内核函数的调用 在CUDA 中创建内核函数并向其传递参数 配置CUDA程序的内核参数和内存分配 CUDA程序中的线程执行 在CUDA程序访问GPU设备属性 在CUDA程序中处理向量 并行通信模型
CUDA程序结构
CUDA程序是在主机或GPU设备上执行的函数的组合。不涉及数据并行的函数在CPU上运行,设计数据并行的函数在GPU上运行。GPU编译器在编译期间隔离这些函数。
如上一节中的myfirstkernel是使用__global__关键字定义的,由NVCC编译器变异,而普通的C主机代码是由C编译器编译的,所以说CUDA代码与标准C代码相比,只是添加了一些数据并行所需要的关键字。
CUDA C实现双变量加法程序
使用一个简单的双变量加法程序来解释与CUDA编程相关的重要概念:内核调用、从主机到设备传递参数到内核函数、内核参数的配置、利用数据并行性所需要的CUDA API、以及发生在主机和设备上的内存分配。
#include <iostream>#include <cuda.h>#include <cuda_runtime.h>// Definition of kernel function to add two variables__global__ void gpuAdd(int d_a, int d_b, int *d_c){*d_c = d_a + d_b;}
gpuAdd 这个内核函数以两个整数变量d_a d_b 作为输入,并将加法存储在第三个整数指针d_c 所指的内存地址。由于该内核函数的结果存储在设备指针指向的内存位置中,而不显示地返回任何之,所以该设备函数代码的返回值为void。
// main functionint main(void){// 1. Definition host variable to store answerint h_c;// 2. Definition device pointerint *d_c;// 3. Allocating memory for device pointercudaMalloc((void**)&d_c, sizeof(int));// 4. Kernel call by passing 1 and 4 as inputs and storing answer in d_c// <<<1, 1>>> means 1 block id executed with 1 thread per blockgpuAdd<<<1, 1>>> (1, 4, d_c);// 5. Copy result from device memory to host memorycudaMemcpy(&h_c, d_c, sizeof(int), cudaMemcpyDeviceToHost);printf("1 + 4 = %d\n", h_c);// 6. Free up memorycudaFree(d_c);return 0;}
上述代码中的第一二步定义了主机和设备的变量,第三步使用cudaMalloc函数在设备上分配d_c变量的内存。cudaMalloc类似于C中的malloc函数。第四步骤调用gpuAdd函数,其输入是 1 和 4 两个变量,d_c是一个作为输出的设备显存存指针,gpuAdd<<<1, 1>>> (1, 4, d_c); 被称作为内核调用。如果gpuAdd的结果需要在主机上使用,那么必须从设备的显存中拷贝到主机的内存中,这是由cudaMemcpy 函数完成的。得到结果之后,一定要记得释放内存。
从程序中释放所用的内存是非常重要。
内核调用
使用ANSI C 关键字和CUDA扩展关键字所编写的设备代码称为内核。它是主机代码(Host Code)通过内核调用(从主机代码启动设备代码)的方式来启动的。
内核调用通常会生成大量的块block和线程Thread在GPU上并行处理数据。内核代码与普通C代码类似,只是这段代码是由多个线程并行执行。内核启动的语法比较特殊,伪代码如下:
kernel <<< number of blocks, number of threads per block, size of shared memory>>> (parameters for kernel function)
该kernel确保是被__global__关键词定义,内核启动配置在<<<>>>中配置,其中第一个参数:希望执行的块数,第二个参数:每个块将具有的线程数。所以该内核函数运行所启动的总线程数 = block nums * thread numbs。第三个参数:optional,指定内核使用的共享内存大小。
