- DB-GPT是什么? 它的诞生是基于什么背景?为什么会做这么一款产品?">DB-GPT是什么? 它的诞生是基于什么背景?为什么会做这么一款产品?
- DB-GPT解决了用户哪些核心痛点?它强调的核心价值理念是什么?">DB-GPT解决了用户哪些核心痛点?它强调的核心价值理念是什么?
- DB-GPT 0.6.0 大版本有什么重磅功能?有哪些相较竞品的突破式创新?能详细展开论述吗?">DB-GPT 0.6.0 大版本有什么重磅功能?有哪些相较竞品的突破式创新?能详细展开论述吗?
- DB-GPT 有哪些客户在使用?他们使用的场景是什么?">DB-GPT 有哪些客户在使用?他们使用的场景是什么?
- DB-GPT我们都说是一款「社区驱动」的产品,如何理解,你们是如何激发社区创作的?">DB-GPT我们都说是一款「社区驱动」的产品,如何理解,你们是如何激发社区创作的?
DB-GPT是什么? 它的诞生是基于什么背景?为什么会做这么一款产品?
DB-GPT是一个开源的AI原生数据应用开发框架,目的是构建大模型领域的数据基础设施,目前已支持数十家企业的生产级应用落地, 服务社区数万开发者。 DB-GPT诞生于23年4月份,当时因为ChatGPT的发布,以及LLaMA模型的开源,我们看到AI领域大量的开源项目如雨后春笋般喷涌而出。同时作为数据领域的从业者,我们看到数据领域的一些前沿发展方向, 如向量数据库需求的爆发、LLM框架的出现(如llama-index、Langchain等)、LLM+SQL实现Text2SQL、LLM+Tools实现任务自动完成等。 同时大模型带来的通过自然语言对话来实现任务交付的交互方式变革也影响着各行各业。 彼时,数据领域还没有一款产品可以实现数据对话,但大家对数据对话式交互的诉求非常强烈,同时大家对数据安全的担忧,不愿意将数据上传到ChatGPT, 因此我们创建了DB-GPT项目,想通过私有化大模型技术来改变数据库的交互方式,让企业和开发者可以通过DB-GPT轻松构建自己的数据应用,实现数据对话。 