也被称为gawk,是一门编程语言,可以对文本和数据进行处理。
格式
awk** [options] ‘{script}’ file
awk:命令
[options]:参数名,-F常用
‘{script}’:命令名,分为基础结构、匹配结构、扩展结构
file:文件名**
常见参数
-F:field,可以自定义字段的分隔符
-v:var=value,定义awk程序中的一个变量及其默认值
‘{script}’
命令名,分为基础结构、匹配结构、扩展结构。
{script} 内需要输入打印的行数,$0代表整个文本行;$1代表第一个字段;$NF代表最后一个字段。
awk命令默认的字段分隔符是空白字符(如空格或者制表符),也可以用-F 自定义分隔符。
基础结构
格式
常见用法
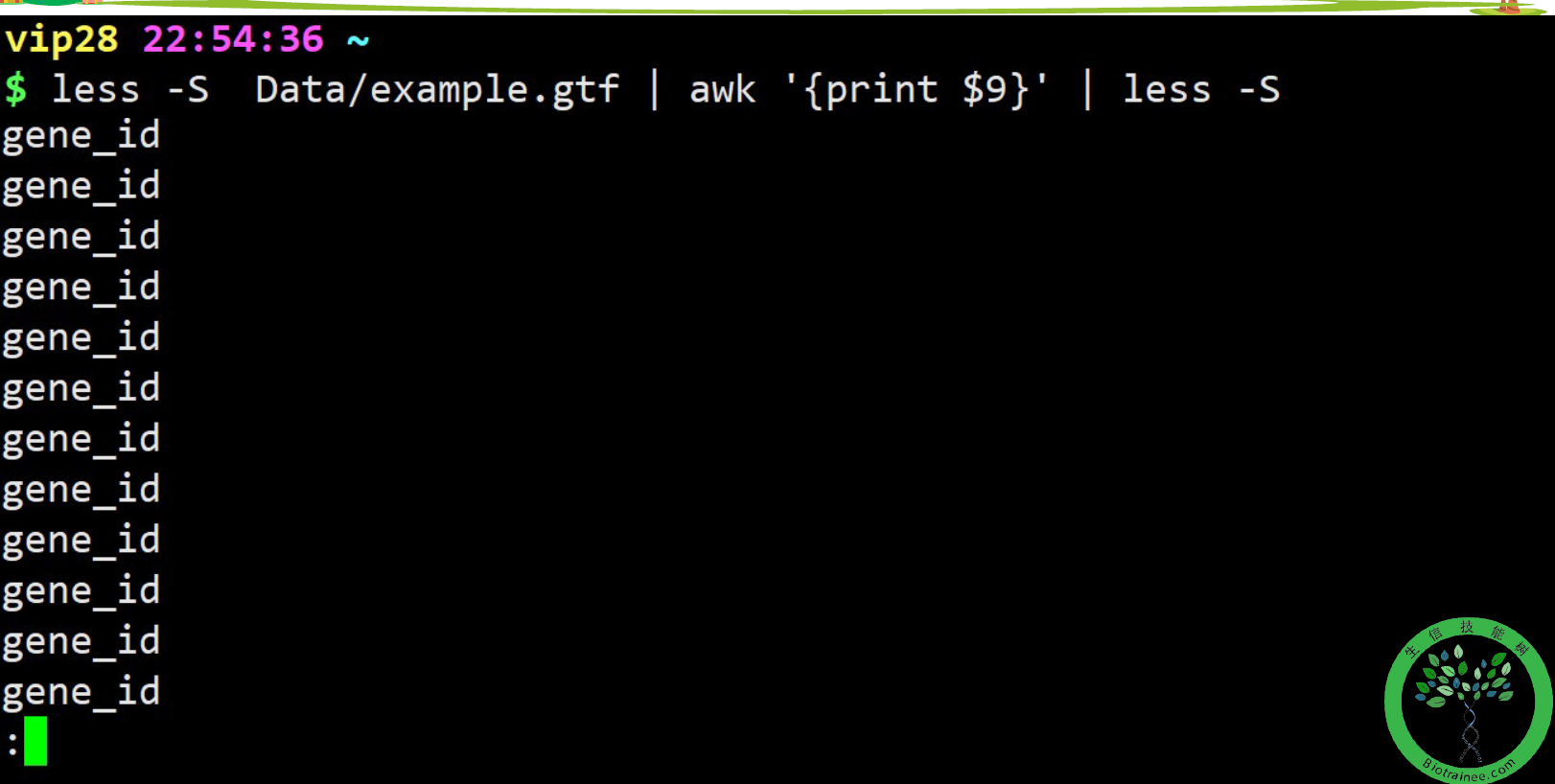
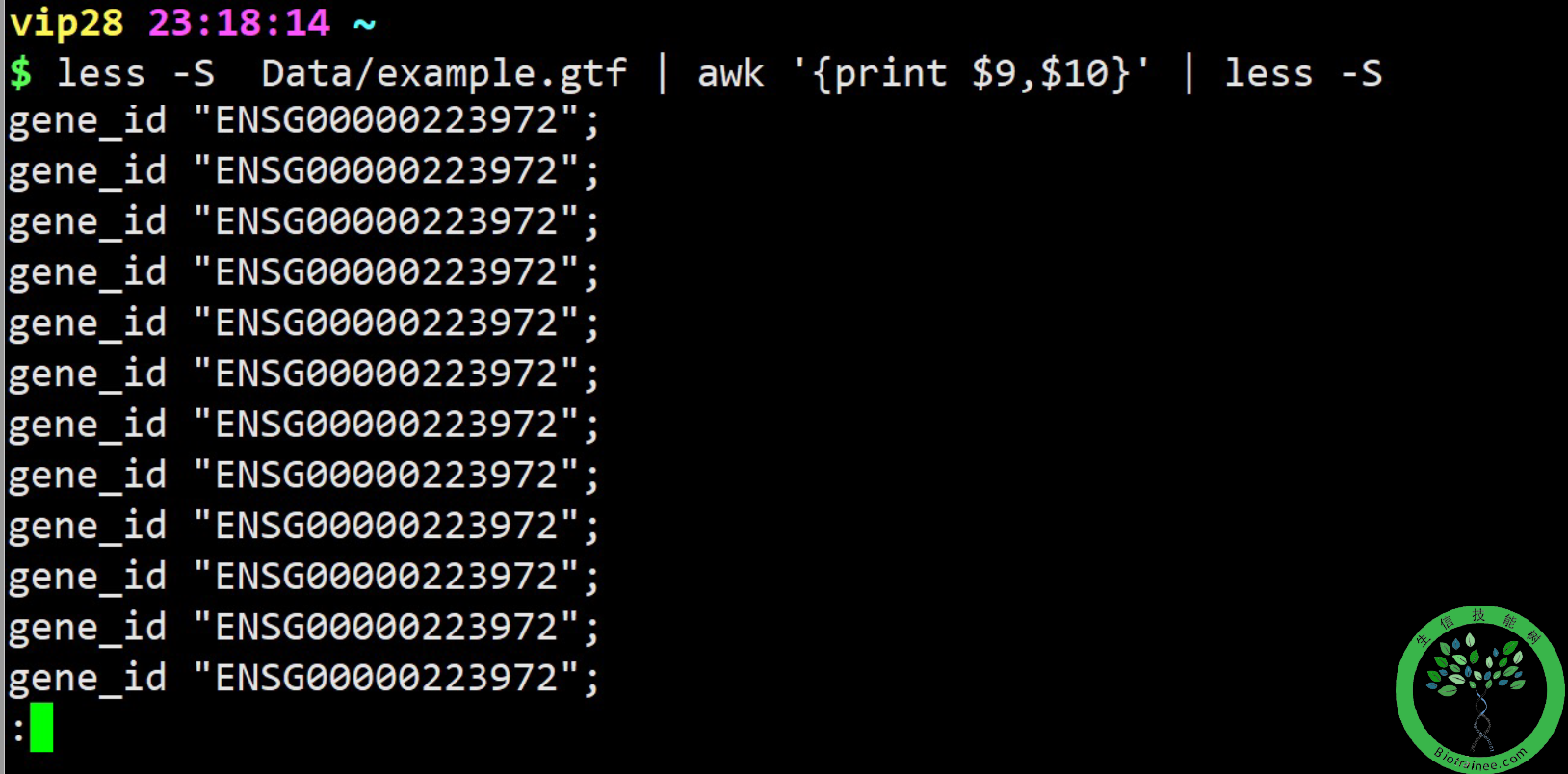
awk -F ' ' {print $6} file1## 截取file1文件中的第6列。
匹配结构
格式
常见用法
