**✨**新特性
**DB-GPT**支持**SiliconCloud**模型,让用户体验到**SiliconCloud**多模型的管理能力。
如何使用:
- 修改环境变量文件
<font style="color:rgb(17, 24, 39);">.env</font>,配置<font style="color:rgb(17, 24, 39);">SiliconCloud</font>模型
# 使用 SiliconCloud 的代理模型LLM_MODEL=siliconflow_proxyllm# 配置具体使用的模型名称SILICONFLOW_MODEL_VERSION=Qwen/Qwen2.5-Coder-32B-InstructSILICONFLOW_API_BASE=https://api.siliconflow.cn/v1# 记得填写您在步骤2中获取的 API KeySILICONFLOW_API_KEY={your-siliconflow-api-key}# 配置使用 SiliconCloud 的 Embedding 模型EMBEDDING_MODEL=proxy_http_openapiPROXY_HTTP_OPENAPI_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/embeddings# 记得填写您在步骤2中获取的 API KeyPROXY_HTTP_OPENAPI_PROXY_API_KEY={your-siliconflow-api-key}# 配置具体的 Embedding 模型名称PROXY_HTTP_OPENAPI_PROXY_BACKEND=BAAI/bge-large-zh-v1.5# 配置使用 SiliconCloud 的 rerank 模型RERANK_MODEL=rerank_proxy_siliconflowRERANK_PROXY_SILICONFLOW_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/rerank# 