理论部分
- 学习使用CUDA Stream和Event
- 学习使用NVVP工具
技能部分
- CUDA Stream和Event的使用技巧和经验
- NVVP的使用技巧和经验
CUDA Stream
CUDA stream是GPU上task 的执行队列,所有CUDA操作(kernel,内存拷贝等)都是在stream上执行的。
CUDA stream有两种
- 隐式流,又叫默认流,NULL流
所有的CUDA操作默认运行在隐式流里。隐式流里的GPU task和CPU端计算是同步的。
举例:𝑛 = 1这行代码,必须等上面三行都执行完,才会执行它。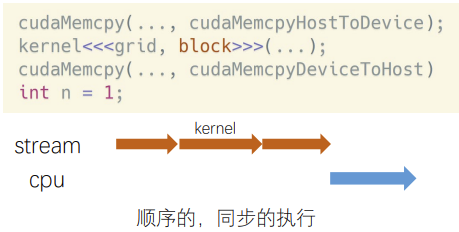
- 显式流:显式申请的流
显式流里的GPU task和CPU端计算是异步的。不同显式流内的GPU task执行也是异步的。
CUDA Stream API
定义
cudaStream_t stream;
创建
cudaStreamCreate(&stream);数据传输
cudaMemcpyAsync(dst, src, size, type, stream)kernel在流中执行
kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list);同步和查询
cudaError_t cudaStreamSynchronize(cudaStream_t stream) cudaError_t cudaStreamQuery(cudaStream_t stream);销毁
cudaError_t cudaStreamDestroy(cudaStream_t stream);CUDA Stream demo
```cpp cudaStream_t stream[2]; // 定义两个流 for (int i = 0; i < 2; i++) {
cudaStreamCreate(&stream[i]); // 创建两个流}
float hostPtr; cudaMallocHost(&hostPtr, 2 size);
// 两个流,每个流有三个命令 for (int i = 0; i < 2; i++) {
// 从主机内存复制数据到设备内存 cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]); // 再流中执行kernel函数处理 MyKernel <<< grid, block, 0, stream[i] >>> (outputDevPtr + i * size, inputDevPtr + i * size, size); // 从设备内存到主机内存 cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);}
// 同步流 for (int i = 0; i < 2; i++) {
cudaStreamSynchronize(stream[i]);}
// 销毁流 for (int i = 0; i < 2; i++) {
cudaStreamDestroy(stream[i]);}
<a name="vo6eO"></a>
### CUDA Stream 优点
- CPU计算和kernel计算并行
- CPU计算和数据传输并行
- 数据传输和kernel计算并行
- kernel计算并行
:::info
**显式流里的GPU task与CPU端 task 的执行是异步的,使用stream一定要注意同步!**
- cudaStreamSynchronize() 同步一个流
- cudaDeviceSynchronize() 同步该设备上的所有
- cudaStreamQuery() 查询一个流任务是否完成
:::
<a name="ODRjI"></a>
### 数据传输和GPU计算重叠
|  |  |
| --- | --- |
| 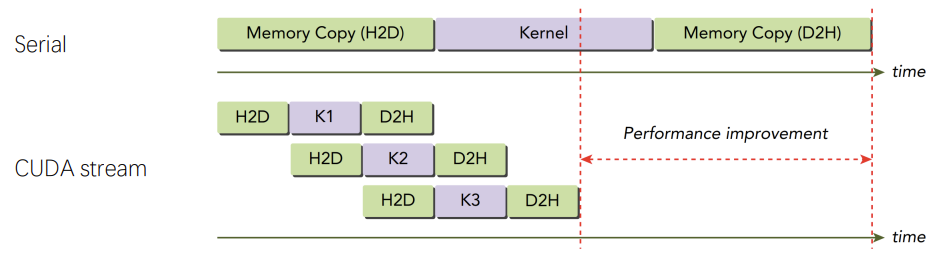 | |
流不是万能的,上述情况只是理论情况,因为流的启动和销毁是耗时的,通常kernel计算特别快,所以当数据量和计算量足够大时,这种提升效果才明显。
:::warning
H2D 、D2H与其他H2D、D2H 为什么没有重叠?它们已经在不同stream上了。
:::
因为CPU和GPU的数据传输是经过PCIe总线的,PCIe上的操作是顺序的。**带有双工PCIe总线的设备**可以重叠两个数据传输,但它们必须在不同的流和不同的方向上。
<a name="BsCEy"></a>
### CUDA Stream 优先级
GPU 算力 3.5 及以上,即Kepler架构及以上,可以为stream设置优先级
```cpp
cudaError_t cudaStreamCreateWithPriority(cudaStream_t* pStream, unsigned int flags, int priority);
cudaError_t cudaDeviceGetStreamPriorityRange(int *leastPriority, int *greatestPriority);
- stream的优先级只对kernel有效,对内存拷贝无效。
flags较低的整数值表示较高的流优先级。
CUDA Stream 为什么有效?
