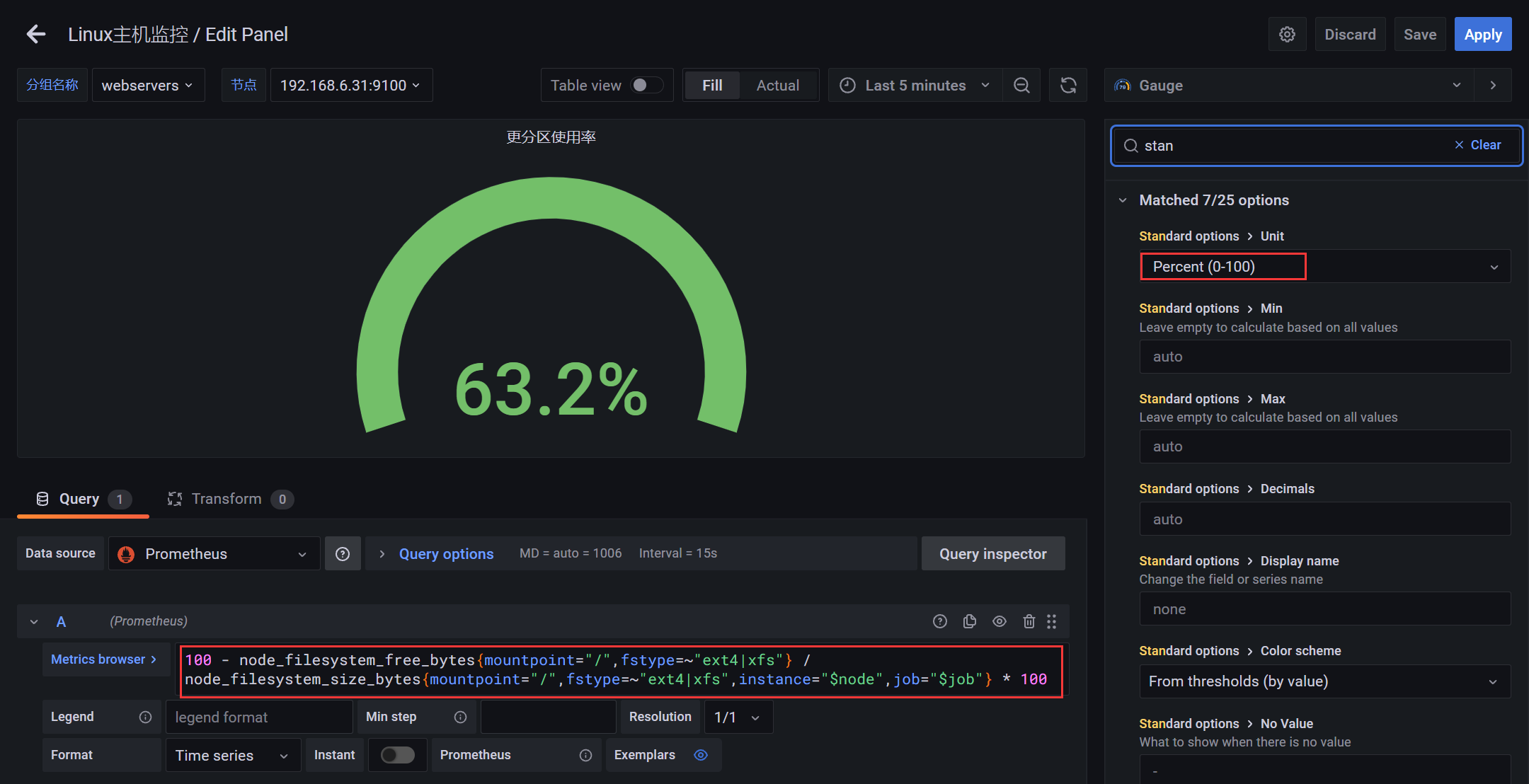
PromQL:文件系统更分区使用率
100 - node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"} * 100100 - node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs",instance="$node",job="$job"} * 100
4.2.6 图表 - CPU使用率(曲线图)
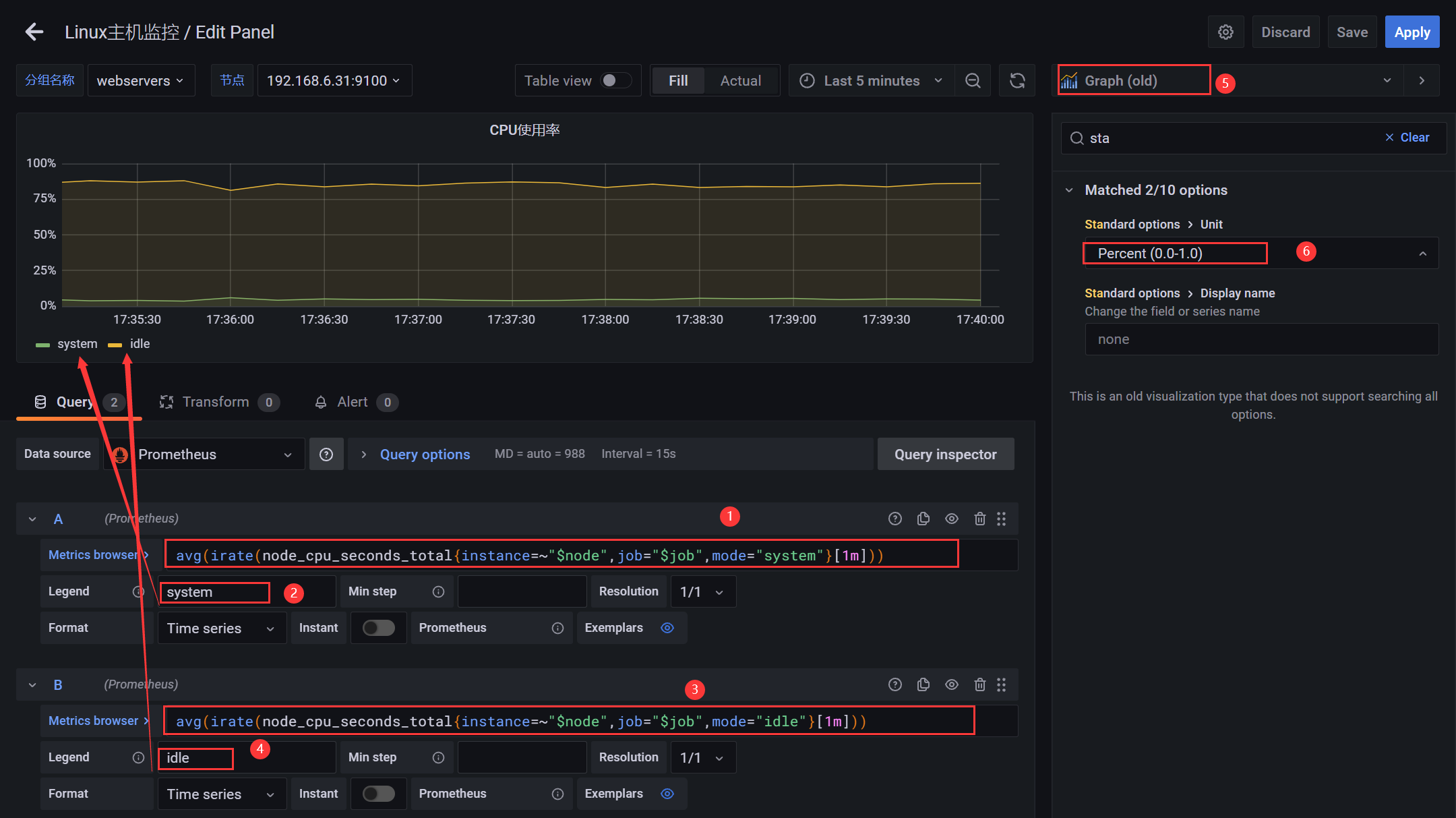
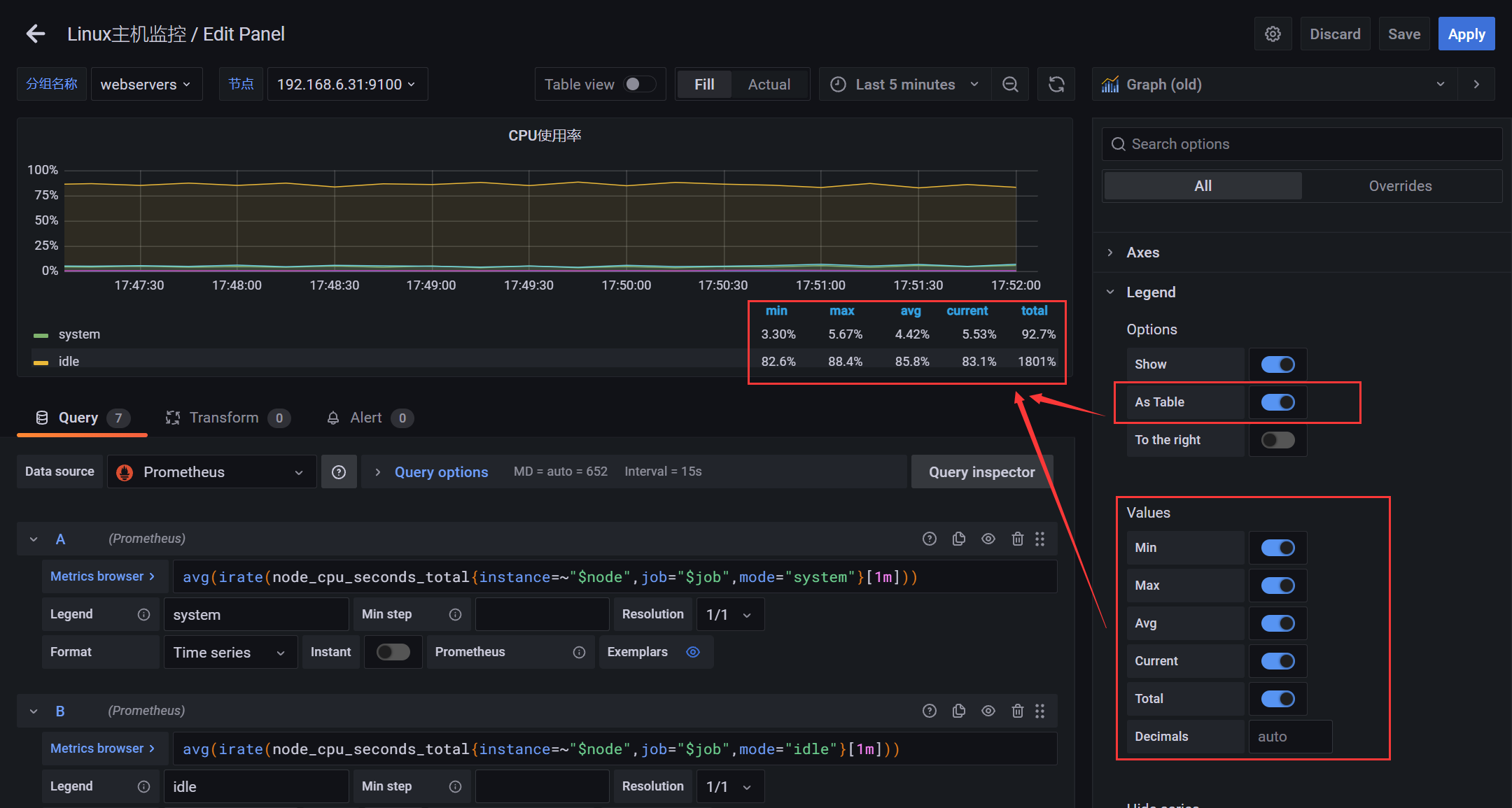
PromQL:CPU使用率
