一、背景
评估模块是衡量智能体应用效果的重要一环,首先高效的评估指标可以帮助开发者和研究人员快速检验智能体应用在特定领域或场景下的表现,从而进行有针对性的优化和调整;其次对于使用RAG技术的企业和组织来说,了解如何评估召回效果以及智能体回答效果可以更好地指导其在产品开发、客户服务等方面的应用,提高服务质量和用户体验。
二、核心概念
评估指标Metric是用于评估智能体应用的相关定量度量。指标有助于评估智能体应用的各个组件相对于给定的测试数据的执行情况。它们为整个应用程序开发和部署过程中的比较、优化和决策提供了数字基础。指标对于以下方面至关重要:
- 指标可用于将智能体应用的不同组件(如召回上下文、提示词模块、大模型回答等)与自己的数据进行比较,并从不同选项中选择最佳组件。
- 指标有助于智能体应用的哪个环境效果或性能不佳,从而更容易调试和优化。
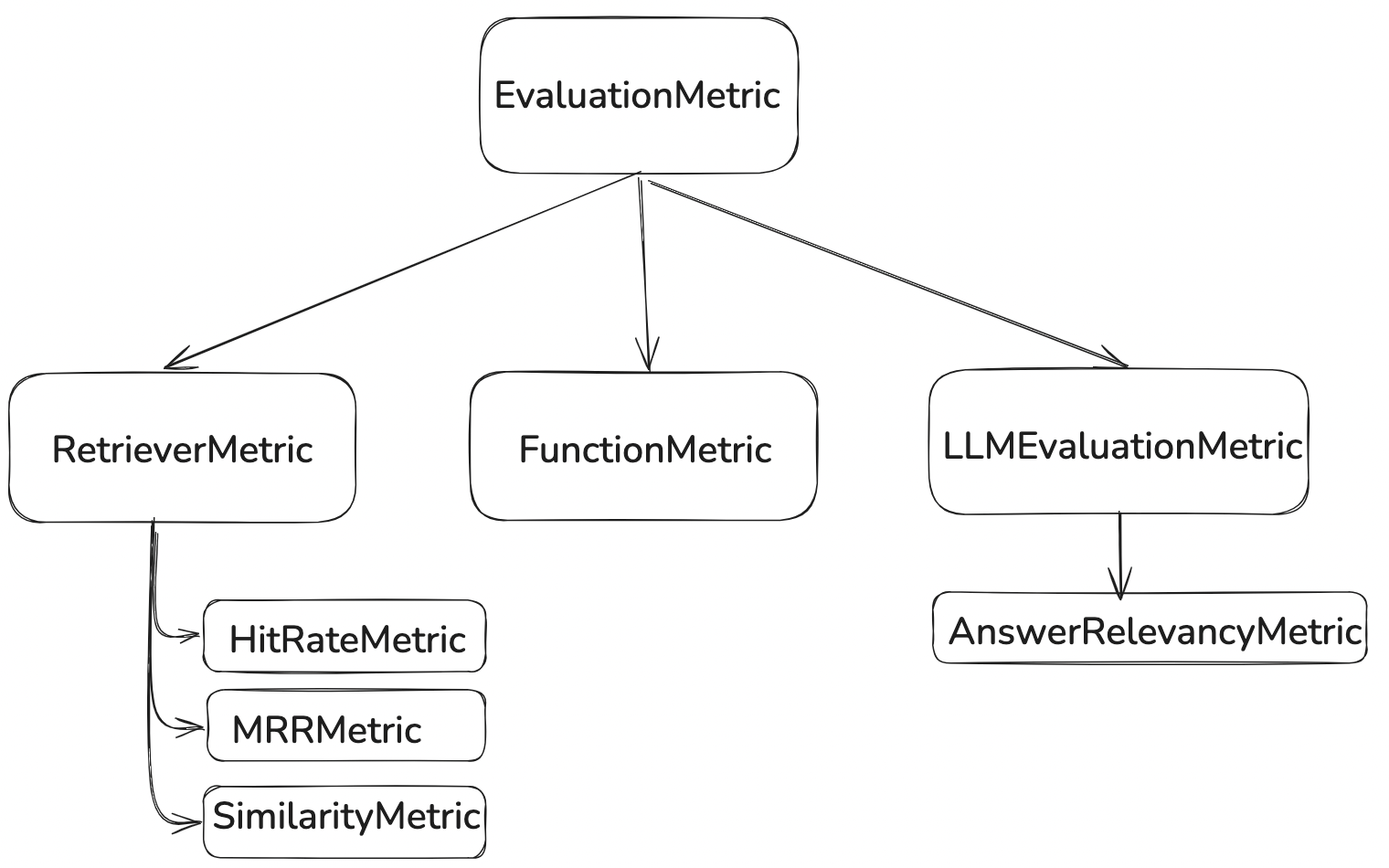
目前DB-GPT指标模块支持RAG召回指标以及Agent答案指标
**RAG**召回指标(RetrieverEvaluationMetric�):
RetrieverHitRateMetric�:命中率衡量的是RAG<font style="color:rgb(37, 41, 51);">retriever</font>召回出现在检索结果前top-k个文档中的比例。RetrieverMRRMetric�:<font style="color:rgb(37, 41, 51);">Mean Reciprocal Rank</font>通过分析最相关文档在检索结果里的排名来计算每个查询的准确性。更具体地说,它是所有查询的相关文档排名倒数的平均值。例如,若最相关的文档排在第一位,其倒数排名为 1;排在第二位时,为 1/2;以此类推。- RetrieverSimilarityMetric�: 相似度指标计算,计算召回内容与预测内容的相似度。
**Agent**答案指标:
AnswerRelevancyMetric�:智能体答案相关性指标,通过智能体答案与用户提问的匹配程度。高相关性的答案不仅要求模型能够理解用户的问题,还要求其能够生成与问题密切相关的答案。这直接影响到用户的满意度和模型的实用性。
注意,这里是借助第三方大模型进行评测打分,因此需要用户指定自己的评测提示词:
你是一个智能答疑专家, 你的任务是根据用户的问题和已经相关的文档给问答的答案进行严格的打分.你将会得到以下输入信息:- 用户的问题- 答案的知识来源,用于评估中的参考.- 问答系统生成的答案约束条件:- 你的工作是判断生成回答的相关性和正确性,并且输出一个代表整体评价的单一得分。- 你所返回的答案必须包含一个得分,且只能包含得分。- 不能返回任何其他格式的答案。在另外一行中需要提供你对得分的理由。遵循以下评分指南:你的得分必须在0到5之间,其中0是最差的,5是最好的。如果生成的答案包含LLM ERROR信息,你应该给出0分。如果生成的答案与相关的参考内容基本不相关,你应该给出1分。如果生成的答案与相关的参考内容有点相关,但回答并没有十分的详细,你应该给出2分。如果生成的答案与相关的参考内容非常相关,但回答并没有十分的详细,你应该给出3分。如果生成的答案与相关的参考内容相关且完全正确,并且十分详细地回答用户的问题,你应该给出4分。如果生成的答案与相关的参考内容相关且完全正确,并且十分详细地回答用户的问题,还有自己的建议和思考,你应该给出5分。用户的问题是:{query}相关的参考:{context}模型生成的答案:{answer}Example Response:4.0如果生成的答案与相关的参考内容相关且完全正确,并且十分详细地回答用户的问题,你应该给出4分。
三、如何使用
RAG召回评测
通过DB-GPT提供的评测服务进行使用
POST api/v2/serve/evaluate/evaluation
http方式:
SPACE_ID={YOUR_SPACE_ID}curl --location --request POST 'http://localhost:5670/api/v2/serve/evaluate/evaluation' \--header 'Content-Type: application/json' \-d'{"scene_key": "recall","scene_value": "'$SPACE_ID'","context":{"top_k":5},"evaluate_metrics":["RetrieverHitRateMetric","RetrieverMRRMetric","RetrieverSimilarityMetric"],"datasets": [{"query": "what awel talked about","doc_name":"awel.md"}]}'
python方式:
from dbgpt.client import Clientfrom dbgpt.client.evaluation import run_evaluationfrom dbgpt.serve.evaluate.api.schemas import EvaluateServeRequestDBGPT_API_KEY = "dbgpt"client = Client(api_key=DBGPT_API_KEY)SPACE_ID={YOUR_SPACE_ID}request = EvaluateServeRequest(# The scene type of the evaluation, e.g. support app, recallscene_key="recall",# e.g. app id(when scene_key is app), space id(when scene_key is recall)scene_value=SPACE_ID,context={"top_k": 5},evaluate_metrics=["RetrieverHitRateMetric","RetrieverMRRMetric","RetrieverSimilarityMetric",],datasets=[{"query": "what awel talked about","doc_name": "awel.md",}],)data = await run_evaluation(client, request=request)
