介绍
目前DB-GPT知识库提供了文档上传 -> 解析 -> 切片 -> Embedding -> 知识图谱三元组抽取 -> 向量数据库存储 -> 图数据库存储等知识加工的能力,但是不具备对文档进行复杂的信息抽取能力,包括同时对文档块进行向量抽取和知识图谱抽取,混合知识加工模版通过定义复杂的知识处理工作流,同时支持对文档的向量抽取,关键词抽取和知识图谱抽取。
适用场景
- 不仅限于传统的,单一的知识加工流程(仅Embedding加工或者知识图谱抽取加工),知识加工workflow实现同时进行Embedding,知识图谱抽取,作为混合知识召回检索数据储备。
- 用户可以根据自身业务场景,对已有的知识加工流程进行裁剪和新增。
如何使用
- 进入AWEL界面并新增工作流
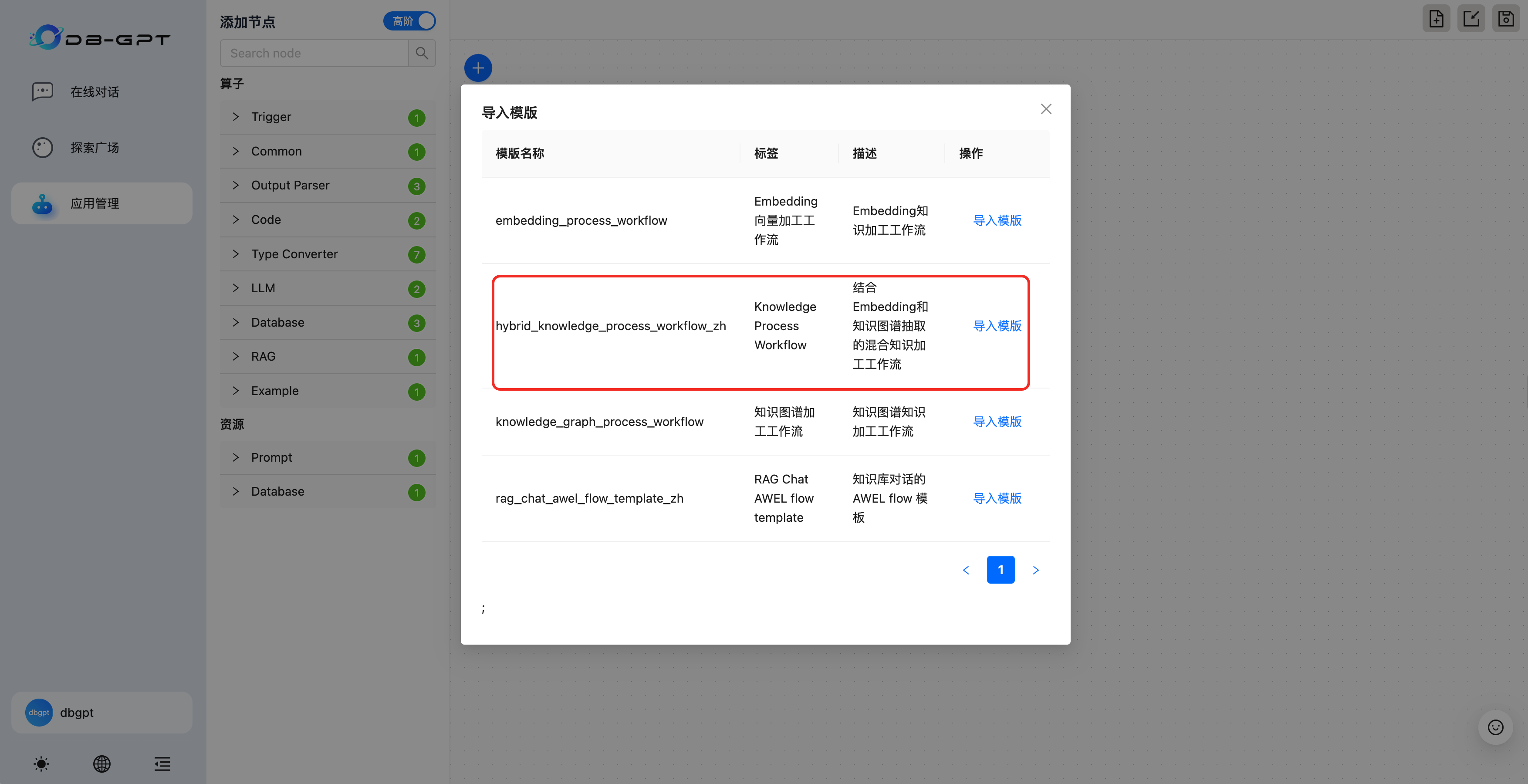
- 导入知识加工模版
- 调整参数并保存
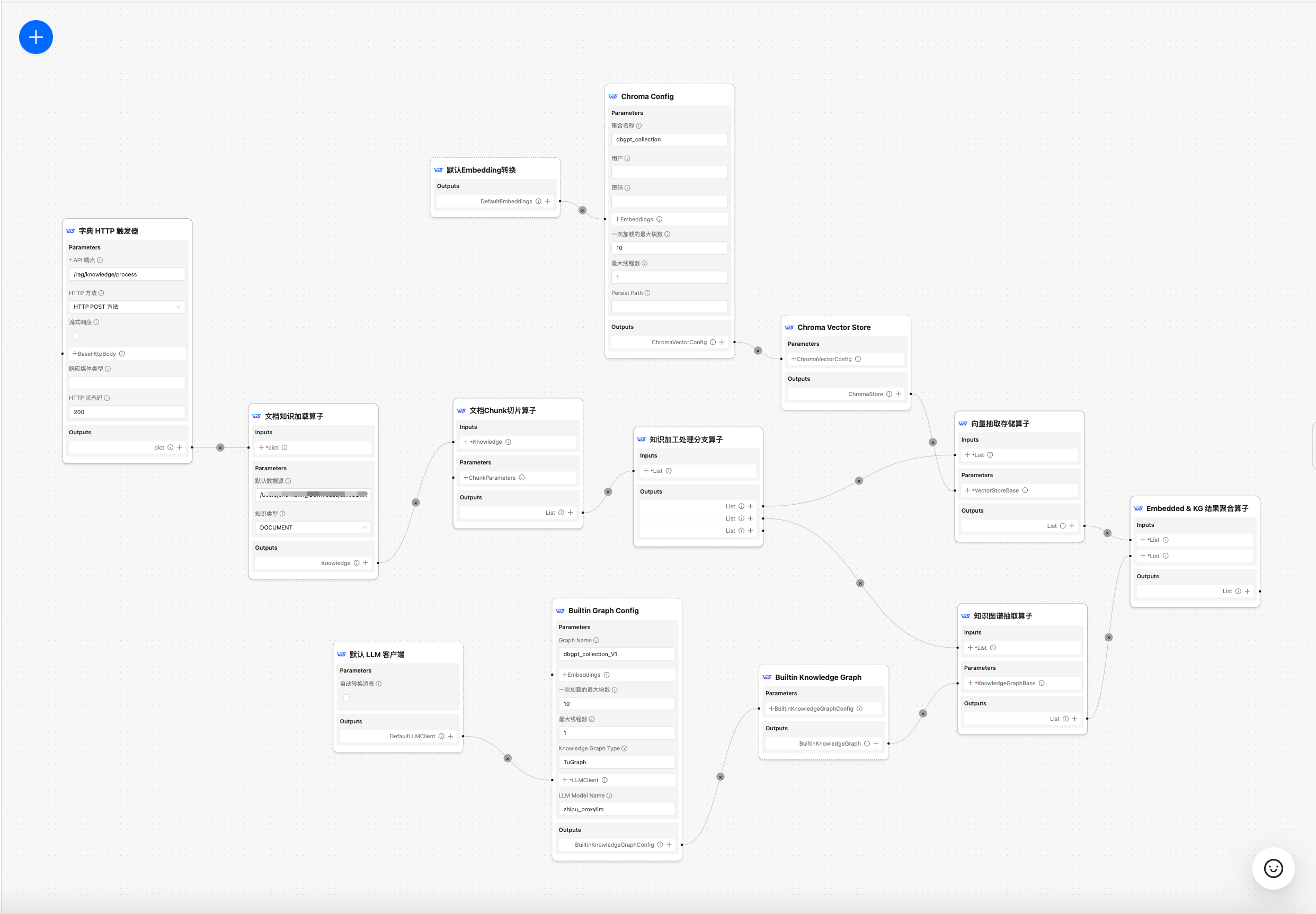
- `文档知识加载算子`: 知识加载工厂,通过加载指定的文档类型,找到对应的文档处理器进行文档内容解析。- `文档Chunk切片算子`:将加载好的文档内容按照指定的切片参数进行切片处理。- `知识加工处理分支算子`:可以连接不同的知识加工流程,包括知识图谱加工流程,向量加工流程,关键词加工流程。- `向量存储加工算子`:可以连接不同的向量数据库进行向量存储,同时也可以连接不同的Embedding模型和服务进行向量抽取。- `知识图谱加工算子`:可以连接不同的知识图谱加工算子,包括原生知识图谱加工算子,社区总结知识图谱加工算子等,同时可以指定不同的图数据库进行存储,目前支持TuGraph数据库。* <font style="color:#DF2A3F;">注意:</font>需要先安装图数据库环境 参考:[Graph RAG User Manual | DB-GPT](http://docs.dbgpt.cn/docs/cookbook/rag/graph_rag_app_develop)- `结果聚合算子`:将向量抽取结果和知识图谱抽取结果进行汇总处理。
- 注册发布为http请求
curl --location --request POST 'http://localhost:5670/api/v1/awel/trigger/rag/knowledge/hybrid/process' \--header 'Content-Type: application/json' \--data-raw '{}'
["async persist vector store success 9 chunks.","async persist graph store success 9 chunks."]

若有收获,就点个赞吧
0 人点赞