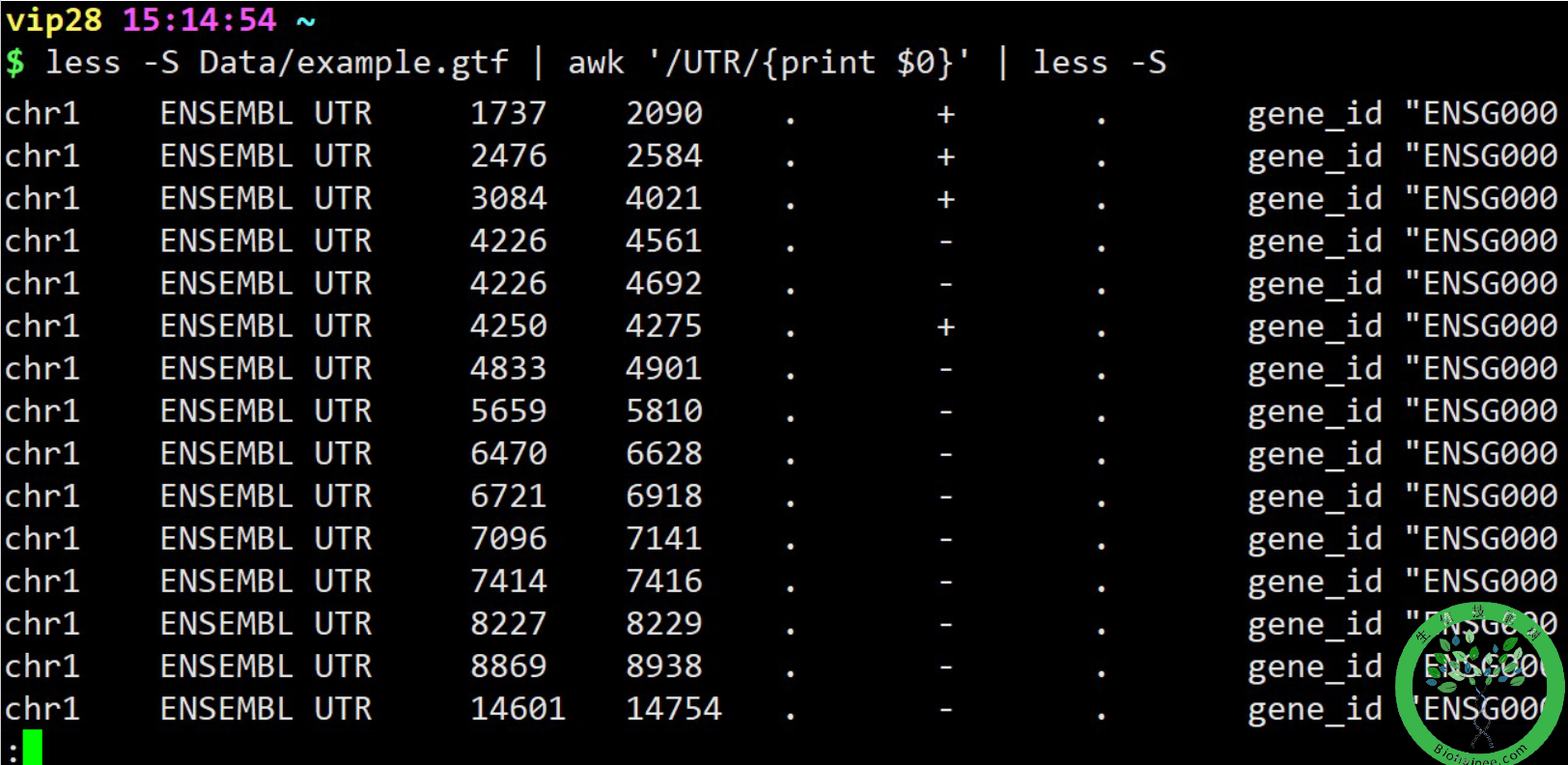
awk -F ' ' {/UTR/{print $0}} file2## 以空格为分隔符,匹配file2中存在UTR的行,输出该行
拓展结构
用来匹配匹配数据中的某一行,用来输出某一列。并添加表头,分隔符,行号等等。
格式
‘**BEGIN{script} {script} END**{script}’
常见用法
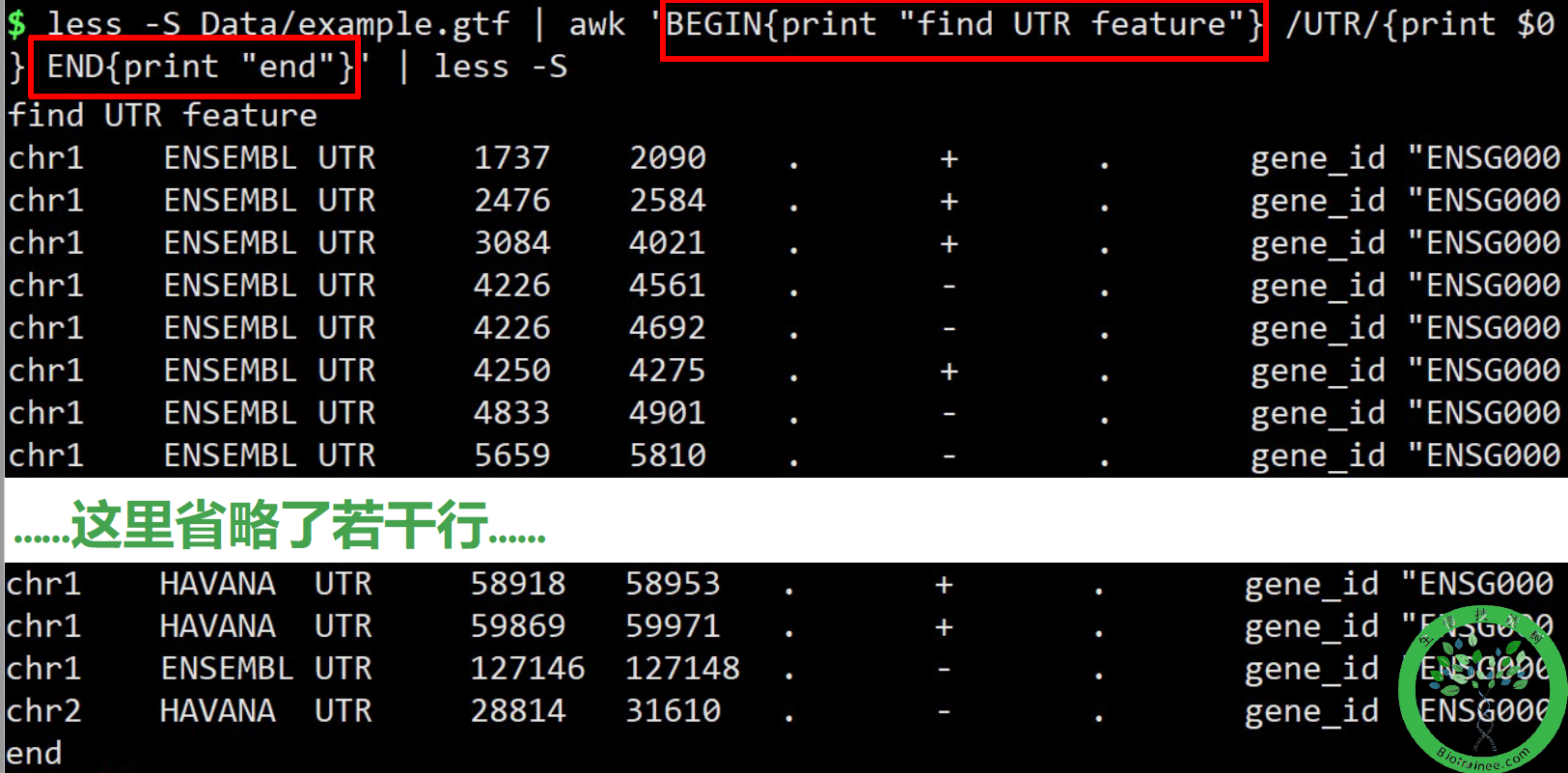