- PCIe总线传输速度慢,是瓶颈,会导致传输数据的时候GPU处于空闲等待状态。多流可以实现数据传输与kernel计算的并行。(NV-link可以直接挂在到IBM的power架构上,速度很快,但是一般人没有啊)
- 一个kernel往往用不了整个GPU的算力。多流可以让多个kernel同时计算,充分利用GPU算力。
流越多越好?
不是流越多越好。GPU内可同时并行执行的流数量是有限的。如果超出了设备的最大线程数,加速效果可能会直线下降。那么如何解决嘞?
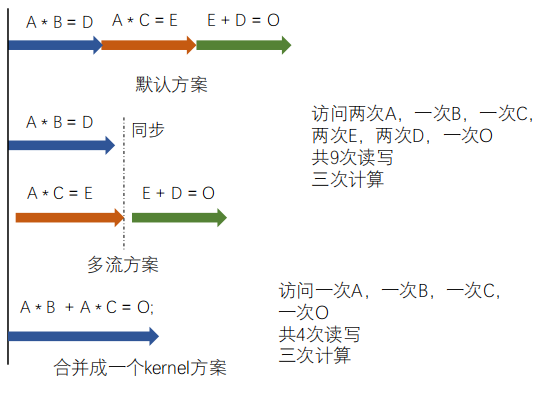
CUDA加速,kernel合并,将小任务合并成大任务,更有效。
计算密集型:耗时在计算,一次访存,数十次甚至上百次计算
访存密集型:耗时在访存,一次访存,几次计算
思考: GPU kernel耗时最大在哪里?GPU一般处理简单可并行计算,大部分kernel都是访存密集型
举例说明此问题:
| 向量𝐴、𝐵、𝐶,大小都为𝑛。 𝐴 ∗ 𝐵 = 𝐷; 𝐴 ∗ 𝐶 = 𝐸; 𝐸 + 𝐷 = 𝑂; |
 |
|---|---|
但是,计算异常复杂,不鼓励合并大kernel。GPU端的kernel并行思路 + 调试难度远远超过CPU端编程。
CUDA Stream 默认流的表现
https://developer.nvidia.com/blog/gpu-pro-tip-cuda-7-streams-simplify-concurrency/
// nvcc ./stream_test.cu -o stream_legacy
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
int main()
{
const int num_streams = 8;
cudaStream_t streams[num_streams];
float *data[num_streams];
for (int i = 0; i < num_streams; i++) {
cudaStreamCreate(&streams[i]);
cudaMalloc(&data[i], N * sizeof(float));
// launch one worker kernel per stream
kernel<<<1, 64, 0, streams[i]>>>(data[i], N);
// launch a dummy kernel on the default stream
kernel<<<1, 1>>>(0, 0);
}
cudaDeviceReset();
return 0;
}
期望运行的结果
实际运行的结果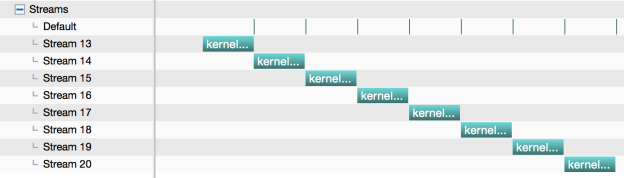
单线程内,默认流的工作方式是同步的,显示流的工作方式是异步的。
单线程内,编译加上--default-stream per-thread 后,默认流的执行是异步的,显式流的执行是异步的,符合预期。并且会将default默认流转换成显示流,才会和其他8个显示流进行异步执行。
nvcc --default-stream per-thread ./stream_test.cu -o stream_per-thread
多线程下,默认流的表现是什么呢?是一个默认流还是多个默认流?
