CPU vs. GPU
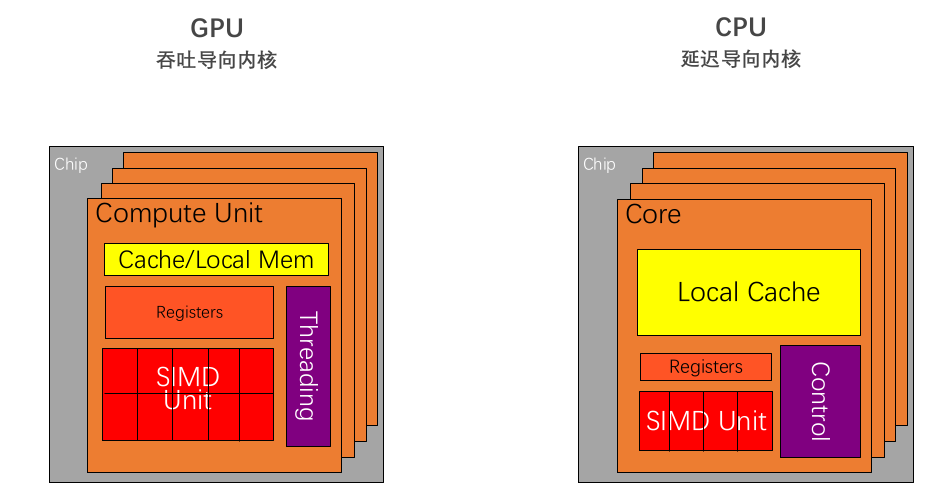
GPU就是我们常说的显卡,目前已经大规模应用于手机端、服务器端,进行图像图形的并行处理。
CPU就是我们常说的中央处理器,几乎每一个电子产品中都存在CPU,来扮演计算核心以及控制核心的个角色。提到这个处理器结构呢,有两个指标是我们这个经常要考虑的,一个指标是延迟;另外一个指标是吞吐量。
这两个指标呢对于处理器结构的设计呢是非常重要的。下面呢我们也将不断的提到这两个指标。
- 延迟:一条指令从他发出到最终返回结果中间经历的这个时间间隔。
- 吞吐量:单位时间内处理的指令的条数。
CPUs: 延迟导向设计 vs. GPUs: 吞吐导向设计
|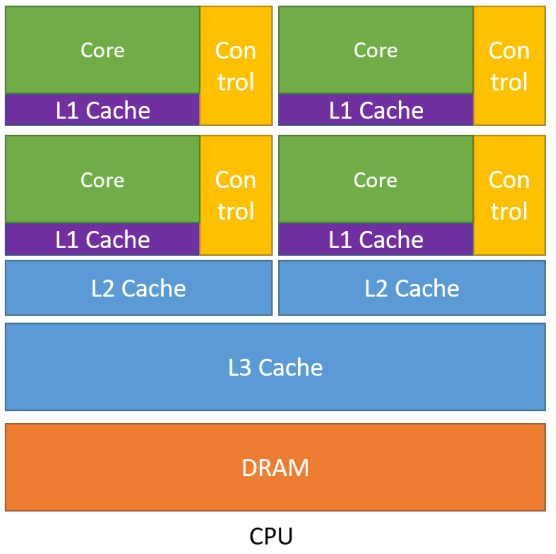 | 内存大
| 内存大
• 多级缓存结构提高访存速度
控制复杂
• 分支预测机制
• 流水线数据前传
运算单元强大
• 整型浮点型复杂运算速度快
CPUs: 连续计算部分,延迟优先
•CPU比 GPU ,单条复杂指令延迟快10倍以上 | | —- | —- | | 这幅图是一个CPU结构,从图中可以看到CPU的几个典型的特点。
1. 第一个特点:CPU中包含了多级高速缓存结构。
因为处理运算的速度要远高于访问存储的速度。因此按照空间换时间的这个基本思想,cpu中设计这种多级缓存的结构。将经常访问的内容放到L1低级缓存中,而将不经常访问的内容放到L3高级缓存中,从而提升这个指令访问存储的速度。
2. 第二个特点:有复杂的控制单元
控制单元里有两个很重要的机制,一个是这个分支预测机制,一个是流水线前传机制。
什么叫分支预测机制?比如说我们程序里有这种if-else判断分支结构,并且在程序里经常有break、continue的命令。这些指令在实际的硬件端就需要CPU中的控制器进行判断究竟这条指令是要进这一个条件,还是进另外一个条件,是从这个条件退出,还是继续当前循环等等。这就需要控制单元进行分支预测判断。
另外流水线前传机制,CPU中的数据机制并不是一个完全串行的,它是一个流水线串行的。对于一些经常访问到的数据,经过判断,之后会马上访问到这些数据,CPU会用流水线前传机制尽可能将其向前推进,使得指令并不需要等待过长时间就可以使用这些数据。
通过这两种机制使得复杂的控制指令的时延尽可能减小。
3. 第三个特点:强大的运算单元
CPU的运算单元支持整型、浮点型的四则运算,还支持与、或、非、异或这种逻辑运算等等。强大的运算单元使得CPU计算复杂指令的时延尽可能小。
通过上面三个CPU的特点,我们可以看到CPU的设计过程,始终是以减少指令的时延来进行设计。因此我们称CPU为延迟导向设计的运算处理器。 | | |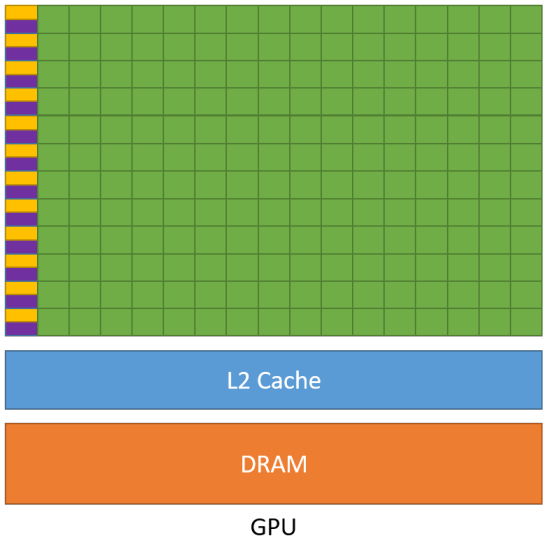 | 缓存小
| 缓存小
• 提高内存吞吐
控制简单
• 没有分支预测
• 没有数据转发
精简运算单元
• 多长延时流水线以实现高吞吐量
• 需要大量线程来容忍延迟
GPUs: 并行计算部分,吞吐优先
•GPU比 CPU ,单位时间内执行指令数量10倍以上 | | 上图是GPU的结构示意图。与之前CPU结构相比有非常大的不同。
1. 首先第一点不同:虽然GPU也有缓存结构,但是它的缓存非常小。使得指令访问缓存的次数显著减少,这无疑能提升指令来去访问内存的这个吞吐量。
2. GPU中的第二个特点:控制单元非常简单。
具体来说呢,在GPU的控制单元中,并没有这种分支预测机制和数据转发机制。虽然这会使得控制复杂的指令在GPU中的效率降低,但是GPU的控制单元对控制简单的指令的吞吐量会显著的提高。
3. GPU中的第三个特点:计算单元的数量是非常多的。