awk -F ' ' 'BEGIN{print "find UTR feature:"} /UTR/{print $9} END{print "end"}' file3## 匹配file3中的存在UTR的行,并打印出第9列(以空格为分隔符),并在前面输出find UTR feature ,在最后输出end
内置变量
FS :定义输入字段的分隔符,同-FRS :定义输入记录的分隔符OFS :定义输出字段的分隔符(常用)ORS :定义输出记录的分隔符NF :列数NR :行数
定义输入字段的分隔符
awk 'BEGIN{FS="\t"} {print $3,$4,$5}' file4 | head -5## 定义输入的字段分隔符为制表符,同-F
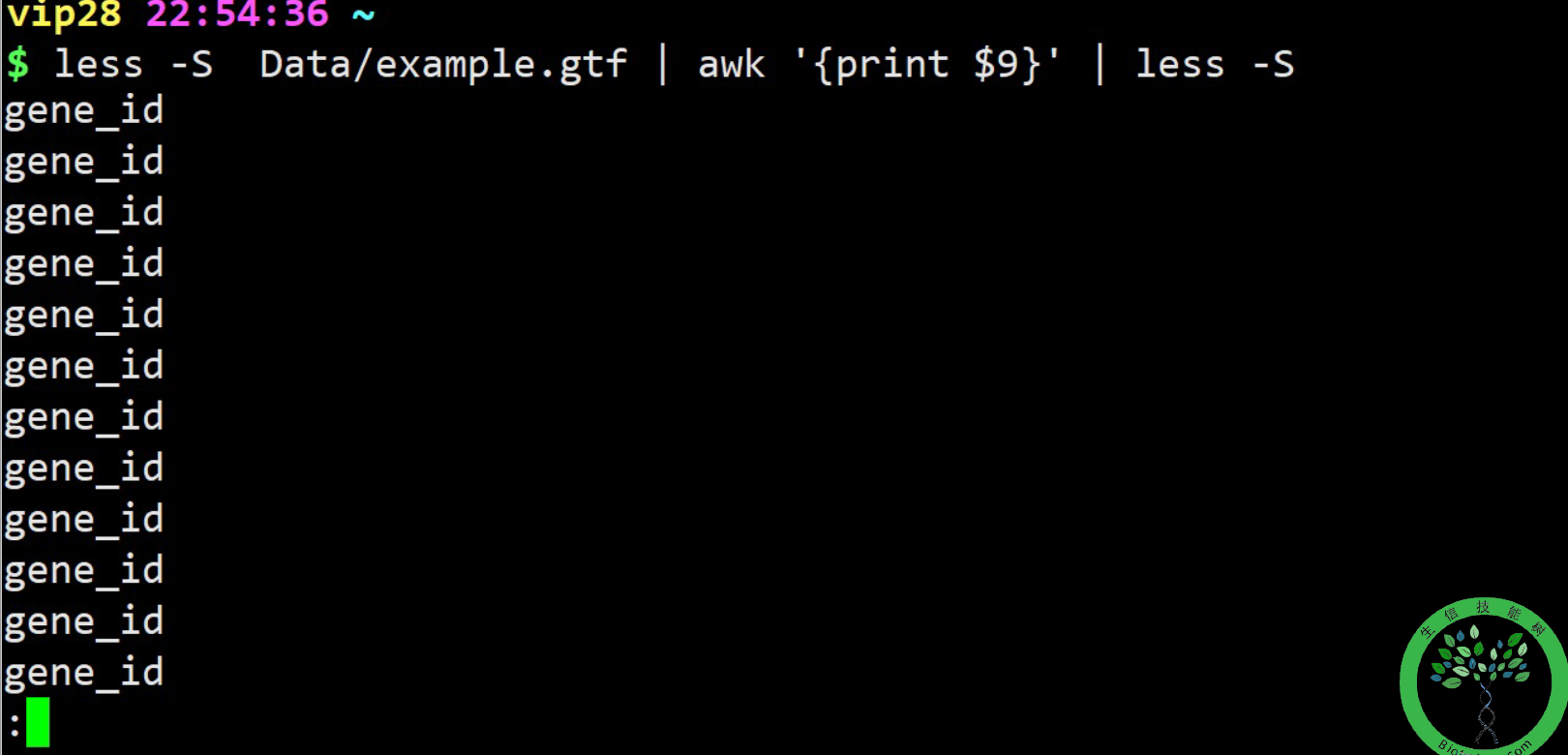
定义输出字段的分隔符
awk 'BEGIN{OFS=":"} {print $3,$4,$5}' file4 | head -5## 定义输出的字段分隔符为:
打印行号
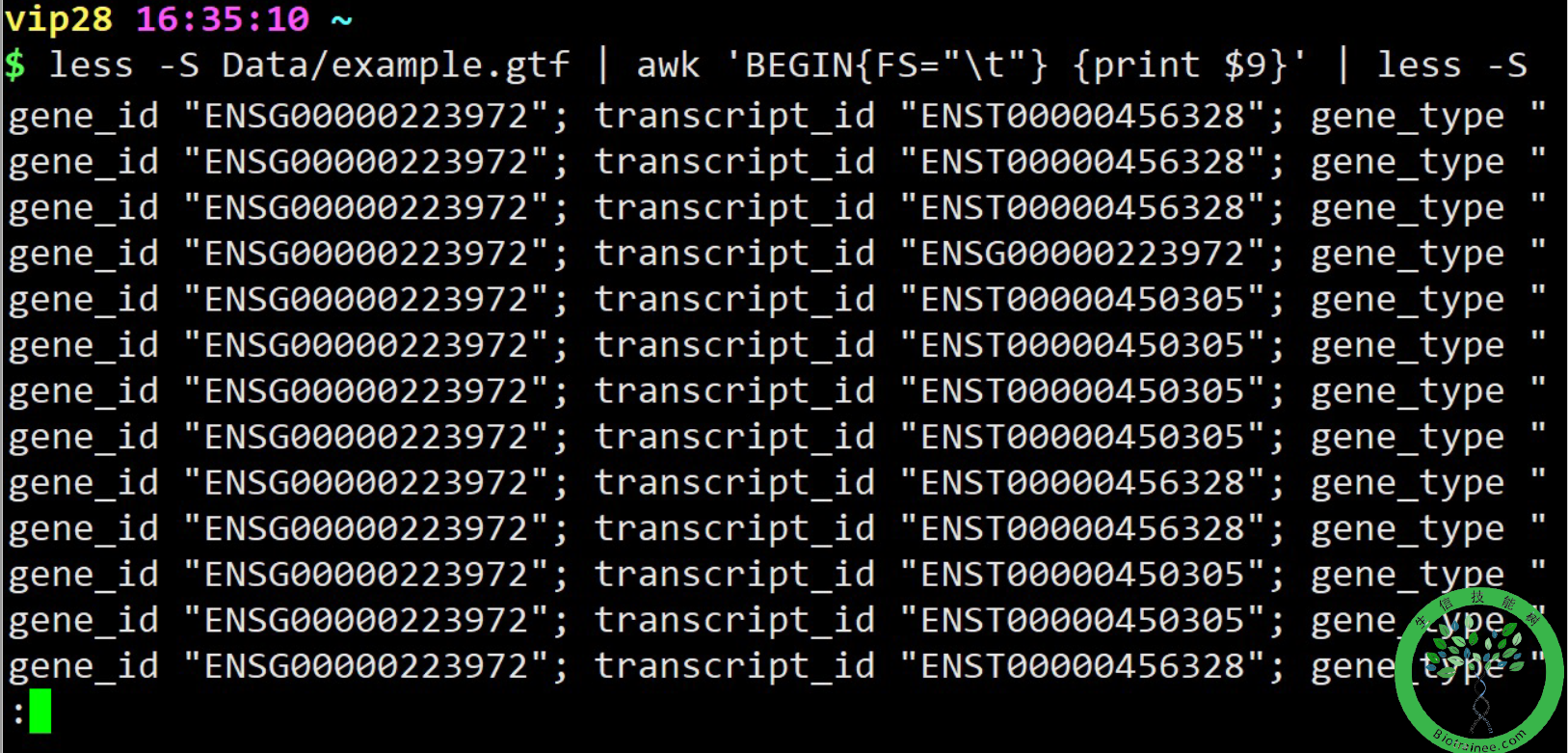
