介绍
传统的Native RAG 的知识抽取准备过程,目的是将文档转向量并导入数据库的过程,包括读取非结构化文档 -> 知识切片 -> 文档切片转向量 -> 导入向量数据库。
适用场景
- 支持简单的智能问答场景,通过语义相似度召回上下文信息。
- 用户可以根据自身业务场景,对现有的Embedding加工流程进行裁剪和新增。
如何使用
- 进入AWEL界面并新增工作流
- 导入知识加工模版
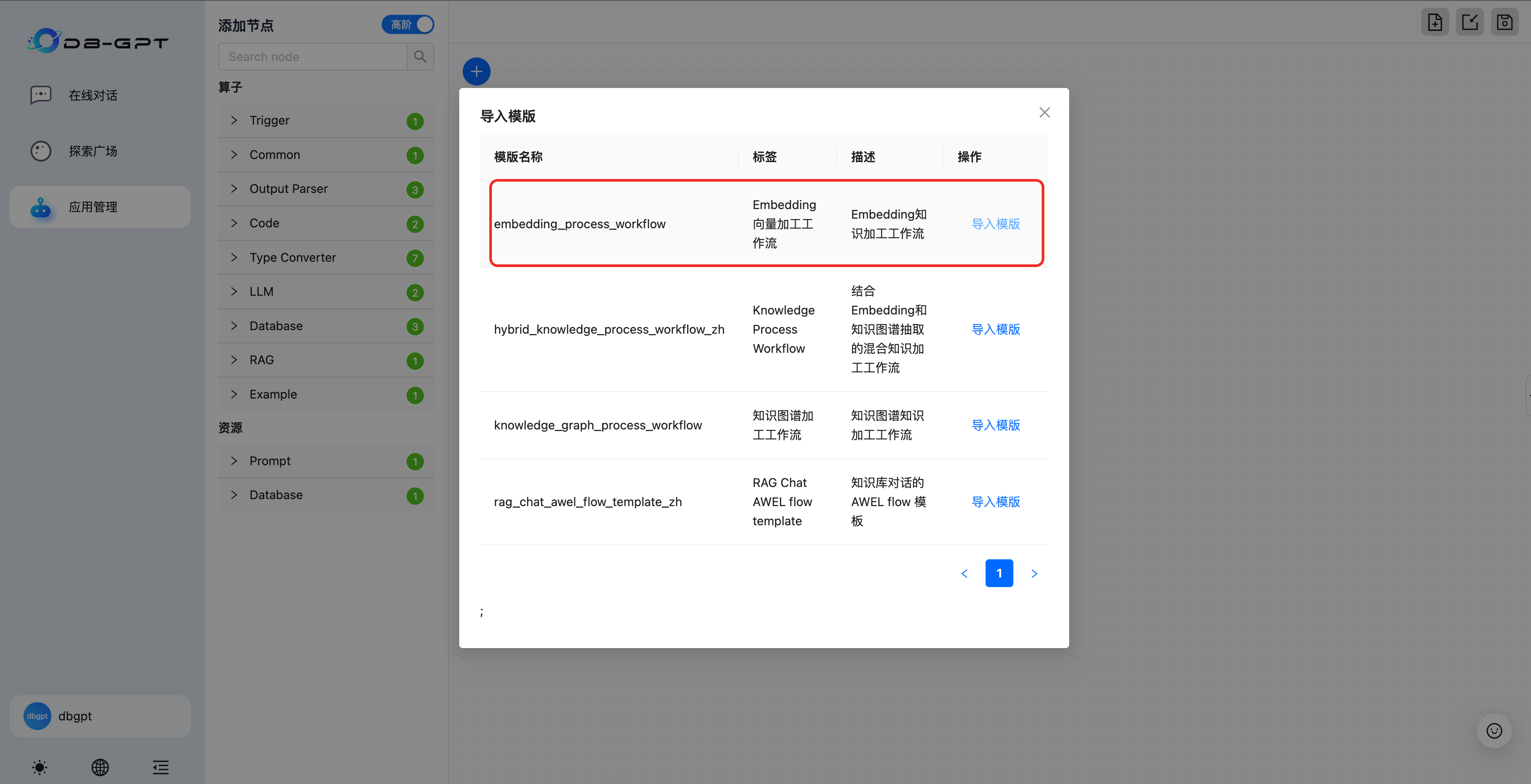
- 调整参数并保存

- `文档知识加载算子`: 知识加载工厂,通过加载指定的文档类型,找到对应的文档处理器进行文档内容解析。- `文档Chunk切片算子`:将加载好的文档内容按照指定的切片参数进行切片处理。- `向量存储加工算子`:可以连接不同的向量数据库进行向量存储,同时也可以连接不同的Embedding模型和服务进行向量抽取。- `结果聚合算子`:将向量抽取结果和知识图谱抽取结果进行汇总处理。
- 注册发布为http请求
curl --location --request POST 'http://localhost:5670/api/v1/awel/trigger/rag/knowledge/embedding/process' \--header 'Content-Type: application/json' \--data-raw '{}'
[{"content": "\"What is AWEL?\": Agentic Workflow Expression Language(AWEL) is a set of intelligent agent workflow expression language specially designed for large model application\ndevelopment. It provides great functionality and flexibility. Through the AWEL API, you can focus on the development of business logic for LLMs applications\nwithout paying attention to cumbersome model and environment details. \nAWEL adopts a layered API design. AWEL's layered API design architecture is shown in the figure below. \n<p align=\"left\">\n<img src={'/img/awel.png'} width=\"480px\"/>\n</p>","metadata": {"Header1": "What is AWEL?","source": "../../docs/docs/awel/awel.md"},"chunk_id": "c1ffa671-76d0-4c7a-b2dd-0b08dfd37712","chunk_name": "","score": 0.0,"summary": "","separator": "\n","retriever": null},...]

若有收获,就点个赞吧
0 人点赞
