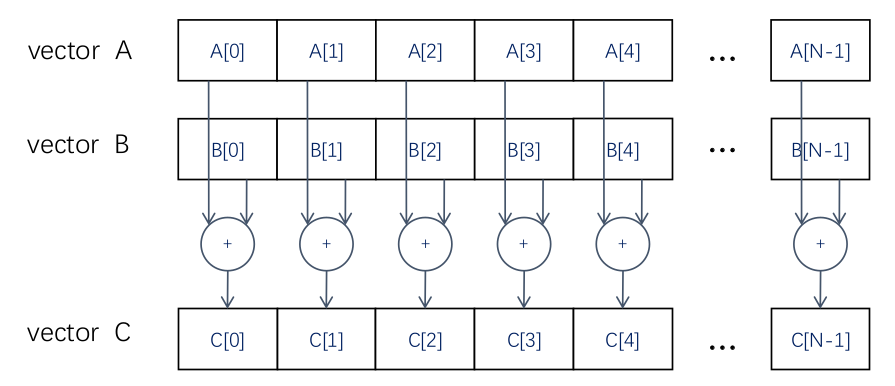
可以看到向量 A 和 B 都是一维、长度是N的向量,得到两向量相加的结果。对于C++语言是非常容易的。
// Compute vector sum C = A+Bvoid vecAdd(float* A, float* B, float* C, int n){for (i = 0, i < n, i++)C[i] = A[i] + B[i]; //CPU中数组相加}int main(){// Memory allocation for A_h, B_h, and C_h// I/O to read A_h and B_h, N elements...vecAdd(A_h, B_h, C_h, N);}
上述代码中,A 和 B 都是一个float 类型的指针,并且已经申请好内存,最终的结果会存放到已经在内存上申请好空间的指针C上。A 跟B是等长的,长度都是N。一个简单的for循环,就可以达到向量相加的目的。
那如何使用CUDA实现向量相加的程序呢?首先回顾一下适合使用CUDA编程的四个特点:
- 访问内存次数少。向量相加程序几乎没有过多访问显存的情况。
- 控制简单,没有复杂的分支预测和数据转发的机制。该程序控制非常简单的,也没有任何的比较、break、continue 的这些分支操作。
- 计算简单,因为GPU中的计算单元是非常精简。向量相加显然满足这个计算简单这个特点。
- 并发高。因为GPU的每一行执行的控制指令是同一个,所以在并行度高的程序上,GPU上吞吐更高的。通过C++程序可以看到,不同的索引
i之间,计算彼此互不影响的。A[i]和B[i]的结果只对C[i]有影响,跟i-1,i+1处的值没有任何关系。
因此向量相加任务符合GPU编程的四个特点。
CUDA编程的三步流程:
下面我们就按照CUDA编程的三大模块,分别介绍如何在GPU上实现向量相加的操作。回顾一下CUDA编程的三大模块:
- 从主机端申请显存、内存,并且将主机端的内容拷贝到设备端。
- 在设备端完成计算操作 ➡️ CUDA核函数。
- 将设备端的结果返回到主机端,并且释放掉申请的主机端和设备端的内存显存。
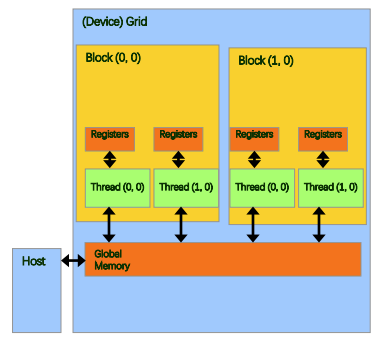 |
- 设备端代码: - 读写线程寄存器 - 读写Grid中全局内存 - 读写block中共享内存 - 主机端代码: - Grid中全局内存拷贝转移 |
|---|---|
设备端要完成哪些的操作:
- 每一个线程的寄存器和独立的内存要去进行访问、读写、计算。
- 对于并行度高,并且会被频繁访问到的内容,会将其放到线程块里的共享内存以及网格里的全局内存,以减少访问寄存器、内存的次数,增加它的吞吐。
- CUDA核函数要在设备端运行,目的就是计算。
