实践教程:安装金融财报分析助手
一、背景
最近,利用大模型进行财务报表分析正逐渐成为垂直领域的一个热门应用。大模型能够比人类更准确地理解复杂的财务规则,并在基于专业知识的基础上输出合理的分析结果。然而,财务报表信息庞大且复杂,对数据分析的准确性要求极高,通用的RAG和Agent的解决方案往往难以满足这些需求。 以某公司的2022年财务报表为例,传统方法在处理类似“2022年XXX子公司的第三季度的营业净利润是多少?”的查询时,通常通过知识向量相似检索和匹配来召回最相关的文本块进行总结和问答。然而,财务年报中包含多处相关信息,如不同季度的利润表、现金流量表等,这些信息可能会引发误判。如果不能准确召回并理解正确部分,就容易生成错误答案。如果涉及到财务指标的计算,分析过程可能会变得更加复杂。例如,计算毛利率、净利率等指标需要对收入和成本等多方面的数据进行综合分析。 为了克服大模型应用中的这些挑战,我们需要结合财务领域的知识背景,添加专门的外部模块来增强其功能。本文将以DB-GPT的AWEL编排模式为例,借助DB-GPT-Hub的几个关键原子,详细阐述如何利用大模型进行有效的财报数据分析,希望能为在垂直领域的进行数据AI赋能的朋友提供一些思考。- GitHub - eosphoros-ai/DB-GPT: AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents
- GitHub - eosphoros-ai/DB-GPT-Hub: A repository that contains models, datasets, and fine-tuning techniques for DB-GPT, with the purpose of enhancing model performance in Text-to-SQL
- GitHub - eosphoros-ai/dbgpts: Intelligent data apps and assets with LLMs
二、 架构方案
目前我们的实现方式是通过上传公司年报,利用大模型作为知识驱动引擎,调用向量数据库、关系型数据库、OCR服务以及相关模型等组件,通过AWEL(agent流式编排)构建一个财报分析的问答助手,能够直接回答用户这几类问题:- 财报基础信息回答
- 财报指标计算
- 报告解读分析
- 专业名词解释
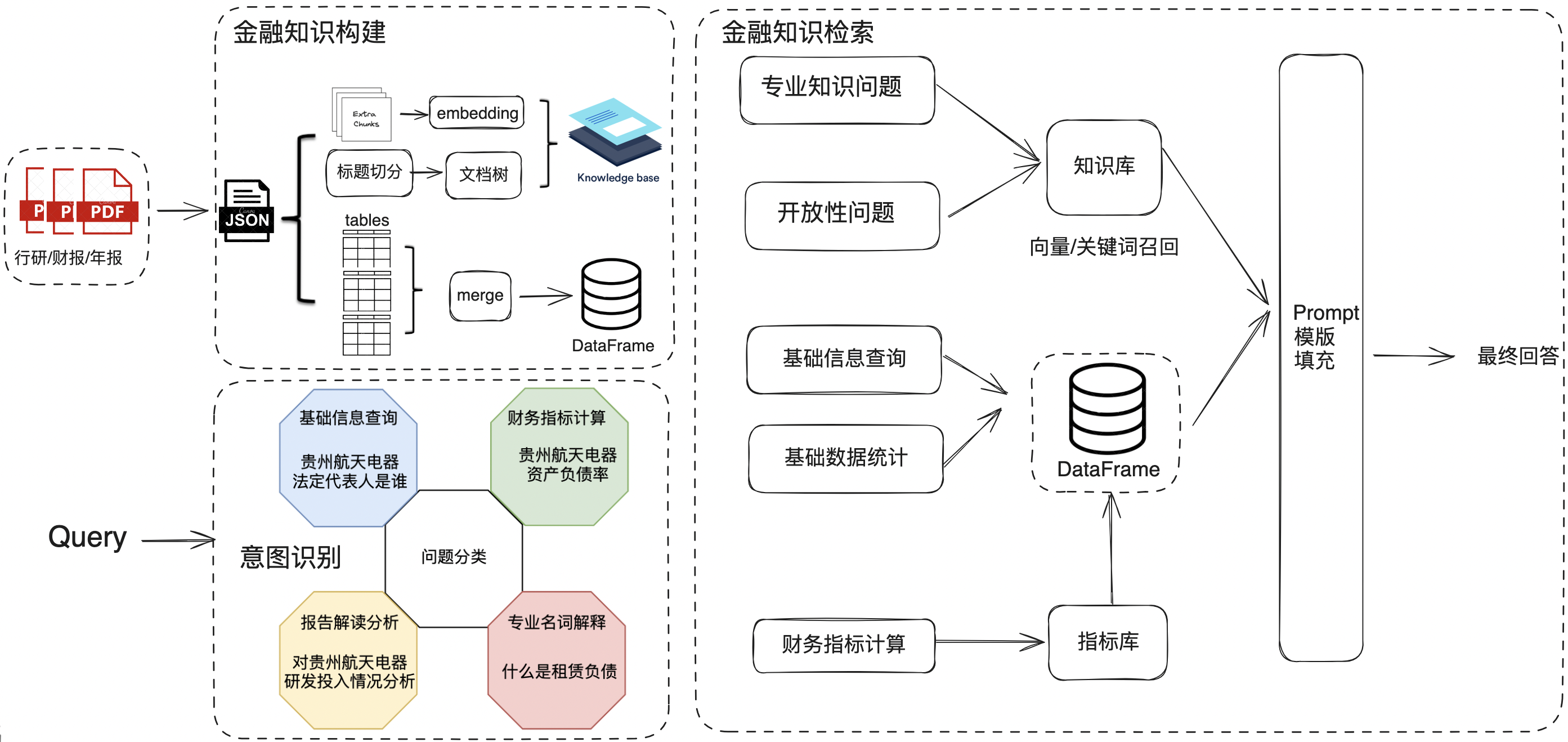
- 金融知识构建,目的是进行数据多元化的信息抽取与索引存储,涉及pdf文档加载,数据预处理,PDF转JSON,文档切分,文档树构建,表格的提取与合并,Embedding以及数据存储等过程。
- 查询意图识别,目的是进行问题分类以及槽位提取,可以解析和抽取用户查询中的相关参数后可以路由到不同的知识检索处理流程中。
- 金融知识检索,目的是更精准地查询出用户想要的知识信息,涉及RAG以及Text2SQL的处理。
三、 金融知识构建
在A股上市公司发布的财务报告中,通常会包含一些重要的文本描述、财务表格和其他附注信息。每个财务报表都提供了不同方面的财务数据,用来展示公司的财务状况、经营成果和现金流情况:- 资产负债表显示公司的资产、负债和股东权益,提供了公司在某一特定日期的财务状况。