Agent答案相关性评测
http方式
APP_ID={YOUR_APP_ID}PROMPT_ID = {YOUR_PROMPT_ID}curl --location --request POST 'http://localhost:5670/api/v2/serve/evaluate/evaluation' \--header 'Authorization: Bearer dbgpt' \--header 'Content-Type: application/json' \-d '{"scene_key": "app","scene_value": "'$APP_ID'","context":{"top_k":5, "prompt":"'$PROMPT_ID'","model":"zhipu_proxyllm"},"evaluate_metrics":["AnswerRelevancyMetric"],"datasets": [{"query": "what awel talked about","doc_name":"awel.md"}]}'
python方式
APP_ID={YOUR_APP_ID}PROMPT_ID = {YOUR_PROMPT_ID}curl --location --request POST 'http://localhost:5670/api/v2/serve/evaluate/evaluation' \--header 'Authorization: Bearer dbgpt' \--header 'Content-Type: application/json' \-d '{"scene_key": "app","scene_value": "'$APP_ID'","context":{"top_k":5, "prompt":"'$PROMPT_ID'","model":"zhipu_proxyllm"},"evaluate_metrics":["AnswerRelevancyMetric"],"datasets": [{"query": "what awel talked about","doc_name":"awel.md"}]}'
请求参数说明:
| 参数名 | 参数说明 | 类型 |
|---|---|---|
| scene_key | 场景类型,支持recall(召回评测),app(智能体评测)两种(**必选**) | string |
| scene_value | 注意:**SPACE_ID**值的是知识空间的id,(**必选**) |
string |
| evaluate_metrics | 召回相关评测指标(**必选**) + RetrieverHitRateMetric + RetrieverMRRMetric + RetrieverSimilarityMetric 智能体答案评测指标 + AnswerRelevancyMetric� |
Array |
| datasets | 评测数据集 + query:用户问题(**必选**) + doc_name:知识库里面的文档名,需要用户指定用户的问题是来源于哪个文档(**必选**) |
Array[Object] |
| context | 评测相关参数: + top_k:指定召回需要上下文数量。**必选 + prompt:提示词模块id,需要在DB-GPT提示词模块构建提示词,当评测场景类型为智能体的时候需要。(可选) + model:模型名,当评测场景类型为智能体的时候需要。(可选)** |
Object |
返回参数说明:
{"success": true,"err_code": null,"err_msg": null,"data": [[{"prediction": "用户问题: what awel talked about\n\n提取的文本内容:\nAWEL是专门为大模型应用开发设计的智能代理工作流表达语言,提供强大的功能性和灵活性。AWEL采用了分层的API设计,分为运算符层、AgentFream层和DSL层。运算符层是最基本的操作原子集合,AgentFream层进一步封装运算符并支持链式计算,DSL层提供一套标准的结构化表示语言,通过编写DSL语句来完成AgentFream和运算符的操作。\n\n总结内容:\nAWEL主要讨论的是一种为大模型应用开发设计的智能代理工作流表达语言,其特点是功能强大、灵活,并且采用分层API设计。它包括运算符层、AgentFream层和DSL层,分别负责基础操作原子的定义、链式计算以及结构化语言的编写,以实现更确定性、围绕数据的大模型应用程序开发。 \n\n输出内容: \nAWEL讨论的是一种为大模型应用开发设计的表达语言,特点是功能性强和灵活,采用分层API设计,包括运算符层、AgentFream层和DSL层,用于实现更确定性、基于数据的大模型应用编程。","contexts": ["\"What is AWEL?\": Agentic Workflow Expression Language(AWEL) is a set of intelligent agent workflow expression language specially designed for large model application\ndevelopment. It provides great functionality and flexibility. Through the AWEL API, you can focus on the development of business logic for LLMs applications\nwithout paying attention to cumbersome model and environment details. \nAWEL adopts a layered API design. AWEL's layered API design architecture is shown in the figure below. \n<p align=\"left\">\n<img src={'/img/awel.png'} width=\"480px\"/>\n</p>","\"What is AWEL?