记得填写您在步骤2中获取的 API KeyRERANK_PROXY_SILICONFLOW_PROXY_API_KEY={your-siliconflow-api-key}# 配置具体的 rerank 模型名称RERANK_PROXY_SILICONFLOW_PROXY_BACKEND=BAAI/bge-reranker-v2-m3
注意,上述的语言模型(**SILICONFLOW_MODEL_VERSION**)、 Embedding 模型(**PROXY_HTTP_OPENAPI_PROXY_BACKEND**)和 rerank 模型(**RERANK_PROXY_SILICONFLOW_PROXY_BACKEND**) 可以从 获取用户模型列表 - SiliconFlow 中获取。
- 通过
<font style="color:rgb(17, 24, 39);">DB-GPT Python SDK</font>使用
pip install "dbgpt>=0.6.3rc2" openai requests numpy
- <font style="color:rgb(17, 24, 39);">使用</font>`<font style="color:rgb(17, 24, 39);">SiliconCloud</font>`<font style="color:rgb(17, 24, 39);">的大语言模型</font>
import asyncioimport osfrom dbgpt.core import ModelRequestfrom dbgpt.model.proxy import SiliconFlowLLMClientmodel = "Qwen/Qwen2.5-Coder-32B-Instruct"client = SiliconFlowLLMClient(api_key=os.getenv("SILICONFLOW_API_KEY"),model_alias=model)res = asyncio.run(client.generate(ModelRequest(model=model,messages=[{"role": "system", "content": "你是一个乐于助人的 AI 助手。"},{"role": "human", "content": "你好"},])))print(res)
更多使用方式参考在 DB-GPT 中使用 - SiliconFlow
- 新增知识处理工作流,支持
**Embedding加工**,**知识图谱加工**,**混合知识加工**处理。
目前DB-GPT知识库提供了文档上传-> 解析 -> 切片 -> Embedding -> 知识图谱三元组抽取 -> 向量数据库存储-> 图数据库存储等单一的知识加工的能力,但是不具备对文档进行复杂的,多元化的信息抽取能力,因此希望通过构建知识加工工作流来完成复杂的,多元化的,可视化的,用户可自定义的知识抽取,转换,加工流程。
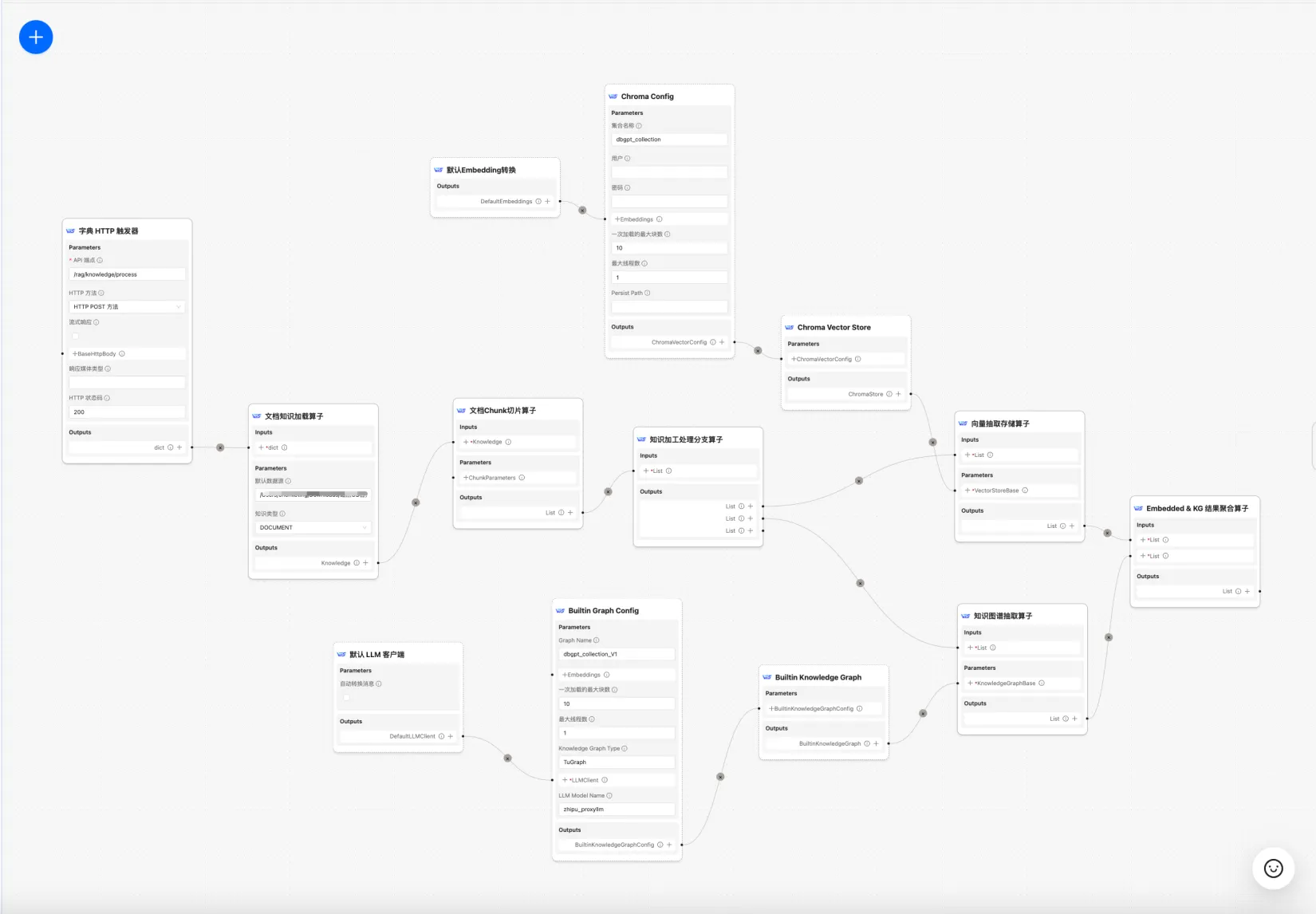
如何使用:
- 导入工作流模版
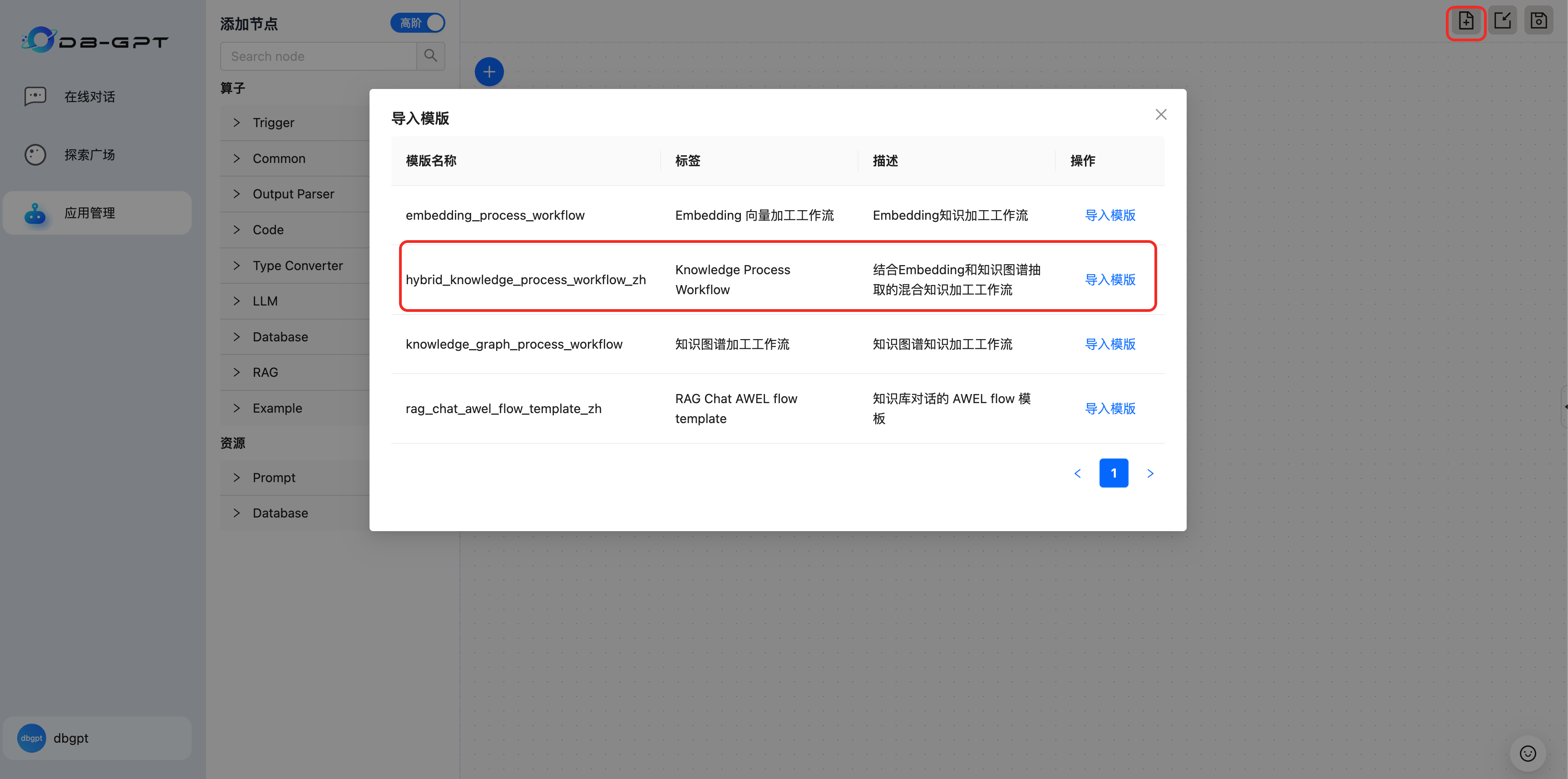
- 保存并注册为服务
curl --location --request POST 'http://localhost:5670/api/v1/awel/trigger/rag/knowledge/hybrid/process' \--header 'Content-Type: application/json' \-d '{}'
["async persist vector store success 9 chunks.","async persist graph store success 9 chunks."]