- 利润表展示公司在一定期间内的收入、成本、费用及净利润情况,反映公司的经营成果。
- 现金流量表展示公司在一定期间内现金及现金等价物流入和流出的情况,分为经营活动、投资活动和筹资活动三个部分。
- 所有者权益变动表展示公司在一定期间内股东权益的变动情况,包括净利润、分红、增发等。
- 财务报表附注提供了对报表中项目的详细解释和补充说明,帮助报表使用者更好地理解公司的财务状况和经营成果。
3.1 数据预处理
针对财报pdf这样的非结构化数据处理,考虑到针对财报文档的一些特性,表格数据密集,专业术语繁多等情况,需要在信息抽取之前对pdf这样的非结构化数据进行预处理,主要的思路是将非结构化数据 -> 结构化数据,因此首先在数据读取和数据预处理模块,利用<font style="color:#000000;">pdfplumber</font>按页读取并转换为json格式,并且识别出哪些是需要的文本数据,哪些是表格数据,哪些是不需要的数据,比如页眉,页脚等等。

3.2 知识抽取
数据预处理后,我们得到了标准的结构化的json数据,基于处理后的json数据,我们将内容划分为文本和表格两大块,针对这两块数据分别进行文本信息抽取和表格抽取。3.2.1 文本抽取
文本抽取包括<font style="color:#000000;">知识切片</font>,<font style="color:#000000;">元数据信息抽取</font>,<font style="color:#000000;">embedding</font>等一系列子任务组成。
知识切片主要目的是1.保持语义相关性,也就是上下文相关性,这直接关乎回复准确率。2.保持在大模型的上下文限制内,分块保证输入到LLMs的文本不会超过其token limitations。这里有很多种分片策略进行选择:按照文本大小切分,按照页切分,按照标题进行切分。本次案例为了保持语义的相关性,推荐采取按照页进行切分和按照标题级别进行切分。
按照页切分
按照pdf每一页进行切分,保留每一页的完整性。- 优点:能够保证语义完整性,实现简单。
- 缺点:会给模型带来额外的数据杂音,对模型上下文窗口要求限制高。
按照标题级别切分
这里需要识别财报里面的标题信息,以标题层级构建chunk的树形节点,形成一个多叉树结构,每一层级节点只需要存储文档标题,叶子节点存储具体的文本内容。这样利用树的遍历算法,如果用户问题命中相关非叶子标题节点,就可以将相关的子节点数据进行召回。- 优点:解决了上下文完整性不足的问题,也能匹配时完全依据语义和关键词,能够减少噪音。
- 缺点:对模型上下文窗口要求限制高。

3.2.2 表格抽取
我们的目标是对金融财报指标进行计算和分析,这里有两个难点:- 一份财报有几十甚至上百张表格,如果对每份表格单独抽取后直接进行数据存储,这里就会面临在NL2SQL环节召回表困难的问题。
- 我们有成百上千份公司的财报,如果对每一份财报数据单独存储,就无法回答用户对不同的公司比较分析的问题。
:::color1
因此,针对这两个问题,我们需要对财报里面的表格进行合并,这里有两种合并方案。:::
合并成一张大宽表,由于不同公司的主要财报数据的表格定义都是相似的,因此可以针对财报数据的表格进行分类:
- 公司基础信息表:包括公司基本信息表,联系方式表,注册变更表,员工信息表等等