随着大模型技术的持续发展, 结合数据库、数据与大模型的需求越来越强烈, 从早期结合大模型与数据库实现通过自然语言与数据库进行交互,再到围绕LLM+Data与Text2SQL、RAG等技术构建ChatData的能力,包括知识库、数据对话与分析、Excel对话与分析等。一直演变到最近的围绕Data+AI+X 的原生数据智能应用构建范式。这个领域的需求越来越迫切,大家也对大模型时代的智能应用构建有了进一步的认识,既从以写代码为主的开发范式逐渐演变为以处理数据为核心的开发范式。 DB-GPT围绕大模型提供了灵活、可拓展的AI原生数据应用管理与开发能力,我们希望通过DB-GPT构建的AI原生数据应用框架能力,帮助企业构建、部署智能AI数据应用,通过智能数据分析、洞察、决策,实现企业数字化转型与业务增长。
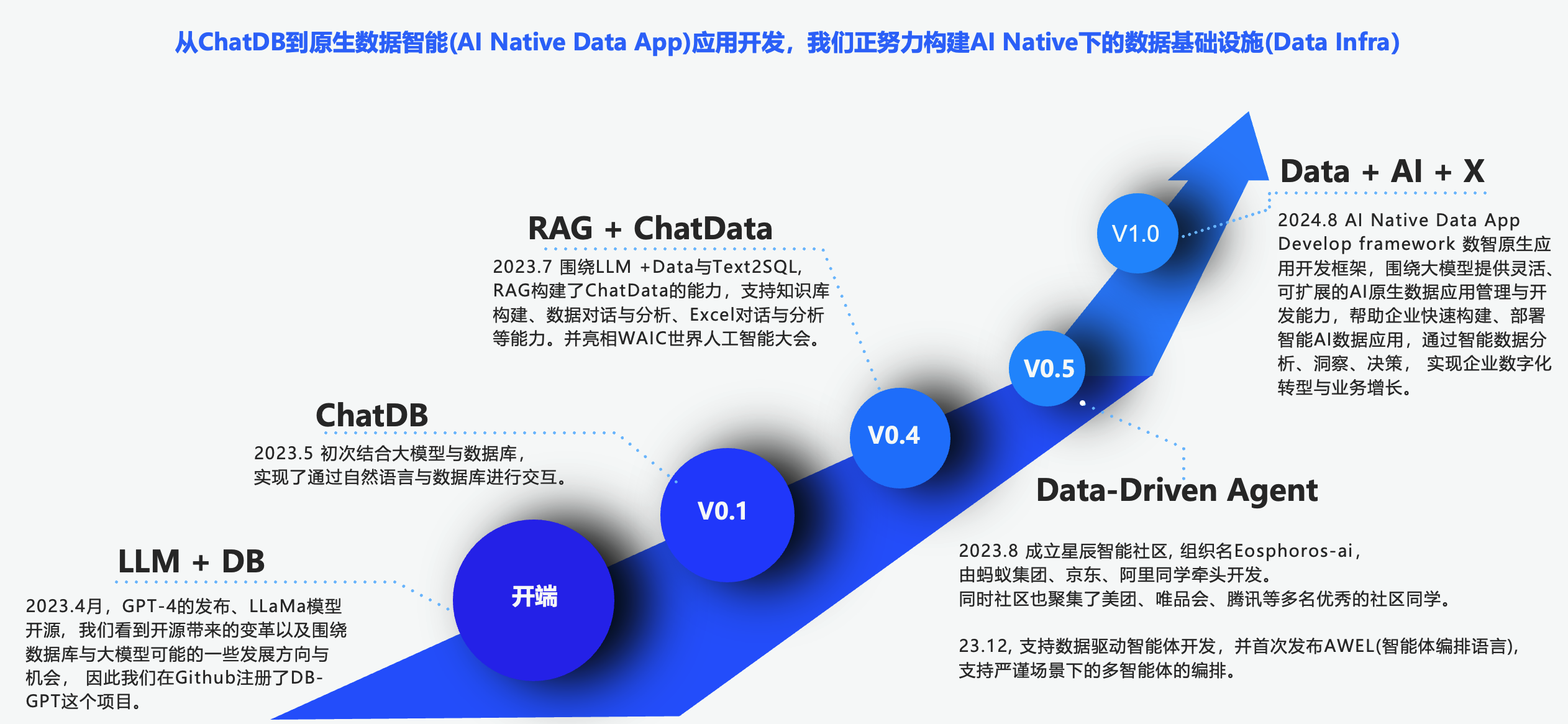
DB-GPT解决了用户哪些核心痛点?它强调的核心价值理念是什么?
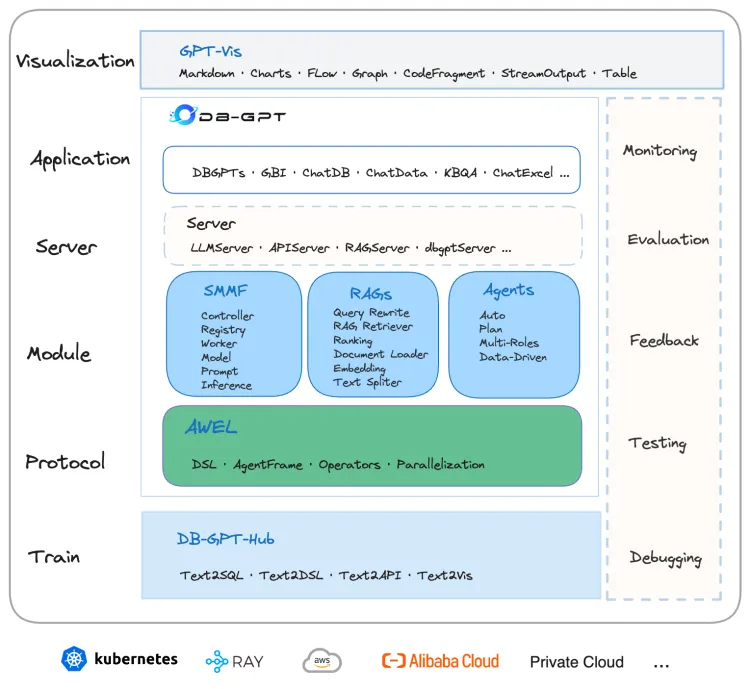
DB-GPT围绕大模型与数据基础设施构建了一套端到端AI Native Data App构建的能力,包含丰富的模块如多模型服务管理与推理、Text2SQL微调与效果优化、RAG增强检索与知识构建、Multi-Agent多智能体协作、AWEL(智能体工作流编排)等多种技术能力,让AI原生数据应用构建更简单、方便。 数据3.0时代,基于模型、数据库、知识库,企业/开发者可以用更少的代码搭建自己的AI原生智能数据应用。 核心价值理念: 数据3.0时代,DB-GPT围绕大模型提供灵活、可扩展的AI原生数据应用管理与开发能力,帮助企业快速构建、部署智能AI数据应用,通过智能数据分析、洞察、决策, 实现企业数字化转型与业务增长。
- 支持AI原生数据应用的管理与开发
- 灵活的智能体工作流编排(AWEL)
- 面向服务的多模型管理,部署,支持海量模型
- 完备的数据驱动Agents模块
- 丰富的RAG检索能力
- 丰富的可视化协议
- 多数据源管理与生成式BI分析
- 支持私有化部署
DB-GPT 0.6.0 大版本有什么重磅功能?有哪些相较竞品的突破式创新?能详细展开论述吗?