-Operators-Example of API-RAG-Example of LLM + cache\": <p align=\"left\">\n<img src={'/img/awel_cache_flow.png'} width=\"360px\" />\n</p>","\"What is AWEL?-AWEL Design\": AWEL is divided into three levels in deign, namely the operator layer, AgentFream layer and DSL layer. The following is a brief introduction\nto the three levels. \n- **Operator layer**\nThe operator layer refers to the most basic operation atoms in the LLM application development process,\nsuch as when developing a RAG application. Retrieval, vectorization, model interaction, prompt processing, etc.\nare all basic operators. In the subsequent development, the framework will further abstract and standardize the design of operators.\nA set of operators can be quickly implemented based on standard APIs \n- **AgentFream layer**\nThe AgentFream layer further encapsulates operators and can perform chain calculations based on operators.\nThis layer of chain computing also supports distribution, supporting a set of chain computing operations such as filter, join, map, reduce, etc. More calculation logic will be supported in the future. \n- **DSL layer**\nThe DSL layer provides a set of standard structured representation languages, which can complete the operations of AgentFream and operators by writing DSL statements, making it more deterministic to write large model applications around data, avoiding the uncertainty of writing in natural language, and making it easier to write around data. Application programming with large models becomes deterministic application programming.","\"What is AWEL?-Examples\": The preliminary version of AWEL has alse been released, and we have provided some built-in usage examples.","\"What is AWEL?-Executable environment\": - Stand-alone environment\n- Ray environment","\"What is AWEL?-Operators-DSL Example\": ``` python\nCREATE WORKFLOW RAG AS\nBEGIN\nDATA requestData = RECEIVE REQUEST FROM\nhttp_source(\"/examples/rags\", method = \"post\"); \nDATA processedData = TRANSFORM requestData USING embedding(model = \"text2vec\");\nDATA retrievedData = RETRIEVE DATA\nFROM vstore(database = \"chromadb\", key = processedData)\nON ERROR FAIL; \nDATA modelResult = APPLY LLM \"vicuna-13b\"\nWITH DATA retrievedData AND PARAMETERS (temperature = 0.7)\nON ERROR RETRY 2 TIMES; \nRESPOND TO http_source WITH modelResult\nON ERROR LOG \"Failed to respond to request\";\nEND;\n```","\"What is AWEL?