向量相加的程序中线程都是相互独立的,没有多个进程之间的通信,大多数实际的应用程序需要中间线程之间的通信。所以要探究不同线程之间如何通信,并解释对相同数据多个线程之间的同步。我们将学习CUDA的分层存储架构,以及加速CUDA代码时使用不同存储器的区别。本章最后部分会解说CUDA的重要应用:向量点乘,矩阵乘法,将使用前面介绍的所有概念。
- 线程调用
- CUDA存储器架构
- 全局内存,本地内存和缓存
- 共享内存和线程同步
- 原子操作
- 常量和纹理内存
- 点乘和矩阵乘法例子
线程
内核函数启动时,可以被切分成多个并行执行的块,每个块又可以进一步地被切分成多个线程,从而完成并行计算。并行计算可以通过两种方式完成:一种是启动多个并行的块,每个块具有1个线程;另一种是启动1个块,每个块里具有多个线程。这两种方式该如何选择?以及并行启动时有没有块和线程数量的限制?
通过共享内存,1个块中的线程可以相互通信。maxThreadPerBlock属性限制了每个块能启动的线程数量。对于最新的GPU卡来说是1024。类似地,第二种方式能最大启动的块数量被限制成 个。
个。
假设一次并行启动多个块,每个块里面多个线程(最多可以是maxThreadPerBlock)。所以,假设向量加法例子你需要启动N=50000这么多的线程,我们可以这样调用内核:
gpuAdd<<<((N+511)/512, 512)>>>(d_a, d_b, d_c);
最大的块能有1024个线程。上面例子中,每个块设置了512个线程,那么则需要有N/512个块。但是如果N不是512的整数倍,那么N除以512会计算得到错误的块数量,比实际的块数量少1个。所以为了计算得到下一个最小的能满足要求的整数结果,N需要加上511,然后再除以512。这基本上是一个除法的向上取整操作。
#include "stdio.h"#include<iostream>#include <cuda.h>#include <cuda_runtime.h>//Defining number of elements in Array#define N 50000//Defining Kernel function for vector addition__global__ void gpuAdd(int *d_a, int *d_b, int *d_c) {//Getting block index of current kernelint tid = threadIdx.x + blockIdx.x * blockDim.x;while (tid < N){d_c[tid] = d_a[tid] + d_b[tid];tid += blockDim.x * gridDim.x;}}
该代码中,和之前的向量相加的例子有两处不同:
- 计算初始tid的时候
由于我们启动了多个块,每个块里面有多个线程。下图是块和线程的示意图,多个块横排排列,每个块里面有N个线程。
tid是每个线程唯一的索引ID,计算tid的时候是用 当前块的ID*当前块里面的线程数量+当前线程在块中的ID,即**tid=blockIdx.x(当前块的ID)*blockDim.x(当前块里面的线程数量)+threadIdx.x(当前线程在块中的ID)**
灰色部分的tid = 2*3 + 1 = 7
while循环中的向量相加部分计算结束,就要更新tid的值:tid+=blockDim.x*gridDim.x。
- 添加while循环 :::info 作用:每次增加现有的线程数量(因为你没有启动到N),直到达到N(数组中元素个数)。 ::: 比如一张计算卡一次最多只能启动100个块,每个块里有7个线程,也就是一次最多能启动700个线程。但N的规模是8000,远远超过700怎么办?答案是直接启动K个(K≥700),这样就能安全启动。然后里面添加一个while循环,这700个线程第一次处理[0,699),第二次处理[700,1400),第三次处理[1400,2100)……直到这8000个元素都被处理完。
因为当N很大的时候,线程总数不可能达到N。所以,每个线程必须执行多次向量相加操作,由已启动的线程总数分隔:这个值可以用gridDim.x*blockDim.x 来计算,前者代表了本次启动的块的数量,而后者代表了每个块里面的线程数量,然后每次while循环,tid变量加上这个值,向后偏移以得到下个任务的索引。这样,该代码将可以处理任意大的值N。
存储器架构
GPU上的代码执行被划分为流多处理器、块和线程。GPU有几个不同的存储器空间,每个存储器空间都有特定的特征和用途以及不同的速度和范围。这个存储空间按层次结构划分为不同的组块,比如全局内存、共享内存、本地内存、常量内存和纹理内存,每个组块都可以从程序中的不同点访问
