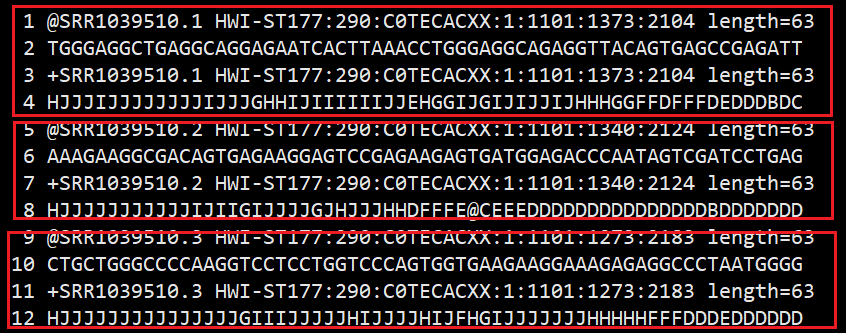
fastq格式
高通量测序(如llumina NovaSeq等测序平台)得到的原始图像数据文件。
经碱基识别(Base Calling)分析转化为原始测序序列(Sequenced Reads),称为Raw Data或Raw Reads,结果以FASTQ(简称为fq)文件格式存储,其中包含测序序列(Reads)的序列信息以及其对应的测序质量信息。
FASTQ格式文件中每个Read由四行描述:
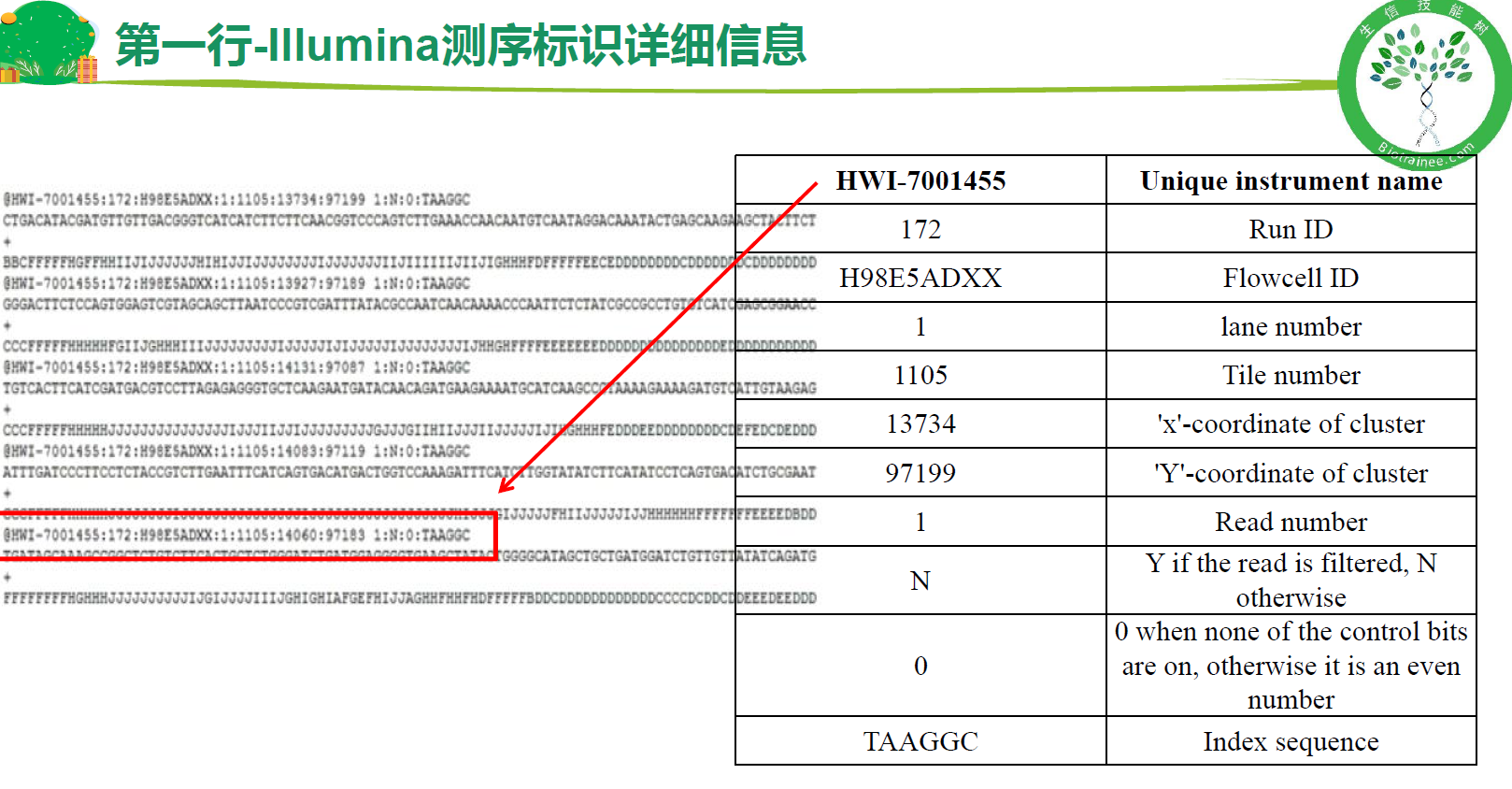
- 以“@”开头,随后为llumina测序识别符(Sequence Identifiers)和描述文字(选择性部分)。
- 碱基序列。
- 以“+”开头,随后为lllumina测序识别符(选择性部分)。
- 对应序列的测序质量的ASCII码。
测序标识
碱基质量
碱基质量值
碱基质量值(Quality Score或Q-score)是碱基识别(Base Calling)出错的概率的整数映射。通常使用的碱基质量值Q公式为: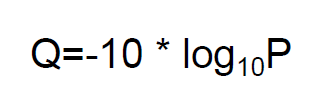