awk 'BEGIN{FS="\t"} {print NF, $9}' file4 | head -5## 定义输入字段的分隔符为制表符,输出第九列并打印行号
进阶用法
条件语句(if语句)
格式
awk ‘{**if(判断条件) {yes} else {no}}’
判断条件为真,则运行{yes},反之,则运行**{no}
用法
awk '{if($3=="gene") {print $0} eles {print $3 "is not gene"}}' file6## 在file6中区第三列,判断是否为“gene”## 若真,则输出这一行## 若假,则输出$3 is not gene 这句话
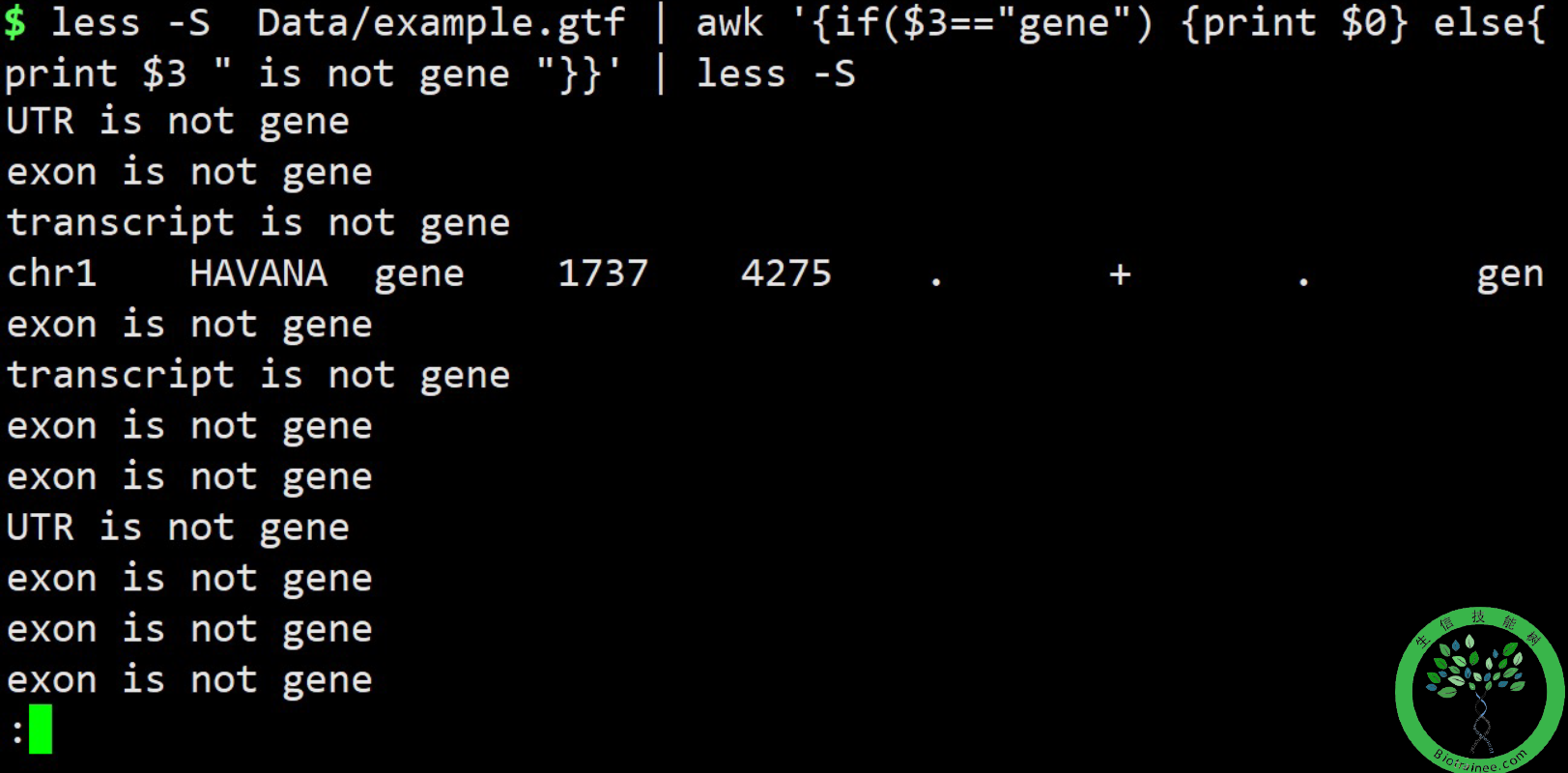
循环语句(for语句)
格式
awk ‘{**for(判断条件) {循环语句}}’
判断条件为真,则运行{循环语句},反之,则终止循环。**
用法
awk '{for(i=1;i<4;i++) {print $i}}' file7## 对file7中的每一行做循环,取前三列
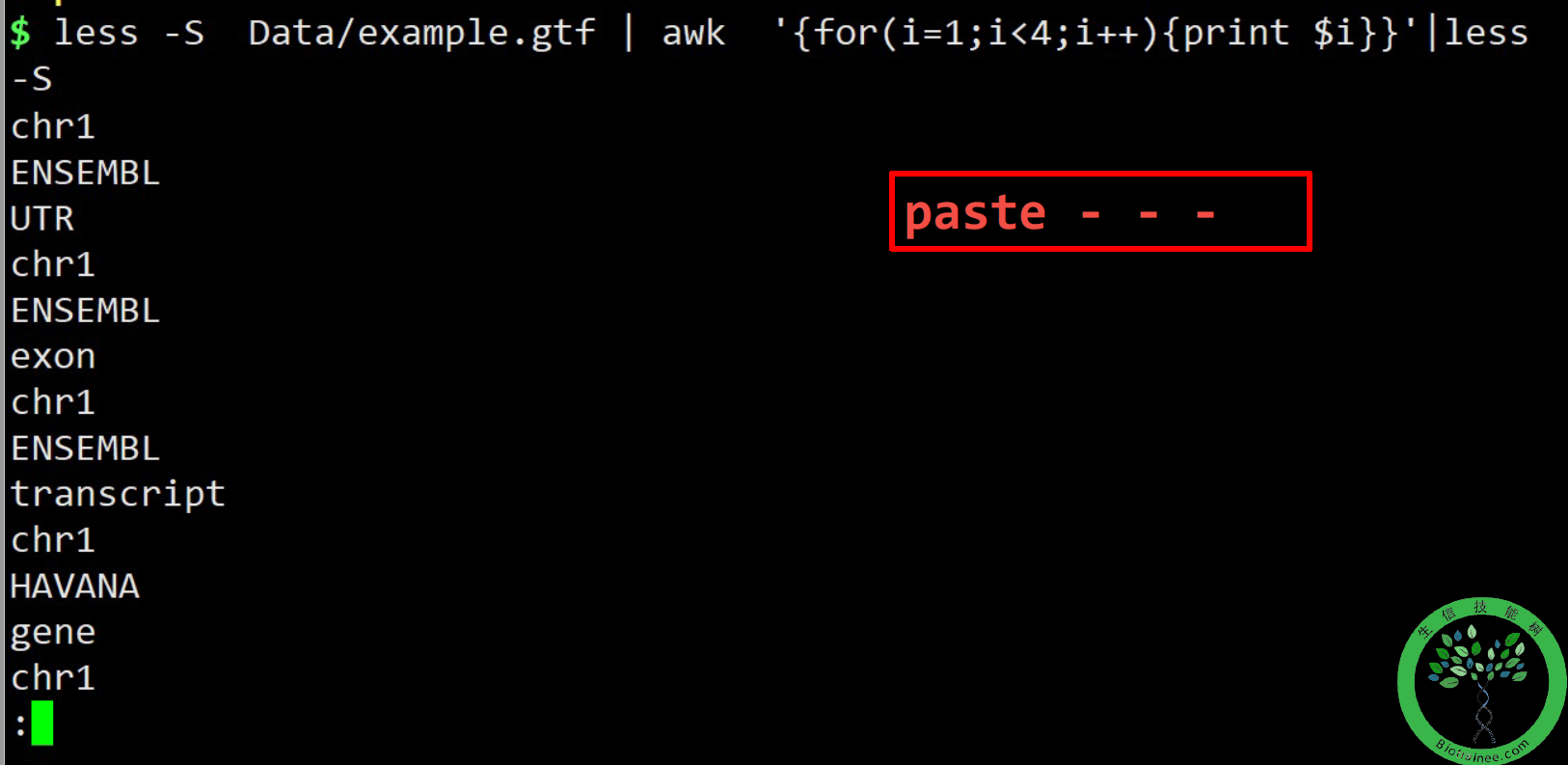
连接语句(paste语句)