经过一段时间的努力研发,DB-GPT V0.6.0要跟大家见面了,在V0.6.0版本,我们提供了丰富的新特性, 如:- AWEL协议升级2.0, 支持更复杂的编排
- 支持数据应用的创建与生命周期管理
- GraphRAG支持图社区摘要与混合检索,图索引成本相比Microsoft GraphRAG降低50%
- 支持丰富的Agent Memory,如感知记忆、短期记忆、长期记忆、混合记忆等
- 支持意图识别与Prompt管理
- GPT-Vis前端可视化升级, 支持更丰富的可视化图表
- 新增支持Text2NLU与Text2GQL微调
- AWEL协议描述: AWEL(Agentic Workflow Expression Language) 是一套专门为大模型应用开发设计的智能体工作流表达式语言,提供强大的功能和灵活性。通过AWEL API 开发者可以专注于大模型应用逻辑开发,不需要关注繁琐的模型、环境等细节。 在AWEL 2.0中,我们支持了更复杂的可视化


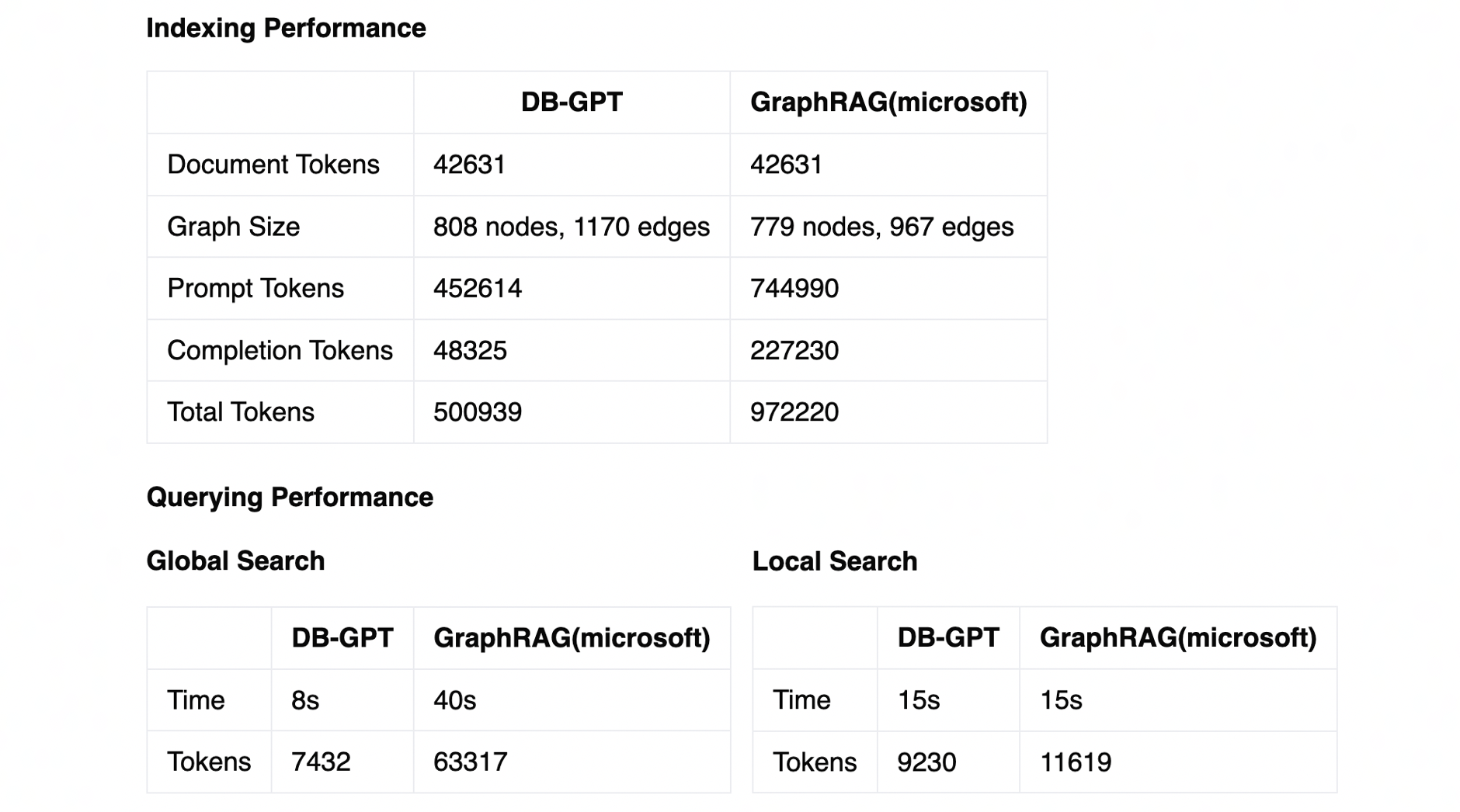
- GraphRAG:GraphRAG是基于知识图谱的增强检索生成系统,通过知识图谱构建与检索,进一步增强检索的准确率与召回的稳定性,降低大模型幻觉的同时,增强领域应用的效果。DB-GPT结合TuGraph,构建了高效的检索增强生成能力。


基于上述设计,我们采用了TuGraph社区提供的开源知识图谱语料(OSGraph)以及DB-GPT和TuGraph的产品介绍材料(共计约43k tokens),并与Microsoft的GraphRAG系统做了对比测试,最终DB-GPT仅消耗了相比50%的token开销,便生成了同等规模的知识图谱。并且在问答测试质量相当的前提下,全局搜索性能有明显提升。
最终生成的知识图谱我们采用AntV的G6引擎升级了前端渲染逻辑,可以直观地预览知识图谱数据和社区划分结果。