cudaMalloc( ) • • • 两个参数 • 地址 • 申请内存大小 cudaFree( ) • • • 指向释放对象的指针
主机端要做的事情其实就是申请显存、内存,然后来去做这个内存显存之间的互相拷贝以及释放。
- 首先第一个函数就是:显存申请函数
cudaMalloc()。cudaError_t cudaMalloc (void **devPtr, size_t size)- 在设备全局内存中分配对象
- 他的目的就是申请显存,去掉前面
cuda,就是C/C++的malloc()函数。 - 参数有两个:
- 参数地址。
- 要申请内存空间的大小。这里一般会用
sizeof(float数据类型)*N完成显存上的申请。
- 显存释放
cudaFree():cudaError_t cudaFree ( void* devPtr )- 从设备全局内存中释放对象
- 同样的把前面
cuda去掉,就是C/C++中的Free()函数。 - 参数:
- 从设备端返回到主机端的指针。
cudaMemcpy():从主机端到设备端,从设备端到主机端,内存和显存之间的互相拷贝。cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)- 目的:内存数据复制传递
- 第一个参数就是:要拷贝到目标地址的对象。第二个对象是const类型的指针,就是起点的指针。第三个是要拷贝的内容大小。同样的,这里我们用
sizeof(float)来去定义它的大小。最后一个参数指明数据传输方向,支持下面这四种这个选项:cudaMemcpyHostToDevice:从主机端拷贝到设备端。cudaMemcpyDeviceToHost:从设备端拷贝到主机端。cudaMemcpyDeviceToDevice:从设备端拷贝到设备端cudaMemcpyDefault:不常用
该函数的拷贝是同步的。还会有
cudaMemcpyAsyn()函数,这是异步的拷贝函数。void vecAdd(float* A, float* B, float* C, int n) { int size = n * sizeof(float); float* A_d, *B_d, *C_d; // Transfer A and B to device memory cudaMalloc((void **) &A_d, size); cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice); cudaMalloc((void **) &B_d, size); cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice); // Allocate device memory for cudaMalloc((void **) &C_d, size); // Kernel invocation code – to be shown later ... // Transfer C from device to host cudaMemcpy(C, C_d, size, cudaMemcpyDeviceToHost); // Free device memory for A, B, C cudaFree(A_d); cudaFree(B_d); cudaFree (C_d); }需要申请的内存大小用
sizeof(float)*N的形式定义的。然后定义*A_d,*B_d,*C_d这三个设备端device 上的指针,我们通过cudaMalloc去申请空间:第一个参数是指针的地址;第二个参数就是需要申请的空间大小。要想访问一定要先申请地址,然后再拷贝cudaMemcpy,把内存中*A_d位置中的内容拷贝到device ,然后执行的方向就是从主机到设备。b 是类似的。然后调用kernel函数。之后把设备端计算好的*C_d的内容拷贝到主机端的C上,然后执行的方向是从设备到主机,然后执行。之后要把设备端申请好的空间释放掉。
所以我们通过这三个函数的介绍,就把第一步和第三步这两步的操作把它介绍完了。下面我们就进入最核心的第二步:核函数的编写。这里在介绍具体怎么写kernel函数之前,我们讲一讲核函数的几个性质:
- 它是在设备端GPU上执行的函数
- 一般会用
__global__修饰核函数 - 函数的调用时,必须要用
<<<参数1, 参数2 >>>的形式来去里边把它的参数写到里边。- 第一个参数是线程的数量;
- 第二个参数是线程块数量。
- 因为多个线程块构成网格Grid,而每个线程块又由若干个线程 (thread)组成
- 内核调用时,这个核函数的执行参数是必须要给到的,不能为空
- 在编程时,必须先为kernel函数中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算 时会发生错误。
- 在GPU编程的时候,一定要切记就是在调用核函数之前,核函数所用到的数组或者变量,一定要使用
cudaMalloc申请好地址,而且宁可多申请一点,也不要少申请,不要发生内存越界。因为一旦没有申请或者是发生了内存显存不够,他在调用cuda函数的时候就会发生了segmentation False。这是让我们一头雾水的一个错误,非常讨厌的一个错误。如果发生,就只能退回到核函数里面去调试寻找错误点,判断到底怎么发生的错误。所以宁可多申请内存,用不到,也不要发生没有申请或者申请不够的情形。
- 在GPU编程的时候,一定要切记就是在调用核函数之前,核函数所用到的数组或者变量,一定要使用
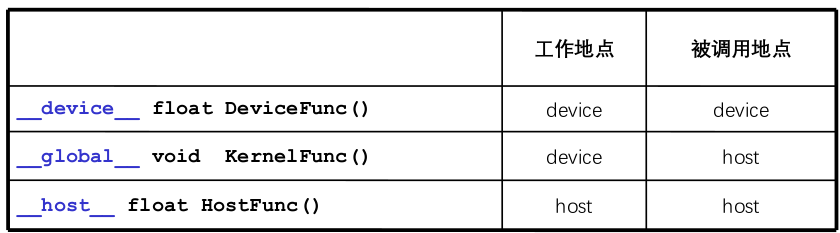