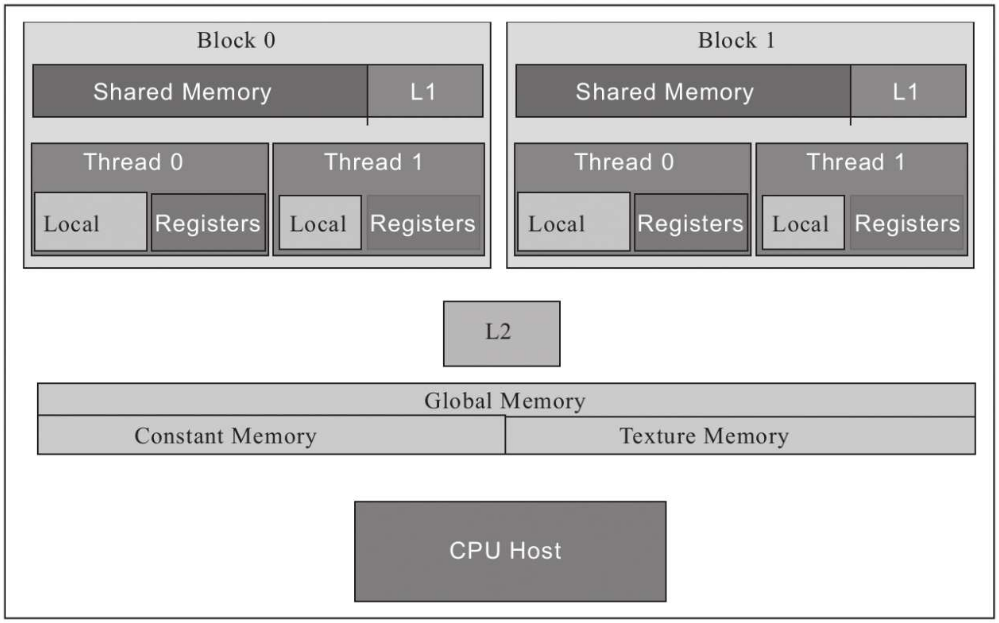 |
 |
|---|---|
- 每个线程都有自己的本地存储器
Local和寄存器堆Registers。- 与CPU不同的是,GPU核心有很多寄存器来存储数据。当线程使用的数据不适合存储在寄存器堆中或者寄存器堆中装不下的时候,将会使用本地内存
Local。 - 寄存器堆和本地内存对每个线程都是唯一的。寄存器堆是最快的一种存储器。
- 与CPU不同的是,GPU核心有很多寄存器来存储数据。当线程使用的数据不适合存储在寄存器堆中或者寄存器堆中装不下的时候,将会使用本地内存
- 同一个块中的线程具有可由该块中的所有线程访问的共享内存。
- 全局内存可被所有的块和其中的所有线程访问。它具有相当大的访问延迟,但存在缓存这种东西来给它提速。GPU有一级和二级缓存(即L1缓存和L2缓存)。
- 常量内存则是用于存储常量和内核参数之类的只读数据。
- 纹理内存,这种内存可以利用各种2D和3D的访问模式。
- 作用范围定义了程序的哪个部分能使用该存储器。而生存期定义了该存储器中的数据对程序可见的时间
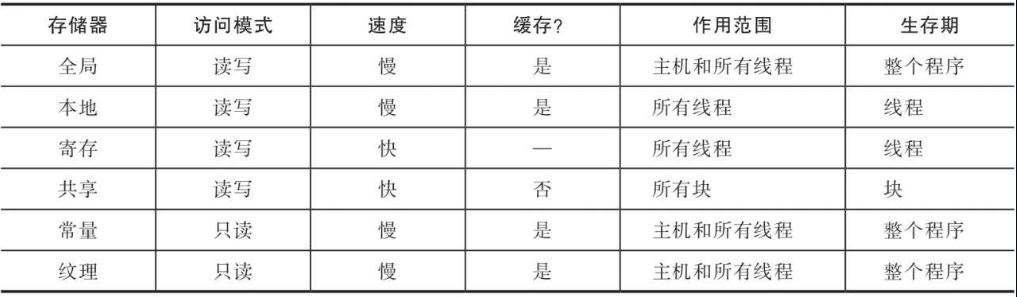
总结:
- 所有线程都有一个寄存器堆,它是最快的。
- 共享内存只能被同一块中的线程访问,但比全局内存快。
- 全局内存是最慢的,但可以被所有的块访问。
- 常量和纹理内存用于特殊用途。
- 存储器访问是程序快速执行的最大瓶颈
全局内存
所有的块中的线程都可以对全局内存进行读写。该存储器较慢,但是可以从你的代码的任何地方进行读写。缓存可加速对全局内存的访问。所有通过cudaMalloc分配的存储器都是全局内存。 ```cpp // 02_gpu_global_memory.cuinclude
define N 5
global void gpu_global_memory(int *d_a) { // “array” is a pointer into global memory on the device d_a[threadIdx.x] = threadIdx.x; }
int main(int argc, char *argv) { // Define Host Array int h_a[N]; //Define device pointer int d_a;
cudaMalloc((void **)&d_a, sizeof(int) * N);// now copy data from host memory to device memorycudaMemcpy((void *)d_a, (void *)h_a, sizeof(int) * N, cudaMemcpyHostToDevice);// launch the kernelgpu_global_memory<<<1, N>>>(d_a);// copy the modified array back to the host memorycudaMemcpy((void *)h_a, (void *)d_a, sizeof(int) * N, cudaMemcpyDeviceToHost);printf("Array in Global Memory is: \n");//Printing result on consolefor (int i = 0; i < N; i++){printf("At Index: %d --> %d \n", i, h_a[i]);}return 0;
}
上面的代码演示了:1. 如何从设备代码中进行全局内存的写入1. 如何从主机代码中用cudaMalloc进行分配1. 如何将指向该段全局内存的指针作为参数传递给内核函数。1. 内核函数用不同的线程ID的值来填充这段全局内存。1. 用cudaMemcpy复制到内存以便显示内容。<a name="rGTPh"></a>### 本地内存&寄存器堆本地内存和寄存器堆对每个线程都是唯一的。寄存器是每个线程可用的最快存储器。当内核中使用的变量在寄存器堆中装不下的时候,将会使用本地内存存储它们,这叫寄存器溢出。请注意使用本地内存有两种情况:1. 寄存器空间不够1. 某些情况下,数据不能放在寄存器中- 例如对一个局部数组的下标进行不定索引的时候。基本上可以将本地内存看成是每个线程的唯一的全局内存部分。相比寄存器堆,本地内存要慢很多。虽然本地内存通过L1缓存和L2缓存进行了缓冲,但寄存器溢出可能会影响你的程序的性能。```cpp// 03_gpu_local_memory.cu#include <stdio.h>#define N 5__global__ void gpu_local_memory(int d_in){int t_local;t_local = d_in * threadIdx.x;printf("Value of Local variable in current thread is: %d \n", t_local);}int main(int argc, char **argv){printf("Use of Local Memory on GPU:\n");gpu_local_memory<<<1, N>>>(5);cudaDeviceSynchronize();return 0;}