- Agent Memory: 支持了多种记忆类型,如感知记忆、短期记忆、长期记忆、混合记忆等。

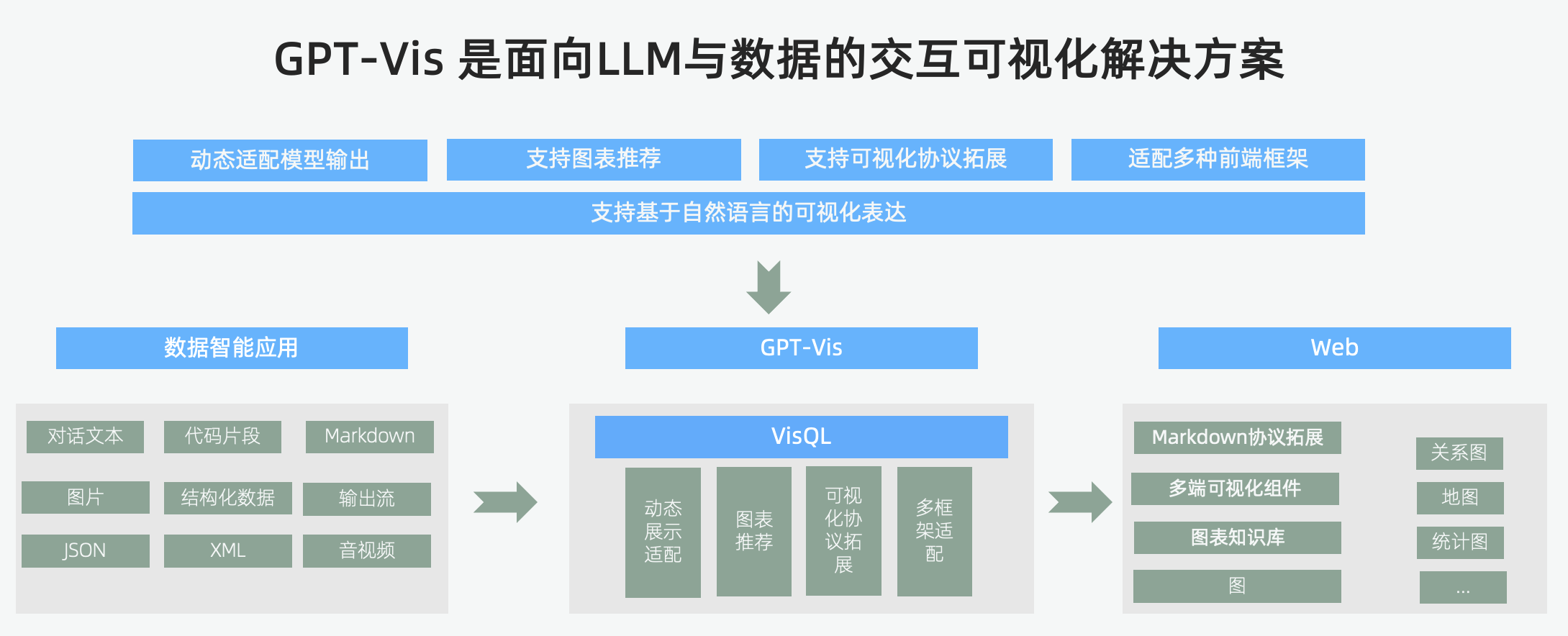
- GPT-Vis: GPT-Vis是面向LLM与数据的交互可视化解决方案,支持丰富的可视化图表展示与智能推荐。


- Text2GQL与Text2NLU微调: 新增支持了自然语言到图语言的微调,以及语义分类的微调。
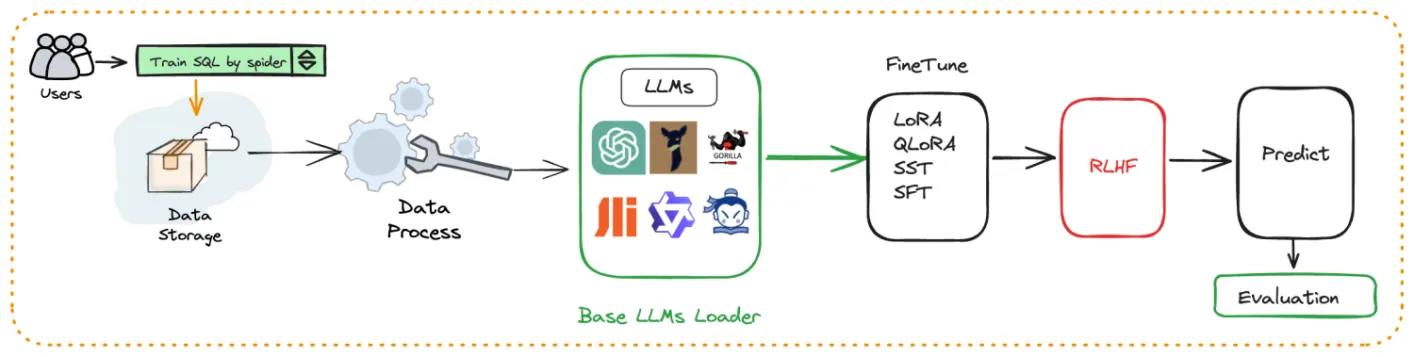
- 智能数据应用管理与构建: 支持智能数据应用的创建与生命周期管理,提供多种构建模式。1. 多智能体自动规划模式 2. 任务流编排模式 3. 单一智能体模式 4. 原生应用模式



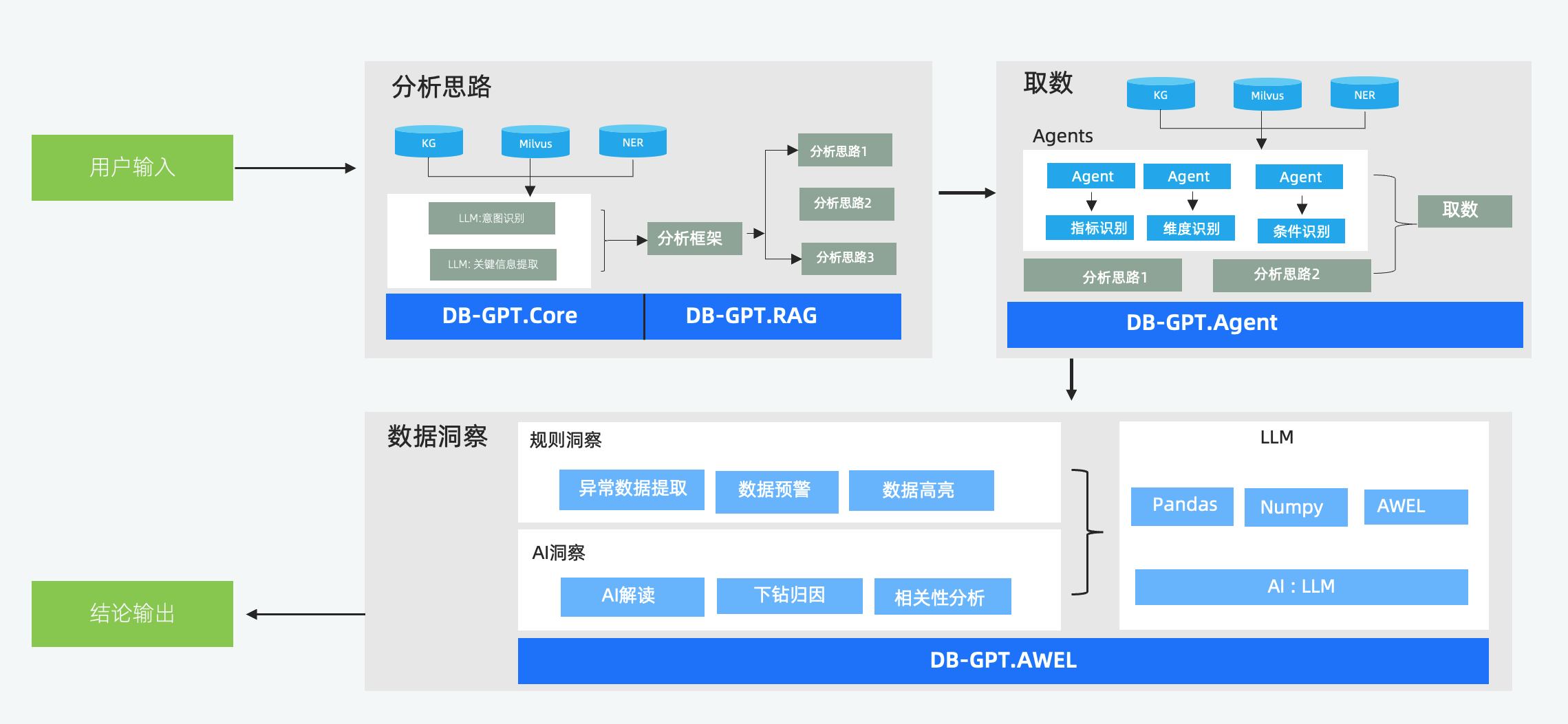
DB-GPT 有哪些客户在使用?他们使用的场景是什么?