- 金融指标表:包括资产负债表,利润表、现金流表等等
- 额外的信息表
- 优点: - 由于都汇总成了一张表,避免了数据计算分析环节nl2sql过程中表召回困难,表召回错误的情况。 - 不同的公司的表格数据都汇总到了一起,可以对不同公司的数据进行比较分析。
- 缺点:在表格提取和数据合并的过程中,存在一部分数据的丢失,导致有些信息的缺失。

合并成多张表数据,包括基本信息表,员工信息表,资产负债表,现金流表,其他信息表等等。
- 优点:避免了大宽表的数据缺失,分析过程可以更加精准
- 缺点: - 需要更细致的表格处理 - NL2SQL需要解决表召回和多表连接的问题
四、意图识别
4.1 问题分类
用户的查询需求多种多样,包括数据查询、年报问答等。模型需要准确识别用户意图,调用相应功能模块。例如,用户查询公司资产负债率时,模型需要识别这是一个数据查询请求,并调用相关公式进行SQL查询;询问公司未来增长策略时,模型需调用年报问答模块,基于RAG模块提供回复。 目前我们提供了几种不同的意图识别方案,每种方案各有优缺,大家可以根据自己的资源和精度要求进行选择实现方案一、基于embedding(Bert)的识别:
- 利用BGE-v1.5对用户query和意图label进行向量化,使用逻辑回归等简单的机器学习模型进行学习分类就能获得很好效果。这种方案训练时间短、准确率高,但需要根据实际业务制作query意图数据集。
- 这个方案最重要的其实是选择一个高质量的embedding模型,文本数据的多样性和复杂性很高,直接处理原始文本往往效果不佳。大多数embedding模型是在大规模语料库上预训练的,它们已经捕捉了广泛的语言特征,embedding模型能够适应和理解不同的文本语义,将输入文本转化为标准化的稠密向量表示,提供了丰富的语言特征,从而使得逻辑回归等简单的分类器也能进行精确分类。
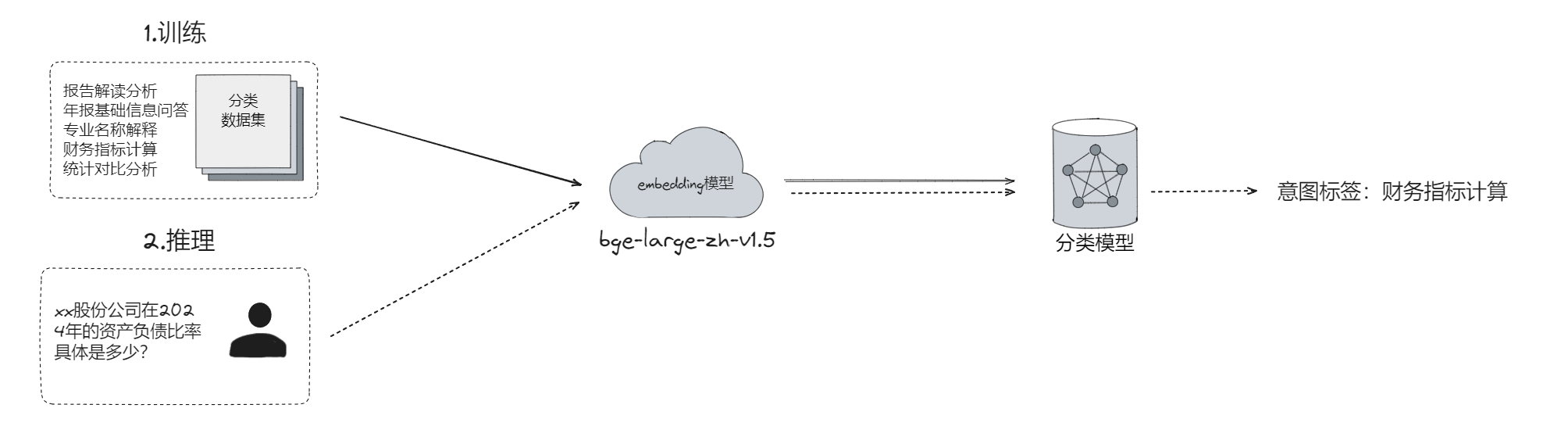
方案二、大模型prompt的ICL能力:
- 通过在prompt中加入意图识别的样例和规则,引导大模型理解用户意图,生成期望输出。这种方案无需大量数据集和训练,但可能产生大量token消耗,且意图数量增加时准确率下降。
- Prompt一般包含意图列表和相关示例,输出一般为具体的意图名称或对应的序号
方案三、大模型SFT
- 构建意图识别的指令微调数据集,输入为用户查询语句,输出为意图标签文本或json。这种方法是通过微调的方式,让大模型具备理解和学习意图的能力
- 开源大模型微调可以试试llama-factory或者DB-GPT-Hub
方案四:在大模型上进行sequence标签监督微调:
- 针对特定意图识别任务,对大模型进行类似bert的序列分类微调。通过lora微调方式在小规模模型(如1.5b、7b)上实现最佳效果,同时可以切换adapter实现下游任务切换,提升推理速度和准确率,降低资源消耗。
- 在分类任务中,标签通常由高度集中的单词或短语组成,某些标签含义比较专业或模糊,在一些模棱两可的情况下会导致LLMs难以从字面上有效理解标签的语义。虽然Meta自LLaMA-1以来就提供了序列分类接口,但其实很少有用LLM直接用于标签分类的工作,因为从直觉上来看decoder的因果掩码避免了前向信息泄露,无法关注全局信息。但是大模型毕竟在参数量和学习的知识信息量级上要远超过往的BERT簇模型,神经网络的黑盒可能会带给我们意外的惊喜。