-Operators-Example of API-RAG\": You can find [source code](https://github.com/eosphoros-ai/DB-GPT/blob/main/examples/awel/simple_rag_example.py) from `examples/awel/simple_rag_example.py`\n```python\nwith DAG(\"simple_rag_example\") as dag:\ntrigger_task = HttpTrigger(\n\"/examples/simple_rag\", methods=\"POST\", request_body=ConversationVo\n)\nreq_parse_task = RequestParseOperator()\n# TODO should register prompt template first\nprompt_task = PromptManagerOperator()\nhistory_storage_task = ChatHistoryStorageOperator()\nhistory_task = ChatHistoryOperator()\nembedding_task = EmbeddingEngingOperator()\nchat_task = BaseChatOperator()\nmodel_task = ModelOperator()\noutput_parser_task = MapOperator(lambda out: out.to_dict()[\"text\"]) \n(\ntrigger_task\n>> req_parse_task\n>> prompt_task\n>> history_storage_task\n>> history_task\n>> embedding_task\n>> chat_task\n>> model_task\n>> output_parser_task\n) \n```\nBit operations will arrange the entire process in the form of DAG \n<p align=\"left\">\n<img src={'/img/awel_dag_flow.png'} width=\"360px\" />\n</p>","\"What is AWEL?-Operators-AgentFream Example\": ```python\naf = AgentFream(HttpSource(\"/examples/run_code\", method = \"post\"))\nresult = (\naf\n.text2vec(model=\"text2vec\")\n.filter(vstore, store = \"chromadb\", db=\"default\")\n.llm(model=\"vicuna-13b\", temperature=0.7)\n.map(code_parse_func)\n.map(run_sql_func)\n.reduce(lambda a, b: a + b)\n)\nresult.write_to_sink(type='source_slink')\n```","\"What is AWEL?-Currently supported operators\": - **Basic Operators**\n- BaseOperator\n- JoinOperator\n- ReduceOperator\n- MapOperator\n- BranchOperator\n- InputOperator\n- TriggerOperator\n- **Stream Operators**\n- StreamifyAbsOperator\n- UnstreamifyAbsOperator\n- TransformStreamAbsOperator","\"\": <font style=\"color:#24292E;\">OceanBase通过Root Service管理各个节点间的负载均衡。不同类型的副本需求的资源各不相同,Root Service在执行分区管理操作时需要考虑的因素包括每台ObServer上的CPU、磁盘使用量、内存使用量、IOPS使用情况、避免同一张表格的分区全部落到少数几台ObServer,等等。让耗内存多的副本和耗内存少的副本位于同一台机器上,让占磁盘空间多的副本和占磁盘空间少的副本位于同一台机器上。经过负载均衡,最终会使得所有机器的各类型资源占用都处于一种比较均衡的状态,充分利用每台机器的所有资源。</font> \n<font style=\"color:#24292E;\">负载均衡分机器、unit两个粒度,前者负责机器之间的均衡,选择一些 unit 整体从负载高的机器迁移到负载低的机器上;后者负责两个unit之间的均衡,从负载高的 unit 搬迁副本到负载低的 unit。</font> \n| | **机器负载均衡** | **unit负载均衡** |\n| --- | --- | --- |\n| 均衡对象 | 机器 | unit |\n| 搬迁内容 | unit | 副本 |\n| 均衡粒度 | 粗 | 细 |\n| 均衡范围 | zone 内均衡 | zone 内均衡 | \n<font style=\"color:#24292E;\">一个租户拥有若干个资源池,这些资源池的集合描述了这个租户所能使用的所有资源。一个资源池由具有相同资源规格(Unit Config)的若干个UNIT(资源单元)组成。每个UNIT描述了位于一个Server上的一组计算和存储资源,可以视为一个轻量级虚拟机,包括若干CPU资源,内存资源,磁盘资源等。一个资源池只能属于一个租户,一个租户在同一个Server上最多有一个UNIT。对于每个Zone,根据UNIT的动态调度,达到均衡的策略。</font> \n+ <font style=\"color:#24292E;\">属于同一个租户的若干个UNIT,会均匀分散在不同的server上</font>\n+ <font style=\"color:#24292E;\">属于同一个租户组的若干个UNIT,会尽量均匀分散在不同的server上</font>\n+ <font style=\"color:#24292E;\">当一个Zone内机器整体磁盘使用率超过一定阈值时,通过交换或迁移UNIT降低磁盘水位线</font>\n+ <font style=\"color:#24292E;\">否则,根据UNIT的CPU和内存规格,通过交换或迁移UNIT降低CPU和内存的平均水位线</font>"],"score": 4.0,"passing": true,"metric_name": "AnswerRelevancyMetric","prediction_cost": -10,"query": "what awel talked about","raw_dataset": {"query": "what awel talked about","doc_name": "awel.md","factual": ["\"What is AWEL?