Simple is Beautiful! Short Simple Efficient
Some Tips on Optimization
- Choose an appropriate algorithm -> 选择合适的算法,
- Clear and simple code for the compiler to optimize -> 代码要简单、简洁
- Optimize code for memory -> 优化内存(内存连续,速度最快)
- Do not copy large memory -> 避免内存拷贝
- No printf()/cout in loops
- Table lookup (sin(), cos() …) -> 使用查找表,三角函数运算慢,可以提前算出,放到一个数组中,到时候直接查表。
- SIMD, OpenMP -> 并行
- Face detection and facial landmark detection in 1600 lines of source code
- facedetectcnn.h :
- 400 lines
- CNN APIs
- facedetectcnn.cpp:
- 900 lines
- CNN function definitions
- facedetectcnn-model.cpp:
- 300 lines
- Face detection model
- facedetectcnn-int8data.cpp
- CNN model parameters in static variables
- facedetectcnn.h :
SIMD: Single instruction, multiple data
一个指令处理多条数据
SMID将四个元素装载到寄存器中,做两数之和
Intel: MMX, SSE, SSE2, AVX, AVX2, AVX512
ARM: NEON
RISC-V: RVV(RISC-V Vector Extension)
SIMD in OpenCV
“Universal intrinsics” is a types and functions set intended to simplify vectorization of code on different platforms.
https://docs.opencv.org/master/df/d91/groupcorehal__intrin.html
使用OpenCV中的universal intrinsics为算法提速(1)(2)(3)
https://mp.weixin.qq.com/s/_dFQ9lDu-qjd8AaiCxYjcQ
https://mp.weixin.qq.com/s/3UmDImwlQwGX50b1hvz_Zw
https://mp.weixin.qq.com/s/XtV2ZUwDq8sZ8HlzGDRaWA
SIMD是在一个内核中执行的,现在cpu是多核的,那么程序如何才能使用多核运算
OpenMP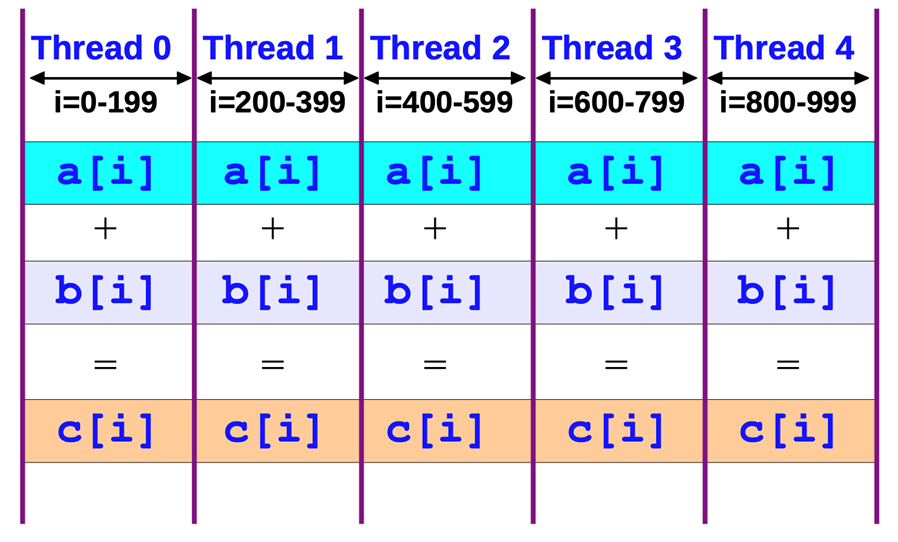
#include <omp.h>#pragma omp parallel forfor (size_t i = 0; i < n; i++){c[i] = a[i] + b[i];}
Where should #pragma be? The 1st loop or the 2nd?
#include <omp.h>
#pragma omp parallel for
for (size_t i = 0; i < n; i++)
{
//#pragma omp parallel for
for (size_t j = 0; j < n; j++)
{
//...
}
}
OpenMP拆解任务并放到各个CPU内核上运行是需要代价的,如果拆解的任务非常简单,这种情况提速不明显,所以一般来说将#pragma omp parallel for放到外部循环。
拆解任务是放到多个内核中去运行,如果内核同时去写同一内存的内容,就会造成数据冲突,OpenMP也没有数据保护机制,所以很容易发生错误。所以要看运算部分的数据是否是相互依赖,如果是,不适合用OpenMP做加速。

若有收获,就点个赞吧
0 人点赞