- 所以我们尝试用标签监督微调LLMs的方式去实现相关分类任务。在DB-GPT-hub中,我们用lora微调qwen-2-1.5B模型,我们直接从大模型输出的最后一层中提取潜在向量,本来这层最初是为自回归下一个token预测而设计的。现在我们将这些向量通过前馈层映射到标签空间中,产生用于判别标签分类的逻辑。从实验结果来看,模型输出的准确率和稳定性是最高的。
4.2 槽位提取
处理用户查询时,需要识别query中的关键槽位(slot),并根据这些槽位在数据库中进行精准匹配。例如,用户查询“2023年Q1的净利润”时,系统需要识别时间(2023年Q1)和指标(净利润),据此查询数据库获取结果。我们具体也做了以下实现:- 大模型few-shot:通过few-shot学习,利用少量标注数据对大模型进行训练,使其能够在低资源条件下进行高效的信息抽取。
- 大模型SFT:需要构建槽位抽取的指令微调数据集,输入为用户查询语句,输出为json化的槽位标签及实体。这种方法是通过微调的方式,让大模型理解并输出格式化的槽位抽取结果
- 在大模型上进行token标签监督微调:针对具体的信息抽取任务,对大模型进行类似bert的token分类微调,使其能够准确识别出query中的各个槽位,并进行相应的数据库匹配。但是你需要创建或收集BIO标注格式的槽位分类数据集
sentence = "请问你知道《Harry Potter and the Philosopher's Stone》的作者是谁吗?"[{'entity_group': 'book', 'score': 0.8257975, 'word': "Harry Potter and the Philosopher's Stone", 'start': 6, 'end': 47}]sentence = "近日,北京市市场监管局召集美团等互联网企业负责人,召开落实“长江禁捕打非断链”工作电商平台行政约谈会。"[{'entity_group': '约谈机构', 'score': 0.8824913, 'word': '北京市市场监管局', 'start': 3, 'end': 11}, {'entity_group': '公司名称', 'score': 0.9569145, 'word': '美团', 'start': 13, 'end': 15}]
- DB-GPT-Hub/src/dbgpt-hub-nlu/dbgpt_hub_nlu/ner.py at nlu · eosphoros-ai/DB-GPT-Hub · GitHub
五、Text2SQL
财务分析过程中,大模型Text2SQL的能力很关键。用户查询经过意图识别后,输出意图如果为数据分析类,则会调用为Text2SQL模块进行数据查询与计算。