更多使用方式参考 知识加工
**ChatData**场景支持**OceanBase**向量可视化

**GraphRAG**社区总结优化,通过并行总结抽取提升索引构建性能
GraphRAG,作为DB-GPT开源项目的重要模块之一,近期获得了显著的技术改进和性能提升。这个创新框架通过巧妙结合图数据库技术与检索增强生成(RAG)方法,在处理复杂数据关系任务上展现出优越性能。
核心改进包括三个关键方面:
- 首先,引入了文档结构(Document Structure)索引,通过识别文档的层级关系,构建了包含”next”(顺序关系)和”include”(包含关系)两种边的有向图结构。
- 其次,在知识图谱构建环节,创新性地采用了”上下文增强”方法和并发抽取优化,将任务处理时间降低至原有耗时的20%。
- 第三,实现了多维度的检索框架,包括三元组图谱检索(局部)、社区摘要检索(全局)和文档结构检索(原文)。
在基于TuGraph基座的图数据建模阶段,GraphRAG 定义了三种节点类型(document、chunk、entity)和五种边类型(包含关系边和顺序关系边),为知识图谱的构建和检索提供了坚实的基础。在社区摘要方面,采用Leiden算法进行社区检测,通过社区文本化和总结,提供了知识的宏观视角。
相比微软的GraphRAG方案,DB-GPT GraphRAG避免了中间态回答(微软GraphRAG一个中间过程)可能带来的信息损失和语义理解偏差,同时我们还支持文档结构溯源,能够为用户提供更可靠的原文参考信息。这些改进使得GraphRAG在保持知识完整性的同时,显著提升了系统性能和用户体验。
在性能测试方面,与微软版本的GraphRAG相比,DBGPT GraphRAG在保持相近的文档输入规模(42,631 tokens)的情况下取得了显著成果:总Token消耗降低至42.9%(417,565 vs 972,220),生成Tokens量减少至18.4%(41,797 vs 227,230),构建知识图谱的时间缩短至80.1%(170s vs 210s)。同时,对照组和实验组的图谱结构均保持了相当的复杂度(734节点/1164边 vs 779节点/967边),确保了知识表示的完整性。