代码中的t_local变量是每个线程局部唯一的,将被存储在寄存器堆中。用这种变量计算的时候,计算速度将是最快速的。
高速缓冲器
在较先进的GPU上,每个流多处理器SM都含有自己独立的L1缓存,以及GPU有L2缓存。L2缓存是所有的GPU中的流多处理器都共有的。所有的全局内存访问和本地内存访问都使用这些缓存,因为L1缓存在流多处理器内部独有,接近线程执行所需要的硬件单位,所以它的速度非常快。一般来说,L1缓存和共享内存共用同样的存储硬件,一共是64KB(注意:这是和计算能力有关,不一定共用相同的存储硬件,也不一定可以配置互相占用的比例,例如计算能力5.X和6.X的GPU卡就不能。同时L1缓存和共享内存在这两个计算能力上也不是共用的,但旧的计算能力和7.X GPU卡是如此),你可以配置L1缓存和共享内存分别在这64KB中的比例。所有的全局内存访问通过L2缓存进行。纹理内存和常量内存也分别有它们独立的缓存。
线程同步
向量相加的程序中线程都是独立计算的。但是实际上,很多程序需要线程之间需要互相交换数据才能完成。因此,必须存在某种能让线程彼此交流的机制——共享内存。当很多线程并行工作并且访问相同的数据或者存储器位置的时候,线程间必须正确的同步,因此还需要有线程同步机制。原子操作在正确地进行“读取-修改-写入”操作序列的时候非常有用。
:::info 需要说明的是:线程间交换数据并不一定需要使用共享内存,只是共享内存较快而已。使用全局内存同样可以。例如配合正确的同步操作或者原子操作(原子操作也支持全局内存),依然可以正确地完成任务。只是使用共享内存,很多情况下较快(延迟较低,带宽较大)而已。 :::
共享内存
共享内存位于芯片内部,因此它比全局内存快得多。(CUDA里面存储器的快慢有两方面,一个是延迟低,一个是带宽大)共享内存的快指的是延迟低,相比没有经过缓存的全局内存访问,共享内存大约在延迟上低100倍。同一个块中的线程可以访问相同的一段共享内存(注意:不同块中的线程所见到的共享内存中的内容是不相同的),这在许多线程需要与其他线程共享它们的结果的应用程序中非常有用。但是如果不同步,也可能会造成混乱或错误的结果。如果某线程的计算结果在写入到共享内存完成之前被其他线程读取,那么将会导致错误。因此,应该正确地控制或管理内存访问。这是由__syncthreads()指令完成的,该指令确保在继续执行程序之前完成对内存的所有写入操作。这也被称为barrier:含义是块中的所有线程都将到达该代码行,然后在此等待其他线程完成。当所有线程都到达了这里之后,它们可以一起继续往下执行。
// 计算MA__global__ void gpu_shared_memory(float *d_a){// Defining local variables which are private to each threadint i, index = threadIdx.x;float average, sum = 0.0f;//Define shared memory__shared__ float sh_arr[10];sh_arr[index] = d_a[index];__syncthreads(); // This ensures all the writes to shared memory have completedfor (i = 0; i <= index; i++){sum += sh_arr[i];}average = sum / (index + 1.0f);d_a[index] = average;}
MA操作:计算数组中当前元素之前所有元素的平均值。很多线程计算的时候将会使用数组中的同样的数据。这种情况使用共享内存,会得到比全局内存更快的数据访问。这将减少每个线程的全局内存访问次数,从而减少程序的延迟。
共享内存上的数字或者变量是通过__shared__修饰符定义的。10行代码:在共享内存上,定义了具有10个float元素的数组。通常,共享内存的大小应该等于每个块的线程数。
