DB-GPT中引入了知识空间的概念,每一个知识空间支持参数定制,包括向量检索的相关参数和知识问答提示的参数。
进入调参界面
如下图所示,点击知识空间, 会弹出对话框。 点击Arguments 按钮。即可进入到调参界面。

Embedding参数
**top-k: **相似度最高的K个文本。**recall_score:**召回分数,取值范围[0, 1], 1代表最相似,0代表完全不相关,默认0.3**recall_type:**top-k, 向量召回最相似的k个文本。**model: **向量化Embedding模型**chunk_size:**每个文本切块大小**chunk_overlop: **相邻数据块之间的重叠量

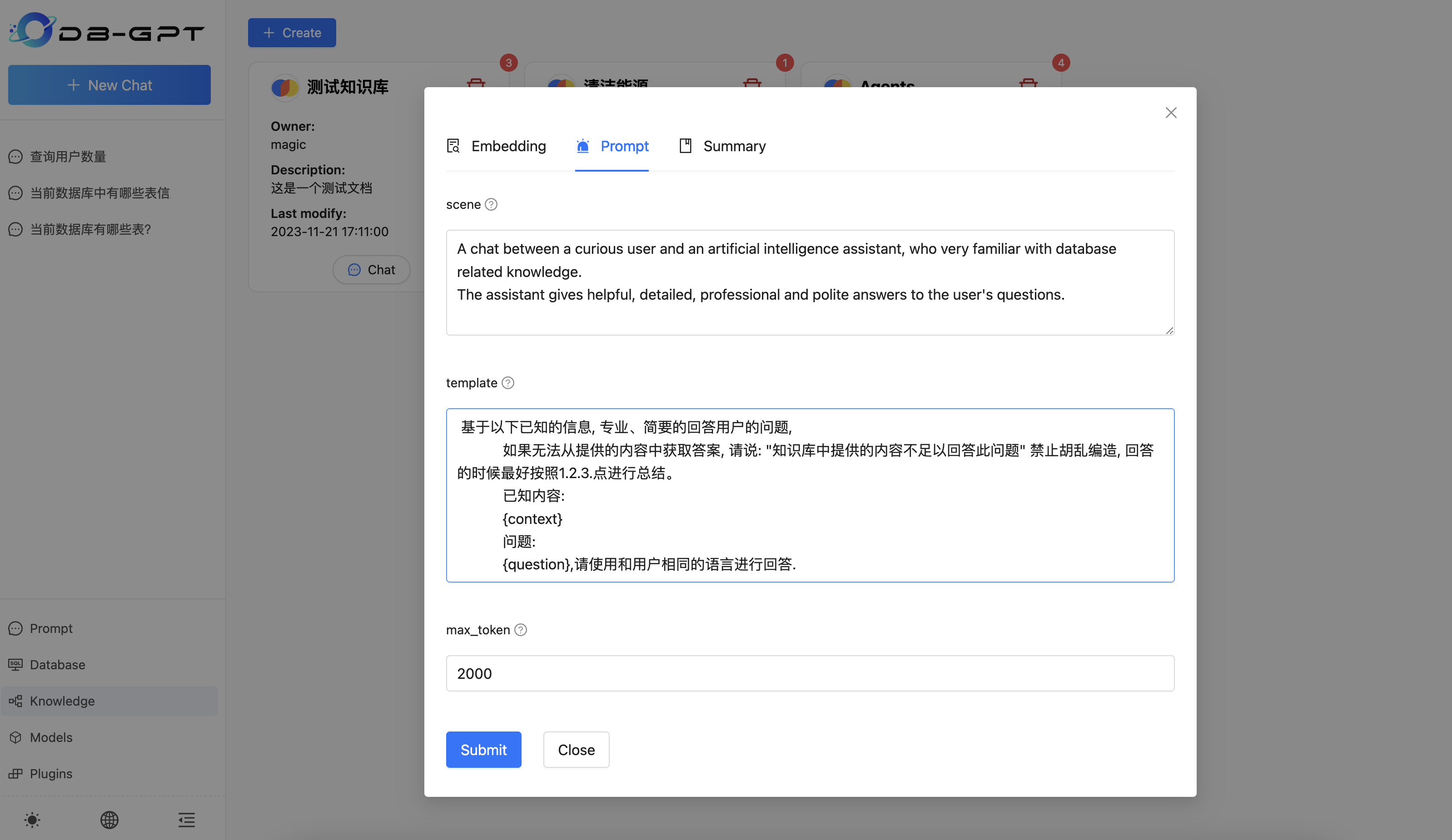
提示词参数
**Scene: **场景也就是系统提示词。**Template**: 提示词模版**max_token:**限定的token长度
文档总结
主要用于文档上传时,形成全文总结。
**<font style="color:rgba(0, 0, 0, 0.88);">max_iteration:</font>**跟模型交互的最大迭代次数, 主要用于知识总结。**<font style="color:rgba(0, 0, 0, 0.88);">concurrency_limit: </font>**限制与模型交互并发数量。
Query改写
在知识库实际应用中,客户过于发散的问题(或者错误的输入), 我们的知识库不足以回答。 此时需要对用户的Query做一些改写。DB-GPT提供了Query改写的能力,在环境变量中.env,设置KNOWLEDGE_SCHEMA_REWRITE=True,然后重启服务,即可生效查询重写能力。
# Whether to enable Chat Knowledge Search Rewrite ModeKNOWLEDGE_SEARCH_REWRITE=True
切换向量数据库
Chroma
在.env 配置文件中,设置数据库类型 VECTOR_STORE_TYPE。
### Chroma vector db configVECTOR_STORE_TYPE=Chroma#CHROMA_PERSIST_PATH=/root/DB-GPT/pilot/data
Milvus
在.env 配置文件中,设置数据库类型。VECTOR_STORE_TYPE
### Milvus vector db configVECTOR_STORE_TYPE=MilvusMILVUS_URL=127.0.0.1MILVUS_PORT=19530#MILVUS_USERNAME#MILVUS_PASSWORD#MILVUS_SECURE=
Weaviate
在.env 配置文件中,设置数据库类型。VECTOR_STORE_TYPE
### Weaviate vector db configVECTOR_STORE_TYPE=Weaviate#WEAVIATE_URL=https://kt-region-m8hcy0wc.weaviate.network

若有收获,就点个赞吧
0 人点赞