展示示例:(GraphRAG 也可以向用户展示数据来源/原始文档)

总得来说,GraphRAG取得了不错的效果:在构建同样规模的知识图谱的情况下,我们在构建图谱这个任务上,花费了更少的时间(约80%),消耗了更少的 tokens (约40%)。同时,在回答需要全局检索的用户问题时,根据测试结果,我们版本的 GraphRAG 在时间和 tokens 的消耗上更具优势。此外,我们的 GraphRAG 得益于文档结构的支持,可以搜索原文,并将原文作为参考文本的一个部分返回给用户,让用户可以获得更可靠的原文信息。
后续,我们将支持更加复杂、更加智能的检索链路(相似度检索、自然语言转GQL检索)。DB-GPT GraphRAG的演进一直在路上,敬请期待。
**ChatData**针对大宽表场景进行**Schema-Linking**优化
测试大宽表sql:
/DB-GPT/docker/examples/sqls/case_3_order_wide_table_sqlite_wide.sql
- 聊天对话支持
**max output tokens**参数
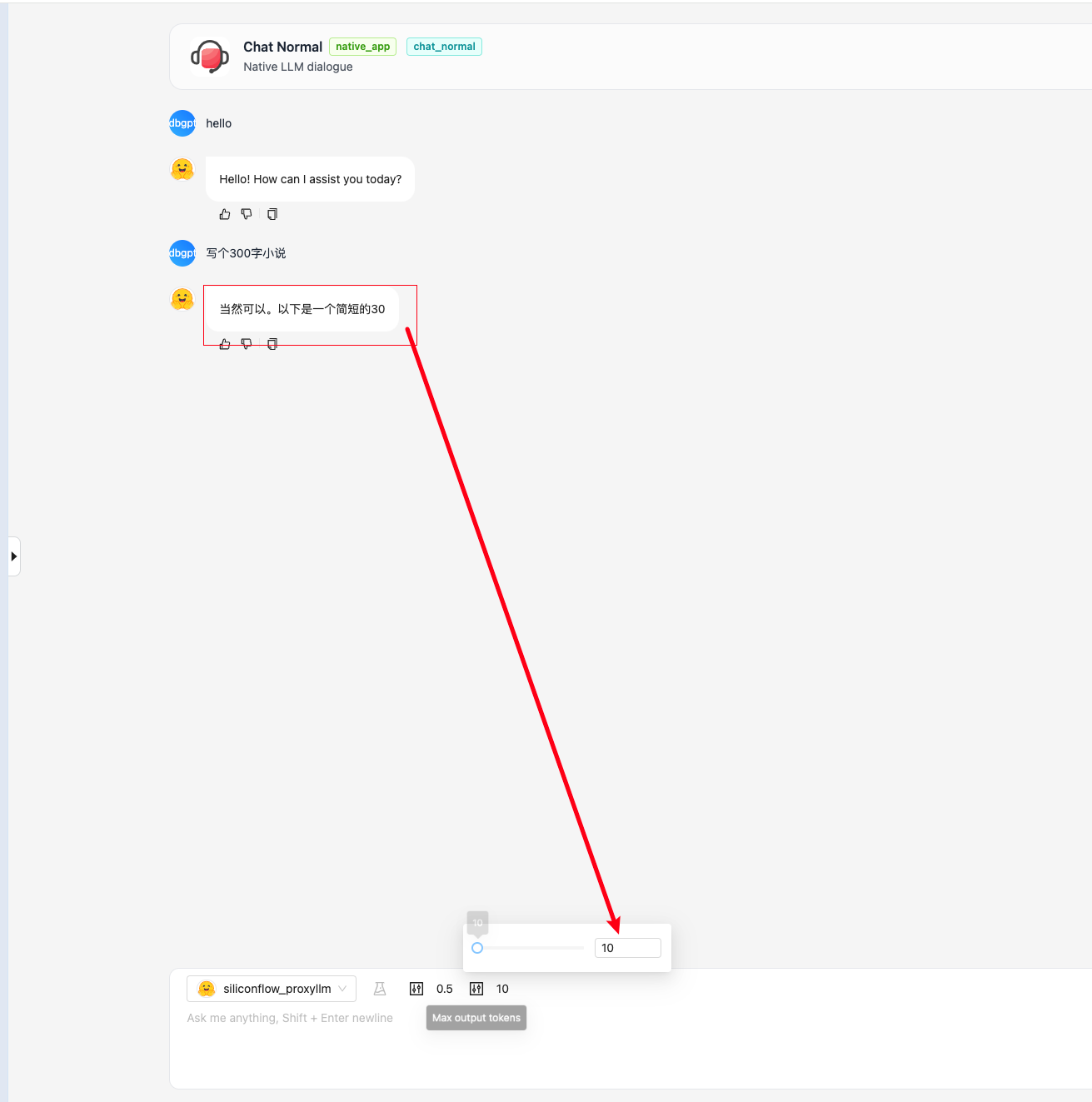
如何设置:
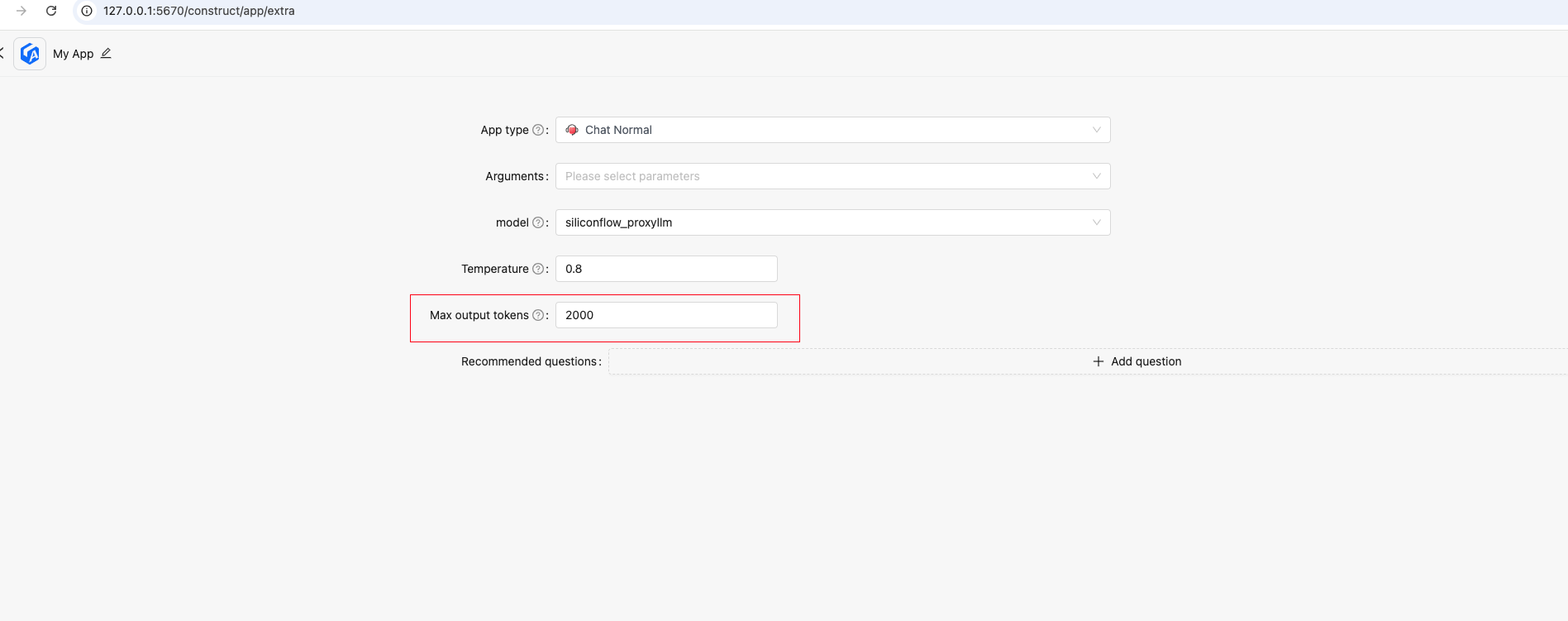
- 支持
**Claude**模型服务
.env文件进行配置
LLM_MODEL=claude_proxyllmANTHROPIC_MODEL_VERSION=claude-3-5-sonnet-20241022ANTHROPIC_BASE_URL=https://api.openai-proxy.org/anthropicANTHROPIC_API_KEY={your-claude-api-key}
- python使用