12行代码:将数据从全局内存复制到共享内存。每个线程通过自己的索引复制一个元素,这样就完成了数据的复制操作,这样数据写到了共享内存中。16行开始读取使用这个共享内存中的数组,但是在继续之前,我们应当保证所有(线程)都已经完成了它们的写入操作。所以,在14行使用了__syncthreads()进行一次同步。
接着就是(每个线程)通过for循环,利用这些存储在共享内存中的值(读取后)计算(从第一个元素)到当前元素的平均值,并且将对应每个线程的结果存放到全局内存中的相应位置。
对应的main函数如下:
int main(int argc, char **argv){//Define Host Arrayfloat h_a[10];//Define Device Pointerfloat *d_a;for (int i = 0; i < 10; i++){h_a[i] = i;}// allocate global memory on the devicecudaMalloc((void **)&d_a, sizeof(float) * 10);// now copy data from host memory to device memorycudaMemcpy((void *)d_a, (void *)h_a, sizeof(float) * 10, cudaMemcpyHostToDevice);gpu_shared_memory<<<1, 10>>>(d_a);// copy the modified array back to the host memorycudaMemcpy((void *)h_a, (void *)d_a, sizeof(float) * 10, cudaMemcpyDeviceToHost);printf("Use of Shared Memory on GPU: \n");//Printing result on consolefor (int i = 0; i < 10; i++){printf("The running average after %d element is %f \n", i, h_a[i]);}return 0;}
在main函数中,当分配好主机和设备上的数组后,用0到9填充主机上的数组h_a,然后将这个数组复制到显存d_a。内核函数将对显存中的数据进行读取,计算并保存结果。最后结果从显存中传输到内存,然后在控制台上输出。本节演示了当多个线程使用来自相同内存区域的数据时,共享内存的使用。
原子操作
考虑当大量的线程需要试图修改一段较小的内存区域的情形,这是(在日常的算法实现中)常发生的现象。当我们试图进行“读取-修改-写入”操作序列的时候,这种情形经常会带来很多麻烦。一个例子是代码d_out[i]++,这代码首先将d_out[i]的原值从存储器中读取出来,然后执行了+1操作,再将结果回写到存储器。然而,如果多个线程试图在同一个内存区域中进行这个操作,则可能会得到错误的结果。
假设某内存区域中有初始值6,两个线程p和q分别试图将这段区域中的内容+1,则最终的结果应当是8。但是在实际执行的时候,可能p和q两个线程同时读取了这个初始值,两者都得到了6,执行+1操作都得到了7,然后它们将7写回这个内存区域。最终结果是7,这是错误的。为了示范一下这种情形,我们做了一个很多线程试图同时访问一个小数组的例子。
#include <stdio.h>#define NUM_THREADS 10000#define SIZE 10#define BLOCK_WIDTH 100__global__ void gpu_increment_without_atomic(int *d_a){// Calculate thread id for current threadint tid = blockIdx.x * blockDim.x + threadIdx.x;// each thread increments elements wrapping at SIZE variabletid = tid % SIZE;d_a[tid] += 1;}int main(int argc, char **argv){printf("%d total threads in %d blocks writing into %d array elements\n",NUM_THREADS, NUM_THREADS / BLOCK_WIDTH, SIZE);// declare and allocate host memoryint h_a[SIZE];const int ARRAY_BYTES = SIZE * sizeof(int);// declare and allocate GPU memoryint *d_a;cudaMalloc((void **)&d_a, ARRAY_BYTES);//Initialize GPU memory to zerocudaMemset((void *)d_a, 0, ARRAY_BYTES);gpu_increment_without_atomic<<<NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH>>>(d_a);// copy back the array to host memorycudaMemcpy(h_a, d_a, ARRAY_BYTES, cudaMemcpyDeviceToHost);printf("Number of times a particular Array index has been incremented without atomic add is: \n");for (int i = 0; i < SIZE; i++){printf("index: %d --> %d times\n ", i, h_a[i]);}cudaFree(d_a);return 0;}
内核函数简单地通过d_a[tid]+=1这行代码来增加存储器中元素的值。关键的问题在于(这行代码)对应的具体内存区域被增加了多少次?线程总数为10000,数组里只有10个(元素)。通过求余(求模,%)运算,来将这10000个线程ID对应的索引到这10个元素上去。所以,每个相同的内存中的元素位置将有1000个线程来进行(+1)的运算。理想状态下,数组中每个位置的元素将被增加1000(次个1)。main函数中,显存中的数组被分配并被初始化为0。这里,cudaMemset函数用来进行显存上的初始化工作,然后将初始化为0值的数组作为参数传递给内核。这个内核将会进行增加这10个元素的工作。这里,我们用100个块,每个块里有100个线程,一共启动10000个线程。最终计算结果将被保存在显存上,并在内核执行完成后复制回内存,同时我们在控制台上显示每个内存区域的结果值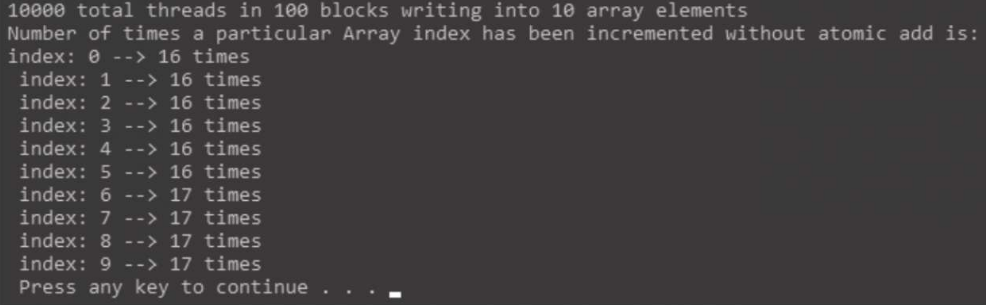
理想状态下,每个元素位置应当都增加了1000,但是运行结果表明实际上大部分元素位置只增加了16或17,这是因为很多线程同时读取同样的位置,然后增加同样的值,并将它们存储到显存中。线程执行的具体时序问题超出了程序员所能控制的范围,和GPU硬件有关,具体每个有多少线程在对同样的显存位置进行访问是无法具体知道的。如果你再次运行一遍程序,运行的结果不一定会相同,这是设备上不定顺序的多线程执行导致的。
为了解决这个问题,CUDA提供了atomicAdd这种原子操作函数。该函数会从逻辑上保证,每个调用它的线程对相同的内存区域上的“读取旧值-累加-回写新值”操作是不可被其他线程扰乱的原子性的整体完成的。使用atomicAdd进行原子累加的代码如下:
#include <stdio.h>#define NUM_THREADS 10000#define SIZE 10#define BLOCK_WIDTH 100__global__ void gpu_increment_atomic(int *d_a){// Calculate thread id for current threadint tid = blockIdx.x * blockDim.x + threadIdx.x;// each thread increments elements wrapping at SIZE variabletid = tid % SIZE;atomicAdd(&d_a[tid], 1);}int main(int argc, char **argv){printf("%d total threads in %d blocks writing into %d array elements\n",NUM_THREADS, NUM_THREADS / BLOCK_WIDTH, SIZE);// declare and allocate host memoryint h_a[SIZE];const int ARRAY_BYTES = SIZE * sizeof(int);// declare and allocate GPU memoryint *d_a;cudaMalloc((void **)&d_a, ARRAY_BYTES);//Initialize GPU memory to zerocudaMemset((void *)d_a, 0, ARRAY_BYTES);gpu_increment_atomic<<<NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH>>>(d_a);// copy