1、Logstash介绍
Logstash能够将采集日志、格式化、过滤,最后将数据推送到Elasticsearch存储。
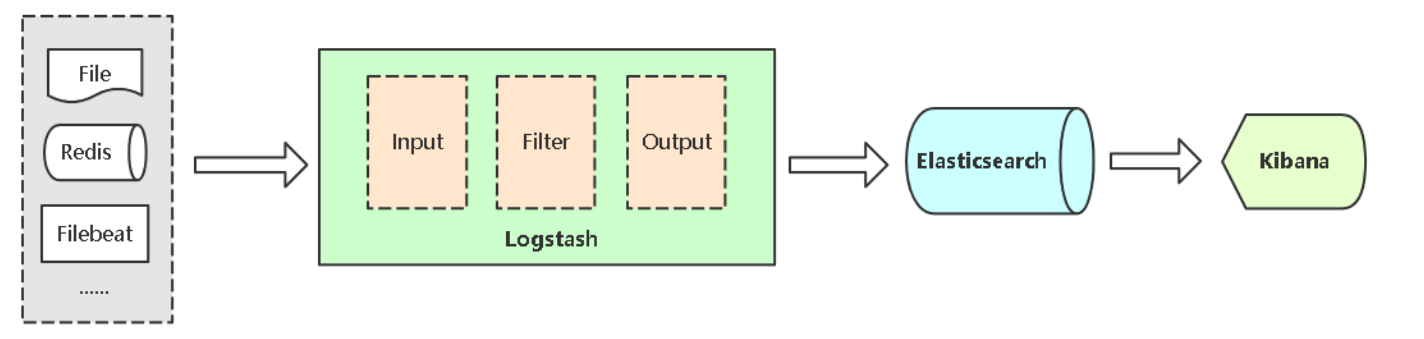
Input:输入,输入数据可以是Stdin、File、TCP、Redis、Syslog等。
Filter:过滤,将日志格式化。有丰富的过滤插件:Grok正则捕获、Date时间处理、Json编解码、Mutate数据修改等。
Output:输出,输出目标可以是Stdout、File、TCP、Redis、ES等。
2、Logstash部署
二进制方式部署:yum install java-1.8.0-openjdk –ycd /opt/elktar zxvf logstash-7.9.3.tar.gzmv logstash-7.9.3 logstash
# vi /usr/lib/systemd/system/logstash.service[Unit]Description=logstash[Service]ExecStart=/opt/elk/logstash/bin/logstashExecReload=/bin/kill -HUP $MAINPIDKillMode=processRestart=on-failure[Install]WantedBy=multi-user.target
# vim config/logstash.ymlpipeline: # 管道配置batch:size: 125delay: 5path.config: /opt/elk/logstash/conf.d # conf.d目录自己创建# 定期检查配置是否修改,并重新加载管道。