\": Agentic Workflow Expression Language(AWEL) is a set of intelligent agent workflow expression language specially designed for large model application\ndevelopment. It provides great functionality and flexibility. Through the AWEL API, you can focus on the development of business logic for LLMs applications\nwithout paying attention to cumbersome model and environment details. \nAWEL adopts a layered API design. AWEL's layered API design architecture is shown in the figure below. \n<p align=\"left\">\n<img src={'/img/awel.png'} width=\"480px\"/>\n</p>","\"What is AWEL?-Operators-Example of API-RAG-Example of LLM + cache\": <p align=\"left\">\n<img src={'/img/awel_cache_flow.png'} width=\"360px\" />\n</p>","\"What is AWEL?-AWEL Design\": AWEL is divided into three levels in deign, namely the operator layer, AgentFream layer and DSL layer. The following is a brief introduction\nto the three levels. \n- **Operator layer**\nThe operator layer refers to the most basic operation atoms in the LLM application development process,\nsuch as when developing a RAG application. Retrieval, vectorization, model interaction, prompt processing, etc.\nare all basic operators. In the subsequent development, the framework will further abstract and standardize the design of operators.\nA set of operators can be quickly implemented based on standard APIs \n- **AgentFream layer**\nThe AgentFream layer further encapsulates operators and can perform chain calculations based on operators.\nThis layer of chain computing also supports distribution, supporting a set of chain computing operations such as filter, join, map, reduce, etc. More calculation logic will be supported in the future. \n- **DSL layer**\nThe DSL layer provides a set of standard structured representation languages, which can complete the operations of AgentFream and operators by writing DSL statements, making it more deterministic to write large model applications around data, avoiding the uncertainty of writing in natural language, and making it easier to write around data. Application programming with large models becomes deterministic application programming.","\"What is AWEL?-Examples\": The preliminary version of AWEL has alse been released, and we have provided some built-in usage examples.","\"What is AWEL?-Executable environment\": - Stand-alone environment\n- Ray environment","\"What is AWEL?