- 数据库结构 - 构建一个元数据字典,用来描述数据库的结构,包括表名、字段名及其类型、表之间的关系等,将其插入数据查询prompt - 将实体-关系(ER)图抽象成文本表示,例如 实体和属性 + 公司 - 属性:公司名称、注册地址、法定代表人、成立日期等。 + 财务报表 - 1. 属性:报表编号、报表类型(如资产负债表、利润表、现金流量表)、报告期间)等。 账户科目 - 1. 属性:科目代码、科目名称、账户类型(如资产、负债、收入、费用)、金额等。 关系描述: + 资产负债表包含了货币资金、应收账款等资产科目,以及短期借款、应付账款等负债科目。属性:购买日期(日期)、数量(整数)、总金额(小数)等。 + 利润表包含了营业收入、营业成本等收入和费用科目。 约束和约定: + 公司实体的主键是公司编号。账户科目实体的外键是报表编号,参照于财务报表实体的主键。 - 优化本地数据库结构,尽量减少复杂查询,将关键信息或常用数据放入一张大宽表中进行处理
- Query查询预处理: - 对查询语句进行信息抽取,将关键实体与关系与schema信息匹配,然后链接映射到具体的数据库表中 - 可构建query-sql_template对进行分类训练,按照不同难度配比生成不同模板下的SQL语料集,用户输入query,应输出对应的sql模板或相应集合,再尝试填充或直接放入prompt中。 - 针对复杂查询可以将其分解为几个简单查询逐步生成SQL语句
- SQL优化 - 在prompt中告诉模型使用索引和适当的查询优化策略,提升SQL查询性能,避免全表扫描等低效操作。 - 将生成的SQL查询在数据库上执行,并验证结果是否符合预期,不符合预期应反馈给用户或执行专门的复杂查询链路
5.1 基础信息查询
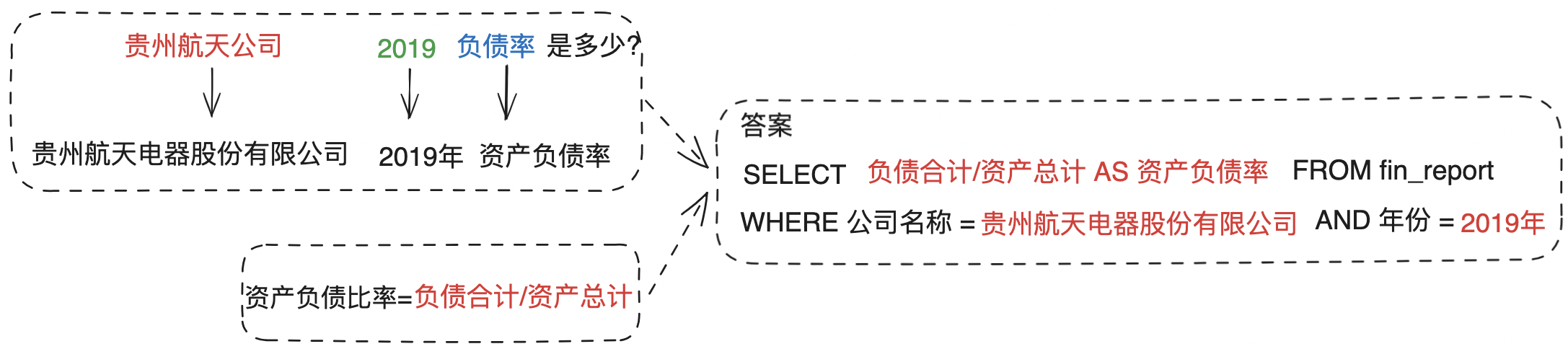
基础信息查询最大的挑战就是需要找到正确的数据列,将原始查询信息进行改写。包括公司名称,年份,查询信息意图,如果用户输入’贵州航天公司2019代表人是谁’基础信息问题,如果不做任何改写,生成的sql就变成了’SELECT 代表人 FROM fin_report WHERE 公司名称=’贵州航天公司’,这样生成的sql执行的结果肯定是不正确的。因此需要根据正确的数据列预先对查询进行改写,这样生成sql才是符合预期的。
5.2 财务指标计算
财务分析中常用许多专业财务指标描述企业经营状况,例如资产负债率、营业利润率、速动比率等。这要求模型能够利用这些公式计算特定财务指标。因此我们需要事先建立财务计算指标公式库,例如:与基础信息查询不同的是,财务指标计算需要预置指标库,将指标的计算公式通过RAG方式进行召回,帮助模型更好的理解指标的计算规则是什么。
"毛利率": {"公式": "毛利率=(CAST(营业收入)-CAST(营业成本))/CAST(营业收入)", "数值": ["营业收入", "营业成本"]},"营业利润率": {"公式": "营业利润率=CAST(营业利润)/CAST(营业收入)", "数值": ["营业利润", "营业收入"]},"流动比率": {"公式": "流动比率=CAST(流动资产合计)/CAST(流动负债合计)", "数值": ["流动资产合计", "流动负债合计"]},"速动比率": {"公式": "速动比率=(CAST(流动资产合计)-CAST(存货))/CAST(流动负债合计)", "数值": ["流动资产合计", "存货", "流动负债合计"]},"资产负债比率": {"公式": "资产负债比率=CAST(负债合计)/CAST(资产总计)", "数值": ["负债合计", "资产总计"]},"现金比率": {"公式": "现金比率=CAST(货币资金)/CAST(流动负债合计)", "数值": ["货币资金", "流动负债合计"]},"非流动负债合计比率": {"公式": "非流动负债合计比率=CAST(非流动负债合计)/CAST(负债合计)", "数值": ["非流动负债合计", "负债合计"]},"流动负债合计比率": {"公式": "流动负债合计比率=流动负债合计/负债合计", "数值": ["流动负债合计", "负债合计"]},"净利润率": {"公式": "净利润率=CAST(净利润)/CAST(营业收入)", "数值": ["净利润", "营业收入"]}