也可以使用SIGHUP信号手动触发# config.reload.automatic: false# config.reload.interval: 3s# http.enabled: truehttp.host: 0.0.0.0http.port: 9600-9700log.level: infopath.logs: /opt/elk/logstash/logs
3、基本使用
3.1 示例:从标准输入获取日志并打印到标准输出
# 使用 -e 参数,需要注释掉path.config(两个不能同时使用,后面会将-e后的参数写入path.config中)/opt/elk/logstash/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'helloworld{"@timestamp" => 2021-11-19T02:06:06.269Z,"message" => "helloworld","@version" => "1","host" => "k8s-master1"}
默认给日志加的三个字段:• "@timestamp" 标记事件发生的时间点• "host" 标记事件发生的主机• "type" 标记事件的唯一类型命令行参数:• -e 字符串形式写配置• -f 指定配置文件• -t 测试配置文件语法
4、输入插件
输入阶段:从哪里获取日志常用插件:• Stdin(一般用于调试)• File• Redis• Beats(例如filebeat)
4.1 输入插件:File
File插件:用于读取指定日志文件常用字段:• path 日志文件路径,可以使用通配符• exclude 排除采集的日志文件• start_position 指定日志文件什么位置开始读,默认从结尾开始,指定beginning表示从头开始读
示例:读取日志文件并输出到文件input {# 指定采集的日志file {path => "/var/log/test/*.log" # 指定采集的日志文件exclude => "error.log" # 要排除的日志文件#start_position => "beginning" # 指定读取的日志文件位置,默认是从结尾,beginning从头开始}}# 过滤是可选的filter {}output {# 指定采集的日志写入位置file {path => "/tmp/test.log"}}
输入插件都支持的字段:
• add_field 添加一个字段到一个事件,放到事件顶部,一般用于标记日志来源。例如属于哪个项目,哪个应用
• tags 添加任意数量的标签,用于标记日志的其他属性,例如表明访问日志还是错误日志
• type 为所有输入添加一个字段,例如表明日志类型
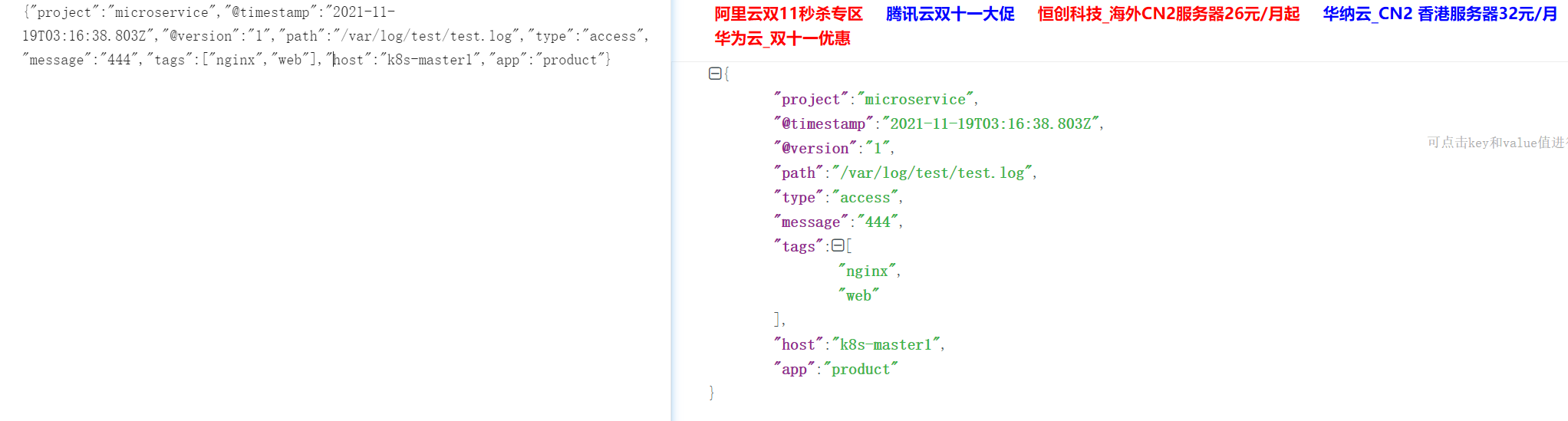
示例:配置日志来源input {file {path => "/var/log/test/*.log"exclude => "error.log"#start_position => "beginning"tags => "web" # 标签tags => "nginx"type => "access" # 日志类型add_field => { # 字段"project" => "microservice" # 例如:微服务项目"app" => "product" # 微服务下的商品项目}}}
4.2 输入插件:Beats
Beats插件:接收来自Beats数据采集器发来的数据,例如Filebeat(后面讲解)
常用字段:
• host 监听地址
• port 监听端口
示例:input {beats {host => "0.0.0.0"port => 5044}}filter {}output {file {path => "/tmp/test.log"}}