back the array to host memorycudaMemcpy(h_a, d_a, ARRAY_BYTES, cudaMemcpyDeviceToHost);printf("Number of times a particular Array index has been incremented is: \n");for (int i = 0; i < SIZE; i++){printf("index: %d --> %d times\n ", i, h_a[i]);}cudaFree(d_a);return 0;}
使用atomicAdd原子操作函数替换了之前的直接+=操作,该函数具有2个参数:
- 第一个参数:我们要进行原子加法操作的内存区域;
- 第二个参数:该原子加法操作具体要加上的值。
在这个代码中,100个线程对同一内存区域进行原子+1操作,这100次相同区域上的操作,每次都将从逻辑上安全地完整执行。这可能会增加执行时间上的代价。可以通过使用共享内存来加速这些原子累加操作。如果线程规模不变,但原子操作的元素数量扩大,则这些同样次数的原子操作会更快地完成。这是因为更广泛的分布范围上的原子操作有利于利用多个能执行原子操作的单元,以及每个原子操作单元上面的竞争性的原子事务也相应减少了。
常量内存
CUDA程序员会经常用到另外一种存储器—常量内存,NVIDIA GPU卡从逻辑上对用户提供了64KB的常量内存空间,可以用来存储内核执行期间所需要的恒定数据。常量内存对一些特定情况下的小数据量的访问具有相比全局内存的额外优势。使用常量内存也一定程度上减少了对全局内存的带宽占用。在将用一个简单的程序进行a*x+b的数学运算,其中a,b都是常数,程序代码如下:
#include "stdio.h"
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
//Defining two constants
__constant__ int constant_f;
__constant__ int constant_g;
#define N 5
//Kernel function for using constant memory
__global__ void gpu_constant_memory(float *d_in, float *d_out)
{
//Thread index for current kernel
int tid = threadIdx.x;
d_out[tid] = constant_f * d_in[tid] + constant_g;
}
int main(void)
{
//Defining Arrays for host
float h_in[N], h_out[N];
//Defining Pointers for device
float *d_in, *d_out;
int h_f = 2;
int h_g = 20;
// allocate the memory on the cpu
cudaMalloc((void **)&d_in, N * sizeof(float));
cudaMalloc((void **)&d_out, N * sizeof(float));
//Initializing Array
for (int i = 0; i < N; i++)
{
h_in[i] = i;
}
//Copy Array from host to device
cudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);
//Copy constants to constant memory
cudaMemcpyToSymbol(constant_f, &h_f, sizeof(int), 0, cudaMemcpyHostToDevice);
cudaMemcpyToSymbol(constant_g, &h_g, sizeof(int));
//Calling kernel with one block and N threads per block
gpu_constant_memory<<<1, N>>>(d_in, d_out);
//Coping result back to host from device memory
cudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);
//Printing result on console
