Service-oriented Multi-model Management Framework(SMMF) 服务化多模型管理框架。
背景
在AIGC应用探索与生产落地中,难以避免直接与模型服务对接,但是目前大模型的推理部署还没有一个事实标准,不断有新的模型发布,也不断有新的训练方法被提出,我们需要花大量的时间来适配多变的底层模型环境,而这在一定程度上制约了AIGC应用的探索和落地。
设计
为了简化模型的适配流程,提高模型部署效率和性能,我们提出了基于服务化的多模型管理框架(Service-oriented Multi-Model Management Framework,简写为SMMF)。
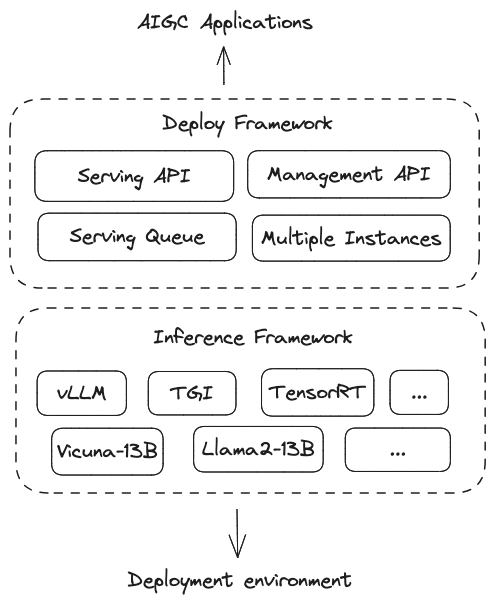
SMMF由模型推理层、模型部署层两部分组成。模型推理层对应模型推理框架vLLM、TGI和TensorRT等。模型部署层向下对接推理层,向上提供模型服务能力。 模型部署框架在推理框架之上,提供了多模型实例、多推理框架、多云、自动扩缩容【1】与可观测性【2】等能力。
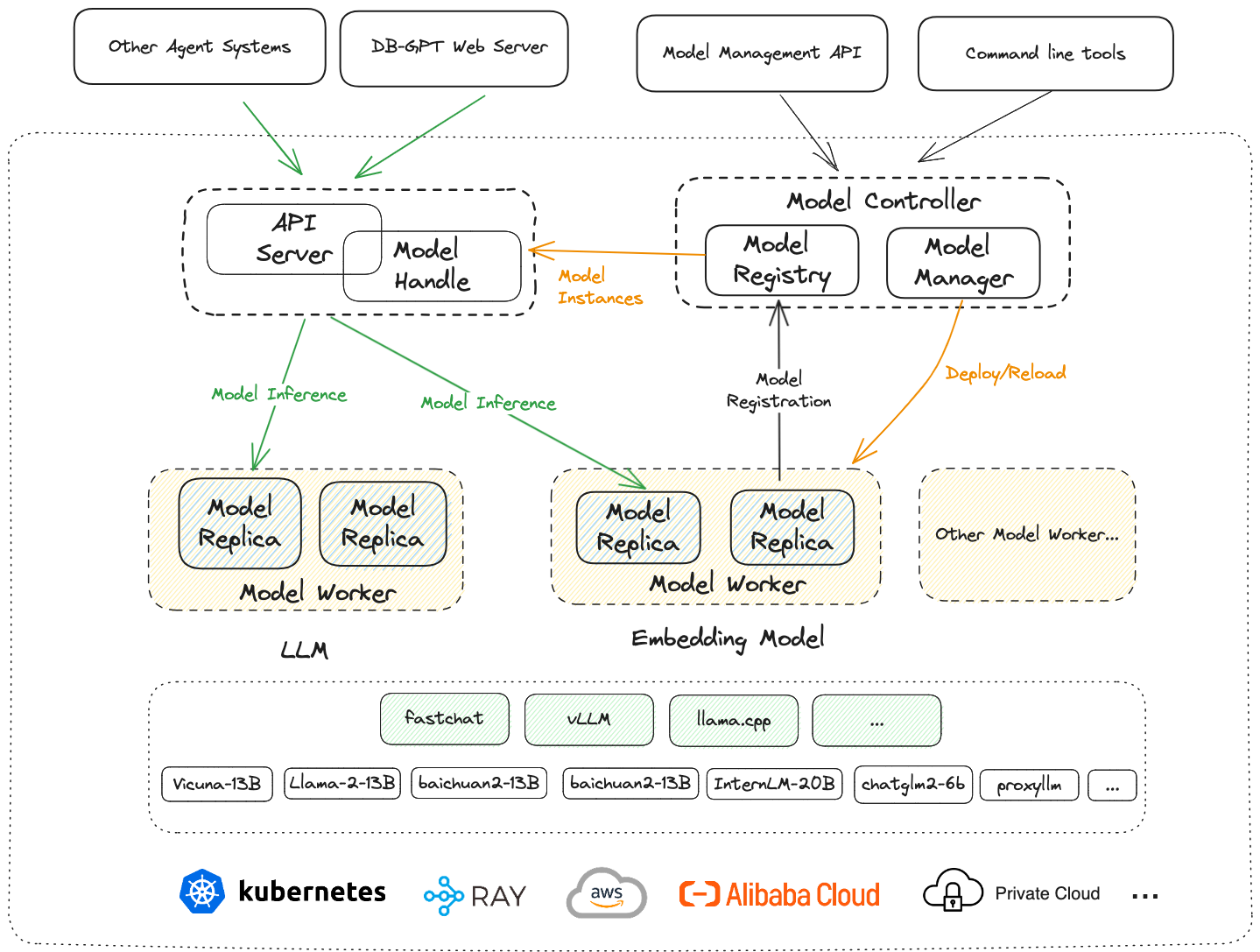
在DB-GPT中,SMMF具体如上图所示: 最上层对应服务与应用层(如DB-GPT WebServer、Agents系统、应用等)。 下一层是模型部署框架层,这层包含了对应用层提供模型服务的APIServer和Model Handle、整个部署框架的元数据管理和控制中心Model Controller和与推理框架和底层环境直接对接的Model Worker。再下一层是推理框架层,这层包含了vLLM、llama.cpp和FastChat(由于DB-GPT直接使用了FastChat的推理接口,这里我们将FastChat也归为推理框架),大语言模型(Vicuna、Llama、Baichuan、ChatGLM)等部署在推理框架中。 最下面一层则是实际部署环境,包括Kubernetes、Ray、AWS、阿里云和私有云等。
SMMF特色能力
- 支持多模型和多推理框架
- 良好的拓展性和稳定性
- 良好的框架性能
- 可管理、可监控
- 轻量化
支持多模型与多推理框架
当前大模型领域的发展可谓日新月异,不断有新的模型发布,在模型训练和推理方面,也不断有新的方法被提出。我们判断,这样的情况还会持续一段时间。
对于大部分AIGC应用场景探索和落地的用户来说,这种情况有利也有弊。典型的弊端是被模型”牵着鼻子走”,需要不断去尝试和探索新的模型、新的推理框架。
在DB-GPT中,直接提供了对FastChat、vLLM和llama.cpp的无缝支持,理论上他们支持的模型,DB-GPT都支持,如果您对推理速度与并发能力有需求,可以直接使用vLLM,如果您希望CPU或者Mac的M1/M2芯片也获得不错的推理性能,可以使用llama.cpp,此外,DB-GPT也支持代理模型, 如: OpenAI、Azure、Google Bard、通义、百川、讯飞星火、百度文心、智谱AI等。