import asynciofrom dbgpt.core import ModelRequestfrom dbgpt.model.proxy import ClaudeLLMClientclient = ClaudeLLMClient(model_alias="claude-3-5-sonnet-20241022")print(asyncio.run(client.generate(ModelRequest._build("claude-3-5-sonnet-20241022", "Hi, claude!"))))
**Agent**支持上下文记忆
通过在.env文件进行设置
MESSAGES_KEEP_START_ROUNDS=0MESSAGES_KEEP_END_ROUNDS=2
🐞 Bug 修复
- 修复了删除图空间后创建同名问题
- 修复了构建
Docker镜像问题 - 修复了
httpx v0.28.0 proxies问题 - 修复
Chat Data fix sql not found error问题 - 修复了
EmbeddingAssemblerOperator算子连接问题 - 解决
fastapi版本问题
🛠️其他
- 发布
DB-GPT Agent论文ROMAS: A Role-Based Multi-Agent System for Database monitoring and Planning
论文地址:ROMAS: A Role-Based Multi-Agent System for Database monitoring and Planning
- 升级
dbgpt-tugraph-plugins版本升级到0.1.1 - 升级最新版的
docker镜像
✨**官方文档地址**
:::color2 英文
:::
:::color2 中文
:::
✨**致谢**
感谢所有贡献者使这次发布成为可能!@Appointat, @Aries-ckt, @FOkvj, @GITHUBear, @HYSMN, @Sween1y, @fangyinc, @fanzhidongyzby, @toralee and @yhjun1026

✨**附录**

若有收获,就点个赞吧
0 人点赞