上图所示,就是在device上运行的核函数,一般会有三个标识符关键词:__global__,__device__,__host__。如果是用__device__ 进行标识的话,它的工作地点就是在设备端,也只能在设备端被调用。这个是在什么样的一个情形会被用到呢?如果我们的核函数是一个非常复杂的函数,将里头的小功能拆分成一个子函数,这时候就可以用__device__ 关键字去修饰该子函数。
如果核函数被 __global__ 关键字修饰,该函数是在主机端调用。工作地点在设备端。
如果核函数是被 __host__ 标识符修饰,该函数是在主机端调用,工作地点在设备端。这和C/C++编程是一致的。
接下来,按照向量相加的步骤编写向量相加的核函数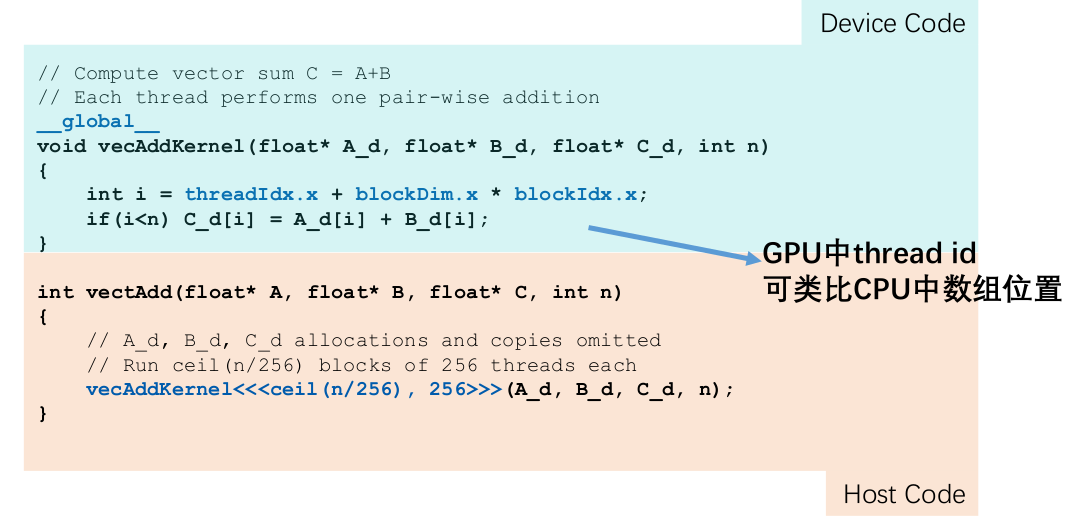
首先vecAddKernel 函数被 __global__ 修饰,意味着该函数在设备端执行,在主机端被调用。该核函数的三个参数是已经申请好的内存空间地址,最后一个参数是N。
threadIdx.x是线程的索引;blockIdx.x是线程块的索引;blockDim.x是线程块维度。根据计算公式得到要访问的这个线程的索引,在全局显存中的位置 i 。
这里我们要加一个判断,比如说n并不是一个32的倍数,假设是240,而申请好了256的内存空间,就意味着后边这些241到255之间的这一部分的寄存器是没有被访问到的。因此我们加一个判断,就是如果这个线程的索引是小于我们的这个向量的这个维度的,我们才去进行这个向量相加的操作。否则这个向量相加是没有意义的。以上就是向量相加,在设备端上执行的CUDA核函数。
而在主机端我们如何调用呢?vectAddKernel 是设备端的核函数的名字,内核调用必须有<<<线程块数量, 线程数量>>>。如上所示,有256个线程,也就是由八个线程束构成的线程块。然后这里为了精简,为了减少这个显存的浪费,线程块的数量使用ceil(n/256) 取整的操作。向该内核函数中传递三个参数:三个device上显存的位置。核函数名字 ➕ 内核调用 ➕ 所需参数 ➡️ 构成了主机端调用核函数。
计算GPU索引的时候,他其实和在之前我们看到CPU代码中,那个数组位置是一个意思,都是来确定好我们在显存中的这个索引的位置,从而去访问每一个线程中的寄存器。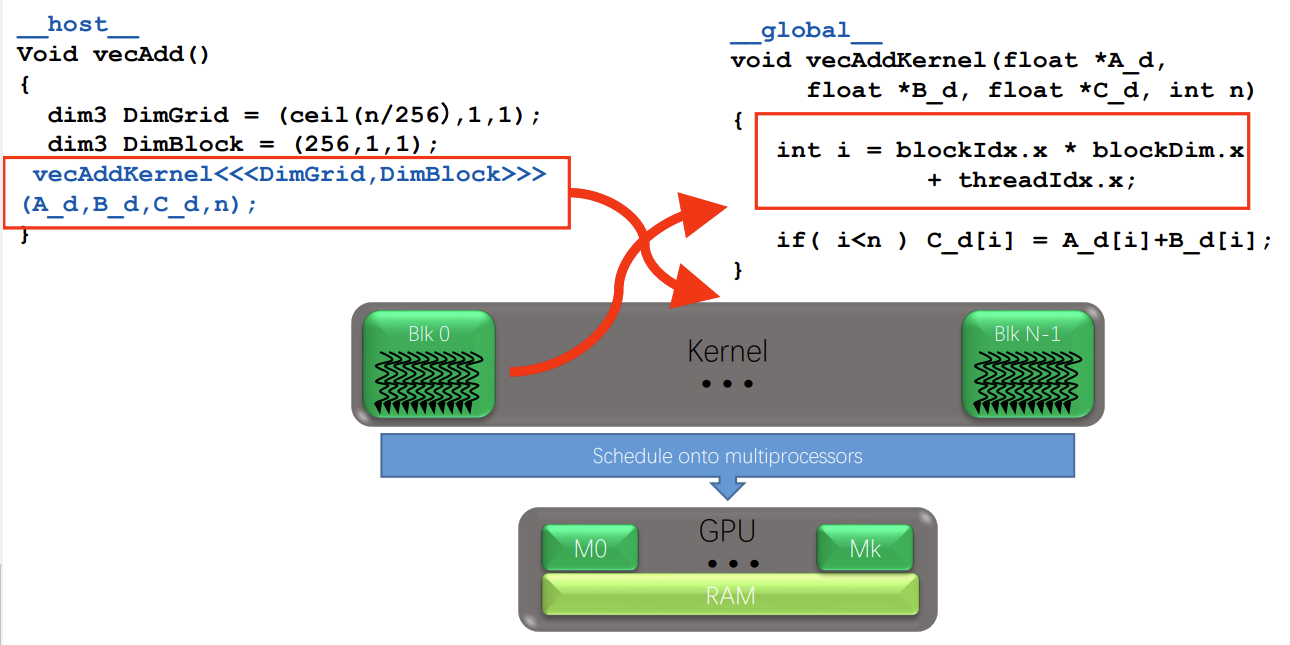 :::info
我们把上面的这些内容梳理一下:在主机端我们第一步要完成申请内存、显存,然后显存内存之间的互相拷贝。以及第三步要完成内存显存的释放。CUDA核函数调用时,要计算好这个网格的维度和线程块的维度,然后放到
:::info