5.3 信息统计分析
统计分析类别中,常常需要涉及分组(GROUP BY)和排序(ORDER BY), 因此,除了前面讲到的需要召回到具体查询的数据列以后,还需要召回统计维度和规则,是需要分组还是需要排序等等。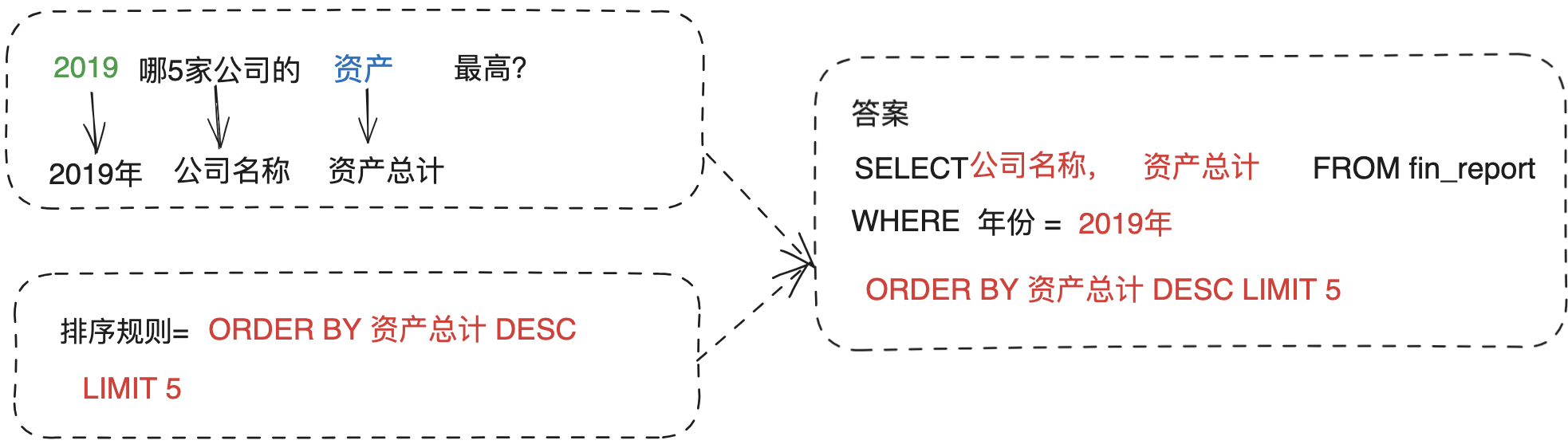
六、金融知识检索
通过对查询进行意图识别后,通过知识检索模块,根据用户的query精准的找到相关性比较高、有一定时效性、比较丰富的内容。目前分为四个阶段,query的改写,元数据过滤,多级召回以及相关性重排序。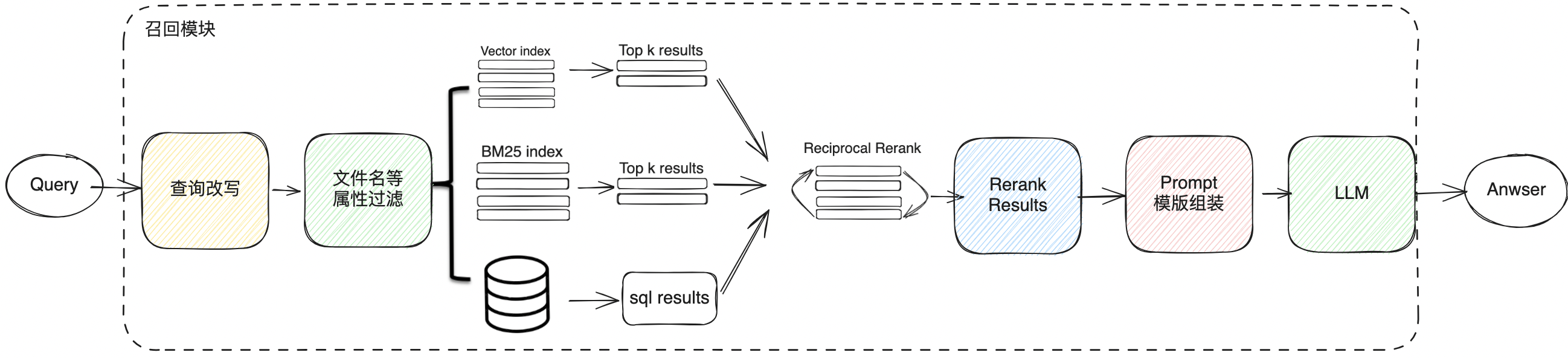
6.1 查询改写
有了意图识别后,查询改写目的是将用户的query改写成语义更清晰、含义更丰富的一个可检索的Query。比如用户问贵州公司资产负债率是多少,但是实际数据库存的公司名称是贵州航天电器股份有限公司,因此需要对查询的主体进行补全改写,当然常用的改写手段还有查询纠错,使用大模型来进行改写等等。通过这一系列的处理,最终目的是把用户的Query从一个主体缺失,语义不明确、不完整、有歧义、有错的改写成一个正确的、语义表达清晰的,可召回的Query。| 原始Query | 改写方法 | 改写后Query |
|---|---|---|
| 贵州公司资产负债率是多少 | 主体补全 | 贵州航天电器股份有限公司资产负债率是多少 |
| guizhouhangtian公司会上市吗 | 纠错 | 贵州航天电器股份有限公司会上市吗 |
| 贵州航天为啥不涨 | Context+LLM改写 | 贵州航天电器股份有限公司A股市场为什么一直低迷,什么时候才能复苏 |
6.2 元数据过滤
当我们把索引分成许多chunks并且都存储在相同的知识空间里面,检索效率会成为问题。比如用户问浙江我武科技公司相关信息时,并不想召回其他公司的信息。因此,如果可以通过公司名称元数据属性先进行过滤,就会大大提升效率和相关度。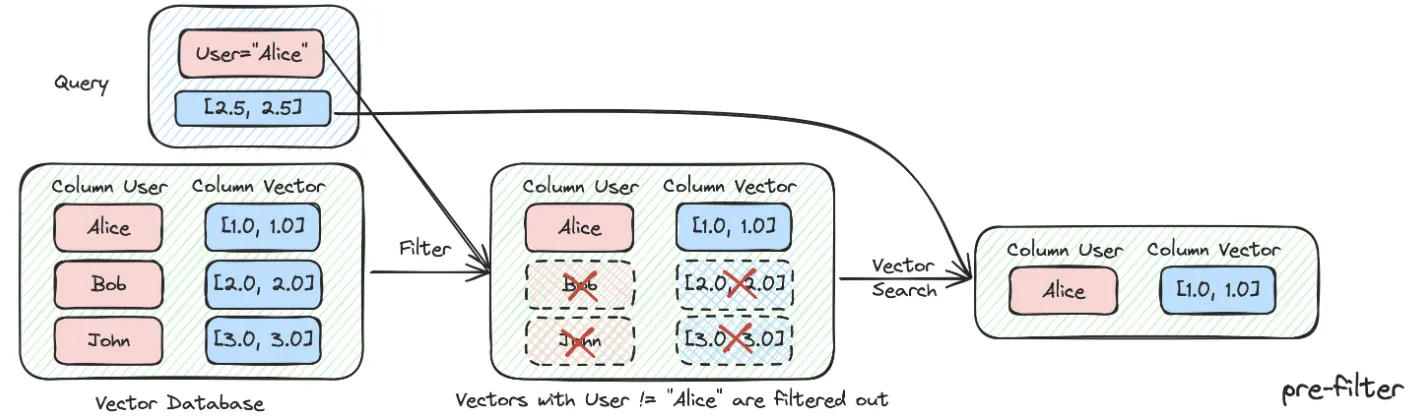
6.3多级召回
传统Native RAG的做法是依靠向量相似度进行单独召回获取相关上下文,如果只靠向量相似度召回,可能检索的内容存在缺失或者语义不够完整的问题,因此在财报除了向量相似度召回以外,我们也需要关键词召回,文档树召回,SQL计算召回和GraphRAG召回来弥补Native RAG的单一召回完整性不够的问题。- 关键词召回:通过构建全文索引,通过原始查询通过分词,通过BM25将相关文档块进行检索,这种召回方式对要求精确性的检索场景非常适用。
- 文档树召回:在前面的知识构建模块中讲到了可以通过构建一棵文档多叉树,因此在检索过程中,可以使用图的广度优先遍历算法将匹配到文档标题的内容的所有叶子节点进行召回,弥补了向量召回的完整性缺失问题。