// nvcc ./pthread_test.cu -o pthreads_legacy
#include <pthread.h>
#include <stdio.h>
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
void *launch_kernel(void *dummy)
{
float *data;
cudaMalloc(&data, N * sizeof(float));
kernel<<<1, 64>>>(data, N);
cudaStreamSynchronize(0);
return NULL;
}
int main()
{
const int num_threads = 8;
pthread_t threads[num_threads];
for (int i = 0; i < num_threads; i++) {
if (pthread_create(&threads[i], NULL, launch_kernel, 0)) {
fprintf(stderr, "Error creating threadn");
return 1;
}
}
for (int i = 0; i < num_threads; i++) {
if(pthread_join(threads[i], NULL)) {
fprintf(stderr, "Error joining threadn");
return 2;
}
}
cudaDeviceReset();
return 0;
}
正常编译的话,默认多线程共享一个默认流
加上--default-stream per-thread之后,编译,每个线程都有一个默认流
nvcc --default-stream per-thread ./pthread_test.cu -o pthreads_per_thread

CUDA Event
CUDA Event,在stream中插入一个事件,类似于打一个标记位,用来记录stream是否执行到
当前位置。
stream类似队列,不断的插入task,除了插入内存之间的copy和kernel函数的执行,还能插入Event。
Event有两个状态,已被执行和未被执行。
- 定义
• 创建cudaEvent_t event
• 插入流中cudaError_t cudaEventCreate(cudaEvent_t* event);
• 销毁cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);
• 同步和查询cudaError_t cudaEventDestroy(cudaEvent_t event);
• 进阶同步函数cudaError_t cudaEventSynchronize(cudaEvent_t event); cudaError_t cudaEventQuery(cudaEvent_t event);cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event)常用功能-测时间
```cpp //使用event计算时间 float time_elapsed = 0; cudaEvent_t start, stop; cudaEventCreate(&start); //创建Event cudaEventCreate(&stop);
cudaEventRecord(start, 0); //记录当前时间
mul<<
