向量的生成
用c()逐一放在一起
> c(1,2,3)[1] 1 2 3> c("a","b","c","d","e")[1] "a" "b" "c" "d" "e"
连续的数字用冒号“:”
> 1:5[1] 1 2 3 4 5
重复值用rep()函数
注意参数times和each的区别
> rep(c("a","b"), times = 3)[1] "a" "b" "a" "b" "a" "b"> rep(c("a","b"), each = 3)[1] "a" "a" "a" "b" "b" "b"
等差序列用seq()函数
参数from,to,by可省略
> seq(from=1,to=100,by=5)[1] 1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96> seq(1,100,5)[1] 1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
随机数用rnorm()函数
生成随机数,mean默认为0,sd默认为1,可根据实际情况修改
> rnorm(n=5)[1] -0.1902086 -0.3159106 0.3200577 -1.3902890 0.8065010> rnorm(n=5,mean=100,sd=10)[1] 101.56500 99.52128 105.64515 77.00335 96.67940
通过组合产生更为复杂的向量
通过paste()和paste0()函数。区别在于:paste()中间间隔空格;paste0()默认直接相连
> paste(rep("sample",n=5),1:5)[1] "sample 1" "sample 2" "sample 3" "sample 4" "sample 5"> paste0(rep("sample",n=5),1:5)[1] "sample1" "sample2" "sample3" "sample4" "sample5"#修改方法如下:> paste(rep("sample",n=5),1:5,sep="-")[1] "sample-1" "sample-2" "sample-3" "sample-4" "sample-5"> paste(rep("sample",n=5),1:5,sep="")[1] "sample1" "sample2" "sample3" "sample4" "sample5"
对单个向量进行一些操作
简单的统计函数
> x = c(1,3,5,1)> x[1] 1 3 5 1> max(x) #最大值[1] 5> min(x) #最小值[1] 1> mean(x) #均值[1] 2.5> median(x) #中位数[1] 2> var(x) #方差[1] 3.666667> sd(x) #标准差[1] 1.914854> sum(x) #总和[1] 10
重要的常用统计函数
> length(x) #长度:向量里面元素的个数[1] 4> unique(x) #去重复[1] 1 3 5> duplicated(x) #对应元素是否重复[1] FALSE FALSE FALSE TRUE> table(x) #重复值统计x1 3 52 1 1> sort(x)[1] 1 1 3 5
对两个向量进行一些操作
逻辑比较
逻辑比较,生成等长的逻辑向量
> x = c(1,3,5,1)> y = c(3,2,5,6)> x == y #x对应位置与y中的值是否相等[1] FALSE FALSE TRUE FALSE> x %in% y #x的每个元素在y中存在吗[1] FALSE TRUE TRUE FALSE