5、过滤插件
过滤阶段:将日志格式化处理常用插件:• json• kv• grok• geoip• date
过滤插件都支持的字段:• add_field 如果过滤成功,添加一个字段到这个事件• add_tags 如果过滤成功,添加任意数量的标签到这个事件• remove_field 如果过滤成功,从这个事件移除任意字段• remove_tag 如果过滤成功,从这个事件移除任意标签
5.1 部署Kibana用于查看测试数据
Kibana 是一个图形页面系统,用于对 Elasticsearch 数据可视化
5.1.1 二进制方式部署
二进制方式部署:cd /opt/elktar zxvf kibana-7.9.3-linux-x86_64.tar.gzmv kibana-7.9.3-linux-x86_64 kibana# vi config/kibana.ymlserver.port: 5601server.host: "0.0.0.0"elasticsearch.hosts: ["http://192.168.31.61:9200"] # 指定集群中一台即可,集群同步i18n.locale: "zh-CN"
配置系统服务管理:# vi /usr/lib/systemd/system/kibana.service[Unit]Description=kibana[Service]ExecStart=/opt/elk/kibana/bin/kibana --allow-rootExecReload=/bin/kill -HUP $MAINPIDKillMode=processRestart=on-failure[Install]WantedBy=multi-user.target
5.1.2 Logstash指定日志写入es
output {# 指定采集的日志写入位置(写入到es)# elasticsearch {# hosts => ["192.168.6.20:9200", "192.168.6.21:9200", "192.168.6.22:9200"]# index => "test-%{+YYYY.MM.dd}"# }file {path => "/tmp/test.log"}}
5.1.3 过滤插件:Json
JSON插件:接收一个json数据,将其展开为Logstash事件中的数据结构,放到事件顶层。常用字段:• source 指定要解析的字段,一般是原始消息message字段• target 将解析的结果放到指定字段,如果不指定,默认在事件的顶层
# 添加过滤 - 使用Json进行解析filter {json {source => "message"}}
模拟数据:{"remote_addr": "192.168.1.10","url":"/index","status":"200"}示例:解析HTTP请求filter {json {source => "message"}}
示例:解析HTTP请求
- 当输入非json字符串,会解析使用

- 当输入json字符串后查看解析 - 解析成功

5.1.4 过滤插件:Json解析到ES,使用kibana查看
output {# 指定采集的日志写入位置(写入到es)elasticsearch {hosts => ["192.168.6.20:9200", "192.168.6.21:9200", "192.168.6.22:9200"]index => "test-%{+YYYY.MM.dd}"}# file {# path => "/tmp/test.log"# }}