在两变量相加的kernel函数中,gpuAdd<<<1, 1>>> (1, 4, d_c); 被称作为内核调用。gpuAdd 是我们想要启动的内核名称,<<<1, 1>>>表示:使用一个block,每个block包含一个Thread,这意味着该内核函数只启动了一个线程。圆括号中的三个参数是要传递给内核的参数:第一和第二个参数是两个常量,第三个参数是指向d_c设备显存的指针。它指向设备显存中的位置,内核将在那里存储相加后的结果。
作为参数传递给内核的指针应该仅仅指向设备显存,如果其指向主机内存,程序会崩溃。
内核执行完成之后,设备指针指向的结果复制回主机内存,以供进一步使用。
我们知道GPU最大的优势就是并行化处理,但是目前为止,还没有体现出GPU强大的并行能力,所以下一节需要介绍内核参数配置,实现初步的并行化。
配置内核参数
为了在设备上并行多个线程,必须在内核调用中配置参数,其指定了Grid中块Block的数量,和每个Block中线程Thread的数量。我们可以并行启动很多块,而每个块内又有很多线程。一个块内的线程可以通过共享内存(Shared Memory)彼此通信。通常每个块有512或1024个线程,程序员无法选定哪个流处理器将执行特定的块,也无法选定块和线程以何种顺序执行。
假设将启动500个线程来执行gpuAdd内核函数,可以通过下面的语句实现:
gpuAdd<<<1, 500>>>(1, 4, d_c);
以上语句是在一个Block中启动500个线程,我们也可以操作Block的数量:2个blocks + 250个Threads;5个Blocks + 50个Threads。
每个块的线程数量不能超过GPU设备所支持的最大限制。
由于CV需要处理二维或者三维的图像,如果GPU支持三维网络块和三维线程块,那就可以更好的处理图像了。语法如下:
mykernel<<<dim3(Nbx, Nby, Nbz), dim3(Ntx, Nty, Ntz)>>>();
Nbx、Nby、Nbz:网格中沿x、y、z轴方向的块数;Ntx、Nty、Ntz:块中沿x、y、z轴方向的线程数;如果没有指定y、z的维数,默认情况下为1。
假设要处理一个图像,需要启动一个16✖️16个块的网格Grid,所有的块中包含16✖️16个线程,语法如下:
mykernel<<<dim3(16, 16), dim3(16, 16)>>>();
启动内核时,块数量和线程数量的配置非常重要。要根据任务不同和GPU资源的不同,谨慎选择内核配置。
CUDA API函数
- global
其与device host一起是三个限定符关键字。该关键字表示一个函数被声明为设备函数,当从主机调用时将在设备上执行,也仅能从主机调用。如果要在设备上执行函数并从设备函数调用函数,则使用device关键字。host关键字用于定义只能从其他主机函数调用的主机函数,类似于普通的C函数。默认情况下函数都是主机函数。host device都可以同时用于定义任何类型函数。它生成同一个函数的两个副本,一个在主机执行,一个在设备上执行。
- cudaMalloc
类似于C中用于动态内存分配的Malloc函数。此函数用于在设备上分配特定大小的内存块,cudaMalloc的语法如下:
// cudaMalloc(void **d_pointer, size_t size);cudaMalloc((void**) &d_c, sizeof(int));
以上代码分配了大小等于一个整数变量大小的内存块,并返回指向该内存位置的指针d_c。
- cudaMemcpy
类似于C中的Memcpy函数,用于将一个内存区域复制到主机或设备上的其他区域,语法如下:
// cudaMemcpy(void * dst_ptr, const void * src_ptr, size_t size, enum cudaMemcpyKind kind)cudaMemcpu(&h_c, d_c, sizeof(int), cudaMemcpuDeviceToHost);
这个函数有四个参数:
- 目标指针:指向主机内存地址或设备显存地址
- 源指针:指向主机内存地址或设备显存地址
- 数据复制的大小
- 数据复制的方向:可以从主机到设备;设备到设备;主机到主机;设备到主机
Warning: 参数一和参数二代表目标指针和源指针,它们应该于数据复制的方向一致。
如以上代码所示,d_c作为指向设备显存地址的指针,h_c作为指向主机内存地址的指针,数据复制的方向就应该是设备显存到主机内存,所以第四个参数应cudaMemcpuDeviceToHost。
- cudaFree
类似于C中的free函数,cudaFree的语法如下:
// cudaFree(void * d_ptr);cudaFree(d_c);
作用:释放d_ptr指向的内存空间