printf("Use of Constant memory on GPU \n");
for (int i = 0; i < N; i++)
{
printf("The expression for input %f is %f\n", h_in[i], h_out[i]);
}
//Free up memory
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
常量内存中的变量使用__constant__关键字修饰。两个浮点数constant_f,constant_g被定义成在内核执行期间不会改变的常量。需要注意的第二点是,使用__constant__(在内核外面)定义好了它们后,不用在内核函数内部定义。内核函数将用这两个常量进行一个简单的数学运算,在main函数中,我们用一个特殊的方式将这两个常量的值传递到常量内存中。
在main函数中,h_f,h_g 两个常量在主机Host上被定义并初始化,然后使用cudaMemcpyToSymbol函数把这些常量复制到内核执行所需要的常量内存中。该函数具有五个参数:
- 第一个参数是(要写入的)目标,也就是我们刚才用constant定义过的
h_f或者h_g常量; - 第二个参数是源主机地址;
- 第三个参数是传输大小;
- 第四个参数是写入目标的偏移量,这里是0;
- 第五个参数是设备到主机的数据传输方向;
- 最后两个参数是可选的,因此后面我们第二次cudaMemcpyToSymbol函数调用的时候省略掉了它们。
常量内存是只读的,常量内存有助于节省全局内存的访问带宽。如果要明白这点,你必须知道warp的概念。warp是32个交织在一起的线程的集合,这些线程将同步执行每一条指令(注意从计算能力7.0+的GPU卡开始不再是这样了)。在一定的情况下,warp整体进行一次常量内存的读取,结果广播给warp里的32个线程。同时,常量内存具有cache缓冲。当后续的在邻近位置上访问,将不会发生额外的从显存过来的传输。每个warp里的32个线程,进行一致性的相同常量内存位置读取的时候,这种广播效果和cache命中效果可以节省执行时间。需要注意的是,当每个warp里的32个线程都读取完全不同的地址的时候,此时常量内存访问反而可能会增加执行时间。完全不同地址的读取可以考虑共享内存这个适合小范围的毫无规律的读取。所以,常量内存需要小心合理地使用。
纹理内存
纹理内存是另外一种当数据的访问具有特定的模式的时候能够加速程序执行,并减少显存带宽的只读存储器。像常量内存一样,它也在芯片内部有cache。该存储器最初是为了图形绘制而设计的,但也可以被用于通用计算。当程序进行具有很大程度上的空间邻近性的访存的时候,这种存储器变得非常高效。
空间邻近性的意思是,每个线程的读取位置都和其他线程的读取位置邻近。这对那些需要处理4个邻近的相关点或者8个邻近的点的图像处理应用非常有用。一种线程进行2D的平面空间邻近性的访存的例子,可能会像下图所示。
通用的全局内存的cache将不能有效处理这种空间邻近性,可能会导致进行大量的显存读取传输。纹理存储被设计成能够利用这种访存模型,这样它只会从显存读取1次,然后缓冲掉,所以执行速度将会快得多。纹理内存支持2D和3D的纹理读取操作,在你的CUDA程序里面使用纹理内存可没有那么容易,特别是对那些并非编程专家的人来说。下面是通过纹理存储进行数组赋值的例子:
#include "stdio.h"
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#define NUM_THREADS 10
#define N 10
texture<float, 1, cudaReadModeElementType> textureRef;
__global__ void gpu_texture_memory(int n, float *d_out)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n)
{
float temp = tex1D(textureRef, float(idx));
d_out[idx] = temp;
}
}
通过“纹理引用”来定义一段能进行纹理拾取的纹理内存。纹理引用是通过texture<>类型的变量进行定义的。定义的时候,它具有3个参数:
- 第一个是texture<>类型的变量定义时候的参数,用来说明纹理元素的类型。在本例中,是foat类型;
- 第二个参数说明了纹理引用的类型,可以是1D的,2D的,3D的。在本例中,是1D的纹理引用;
- 第三个参数则是读取模式,这是一个可选参数,用来说明是否要执行读取时候的自动类型转换。