- SQL召回:对涉及财报统计或者指标计算场景中,需要进行根据用户问题生成需要的sql进行数据分析。
6.4 相关性重排序
有时候随着知识空间的文档越来越多,我们的检索结果并不理想,原因是chunks在系统内数量很多,我们检索的维度不一定是最优的,一次检索的结果可能就会在相关度上面没有那么理想。仅仅靠embedding模型的向量召回,这时候我们需要有一些策略来对检索的结果做重排序,比如使用planB重排序,或者把组合相关度、匹配度等因素做一些重新调整,得到更符合我们业务场景的排序。因为在这一步之后,我们就会把结果送给LLM进行最终处理了,所以这一部分的结果很重要。 与Embedding模型不同,重排序模型以查询和上下文作为输入,直接输出相似度分数,而不是Embeddings。重要的是要注意,重新排序模型是使用交叉熵损失函数进行优化的,允许不限于特定范围的相关性分数,甚至可以是负的。目前,没有很多可用的重排模型。一种选择是Cohere提供的在线模型,可以通过API访问。还有一些开源模型,如bge-reranker-base和bge-reranker-large等。七、实践
` 本章节会介绍怎么通过AWEL表达式语言实现金融财报答疑机器人应用。安装金融财报分析应用相关教程: Agentic Workflow Expression Language(AWEL)是一套专为大型模型应用开发而设计的智能代理工作流表达语言。它提供了强大的功能和灵活性。通过AWEL,我们可以自定义财务分析的各个环节,从数据收集、清洗、解析到最终的报告生成,形成一个完整的自动化分析链路。在财务分析系统中,不同任务可由不同的AWEL workflow协同完成。例如,一个workflow负责财务报告的知识加工,另一个workflow负责投资评级。通过AWEL编排,让不同的agent可以协同工作,实现更复杂和全面的财务分析任务。:::success 财报知识加工workflow
:::

<font style="color:#333333;">KnowledgeLoaderOperator</font>:负责财报知识的加载和数据预处理,将pdf非结构化文本数据处理为标准的json格式化数据。<font style="color:#333333;">KnowledgeExtractBranchOperator</font>:知识提取分支算子,哪些数据需要文本进行提取,哪些数据需要进行表格进行提取。<font style="color:#333333;">FinTextExtractOperator</font>:金融知识文本信息提取算子,根据第一步提取的json数据,合并文本部分信息,将文本信息进行计算和切片。<font style="color:#333333;">FinTableExtractorOperator</font>:金融表格信息提取算子,负责提取并汇总金融的基础信息表格,金融信息表格和其他信息表格,这里的处理需要很多细节的优化,包括表格直接的衔接,行列的转换等等。<font style="color:#333333;">VectorStorageOperator</font>: 向量存储算子,负责将文本信息进行embedding到向量数据库。<font style="color:#333333;">DatabaseStorageOperator</font>:数据库存储算子,负责讲提取的金融信息表格存储到关系型数据库中。<font style="color:#333333;">FinKnowledgeJoinOperator</font>:进行最后的结果处理。