在以上代码中,其释放了d_c指向位置的内存。请确保使用了cudaMalloc分配了d_c的内存,在程序结束之前,要使用cuaFree释放掉。
将参数传递给CUDA函数
1. 按值传递参数
gpuAdd的内核调用如下:
gpuAdd<<<1, 1>>> (1, 4, d_c);
gpuAdd函数的定义如下:
__global__ gpuAdd(int d_a, int d_b, int *d_c);
在调用内核时传递的是d_a 和 d_b的值。在内核调用时参数1会被复制到d_a,参数2会被复制到d_b,相加后的结果将存储到设备显存中d_c指向的地址。与其直接将值1和4作为输入传递给内核,我们还可以这样写:
gpuAdd <<<1, 1>>>(a, b, d_c);
a和b可以包含任何整数值的整数变量。
不建议按值传递参数,会给程序造成不惜要的混乱和复杂性。最好通过引用传递参数。
2. 通过引用传递参数
代码如下:
#include <iostream>#include <cuda.h>#include <cuda_runtime.h>// Kernel function to add two variables, parameters are passed by reference__global__ void gpuAdd(int *d_a, int *d_b, int *d_c){*d_c = *d_a + *d_b;}
该内核函数不是使用整数变量d_a d_b作为内核输入,而是将指向设备d_a d_b变量的指针作为输入,相加的结果存储在第三个整数指针d_c所指向的内存位置。
// main functionint main(void){// Defining host and variablesint h_a, h_b, h_c;int *d_a, *d_b, *d_c;// Initializing host variablesh_a = 1;h_b = 4;// Allocating memory for Device PointerscudaMalloc((void**) &d_a, sizeof(int));cudaMalloc((void**) &d_b, sizeof(int));cudaMalloc((void**) &d_c, sizeof(int));// Coping value of host variables in device memorycudaMemcpy(d_a, &h_a, sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, &h_b, sizeof(int), cudaMemcpyHostToDevice);// Calling kernel with one thread and one block with parameters passed by referencegpuAdd<<<1, 1>>> (d_a, d_b, d_c);// Coping result from device memory to hostcudaMemcpy(&h_c, d_c, sizeof(int), cudaMemcpuDeviceToHost);printf("Passing Parameter by Reference Output: %d + %d = %d\n", h_a, h_b, h_c);// Free up MemorycudaFree(d_a);cudaFree(d_b);cudaFree(d_c);return 0;}
h_a h_b h_c都是主机内存中的变量;d_a d_b d_c是驻留在主机内存中的指针,它们指向设备显存。它们通过使用cudaMalloc函数从主机分配内存,使用cudaMemcpy函数将h_a h_b的值复制到d_a d_b指向设备显存,数据传输方向:从主机到设备。
然后在内核调用中,着三个设备指针作为参数传递给内核,内核计算加法之后将结果存储在d_c指向的内存位置。结果再次使用cudaMemcpy函数复制回主机内存,这次数据传输方向:从设备到主机内存。
程序最后使用cudaFree释放三个设备指针所使用的内存。
从表中可以看出d_a d_b d_c驻留在主机,并指向设备显存中的值,当通过对内核的引用传递参数时,所有指针进指向设备显存。
在使用设备指针并将其传递给内核时,使用cudaMalloc分配内存的设备指针只能用于从设备显存中读写。它们可以作为参数传递给设备函数,而不应该用于从主机函数读写内存。
使用设备指针从设备函数中读取和写入设备显存,使用主机指针从主机函数中读取和写入主机内存。
在设备上执行线程
在配置内核参数的时候,可以并行启动多个块和线程。那么这些块和线程以什么顺序启动和结束呢?