- 注意hosts中必须指定端口
- index中的+,是一定的
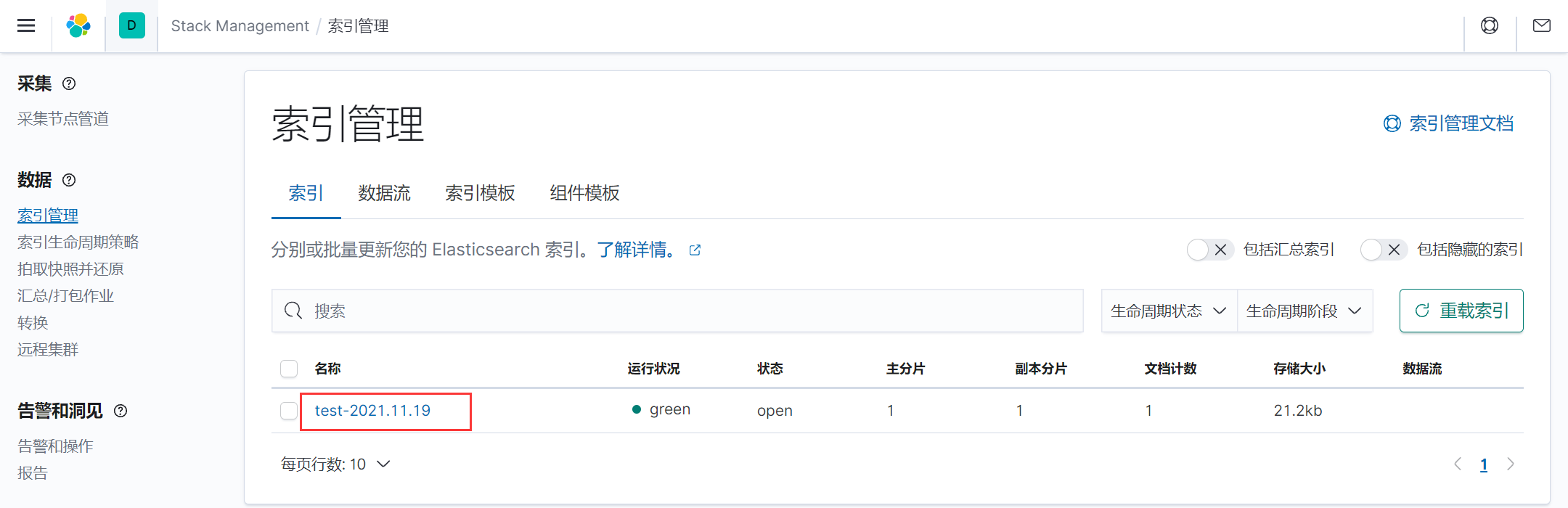
kibana管理页面:discover -> 索引管理
- 非json的无法被解析,错误信息如下:
Parsed JSON object/hash requires a target configuration option {:source=>"message", :raw=>"444"}
创建索引模式:只展示以test-开头的索引
索引模式 -> 创建索引模式test-* 时间戳
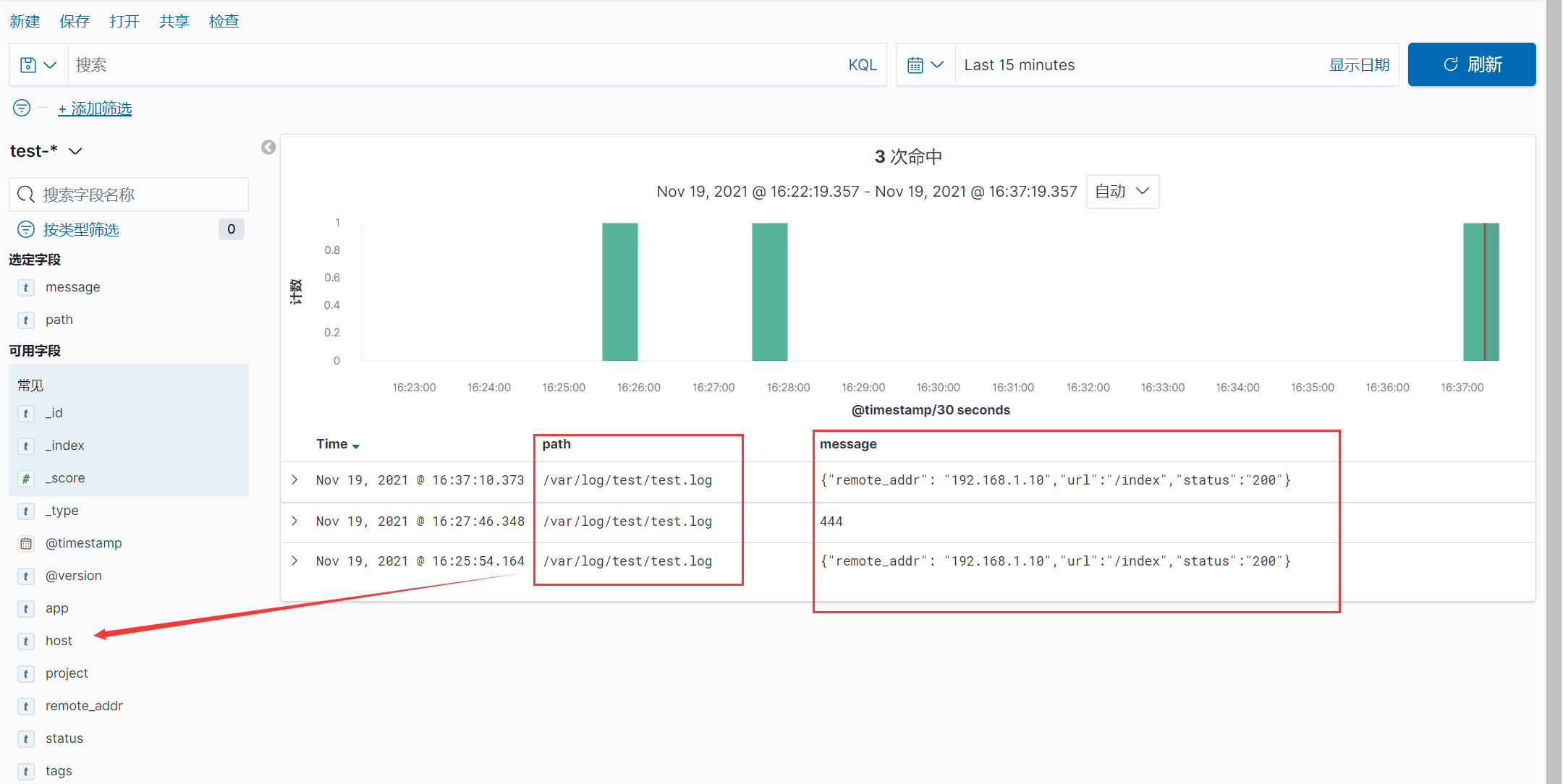
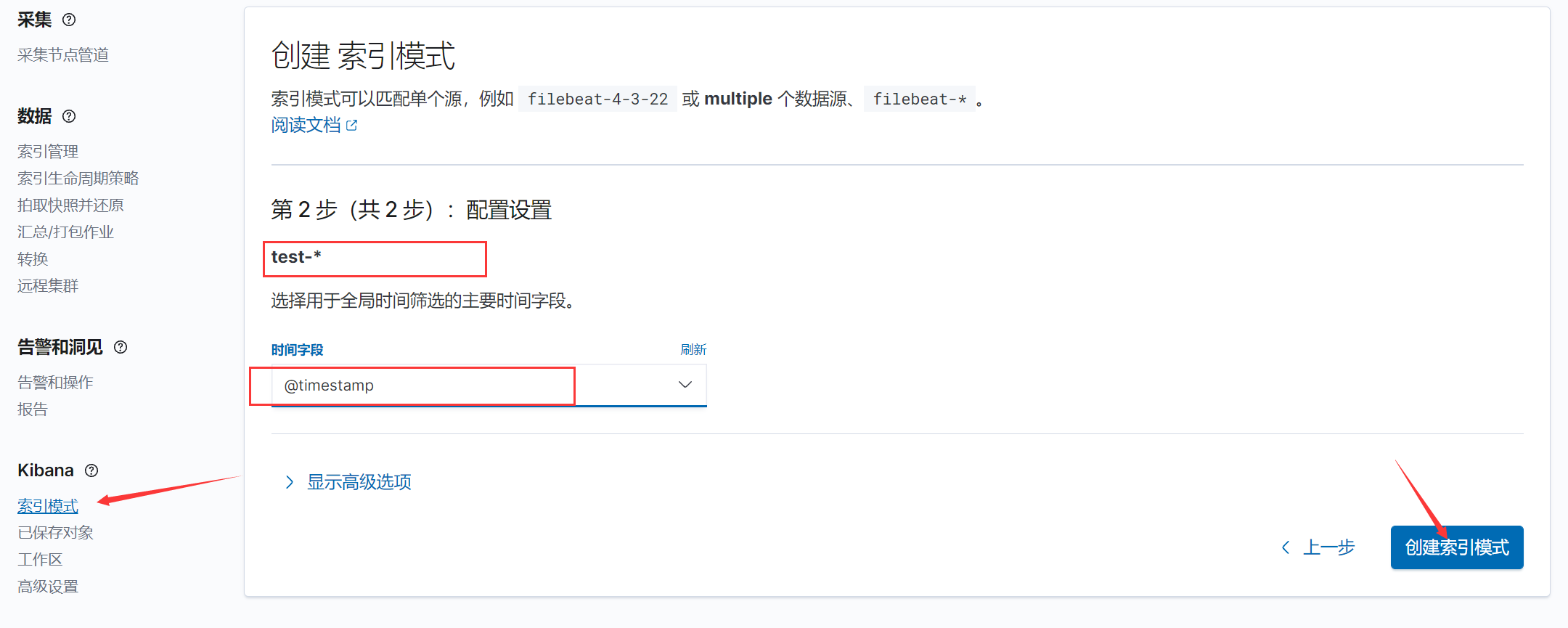 创建索引之后可以通过discover查看日志信息:
创建索引之后可以通过discover查看日志信息:
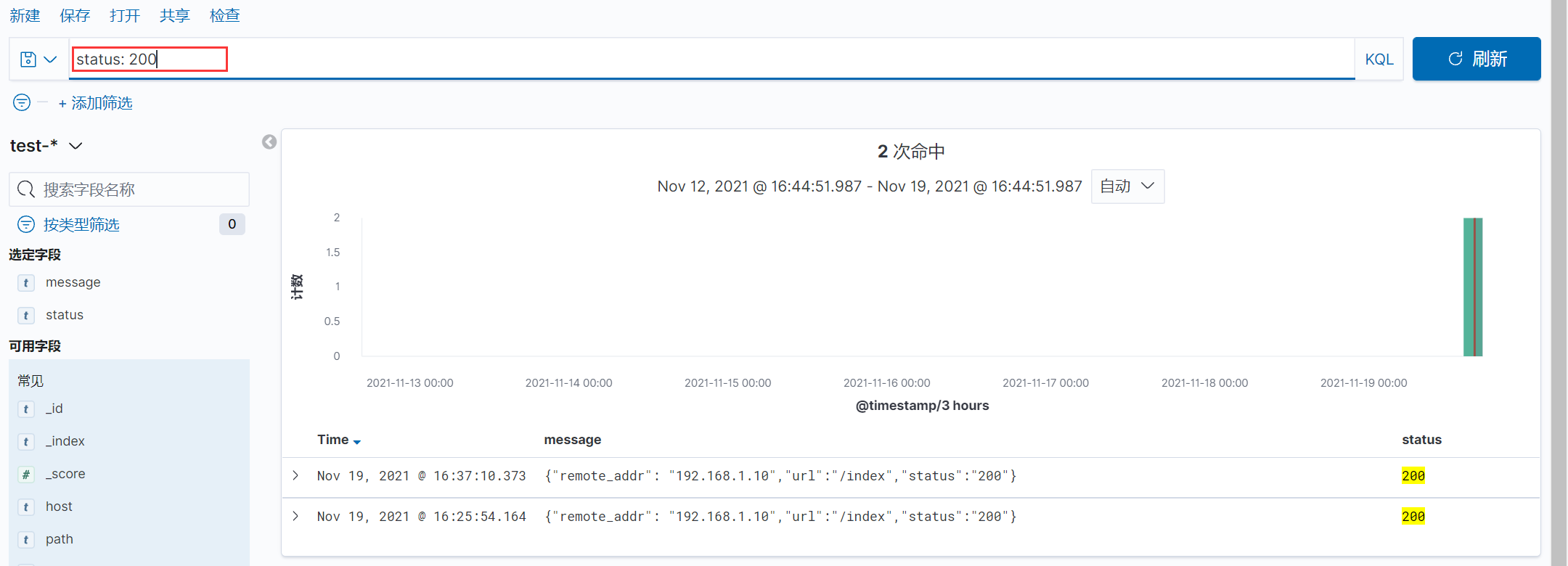
 查询状态码是200的数据:
查询状态码是200的数据:
 #### 5.1.5 过滤插件:KV
KV插件:接收一个键值数据,按照指定分隔符解析为Logstash事件中的数据结构,放到事件顶层。
常用字段:
• field_split 指定键值分隔符,默认空
#### 5.1.5 过滤插件:KV
KV插件:接收一个键值数据,按照指定分隔符解析为Logstash事件中的数据结构,放到事件顶层。
常用字段:
• field_split 指定键值分隔符,默认空
bash
模拟数据:
www.ctnrs.com?id=1&name=aliang&age=30
示例:解析URL中参数
filter {
kv {
field_split => "&?"