# 用户态avg(irate(node_cpu_seconds_total{instance=~"$node",job="$job",mode="user"}[1m]))# 内核态avg(irate(node_cpu_seconds_total{instance=~"$node",job="$job",mode="system"}[1m]))# 空闲avg(irate(node_cpu_seconds_total{instance=~"$node",job="$job",mode="idle"}[1m]))# io等待avg(irate(node_cpu_seconds_total{instance=~"$node",job="$job",mode="iowait"}[1m]))# 中断请求(硬中断(Hardware IRQ)占用CPU的百分比)avg(irate(node_cpu_seconds_total{instance=~"$node",job="$job",mode="irq"}[1m]))# Hypervisor分配给运行在其它虚拟机上的任务的实际CPU时间avg(irate(node_cpu_seconds_total{instance=~"$node",job="$job",mode="steal"}[1m]))# 中断请求(软中断(Software Interrupts)占用CPU的百分比)avg(irate(node_cpu_seconds_total{instance=~"$node",job="$job",mode="softirq"}[1m]))
4.2.7 图表 - 各分区可用空间
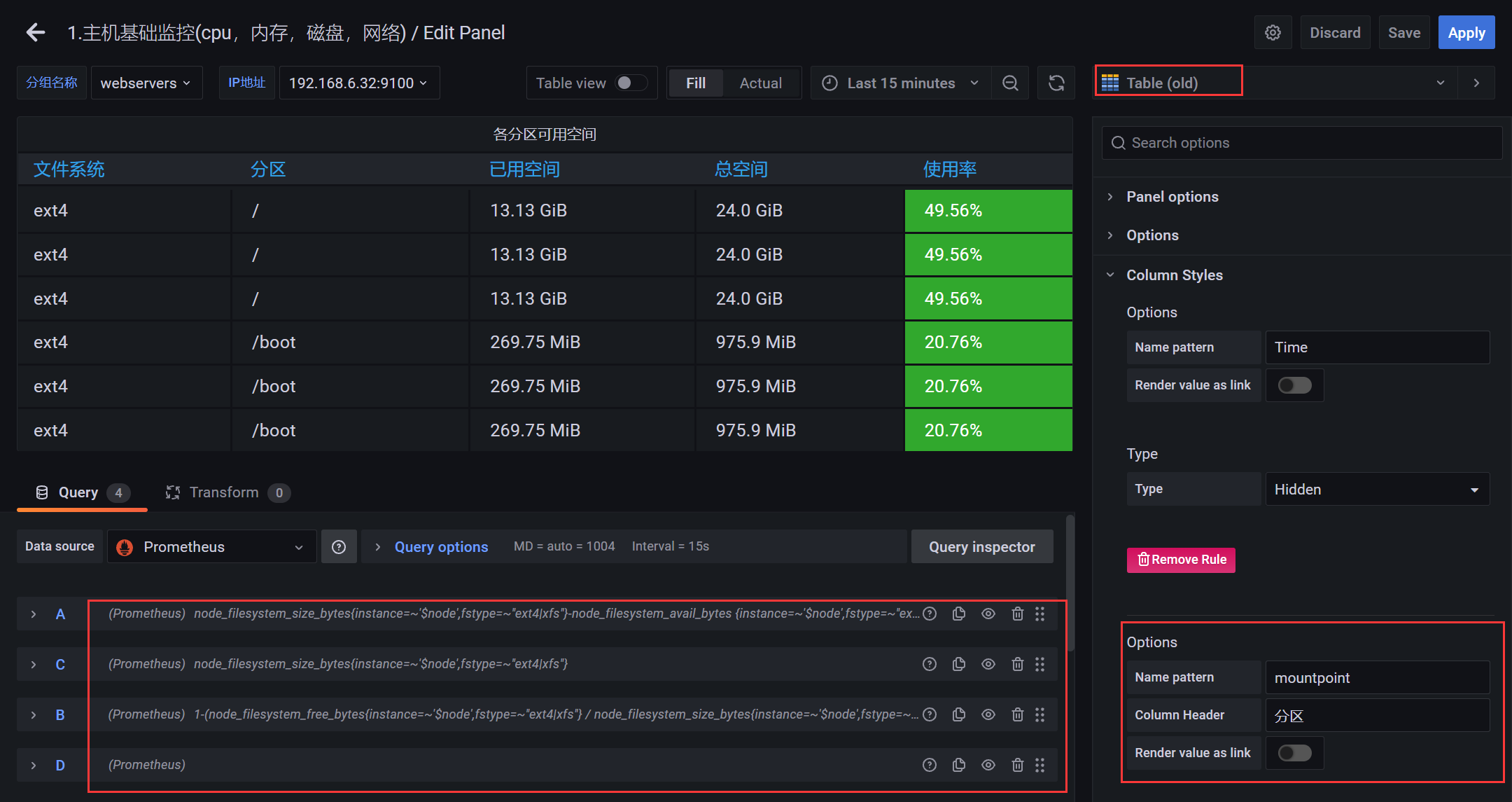
# Anode_filesystem_size_bytes{instance=~'$node',fstype=~"ext4|xfs"}-node_filesystem_avail_bytes {instance=~'$node',fstype=~"ext4|xfs"}# Bnode_filesystem_size_bytes{instance=~'$node',fstype=~"ext4|xfs"}# C1-(node_filesystem_free_bytes{instance=~'$node',fstype=~"ext4|xfs"} / node_filesystem_size_bytes{instance=~'$node',fstype=~"ext4|xfs"})# D 空
4.3 仪表盘导入导出

若有收获,就点个赞吧
0 人点赞