-Operators-DSL Example\": ``` python\nCREATE WORKFLOW RAG AS\nBEGIN\nDATA requestData = RECEIVE REQUEST FROM\nhttp_source(\"/examples/rags\", method = \"post\"); \nDATA processedData = TRANSFORM requestData USING embedding(model = \"text2vec\");\nDATA retrievedData = RETRIEVE DATA\nFROM vstore(database = \"chromadb\", key = processedData)\nON ERROR FAIL; \nDATA modelResult = APPLY LLM \"vicuna-13b\"\nWITH DATA retrievedData AND PARAMETERS (temperature = 0.7)\nON ERROR RETRY 2 TIMES; \nRESPOND TO http_source WITH modelResult\nON ERROR LOG \"Failed to respond to request\";\nEND;\n```","\"What is AWEL?-Operators-Example of API-RAG\": You can find [source code](https://github.com/eosphoros-ai/DB-GPT/blob/main/examples/awel/simple_rag_example.py) from `examples/awel/simple_rag_example.py`\n```python\nwith DAG(\"simple_rag_example\") as dag:\ntrigger_task = HttpTrigger(\n\"/examples/simple_rag\", methods=\"POST\", request_body=ConversationVo\n)\nreq_parse_task = RequestParseOperator()\n# TODO should register prompt template first\nprompt_task = PromptManagerOperator()\nhistory_storage_task = ChatHistoryStorageOperator()\nhistory_task = ChatHistoryOperator()\nembedding_task = EmbeddingEngingOperator()\nchat_task = BaseChatOperator()\nmodel_task = ModelOperator()\noutput_parser_task = MapOperator(lambda out: out.to_dict()[\"text\"]) \n(\ntrigger_task\n>> req_parse_task\n>> prompt_task\n>> history_storage_task\n>> history_task\n>> embedding_task\n>> chat_task\n>> model_task\n>> output_parser_task\n) \n```\nBit operations will arrange the entire process in the form of DAG \n<p align=\"left\">\n<img src={'/img/awel_dag_flow.png'} width=\"360px\" />\n</p>","\"What is AWEL?-Operators-AgentFream Example\": ```python\naf = AgentFream(HttpSource(\"/examples/run_code\", method = \"post\"))\nresult = (\naf\n.text2vec(model=\"text2vec\")\n.filter(vstore, store = \"chromadb\", db=\"default\")\n.llm(model=\"vicuna-13b\", temperature=0.7)\n.map(code_parse_func)\n.map(run_sql_func)\n.reduce(lambda a, b: a + b)\n)\nresult.write_to_sink(type='source_slink')\n```","\"What is AWEL?-Currently supported operators\": - **Basic Operators**\n- BaseOperator\n- JoinOperator\n- ReduceOperator\n- MapOperator\n- BranchOperator\n- InputOperator\n- TriggerOperator\n- **Stream Operators**\n- StreamifyAbsOperator\n- UnstreamifyAbsOperator\n- TransformStreamAbsOperator","\"\": <font style=\"color:#24292E;\">OceanBase通过Root Service管理各个节点间的负载均衡。不同类型的副本需求的资源各不相同,Root Service在执行分区管理操作时需要考虑的因素包括每台ObServer上的CPU、磁盘使用量、内存使用量、IOPS使用情况、避免同一张表格的分区全部落到少数几台ObServer,等等。让耗内存多的副本和耗内存少的副本位于同一台机器上,让占磁盘空间多的副本和占磁盘空间少的副本位于同一台机器上。经过负载均衡,最终会使得所有机器的各类型资源占用都处于一种比较均衡的状态,充分利用每台机器的所有资源。</font> \n<font style=\"color:#24292E;\">负载均衡分机器、unit两个粒度,前者负责机器之间的均衡,选择一些 unit 整体从负载高的机器迁移到负载低的机器上;后者负责两个unit之间的均衡,从负载高的 unit 搬迁副本到负载低的 unit。