DB-GPT目前服务了数万开发者,有数十家企业在使用。 包括我们的共建伙伴阿里、京东、美团、唯品会、深圳数联等。以及其他数十家客户都在应用我们的产品或基于我们产品做二次开发。 主要应用场景方面不同公司也各有侧重。如在蚂蚁主要用于: 数据基础设施智能专家,提供智能数据分析,数据基础设施日常运维、故障诊断与定位,SQL诊断与优化,智能答疑与处理等多种能力,助力业务数据基础设施智能化升级。 京东: 大数据平台智能助手,提供平台使用、日常问题解答和任务故障分析排查的智能数据运维能力,以及提供海量数据资产检索、SQL补全和SQL优化的智能数据开发能力,助力数据平台智能化升级。 武汉天河: 给武汉天河机场打造智能体中心,智能体场景包括机场集团人资管理助手,人资招聘助手,知识库问答,政策法规助手,报告生成助手。智能体场景通过自动化技术,覆盖从人力资源管理到报告生成的各个业务环节。系统能够自动执行日常任务,如员工管理、招聘流程、法规解读、知识库问答、以及报告生成,显著提高了运营效率,减少了人为干预的需求 唯品会: 数坊【数据开发平台】AI助手,提供平台FAQ、自然语言转Spark SQL、UDF、知识库、SPark SQL补全等功能,提升数据开发效率 深圳市数联天下: 大数据平台自助分析助手,提供平台使用、日常问题提供海量数据资产检索、生成数据卡片,拼接卡片生成数据报表。助力智能运营分析 上海X水务信息化公司: WI水务智能管家是基于DB-GPT扩展开发的智慧水务助手,利用AIAgent专为水务行业打造的垂直行业大模型应用;WI水务智能管家能够提供水务行业通用知识库、水务企业专有知识库,方便普通用户QA问答各种水务行业的专业知识;针对企业数据分析人员和企业管理人员WI水务智能管家能够提供客户服务、管网运行、水厂生产等各种应用场景的数据查询和数据分析能力,彻底改变软件交互方式,从而提高工作效率。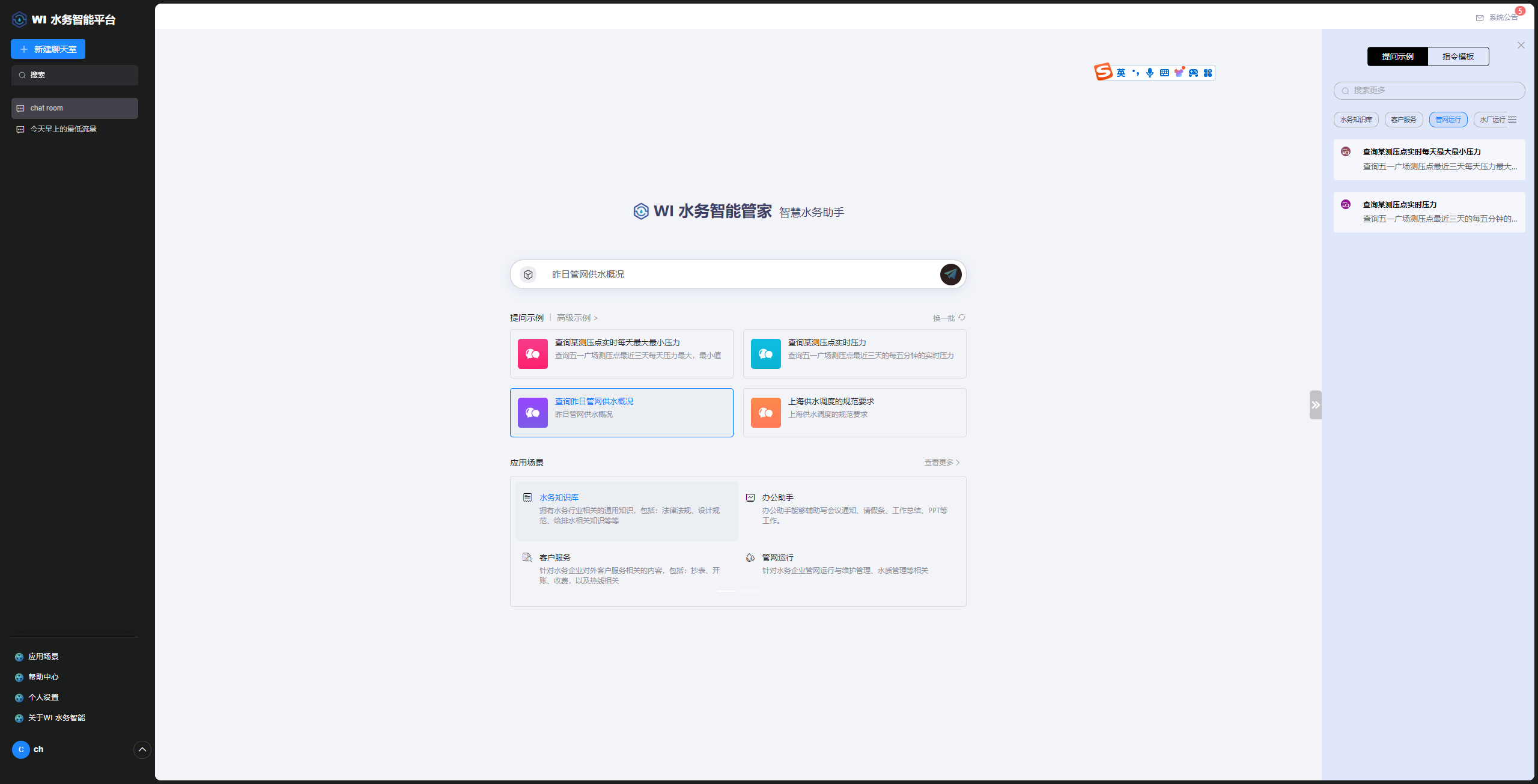
DB-GPT我们都说是一款「社区驱动」的产品,如何理解,你们是如何激发社区创作的?