:::success 财报智能问答workflow
:::

<font style="color:#333333;">FinIntentExtractorOperator</font>:意图识别算子,将用户的问题按照公司名、年份,意图进行槽位提取。<font style="color:#333333;">QuestionClassifierOperator</font>:问题分类算子,不同于直接Prompt + 调用大模型进行分类,我们采取了社区的dbgpt-nlu方案,通过双塔模型,上游的Embedding任务 + 下游的分类器结合来进行文本分类。<font style="color:#333333;">QuestionClassifierBranchOperator</font>:问题分类分支处理算子:负责将不同种类的问题路由到不同的处理流程中。<font style="color:#333333;">ChatKnowledgeOperator</font>:金融RAG处理流程,结合了查询改写->知识召回->重排序->模型响应生成的处理流程。<font style="color:#333333;">ChatIndicatorOperator</font>:指标计算分析处理流程,结合了查询改写->指标召回->nl2sql->图表显示处理流程。
八、 参考
- GitHub - eosphoros-ai/DB-GPT: AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents
- GitHub - eosphoros-ai/DB-GPT-Hub: A repository that contains models, datasets, and fine-tuning techniques for DB-GPT, with the purpose of enhancing model performance in Text-to-SQL
- GitHub - eosphoros-ai/dbgpts: Intelligent data apps and assets with LLMs
- GitHub - MetaGLM/FinGLM: FinGLM: 致力于构建一个开放的、公益的、持久的金融大模型项目,利用开源开放来促进「AI+金融」。
- GitHub - FlagOpen/FlagEmbedding: Retrieval and Retrieval-augmented LLMs
- GitHub - WhereIsAI/BiLLM: Tool for converting LLMs from uni-directional to bi-directional by removing causal mask for tasks like classification and sentence embeddings. Compatible with 🤗 transformers.

若有收获,就点个赞吧
0 人点赞