请一定要确保纹理引用被定义成全局静态变量,同时还要确保它不能作为参数传递给任何其他函数。在这个内核函数中,每个线程通过纹理引用读取自己线程ID作为索引位置的数据,然后复制到d_out指针指向的全局内存中。本例中,并没有利用任何空间邻近性。空间临近性的用例将在我们讲如何用CUDA进行图像处理的时候再进行讲解。
int main()
{
//Calculate number of blocks to launch
int num_blocks = N / NUM_THREADS + ((N % NUM_THREADS) ? 1 : 0);
//Declare device pointer
float *d_out;
// allocate space on the device for the result
cudaMalloc((void **)&d_out, sizeof(float) * N);
// allocate space on the host for the results
float *h_out = (float *)malloc(sizeof(float) * N);
//Declare and initialize host array
float h_in[N];
for (int i = 0; i < N; i++)
{
h_in[i] = float(i);
}
//Define CUDA Array
cudaArray *cu_Array;
cudaMallocArray(&cu_Array, &textureRef.channelDesc, N, 1);
//Copy data to CUDA Array
cudaMemcpyToArray(cu_Array, 0, 0, h_in, sizeof(float) * N, cudaMemcpyHostToDevice);
// bind a texture to the CUDA array
cudaBindTextureToArray(textureRef, cu_Array);
//Call Kernel
gpu_texture_memory<<<num_blocks, NUM_THREADS>>>(N, d_out);
// copy result back to host
cudaMemcpy(h_out, d_out, sizeof(float) * N, cudaMemcpyDeviceToHost);
printf("Use of Texture memory on GPU: \n");
for (int i = 0; i < N; i++)
{
printf("Texture element at %d is : %f\n", i, h_out[i]);
}
free(h_out);
cudaFree(d_out);
cudaFreeArray(cu_Array);
cudaUnbindTexture(textureRef);
}
在main函数中,定义并分配了内存和显存上的数组后,主机上的数组(中的元素)被初始化为0-9的值。本例中,你会第一次看到CUDA数组的使用。它们类似于普通的数组,但是却是纹理专用的。CUDA数组对于内核函数来说是只读的。但可以在主机上通过CudaMemcpyToArray函数写入。
在cudaMemcpyToArray函数中,第二个和第三个参数中的0代表传输到的目标CUDA数组横向和纵向上的偏移量。两个方向上的偏移量都是0代表我们的这次传输将从目标CUDA数组的左上角(0,0)开始。CUDA数组中的存储器布局对用户来说是不透明的,这种布局对纹理拾取进行过特别优化。
cudaBindTextureToArray函数,将纹理引用和CUDA数组进行绑定。我们之前写入内容的CUDA数组将成为该纹理引用的后备存储。纹理引用绑定完成后我们调用内核,该内核将进行纹理拾取,同时将结果数据写入到显存中的目标数组。
:::info 注意:CUDA对于显存中常见的大数据量的存储方式有两种:
- 一种是普通的线性存储,可以直接用指针访问。
- 另外一种则是CUDA数组,对用户不透明,不能在内核里直接用指针访问,需要通过texture或者surface的相应函数进行访问。 :::
本例的内核中,从texturere ference进行的读取使用了相应的纹理拾取函数,而写入直接用普通的指针(d_out[])进行。当内核执行完成后,结果数组被复制回到主机上的内存中,然后在控制台窗口中显示出来。当使用完纹理存储后,我们需要调用cudaUnbindTexture函数解除绑定。然后使用cudaFreeArray()函数释放刚才分配的CUDA数组空间。

若有收获,就点个赞吧
0 人点赞