这些计算单元采用长延时流水线的机制,非常高的提升了GPU对于这些运算简单指令的吞吐量。
4. 第四个特点比较隐藏:对于每一行运算单元,它的控制器只有一个。
也就意味着每一行的运算单元,他去执行的控制指令是同一个,只是使用了不同的数据。而这种整齐划一的运算的方式,使得GPU对于那些控制简单而运行高效的指令的吞吐会显著的增加。
通过以上这四个特点可以看出:GPU在设计过程中始终以一个原则为核心:增加指令的吞吐量。因此呢我们称GPU为吞吐导向设计的运算处理器。 | |
那么到这里呢,我们就有一个问题,那就是究竟是GPU好还是CPU好?其实不管是基于吞吐量设计的运算处理器,还是基于延迟导向设计的处理器,并没有一个统一的固定的标准来去判断孰优孰劣。而是要根据我们实际的运算任务来去决定究竟是使用GPU还是CPU。
以CPU为例,其三个显著的特点:多级高速缓存,强大的控制单元,以及强大的计算单元。这三个特点保证了CPU在处理指令时的延迟非常小。那么对于那些控制复杂、计算复杂的指令来说呢,单条复杂指令延迟比GPU快10倍以上。
GPU的四个特点:小缓存、精简的控制单元、数量庞大并且并行度高的运算单元。
那么当控制简单的、计算并行度高的指令放在GPU上,单位时间内执行指令数量(吞吐量)是CPU的10倍以上。
一个形象的比喻:CPU就好比一个优秀的大学生来去进行做题;GPU就好比1000个优秀的中学生去做题。那么做题的效果如何呢?是要根据这个题的属性去选择,是让一个大学生来去做题,还是让一千多个优秀的中学生去做题。也就是说我们究竟是使用CPU还是使用GPU。
GPU编程: 什么样的问题适合GPU
什么样的问题适合使用GPU。其实我们可以从刚才提到的GPU的四个特点上总结出哪些问题适合使用。首先第一个特点:缓存非常小,因此那些需要频繁访问缓存的程序并不适合在GPU上执行。第二个特点:GPU没有复杂的控制单元,因此那些控制复杂的指令不适合在GPU上进行执行。第三个特点:有大量简单的计算单元,计算密集的程序很适合在GPU上进行执行。最后一个特点:每一行的运算单元的控制器只有一个。使得那些并行度高的程序适合在GPU上执行。
总结:
- 计算密集:
- 数值计算的比例要远大于内存操作,因此内存访问的延时可以被计算掩盖。
- 数据并行:
- 大任务可以拆解为执行相同指令的小任务,因此对复杂流程控制的需求较低。
我们举一些并不满足计算密集的一些指令:比如说我们要使用网络传输进行收包,这个发包收包的这些任务。因为它要频繁的使用网络进行传输,对于内存的访问也是非常频繁的,就不能称之为一个计算密集的任务;比如杀毒软件或者一些磁盘清理工具,都不只是访问内存,还需要频繁的访问磁盘。这些任务都不是计算密集任务。
那么对于不满足数据并行的这样一个程序呢,其实最显著的就是时序的任务。因为时序任务在下一时刻执行的结果是要依赖前一个时刻程序执行的结果。因此这种程序在时序上就不满足数据可并行的特点。
GPU编程与CUDA
上面部分简单介绍了GPU和CPU在结构上的基本特点。下面开始介绍GPU编程的基本知识。
CUDA(Compute Unified Device Architecture,字面意思理解:设备计算统一框架),由英伟达公司2007年开始推出,初衷是为GPU增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语,就可以使用GPU进行并行编程操作。
OpenCL(Open Computing Languge)是2008年发布的异构平台并行编程的开放标准,也是一个编程框架。OpenCL相比CUDA,支持的平台更多,除了GPU还支持CPU、DSP、FPGA等设备。
CUDA编程并行计算整体流程