格式
paste** **- - - -
将几行粘贴在一起;示例为4行
数学运算
格式
常见命令
+、-、、^(幂)、/
*(平方)%(取余)
int(x)(取整) log(x)(取log)
用法
awk '/exon/{print $5-$4}' file8## 在file8文件中匹配存在exon的行,输出$5-$4的值,本例是看exon的长度

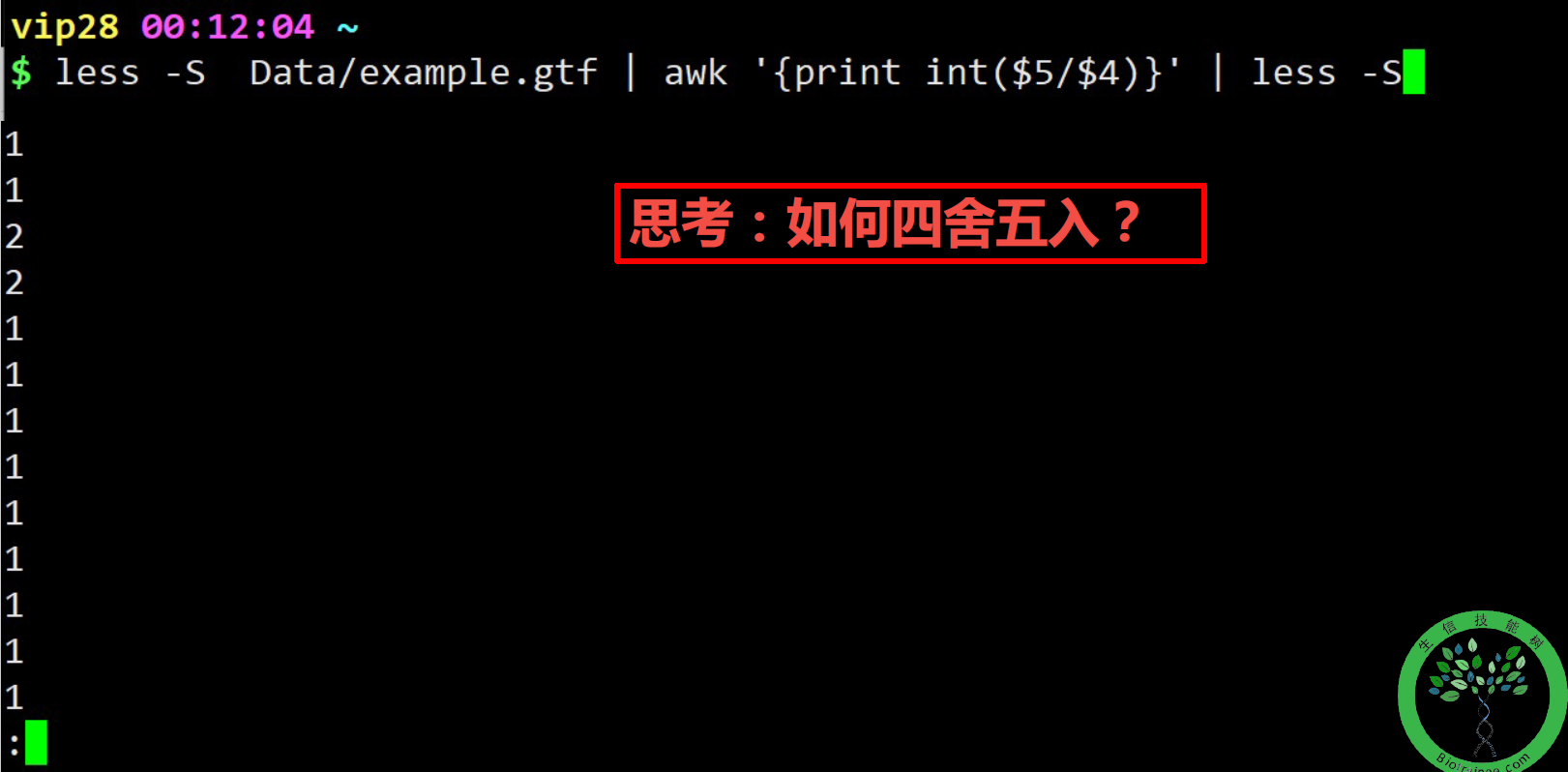
(+0.5后取整)

若有收获,就点个赞吧
0 人点赞