支持模型列表
代理模型
开源模型
- Vicuna
- vicuna-13b-v1.5
- LLama2
- baichuan2-13b
- baichuan2-7b
- chatglm-6b
- chatglm2-6b
- chatglm3-6b
- falcon-40b
- internlm-chat-7b
- internlm-chat-20b
- qwen-7b-chat
- qwen-14b-chat
- wizardlm-13b
- orca-2-7b
- orca-2-13b
- openchat_3.5
- zephyr-7b-alpha
- mistral-7b-instruct-v0.1
- Yi-34B-Chat
:::warning 更多模型请参考源码
:::
良好的拓展性和稳定性
云原生领域解决了海量计算资源的管控、调度、利用等核心痛点问题。 让计算的价值被充分释放,使得大规模的计算成为了普适技术。
在大模型领域,我们也关注到在模型推理过程中,对于计算资源爆炸式需求。所以具备调度超算能力的多模型管理是我们生产落地中所重点关注的。 鉴于在过去几年Kubernetes、Istio等计算调度层取得的卓越成绩,因此我们在多模型管控方面充分借鉴了相关的设计理念。
一个比较完善的模型部署框架需要多个部分组成,与底层推理框架直接对接的Model Worker,管理和维护多个模型组件的Model Controller以及对外提供模型服务能力的Model API。其中Model Worker必须要可扩展,可以是专门部署大语言模型的Model Worker,也可以是用来部署Embedding模型的Model Worker,当然也可以根据部署的环境,如物理机环境、kubernetes环境以及一些特定云服务商提供的云环境等来选择不同的Model Worker。
用来管理元数据的Model Controller也需要可拓展,不同的部署环境以及不同的模型管控要求来选择不同的Model Controller。此外,从技术角度来看,模型服务与传统的微服务有很多共同之处,在微服务中,微服务中某个服务可以有多个服务实例,所有的服务实例都统一注册到注册中心,服务调用方根据服务名称从注册中心拉取该服务名对应的服务列表,然后根据一定的负载均衡策略选择某个具体的服务实例去调用。
而在模型部署中,也可以考虑类似的架构,某一个模型可以有多个模型实例,所有的模型实例都统一注册到模型注册中心,然后模型服务调用方根据模型名称到注册中心拉取模型实例列表,然后根据模型的负载均衡策略去调用某个具体的模型实例。
这里我们引入模型注册中心,它负责存储Model Controller中的模型实例元数据,它可以直接使用现有微服务中的注册中心作为实现(如nacos、eureka、etcd和console等),这样整个部署系统即可做到高可用。
良好的框架性能