</font> \n| | **机器负载均衡** | **unit负载均衡** |\n| --- | --- | --- |\n| 均衡对象 | 机器 | unit |\n| 搬迁内容 | unit | 副本 |\n| 均衡粒度 | 粗 | 细 |\n| 均衡范围 | zone 内均衡 | zone 内均衡 | \n<font style=\"color:#24292E;\">一个租户拥有若干个资源池,这些资源池的集合描述了这个租户所能使用的所有资源。一个资源池由具有相同资源规格(Unit Config)的若干个UNIT(资源单元)组成。每个UNIT描述了位于一个Server上的一组计算和存储资源,可以视为一个轻量级虚拟机,包括若干CPU资源,内存资源,磁盘资源等。一个资源池只能属于一个租户,一个租户在同一个Server上最多有一个UNIT。对于每个Zone,根据UNIT的动态调度,达到均衡的策略。</font> \n+ <font style=\"color:#24292E;\">属于同一个租户的若干个UNIT,会均匀分散在不同的server上</font>\n+ <font style=\"color:#24292E;\">属于同一个租户组的若干个UNIT,会尽量均匀分散在不同的server上</font>\n+ <font style=\"color:#24292E;\">当一个Zone内机器整体磁盘使用率超过一定阈值时,通过交换或迁移UNIT降低磁盘水位线</font>\n+ <font style=\"color:#24292E;\">否则,根据UNIT的CPU和内存规格,通过交换或迁移UNIT降低CPU和内存的平均水位线</font>"]},"feedback": "生成的答案与参考内容紧密相关,且完全正确,详细地描述了AWEL的概念、特点和设计架构,充分回答了用户的问题。"}]]}
| 参数名 | 参数说明 | 类型 |
|---|---|---|
| prediction | RAG召回的答案,如果场景类型是recall 智能体生成的答案,如果场景类型为 |
string |
| query | 用户的问题 | string |
| contexts | RAG根据用户问题召回的上下文 | Array |
| score | 本次评测的得分 | float |
| raw_dataset | 数据集 + query:用户问题(**必选**) + doc_name:知识库里面的文档名,需要用户指定用户的问题是来源于哪个文档(**必选**) + factual:召回的实际上下文 |
Array[Object] |
| metric_name | 评测的指标名 | Object |
| feedback | 模型的生成的评测反馈 | string |
四、如何自定义指标
EvaluationMetric├── LLMEvaluationMetric│ ├── AnswerRelevancyMetric├── RetrieverEvaluationMetric│ ├── RetrieverSimilarityMetric│ ├── RetrieverMRRMetric│ └── RetrieverHitRateMetric
如果需要实现RAG召回模块,继承RetrieverEvaluationMetric,实现sync_compute方法即可
class RetrieverMRRMetric(RetrieverEvaluationMetric):"""Retriever Mean Reciprocal Rank metric.For each query, MRR evaluates the system’s accuracy by looking at the rank of thehighest-placed relevant document. Specifically, it’s the average of the reciprocalsof these ranks across all the queries. So, if the first relevant document is thetop result, the reciprocal rank is 1; if it’s second, the reciprocal rank is 1/2,and so on."""def sync_compute(self,prediction: List[str],contexts: Optional[Sequence[str]] = None,query: Optional[str] = None,) -> BaseEvaluationResult:"""Compute MRR metric.Args:prediction(Optional[List[str]]): The retrieved chunks from the retriever.contexts(Optional[List[str]]): The contexts from dataset.query:(Optional[str]) The query text.Returns:BaseEvaluationResult: The evaluation result.The score is the reciprocal rank of the first relevant chunk."""if not prediction or not contexts:return BaseEvaluationResult(prediction=prediction,contexts=contexts,score=0.0,)for i, retrieved_chunk in enumerate(prediction):if retrieved_chunk in contexts:return BaseEvaluationResult(score=1.0 / (i + 1),)return BaseEvaluationResult(score=0.0,)
如果需要借助大模型LLM实现评测指标,继承LLMEvaluationMetric,实现_parse_evaluate_response方法即可。

若有收获,就点个赞吧
0 人点赞
