cuBLAS背景:是一个BLAS的实现,允许用户使用NVIDIA的GPU的计算资源。使用cuBLAS 的时候,应用程
序应该分配矩阵或向量所需的GPU内存空间,并加载数据,调用所需的cuBLAS函数,然后从GPU的内存空
间上传计算结果至主机,cuBLAS API也提供一些帮助函数来写或者读取数据从GPU中。
- 列优先的数组,索引以1为基准
- 头文件 include “cublas_v2.h”
- 三类函数(向量标量、向量矩阵、矩阵矩阵)
学习网站: https://docs.nvidia.com/cuda/cublas/index.html
Cublas实现矩阵乘法
30个数:12, 9, 8, 23, 3, 40, 60, 9, 6, 8, 29, 87, 0, 2, 3, 8, 4, 0, 9, 5, 7, 3, 0, 6, 56, 43, 11, 31, 89, 40
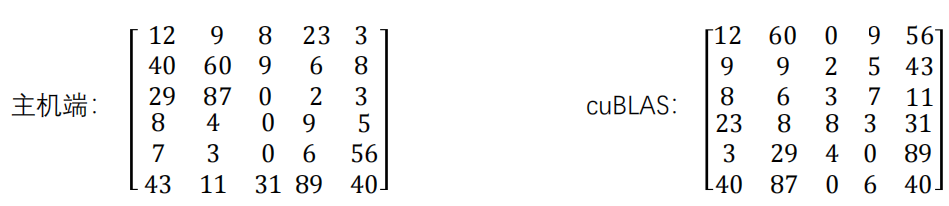
...// 准备 A, B, C 以及使用的线程网格、线程块的尺寸// 创建句柄cublasHandle_t handle;cublasCreate(&handle);// 调用计算函数cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, m, n, k, &alpha, *B, n, *A, k, &beta, *C, n);// 销毁句柄cublasDestroy(handle);...// 回收计算结果,顺序可以和销毁句柄交换
cuBLAS 辅助函数
句柄管理函数**cublasCreate()**, **cublasDestroy()**
- cublasStatus_t cublasCreate(cublasHandle_t *handle)
cublasStatus_t cublasDestroy(cublasHandle_t handle) :::info 初始化CUBLAS库,并为保存CUBLAS库上下文创建一个句柄。 它在主机和设备上分配硬件资源,并且
在进行任何其他CUBLAS库调用时必须使用它。 CUBLAS库上下文绑定到当前CUDA设备。要在多个设
备上使用该库, 需要为每个设备创建一个CUBLAS句柄。创建句柄的函数 cublasCreate( ) 会返回一个 cublasStatus_t 类型的值,用来判断句柄是否创建成功 ::: 流管理函数**cublasSetStream()**,**cublasGetStream()**cublasStatus_t cublasSetStream(cublasHandle_t handle, cudaStream_t streamId)
- cublasStatus_t cublasGetStream(cublasHandle_t handle, cudaStream_t *streamId)
Cublas level1函数:标量
- cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float x, int incx, int result)
- cublasStatus_t cublasIsamin(cublasHandle_t handle, int n, const float x, int incx, int result)
实现功能: result = max/min( x )
参数意义
-
Cublas level2函数:矩阵向量
cublasStatus_t cublasSgemv( cublasHandle_t handle, cublasOperation_t trans, int m, int n, const float *alpha, const float *A, int lda, const float *x, int incx, const float *beta, float *y, int incy)实现功能: y = alpha op ( A ) x + beta * y
参数意义 Lda:A的leading dimension,若转置按行优先,则leading dimension为A的列数
-
Cublas level3函数:矩阵矩阵
cublasStatus_t cublasSgemm( cublasHandle_t handle, cublasOperation_t transa, cublasOperation_t transb, int m, int n, int k, const float *alpha, const float *A, int lda, const float *B, int ldb, const float *beta, float*C, int ldc)实现功能: C = alpha op ( A ) op ( B ) + beta * C
参数意义 alpha和beta是标量, A B C是以列优先存储的矩阵
- 如果 transa的参数是CUBLAS_OP_N 则op(A) = A ,如果是CUBLAS_OP_T 则op(A)=A的转置
- 如果 transb的参数是CUBLAS_OP_N 则op(B) = B ,如果是CUBLAS_OP_T 则op(B)=B的转置
- Lda/Ldb:A/B的leading dimension,若转置按行优先,则leading dimension为A/B的列数
- Ldc:C的leading dimension,C矩阵一定按列优先,则leading dimension为C的行数
Cublas实现矩阵乘法
```cpp float d_A, d_B, d_C; unsigned int size_C = ms.wc ms.hc; unsigned int mem_size_C = sizeof(float) size_C; float h_CUBLAS = (float *) malloc(mem_size_C);
cudaMalloc((void ) &d_A, mem_size_A); cudaMalloc((void ) &d_B, mem_size_B);
cudaMemcpy(d_A, h_A, mem_size_A, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, mem_size_B, cudaMemcpyHostToDevice); cudaMalloc((void **) &d_C, mem_size_C);
dim3 threads(1,1); dim3 grid(1,1);
//cuBLAS代码 const float alpha = 1.0f; const float beta = 0.0f; int m = A.row, n = B.col, k = A.col; cublasHandle_t handle; cublasCreate(&handle); cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, d_B, n, d_A, k, &beta, d_C, n);//C=AB->C_T=B_T*A_T
cublasDestroy(handle); cudaMemcpy(h_CUBLAS, d_C, mem_size_C, cudaMemcpyDeviceToHost);
```cpp
cublasStatus_t cublasSgemmBatched(
cublasHandle_t handle,
cublasOperation_t transa, cublasOperation_t transb,
int m, int n, int k,
const float *alpha, const float*Aarray[], int lda,
const float *Barray[], int ldb, const float *beta,
float*Carray[], int ldc,
int batchCount
)
实现功能: C[i] = alpha op ( A[i] ) op ( B[i] ) + beta * C[i]
• 参数意义
• Lda/Ldb:A/B的leading dimension,若转置按行优先,则leading dimension为A/B的列数
• Ldc:C的leading dimension,C矩阵一定按列优先,则leading dimension为C的行数
• Batchcount:批处理数量
cublasStatus_t cublasSgemmStridedBatched(
cublasHandle_t handle, cublasOperation_t transa, cublasOperation_t transb,
int m, int n, int k,
const float *alpha, const float *A, int lda, long long int strideA,
const float *B, int ldb, long long int strideB, const float *beta,
float *C, int ldc, long long int strideC,
int batchCount
)
• 实现功能: C +istrideC= alpha op ( A+istrideA) op ( B +istrideB) + beta (C +i*strideC) • 参数意义
• alpha和beta是标量, A B C是以列优先存储的矩阵
• 如果 transa的参数是CUBLAS_OP_N 则op(A) = A ,如果是CUBLAS_OP_T 则op(A)=A的转置
• 如果 transb的参数是CUBLAS_OP_N 则op(B) = B ,如果是CUBLAS_OP_T 则op(B)=B的转置

若有收获,就点个赞吧
0 人点赞