框架层不应该成为模型推理性能的瓶颈,大部分情况下, 硬件及推理框架决定了模型服务的能力,模型的推理部署和优化是一项复杂的工程,而不恰当的框架设计可能增加这种复杂度,在我们看来,部署框架为了性能上”不拖后腿”,有两个主要的关注点:
- 避免过多的封装: 封装越多、链路越长,性能问题越难以排查。
- 高性能的通信设计: 高性能通信设计的点很多,这里不过多阐述。 由于目前AIGC应用中,Python占据领导地位,在Python中,异步接口对服务的性能至关重要。因此,模型服务层只提供异步接口,与模型推理框架对接层做兼容,如果模型推理框架提供了异步接口则直接对接。否则使用同步转异步任务的方式支持。
可管理、可监控
在AIGC应用探索中或者AIGC应用生产落地中,我们需要模型部署系统具备一定管理能力,通过API或者命令行等部署的模型实例进行一定管控(如: 上线、下线、重启、Debug等)
可观测性是生产系统一项非常重要的能力,我们认为在AIGC应用中,可观测性至关重要。因为用户体验、用户与系统的交互行为更复杂,除了传统的观测指标之外,我们还更加关心用户的输入信息及其对应的场景的上下文信息。调用了哪个模型实例和模型参数,模型的输出内容与响应时间、用户反馈等。
我们可以从这些信息中发现一部分模型服务的性能瓶颈,以及一部分用户体验数据
- 响应延迟如何?
- 是否解决了用户的问题以及用户内容中提取用户满意度等?
这些都是整个应用进一步优化的依据。
轻量化
考虑到支持的模型和推理框架众多,我们需要努力避免不必要的依赖,确保用户可以做到按需安装。
在 DB-GPT 中,用户可以按需安装自己的依赖,一些主要可选依赖如下:
- 安装最基础的依赖
pip install -e .或者pip install -e ".[core]" - 安装基础框架的依赖
pip install -e ".[framework]" - 安装 openai 代理模型的依赖
pip install -e ".[openai]" - 安装默认的依赖
pip install -e ".[default]" - 安装 vLLM 推理框架的依赖
pip install -e ".[vllm]" - 安装模型量化部署的依赖
pip install -e ".[quantization]" - 安装知识库相关依赖
pip install -e ".[knowledge]" - 安装 pytorch 的依赖
pip install -e ".[torch]" - 安装 llama.cpp 的依赖
pip install -e ".[llama_cpp]" - 安装向量化数据库的依赖
pip install -e ".[vstore]" - 安装数据源的依赖
pip install -e ".[datasource]"
实现
多模型相关的实现,可以参见源码
附录
- 【1】【2】自动扩缩容与可观测性等能力目前还在孵化当中,还未具体实现。

若有收获,就点个赞吧
0 人点赞