#include <iostream>#include <stdio.h>__global__ void myfirstkernel(void){// blockIdx.x gives the block number of current kernelprintf("Hello! I'm thread in block: %d\n", blockIdx.x);}int main(void){// A kernel call with 16 blocks and 1 thread per blockmyfirstkernel<<<16, 1>>>();// Function used for waitting for all kernels to finishcudaDeviceSynchronize();printf("All threads are finished!\n");return 0;}
上述代码中,启动了16个并行块,每个块一个线程,在内核函数中打印每个块的ID。并行启动了16个执行相同myfirstkernel代码的线程副本,每个副本线程拥有一个属于子集的块ID和线程ID。块ID可通过blockId.x 获取,线程ID可以通过 ThreadId.x 获取。当执行上述代码后,会发现每次运行块ID都以不同顺序运行。
上述程序还有一个额外的CUDA API 函数调用cudaDeviceSynchronize()。因为启动内核是一个异步操作,只要发布了内核启动命令,不等内核执行完成,控制权就会立刻返回给调用内核的CPU线程。所以上述代码中,调用内核之后,CPU线程返回,继续执行printf,之后程序结束,终止控制台窗口,如果不加入同步函数,就无法得到任何内核执行结果的输出。
CUDA程序获取GPU设备属性
#include <iostream>#include <memory>#include <cuda_runtime.h>int main(void){int device_count, driver_version, runtime_version = 0;cudaGetDeviceCount(&device_count);// This function returns count of number of CUDA enable devices and 0 if there are no CUDA capable devices.if (device_count == 0){printf("There are no avaiable device(s) that support CUDA\n");}else{printf("Detected %d CUDA Capable device(s) \n", device_count);}cudaDeviceProp device_property;cudaGetDeviceProperties(&device_property, 0);printf("\nDevice %d: \"%s\"\n", 0, device_property.name);cudaDriverGetVersion(&driver_version);cudaRuntimeGetVersion(&runtime_version);printf("CUDA Driver Version / Runtime Version %d.%d / %d.%d\n",driver_version / 1000, (driver_version % 100) / 10,runtime_version / 1000, (runtime_version % 100) / 10);printf("Total amount of global memory: %.0f MBytes (%llu bytes)\n",(float)device_property.totalGlobalMem / 1048576.0f,(unsigned long long)device_property.totalGlobalMem);printf("(%2d) Multiprocessors\n", device_property.multiProcessorCount);printf("GPU Max Clock rate: %.0f MHz (%0.2f Ghz) \n",device_property.clockRate * 1e-3f,device_property.clockRate * 1e-6f);printf("Memory Clock rate: %.0f MHz\n", device_property.memoryClockRate * 1e-3f);printf("Memory Bus Width: %d-bit\n", device_property.memoryBusWidth);if (device_property.l2CacheSize){printf("L2 Cache Size: %d bytes\n", device_property.l2CacheSize);}printf("Total amount of constant memory: %lu bytes \n", device_property.totalConstMem);printf("Total amount of shared memory per block: %lu bytes\n", device_property.sharedMemPerBlock);printf("Total number of registers availabel per block: %d\n", device_property.regsPerBlock);// 显示线程数量限制信息printf("Maxmum num of threads per multiprocessor: %d\n", device_Property.maxThreadsPerMultiProcessor);printf("Maximum num of of threads per block: %d\n", device_Property.maxThreadsPerBlock);printf("Max dimension size of a thread block (x, y, z): (%d, %d, %d)\n", device_Property.maxThreadsDim[0], device_Property.maxThreadsDim[1], device_Property.maxThreadsDim[2]);printf("Max dimension size of a grid size (x, y, z): (%d, %d, %d)\n", device_Property.maxGridSize[0], device_Property.maxGridSize[1], device_Property.maxGridSize[2]);return 0;}
确定计算系统上有多少支持CUDA的设备,使用 cudaGetDeviceCount() 来获得。
cudaDevicePro 结构体可以找到每个设备的相关信息,这个结构体可以返回所有设备属性。如果有多个设备,可以使用for循环遍历所有设备属性。其提供的 name 属性,可以以字符串的方式返回设备名称;
cudaDriverGetVersion 获得设备使用的CUDA Driver的版本;cudaRuntimeGetVersion 获得设备运行时引擎的版本。
如果有多个设备,并希望使用其中的具有最多流处理器,可以通过 multiProcessonCount 属性来判断,该属性返回设备上流多处理器。
使用 clockRate 属性获取GPU的时钟速率,以 Khz 返回时钟速率。
GPU的内存为分层结构,可以分为L1缓存、L2缓存、全局缓存、纹理内存和共享内存。cudaDeviceProp 提供了许多特性来识别设备中可用的内存。memoryClockRate 显示显存频率;memoryBusWidth 显示显存位宽。显存的读写速度非常重要,它会影响程序的总体速度。totalGlobalMem 返回设备可用的全局内存大小。totalConstMem 返回设备中可用的总常量显存。sharedMemPerBlock 返回的是设备上每个块中的最大可用共享内存大小。使用 regsPerBlock 可以识别每个块的可用寄存器总数。可用 I2CacheSize 属性识别L2缓存的大小。
块和线程可以是多维度的,所以最好知道每个维度中可以并行启动多少线程和块。对于多处理器的最大线程数量和每个块的线程数量可以通过maxThreadsPerMultiProcessor 和 maxThreadsPerBlock 找到,如果设置的数量超出最大数量,程序会崩溃。
通过maxThreadsDim 来确定块中各个维度上的最大线程数量。每个维度中的每个网格的最大块可以通过maxGridSize 标识。它们都返回一个具有三个值的数组,分别显示x y z维度中的最大值。
为啥要了解设备属性?