其中P为碱基识别出错的概率。下表给出了碱基质量值与碱基识别出错的概率的对应关系:
碱基质量值越高表明碱基识别越可靠,准确度越高。比如,对于碱基质量值为Q20的碱基识别,100个碱基中有1个会识别出错,以此类推。
ASCII码表
为了使得单一字符对应单一数字,利用ASCII码表,引入Phred值。即 Q+Pherd = ASCII表中该符号对应的数字。常见的Phred值为33或64。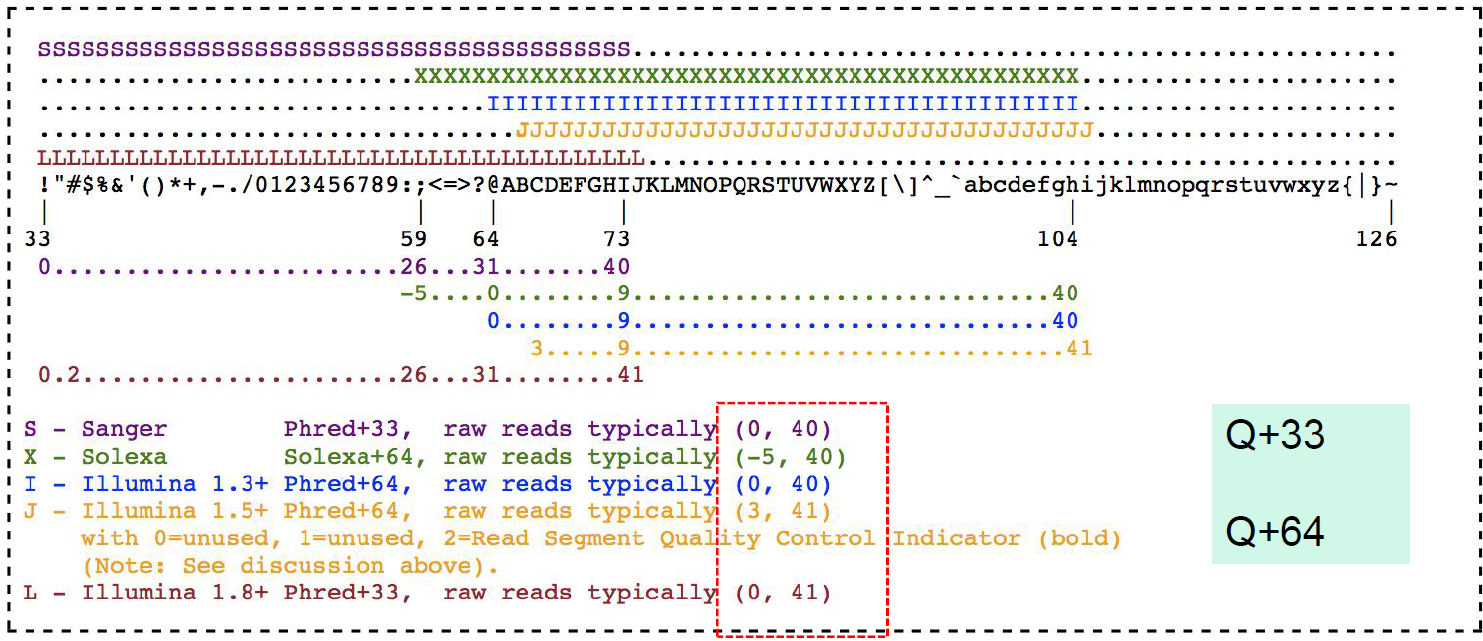
练习
题目

答案
zcat SRR1039510_1.fastq.gz | grep '@SRR' | wc -l ## 1zcat SRR1039510_1.fastq.gz | grep '@SRR' | less -SN ## 2zcat SRR1039510_1.fastq.gz | awk 'NR%4==2{print $0}' | less -SN ## 3zless -S SRR1039510_1.fastq.gz |awk '{ if(NR%4==2){print} }' | awk 'BEGIN {num=0} {num=num+length($0)} END{ print "num="num}'

若有收获,就点个赞吧
0 人点赞