}
}
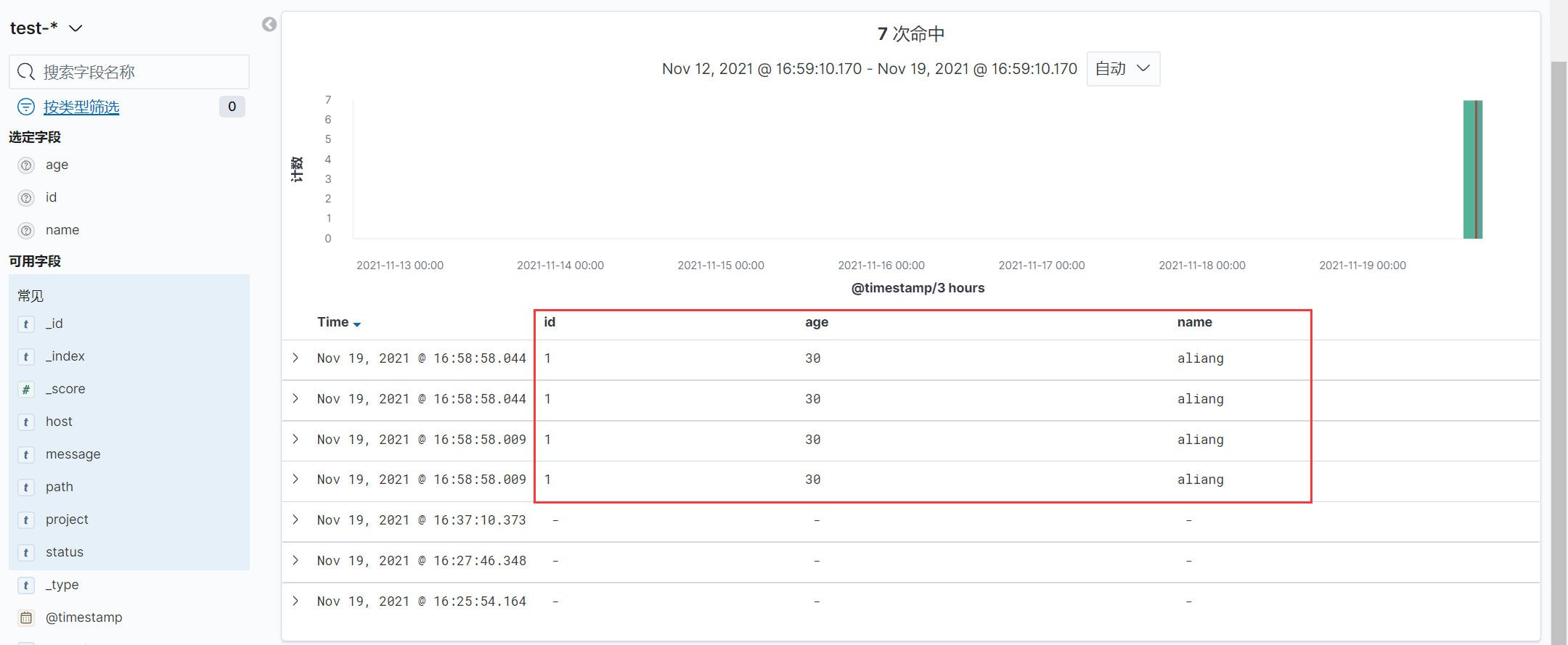 + 可以看到kv的模拟信息已经被解析
+ 可以看到kv的模拟信息已经被解析
5.1.6 过滤插件:Grok
Grok插件:如果采集的日志格式是非结构化的,可以写正则表达式提取,grok是正则表达式支持的实现。
常用字段:
• match 正则匹配模式
• patterns_dir 自定义正则模式文件

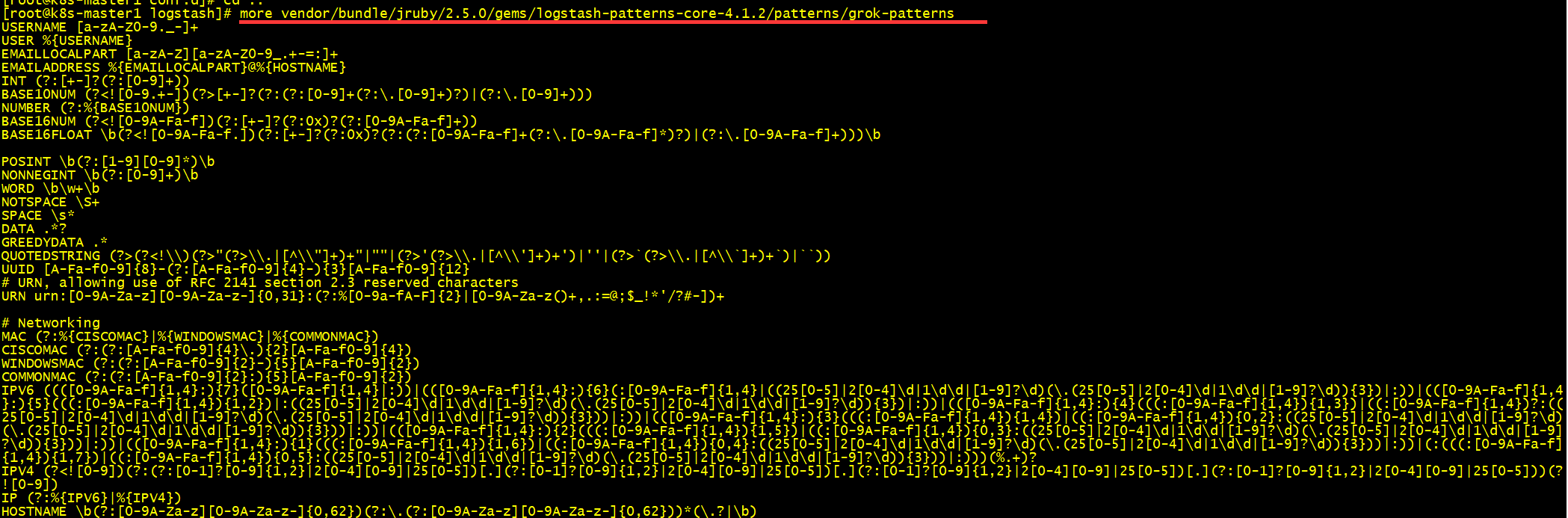
Logstash内置的正则匹配模式,在安装目录下可以看到,路径:vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns正则匹配模式语法格式:%{SYNTAX:SEMANTIC}• SYNTAX 模式名称,模式文件中的第一列• SEMANTIC 匹配文件的字段名例如: %{IP:client}
logstash内置的一些正则表达式:
6、输出插件
7、条件判断

若有收获,就点个赞吧
0 人点赞