- 如果有多个GPU设备,这会帮助人们选择具有更多多处理器、性能更高的GPU设备。
- 可以通过查询设备可用的块的数量和每个块的线程数量,帮助配置内核参数。
如果一个程序要求双精度浮点操作,但是有的设备是不支持这种操作,可以使用如下代码检测:
#include <memory>
#include <iostream>
#include <cuda_runtime.h>
// Main Program
int main(void)
{
int device;
cudaDeviceProp device_property;
cudaGetDevice(&device);
printf("Id of device: %d\n", device);
memset(&device_property, 0, sizeof(cudaDeviceProp));
device_property.major = 1;
device_property.minor = 3;
cudaChooseDevice(&device, &device_property);
printf("ID of device which supports double precision is : %d\n", device);
cudaSetDevice(device);
}
如上代码使用cudaDeviceProp 结构体中的两个属性 major 和 minor 来帮助识别设备是否支持双精度操作。如果 major 大于 1 而 minor 小于 3,那么设备将支持双精度操作。cudaChooseDevice 用于当前设备,以确定是否包含这两个属性,帮助选择特定属性的设备。如果包含属性,则使用 cudaSetDevice 为应用程序选择该设备。
向量相加
上面的所有例子都还没有用到GPU设备的并行处理能力,下面的向量相加的例子开始利用GPU的并行处理能力,执行向量或数组操作。
CPU版本
#include <iostream>
#include <stdio.h>
#include <cuda.h>
#include <cuda_runtime.h>
// defining Number of elements in Array
#define N 100000
// Defining vector addition function for CPU
void cpuAdd(int *h_a, int *h_b, int *h_c)
{
int tid = 0;
while (tid < N)
{
h_c[tid] = h_a[tid] + h_b[tid];
tid += 1;
}
}
int main(void)
{
printf("Doing CPU Vector add\n");
int h_a[N], h_b[N], h_c[N];
// Initializeing two arrays for addition
for (int i = 0; i < N; i++)
{
h_a[i] = 2 * i * i;
h_b[i] = i;
}
clock_t start_d = clock();
// Calling CPU function for vector addition
cpuAdd(h_a, h_b, h_c);
clock_t end_d = clock();
double time_d = (double)(end_d - start_d) / CLOCKS_PER_SEC;
printf("No of Elements in Array:%d\n Device time %f seconds \n", N, time_d);
// Printing Answer
printf("Vector addition on CPU\n");
for (int i = 0; i < N; i++)
{
printf("The sum of %d element is %d + %d = %d \n", i, h_a[i], h_b[i], h_c[i]);
}
上述程序中有两个函数:main 和 cpuAdd 函数,在main中定义了两个输入数组,并随机初始化了一些值;然后将这两个数组当作输入传递给cpuAdd 函数,并将输出存储在第三个数组中。
GPU版本
#include <iostream>
#include <stdio.h>
#include <cuda.h>
#include <cuda_runtime.h>
// defining Number of elements in Array
#define N 100000
// Defining Kernel function for vector addition
__global__ void gpuAdd(int *d_a, int *d_b, int *d_c)
{
// Getting block index of current kernel
int tid = blockIdx.x; // handle the data at this index
if (tid < N)
d_c[tid] = d_a[tid] + d_b[tid];
}
int main(void)
{
printf("Doing GPU Vector add\n");
// Defining host arrays
int h_a[N], h_b[N], h_c[N];
// Defining device pointers
int *d_a, *d_b, *d_c;
// allocate the memory
cudaMalloc((void **)&d_a, N * sizeof(int));
cudaMalloc((void **)&d_b, N * sizeof(int));
cudaMalloc((void **)&d_c, N * sizeof(int));
// Initializing Arrays
for (int i = 0; i < N; i++)
{
h_a[i] = 3 * i * i;
h_b[i] = i;
}