- 首先Day One DB-GPT的诞生就是通过开源开始的,第一行代码就是提交在开源Github
- 其次我们的共建者来自不同的企业跟高校,大家之间有一个比较良好的社区共同讨论与决策机制,在很早期,我们就设立了社区的管理与协作机制。其中一期Maintainer成员: 陈发强、程方银、陈柯廷、杨宏俊、张志平、赵旺、张洪洋,有2/3同学属于蚂蚁外的社区同学。同时我们也随着社区的贡献来不断更新我们的贡献者。
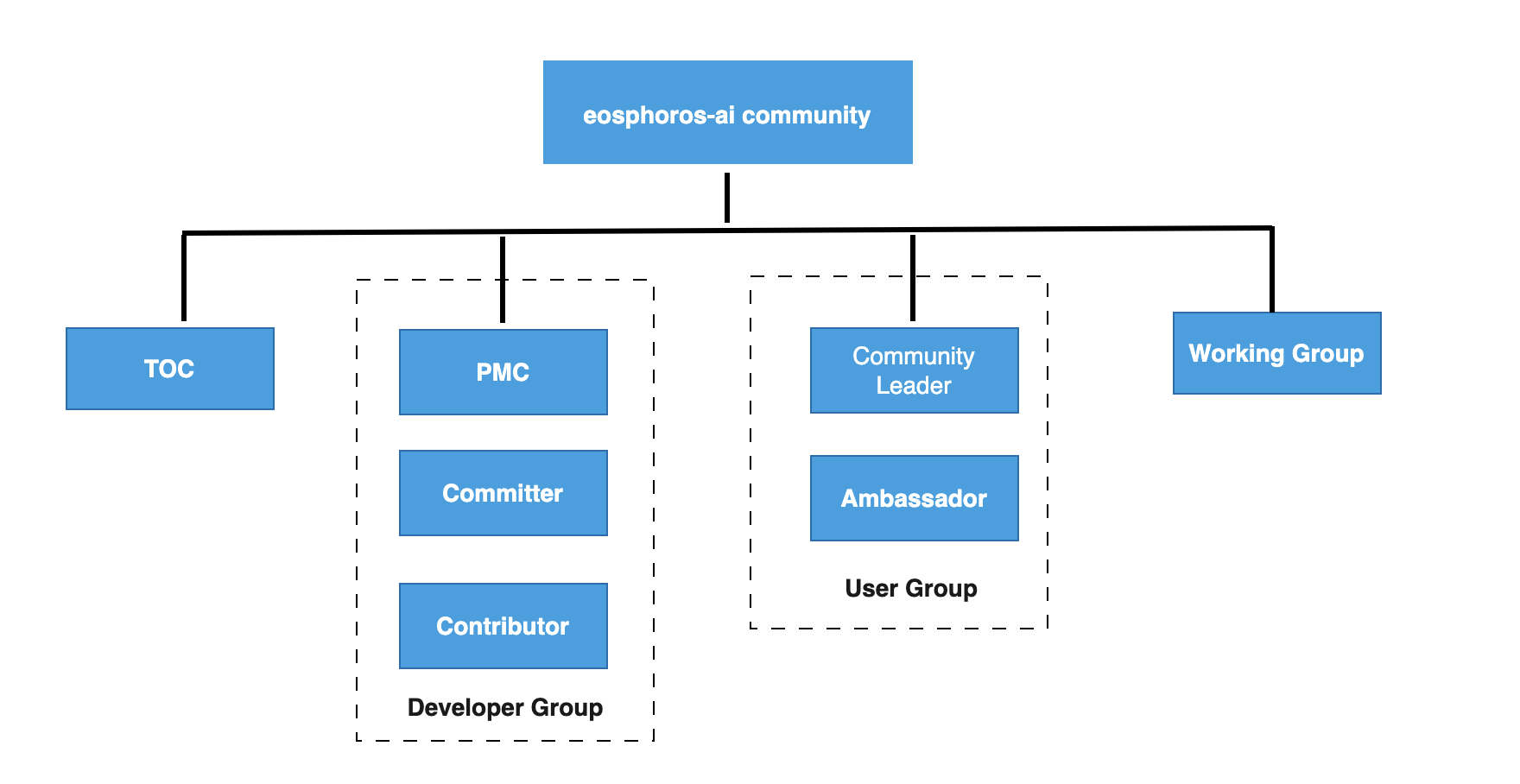
- 技术委员会(Technical Oversight Committee): 是eosphoros-ai 社区的技术管理机构,负责eosphoros-ai社区相关的技术类重大决议决策。
- PMC(Project Management Committee): 单个项目的项目管理委员会,为项目核心管理团队,参与Roadmap和本项目重大决策决议。
- Committer: 具有代码提交能力的开发者。
- Contributor: 曾参与过代码贡献的开发者。
- Community Leader: 社区用户布道师。
- Ambassador:帮助推广,使用,答疑的DB-GPT热心用户。
- Working Group:单个项目的工作组,主要负责单个项目的工作推进,社区开发者、用户发展。
- 参考最新的OSGraph项目社区图谱,分析参与的公司与国家也都非常分散,开发者来着全球数十个国家。DB-GPT社区图谱链接:https://osgraph.com/graphs/repo-community/github/eosphoros-ai/DB-GPT?country-limit=100&org-limit=100&contrib-limit=1

- 我们每一次的社区会议,都坚持开放,绝大多数参与者都来自社区。

最后, 我们也非常希望有更多有技术理想的同学一起加入我们。

若有收获,就点个赞吧
0 人点赞