数学计算
简单加减乘除运算
> x + y[1] 4 5 10 7
连接
paste()/paste0()函数
> paste(x,y,sep=",")[1] "1,3" "3,2" "5,5" "1,6"
交集、并集、补集
> intersect(x,y)[1] 3 5> union(x,y)[1] 1 3 5 2 6> setdiff(x,y)[1] 1> setdiff(y,x)[1] 2 6
两向量长度不一致
循环补齐:短的向量自动补齐至长的向量,并进行比较
> x = c(1,3,5,6,2)> y = c(3,2,5)> x == y # 啊!warning![1] FALSE FALSE TRUE FALSE TRUEWarning message:In x == y : longer object length is not a multiple of shorter object length
向量取子集
根据逻辑值取子集
> x <- 8:12> #根据逻辑值取子集> x[x==10][1] 10> x[x<12][1] 8 9 10 11> x[x %in% c(9,13)][1] 9
根据位置取子集
> #根据位置取子集> x[4][1] 11> x[2:4][1] 9 10 11> x[c(1,5)][1] 8 12> x[-4][1] 8 9 10 12> x[-(2:4)][1] 8 12
修改向量中的某个/某些元素
改一个元素
> x <- 8:12> x[1] 8 9 10 11 12> x[4] <- 40> x[1] 8 9 10 40 12
改多个元素
> x[1] 8 9 10 40 12> x[c(1,5)] <- c(80,20)> x[1] 80 9 10 40 20
简单的向量作图
> k1 = rnorm(12);k1[1] -1.1376829 1.2146663 -1.5720444 0.4155029 0.1068474[6] 0.1332813 -0.1999525 0.3122200 0.4607502 0.5994738[11] 0.1071601 -0.5560571> k2 = rep(c("a","b","c","d"),each = 3);k2[1] "a" "a" "a" "b" "b" "b" "c" "c" "c" "d" "d" "d"> plot(k1)> boxplot(k1~k2)
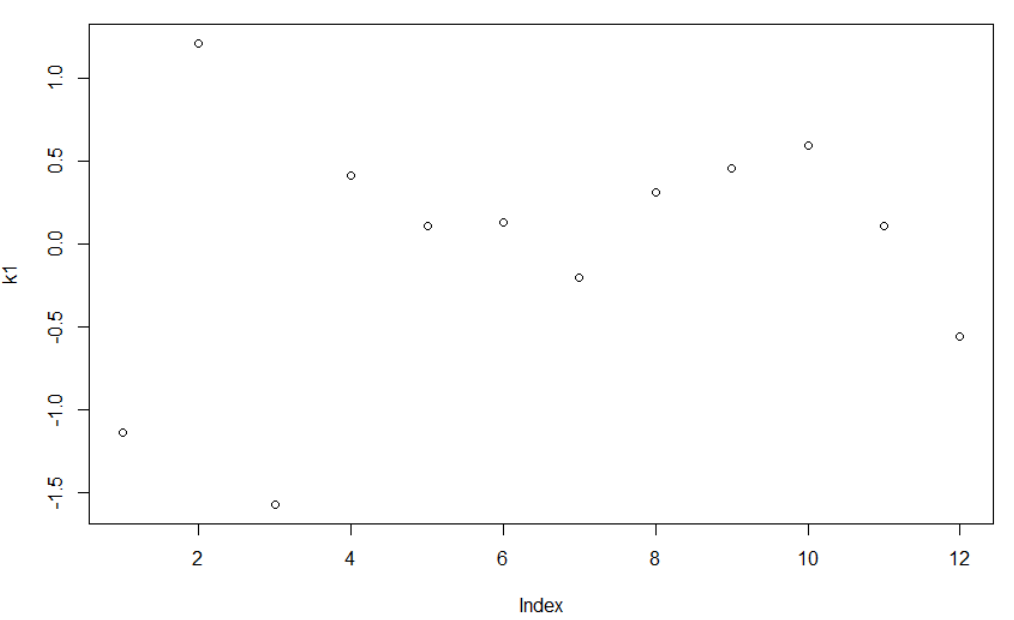
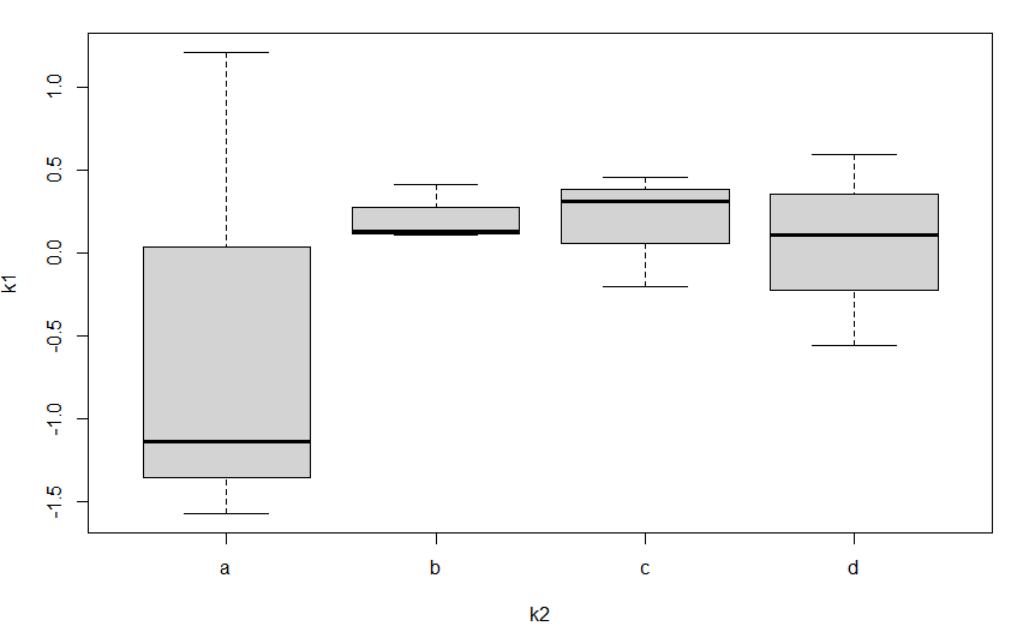
order()与match()函数的区别
order()函数返回sort函数排序后的下标
kids = c("jimmy","nicker","lucy","doodle","tony")> scores = c(100,59,73,95,45)> sort(scores)[1] 45 59 73 95 100> order(scores)[1] 5 2 3 4 1> kids[order(scores)][1] "tony" "nicker" "lucy" "doodle" "jimmy"
match()函数考察向量的元素在另一向量中的位次
> x <- c("A","B","C","D","E")> x[c(2, 4, 5, 1, 3)][1] "B" "D" "E" "A" "C"> y <- c("B","D","E","A","C")> match(y,x)[1] 2 4 5 1 3> x[match(y,x)][1] "B" "D" "E" "A" "C"

若有收获,就点个赞吧
0 人点赞