// Copy input arrays from host to device memory
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
// Calling kernels with N blocks and one thread per block,
// pasing device pointers as parameters
clock_t start_d = clock();
gpuAdd<<<N, 1>>>(d_a, d_b, d_c);
clock_t end_d = clock();
double time_d = (double)(end_d - start_d) / CLOCKS_PER_SEC;
printf("No of Elements in Array:%d\n host time %f Seconds \n", N, time_d);
// Copy result back to host memory from device memory
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
printf("Vector addition on GPU \n");
// Printingg result on console
for (int i = 0; i < N; i++)
{
printf("The sum of %d element is %d + %d = %d\n", i, h_a[i], h_b[i], h_c[i]);
}
// Free up memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
在gpuAdd的kernel 函数中,每个块中的线程,用当前块的ID来初始化tid变量。然后根据tid变量,每个线程将一对元素进行相加。如果块的总数等于每个数组中元素的总数,那么所有的加法都将并行执行。
该main函数中具有cuda程序的编程模板:
- 定义CPU和GPU上的数组和指针。设备指针指向通过
cudaMalloc分配的显存 - 通过
cudaMemcpy函数,将前两个数组,从主机内存拷贝到设备显存 - 内核启动的时候,将设备指针作为参数传递给内核函数。内核启动符号
<<< >>>里的N, 1代表:启动N个块,每个块中只有一个线程。 - 内核函数执行完毕,通过
cudaMemcpy函数,将内核计算结果从设备显存传输到主机内存。 - 最后,使用
cudaFree释放掉在显存中分配的三段缓冲区。
:::info 所有CUDA程序都遵循该式。并行启动N个块:意味着同时启动了N个执行该内核代码的线程副本。 :::
你可以通过一个现实的例子来理解这一点:假设你想把5个大盒子从一个地方转移到另一个地方。在第一种方法中,你可以通过雇佣一个人将一个盒子从一个地方带到另一个地方,然后重复5次来完成这项任务。这个方式需要时间,它类似于如何在CPU上做向量相加。现在,假设你雇了5个人,每个人都带着一个盒子。他们每个人也知道他们所携带的箱子的ID。这个方法将比前一个快得多。每个人只需要被告知他们必须携带一个带有特定ID的盒子从一个地方到另一个地方。
从上述例子里我们知道内核代码的编写方式,以及这些线程是如何在GPU上执行的。每个线程可以通过blockIdx.x 内置变量来知道的ID。然后每个线程通过ID来索引数组,计算每对元素加法。这样,多个线程的并行计算,明显减少了数组整体的处理时间。所以,用这种并行的计算方式,比CPU上的串行计算,提高了吞吐率。
Speed of CPU and CUDA
CPU的加法程序和GPU的加法程序都是以一个模块化(函数)的方式来编写的,可以随意设置N的值,如果N设得小,CPU和GPU代码之间计算时间的差异微小。但如果N是足够大,那么你会发现在执行同一个向量加法的时候,CPU执行时间和GPU执行时间的显著差异。
// Calling kernels with N blocks and one thread per block, pasing device pointers as parameters
clock_t start_d = clock();
gpuAdd<<<N, 1>>>(d_a, d_b, d_c);
clock_t end_d = clock();
double time_d = (double)(end_d - start_d) / CLOCKS_PER_SEC;
printf("No of Elements in Array:%d\n host time %f Seconds \n", N, time_d);
时间是通过测量特定操作所需的时钟周期数来确定的。这可以通过调用clock()函数,测量两个时刻的滴答计数值,然后作差来求得(注意:函数clock()在Windows上和在Linux/BSD上是不一样的!一个是wall time,一个是processortime。前者是生活中的时间,后者是CPU时间),然后除以每秒钟的滴答数,就可以得到以秒为单位的时间了。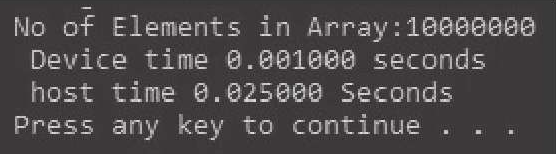
执行时间或叫吞吐量,从25ms提高到在GPU上几乎1ms实现相同的功能。这证明了我们之前在理论上提到的GPU并行执行代码有助于提高吞吐量。
向量相乘
前面例子中,启动了N个块,每个块中开启一个线程,完成了向量相加的并行操作。那么,能否在一个块中,启动N个线程,bingo。我们使用向量相乘的例子来完成并行CUDA代码 :::info 将一个向量数组里面的元素进行平方。我们以一个数值数组作为输入,然后输出一个每个元素都平方后的数组。用来求(find)每个元素平方的内核如下: :::
#include "stdio.h"
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
// Defining number of elements in Array
#define N 5
// Kernel function for squaring number