我们把上面的这些内容梳理一下:在主机端我们第一步要完成申请内存、显存,然后显存内存之间的互相拷贝。以及第三步要完成内存显存的释放。CUDA核函数调用时,要计算好这个网格的维度和线程块的维度,然后放到<<<>>>中,然后后边还有它的这三个参数和它的大小。而在设备端用__global__ 关键字作为修饰证明这个函数可以主机端被调用,且在设备端被执行。首先计算一个索引的绝对位置,保证索引不超过我们的向量维度,然后执行并行,执行相加。
:::
这里我们就看到当我们,在主机端调用这个函数的时候,他就把这个kernel 就执行在了一个grid 上。而这个grid是由N个线程块组成的,每一个线程框内是有256个线程并行执行。然后当它运算结束之后,把结果返回到主机端。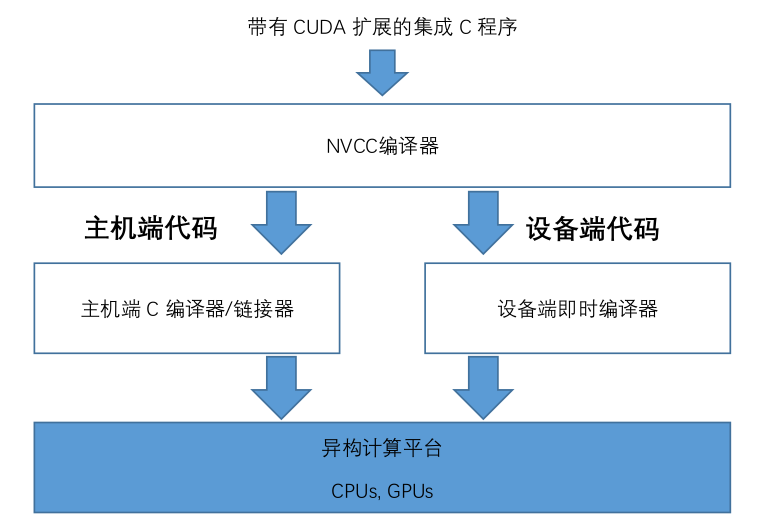
这里最后介绍一下,就是CUDA编程如何去执行编译源码的过程。因为我们之前在CPU进行编程的,我们如编程环境是linus,我们可能会使用g++或者gcc进行编译。然后编译好之后,统一进行link,就是统一进行生成它的可执行程序。
如果用这GPU,我们可能是用的这种windows mysql 去进行代码的书写。那么在GPU端,CUDA其实是有扩展执行C程序这个功能的,他也有对应的编译器,就是NVCC。通常我们是怎么做的呢?我们会把这个和gpu相关的这些头文件放在.h或者是叫.cuh。然后把这个设备端执行的程序,就是刚才我们说用global 这个关键字定义和用device 关键字定义的这些函数放在.cu程序,然后这些程序我们是用NVCC来去进行编译,然后把主机端的那些程序放在.h和.cpp或者.c里面。这些我们可以是用继续用这个G++或者GCC编译。
通常我们在这个执行编译的过程中有几种方法:
- 第一种方法就是逐个文件编译。如果是足够文件编译,就是GPU的,就用NVCC编译成一个.o。然后CPU是用GCC或者G++编译,编译成一个.o,最后我们把这些.o汇总到一起,然后用这个link 输出,然后输入一个可执行文件。这个EXE最终达到我们的可以在GPU和CPU之间异构计算平台都可以使用的这么一个程序。
- 逐个文件编译,当我们文件多的时候,他这个编译文件写的是非常困难的。第二种方法就是我们用NVCC将我们的gpu程序变成一个.so、.a,就是静态编译和动态编译。而我们在链接过程中只使用.so就可以,不需要使用这些所有的.o。你假设我们有1000个文件,如果用第一种方式,在链接的过程中就有1000个.o,显然是非常麻烦的。我们这里可以把所有GPU的这些编译好的东西变成.so 或者.o,然后最后用g++去编译。
- Cmake方式,就是我们写一个make file,一键式执行编译链接的操作。
作业:
- 流水线前传机制
- 三级缓存 及特点,内容匹配
- gpu的控制单元 计算单元如何结合 线程束如何在硬件端 软件端应用。线程束是执行核函数的基本单元。

若有收获,就点个赞吧
0 人点赞