cudaEventSynchronize(start); // waits for an event to complete. cudaEventSynchronize(stop); // waits for an event to complete.Record之前的任务 cudaEventElapsedTime(&time_elapsed , start,stop ); // 计算时间差
cudaEventDestroy(start); // destory the event cudaEventDestroy(stop); printf(“执行时间:%f( ms ) \n”, time_elapsed);
<a name="RlVBM"></a>
## CUDA 同步操作
CUDA中的显式同步按粒度可以分为四类
- device synchronize 影响很大
- stream synchronize 影响单个流和CPU
- event synchronize 影响CPU,更细粒度的同步
- synchronizing across streams **using an event**
<a name="Ud4us"></a>
### device synchronize
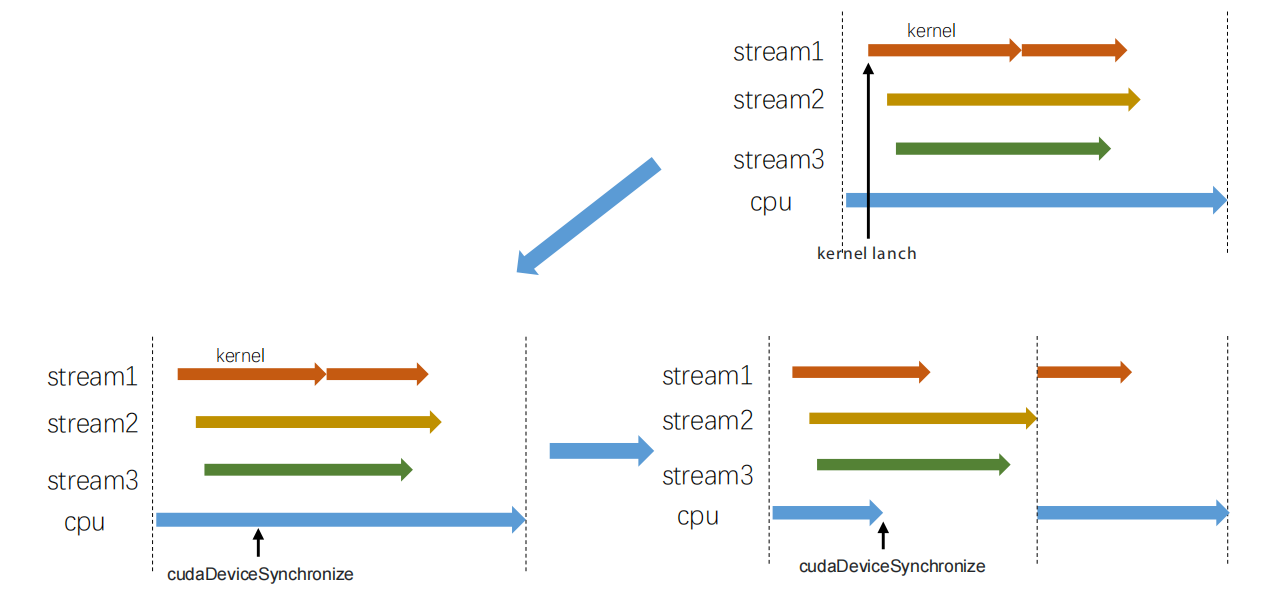<br />会让所有的流和cpu都等待。上图中有三个stream,stream1中有两个kernel,顺序执行,stream2和stream3都各自有一个kernel,cpu也在同步计算。当程序执行到短黑色箭头处,加入`cudaDeviceSynchronize`,此时程序中cpu端立马停止,进入等待模式,已经运行的kernel会执行完,没有执行的也会继续等待,直到最长的kernel执行完成。程序才会继续运行。
<a name="Q7lRj"></a>
### stream synchronize
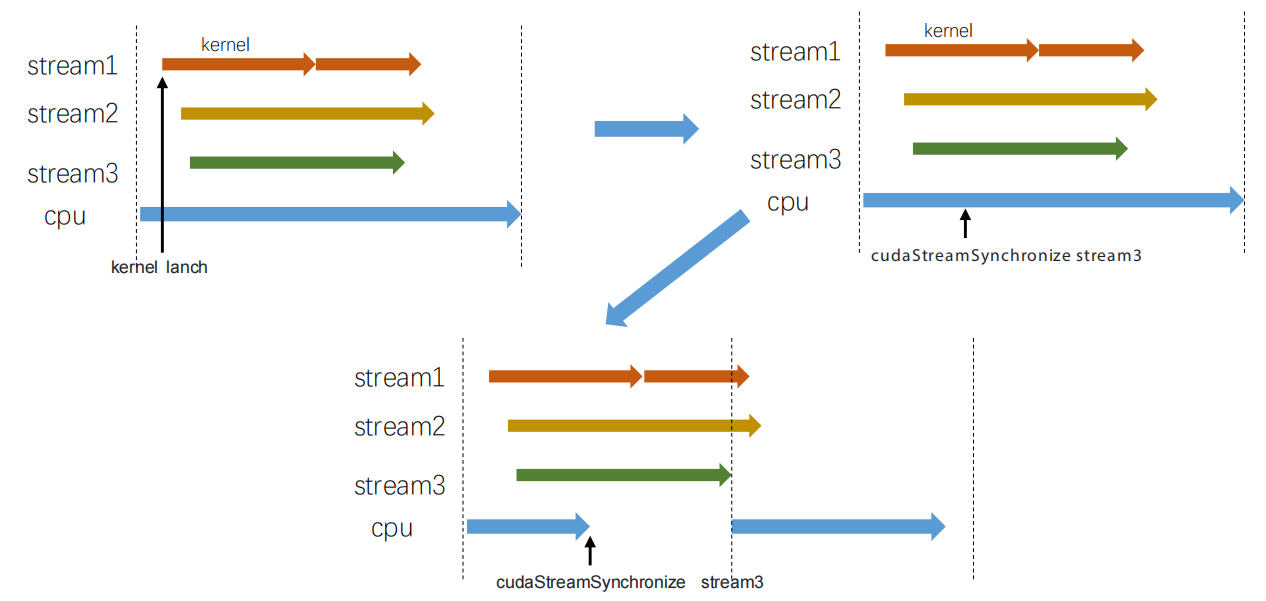<br />**影响单个流和cpu。**在短黑色箭头处插入对流stream3的同步,stream1和stream2会正常执行,cpu会立即处于等待状态,当stream3完成之后,cpu也会恢复状态、
<a name="nRqIw"></a>
### event synchronize 影响CPU,更细粒度的同步
<br />将event1插入到stream中,当运行到cudaEventSynchronize时,cpu会立即进入等待状态,等待event1被标记为完成,cpu才会继续运行。
<a name="Bdtv2"></a>
### synchronizing across streams using an event
以上三种同步,CPU一定会处于等待状态,该API可以使CPU继续执行
```cpp
cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event);
该函数会指定该stream等待特定的event,该event可以关联到相同或者不同的stream流中。
stream1和stream中有很多task在运行,当在stream1中插入event,当在stream2中运行cudaStreamWaitEvent,event是在stream1中插入的event。stream2中之后的task会等待event1完成之后,才会继续执行。
这种同步方式,高级用法,不建议设计流时这么复杂,平常用不到

若有收获,就点个赞吧
0 人点赞