__global__ void gpuSquare(float *d_in, float *d_out)
{
// Getting thread index for current kernel
int tid = threadIdx.x; // handle the data at this index
float temp = d_in[tid];
d_out[tid] = temp * temp;
}
int main(void)
{
//Defining Arrays for host
float h_in[N], h_out[N];
//Defining Pointers for device
float *d_in, *d_out;
// allocate the memory on the cpu
cudaMalloc((void **)&d_in, N * sizeof(float));
cudaMalloc((void **)&d_out, N * sizeof(float));
// Initializing Array
for (int i = 0; i < N; i++)
{
h_in[i] = i;
}
// Copy Array from host to device
cudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);
// Calling square kernel with one block and N threads per block
gpuSquare<<<1, N>>>(d_in, d_out);
// Coping result back to host from device memory
cudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);
// Printing result on console
printf("Square of Number on GPU \n");
for (int i = 0; i < N; i++)
{
printf("The square of %f is %f\n", h_in[i], h_out[i]);
}
//Free up memory
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
gpuSquare 内核函数具有两个指针参数:
- 第一个指针
d_in指向存储输入数据的显存。 - 第二个指针
d_out则指向输出结果的显存。
在这程序里,我们并行启动了多个线程,而不是启动多个块,所以每个线程特有的tid被初始化为threadIdx.x
main函数的流程和向量相加相同。
当启动N个线程并行的时候,应该注意:每个块的最大线程不超过512或1024(注意:现在所有计算能力3.0-7.5的GPU卡,每个块最大1024个线程)。因此,N的值应该小于或等于这个值。应当理性地选择合适数量的块和每个块具有的线程数量。
通过两个例子,知道了如何使用向量以及如何并行启动多个块和多个线程。而且,相较于CPU上相同的操作,在GPU上的向量运算可以提高吞吐量。
并行通信模式
当多个线程并行执行时,它们遵循一定的通信模式,指导它们在显存里哪里输入,哪里输出。我们将讨论每个通信模式。它将帮助你识别通信模式相关的应用程序,以及如何编写代码。
映射 Map
在这种通信模式中,每个线程或任务读取单一输入,产生一个输出。基本上,它是一个一对一的操作。前面部分中向量加法程序和向量元素平方的程序,就是Map模式的例子。Map的代码模式看起来如下:
d_out[i] = d_in[i] * 2
收集 Gather
在此模式中,每个线程或者任务,具有多个输入,并产生单一输出,保存到存储器的单一位置中。假设你想写一个求3个数据的MA操作的程序。这就是一个Gather操作的例子。每个线程读取3个输入数据,产生单一的结果数据保存到显存。因此,在输入端有数据复用。它基本上是一个多对一的操作。Gather模式的代码看起来如下:
out[i] = (in[i-1] + in[i] + in[i+1]) / 3
分散式 Scatter
在Scatter模式中,线程或者任务读取单一输入,但向存储器产生多个输出。数组排序就是一个Scatter操作的例子。它也可以叫作1对多操作。Scatter模式的代码看起来如下:
out[i -1] += 2 * in[i] and out[i+1] += 3 * in[i]
蒙版 Stencil
当线程或者任务要从数组中读取固定形状的相邻元素时,这叫stencil模式。这种模式在图像处理中非常有用,例如当你想用一个3×3或者5×5的(滤波)窗口时(对整个图像进行滑动处理的时候)。它是Gather操作的一种模式,所以代码的语法和Gather很相似。
转置 Transpose
当原始输入矩阵是行主序的时候,如果需要输出得到一个列主序的矩阵,则应当进行转置操作。如果你有一个结构数组(SoA),而你想把它转换成一个数组结构(AoS),它是特别有用的。这也是一个一对一的操作。Transpose模式的代码看起来如下:
out[i + j*128] = in[j + i * 128]
总结
- CUDA C编程概念
- 如何使用CUDA并行计算。CUDA程序可以高效地并行在任何NVIDIA GPU卡上。所以,CUDA既高效也可扩展。
- 详细讨论了并行数据计算所需的CUDA API函数,以及如何通过内核调用从主机代码中调用设备代码,还通过一个简单的两变量相加的例子来讨论如何传递一个参数给内核。同时也表明,CUDA并不保证块和线程的启动顺序以及哪个块被分配给硬件中的多处理器。
- 利用GPU和CUDA并行处理能力来进行向量运算。可以看出,利用GPU执行向量运算,可以相较于CPU大幅提高吞吐量。
- 并行编程中常见的通信模式。不过还没有讨论存储器架构以及在CUDA中线程是如何相互通信。如果一个线程需要其他线程的数据,我们该如何做呢?留坑
习题
// Defining Kernel function for vector addition global void gpuSub(int d_a, int d_b, int d_c) { *d_c = d_a - d_b; }
int main(void) { int h_c; int d_c; cudaMalloc((void*) &d_c, sizeof(int)); gpuSub <<<1, 1>>> (4, 1, d_c); cudaMemcpy(&h_c, d_c, sizeof(int), cudaMemcpyDeviceToHost); printf(“4 - 1 = %d\n”, h_c); cudaFree(d_c);
return 0;
}
2. 两个数字相乘时,以**通过引用传递参**数的CUDA代码如下所示:
```cpp
#include <iostream>
#include <memory>
#include <cuda_runtime.h>
#define N 2
// Defining Kernel function for vector addition
__global__ void gpuMul(int *d_a, int *d_b, int *d_c)
{
*d_c = *d_a * *d_b;
}
int main(void)
{
int h_a[N], h_b[N], h_c[N];
int *d_a, *d_b, *d_c;
cudaMalloc((void **) &d_a, N * sizeof(int));
cudaMalloc((void **) &d_b, N * sizeof(int));
cudaMalloc((void **) &d_c, N * sizeof(int));
// Initializing Arrays
for (int i = 0; i < N; i++)
{
h_a[i] = 3 * i * i;
h_b[i] = i;
}
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
gpuMul<<<1, 1>>>(d_a, d_b, d_c);
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < N; i++)
{
printf("The mul of %d element is %d + %d = %d\n", i, h_a[i], h_b[i], h_c[i]);
}
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
为gpuMul内核并行启动5000个线程的三种方法如下:
gpuMul<<<25, 200>>>(d_a, d_b, d_c); gpuMul<<<50, 100>>>(d_a, d_b, d_c); gpuMul<<<10, 500>>>(d_a, d_b, d_c);程序员可以决定设备上块的启动顺序,以及哪个块被分配给硬件的流多处理器(错误)
- 查找5.0或更高版本的GPU设备的程序如下:
```cpp
include
include
include
int main(void) { int device; cudaDeviceProp device_property; cudaGetDevice(&device);
printf("ID of device: %d\n", device);
memset(&device_property, 0, sizeof(cudaDeviceProp));
device_property.major = 5;
device_property.minor = 5;
cudaChooseDevice(&device, &device_property);
printf("ID of device which supports double precision is : %d\n", device);
cudaSetDevice(device);
}
6. 求元素的三次方的CUDA代码如下:
```cpp
#include <stdio.h>
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#define N 50
__global__ void gpuCube(float *d_in, float *d_out)
{
// Getting thread index for current kernel
int tid = threadIdx.x;
float temp = d_in[tid];
d_out[tid] = temp * temp * temp;
}
int main(void)
{
float h_in[N], h_out[N];
float *d_in, *d_out;
cudaMalloc((void**) &d_in, N * sizeof(float));
cudaMalloc((void**) &d_out, N * sizeof(float));
for (int i = 0; i < N; i ++)
{
h_in[i] = i;
}
cudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);
gpuCube<<<1, N>>>(d_in, d_out);
cudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyHostToDevice);
printf("Cube of Number on GPU \n");
for (int i = 0; i < N; i ++)
{
printf("The cube of %f is %f \n", h_in[i], h_out[i]);
}
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
- 给出下列应用程序的通信模式如下:
- 图像处理:Stencil(蒙版)模式
- 移动平均:Gather(收集)模式
- 按升序排列数组:Scatter(分散式)模式
- 求一个数组中元素的三次方:Map(映射)模式

若有收获,就点个赞吧
0 人点赞