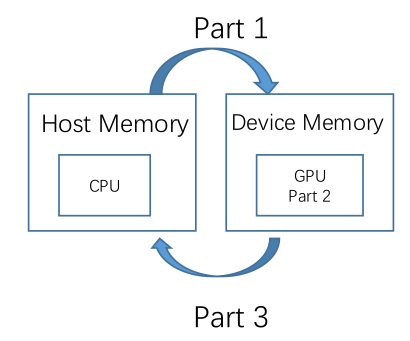
下面我们举一些实际的CUDA编程的细节,去熟悉CUDA编程。一个CUDA程序可以把它分为三个部分:
- 第一个部分:从主机端申请内存,然后把内存的内容拷贝到设备端,从host memory拷贝到device memory。
- 第二个部分:在设备端的核函数进行计算,实现运算的结果。实现那些符合计算密集和数据并行特点的程序。
- 第三部分呢:从device memory(设备端)拷贝到host memory(主机端)的这么一个操作,并且释放显存以及内存的操作。
|
 |
| cpp void GPUkernel(float* A, float* B, float* C, int n) { // 1. Allocate device memory for A, B, and C // 2. copy A and B to device memory // 3. Kernel launch code – to have the device to perform the actual vector addition // 4. copy C from the device memory // 5. Free device vectors }| | —- | —- |
CUDA编程术语
硬件

- Device=GPU
- Host=CPU
- Kernel=GPU上运行的函数
设备端指GPU;主机端指CPU;核函数指在GPU上运行的函数。gpu和cpu之间通过这种内存和显存之间的这个互相拷贝进行参数的传递。这就引出了CUDA编程中非常重要的一个概念:内存模型。
内存模型
在CUDA编程中的内存模型,可以在硬件侧和软件侧来去共同解释的。我们先在硬件侧解释这个CUDA中内存模型。
在硬件侧,CUDA内存模型的最基本的单位是线程处理器SP。每个线程处理器有自己的寄存器registers和局部内存local memory,每个线程处理器的寄存器和局部内存只能被自己访问。不同的线程处理器之间呢是彼此独立的。
那么由多个线程处理器和一个共享内存一起构成的就是多核处理器SM。多核处理器的不同的线程处理器之间是互相并行的,不互相影响的。
共享内存是可以被多核处理器里边的每一个线程处理器进行访问的,只不过这个共享内存的大小会比较小,因此只能存放经常被访问到的内容。
由多个多核处理器和全局内存就构成了设备端GPU。类似的,不同的多核处理器之间是相互并行的,全局内存是可以被所有的多核处理器访问。
总结:
CUDA中的内存模型在硬件侧分为以下几个层次:
- 每个线程处理器(SP)都用自己的registers(寄存器)
- 每个SP都有自己的local memory(局部内存),register和local memory只能被线程自己访问
- 每个多核处理器(SM)内都有自己的shared memory(共享内存),shared memory 可以被线程块内所有线程访问
- 一个GPU的所有SM共有一块global memory(全局内存),不同线程块的线程都可使用
在软件侧
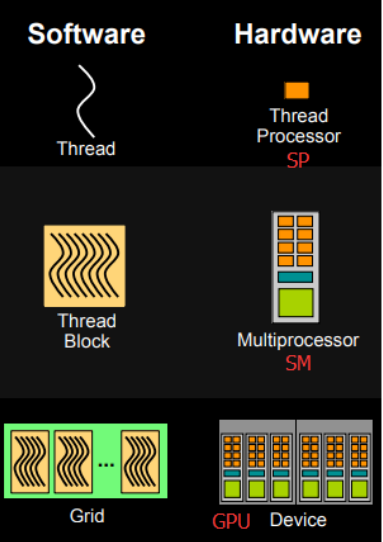 |
在软件侧,CUDA中的内存模型分为以下几个层次: - 线程处理器(SP)对应线程(thread) - 多核处理器(SM)对应线程块(thread block) - 设备端(device)对应线程块组合体(grid) 一个kernel其实由一个grid来执行, 一个kernel一次只能在一个GPU上执行 |
|---|---|
线程块:可扩展的集合体
将线程数组分成多个块
- 块内的线程通过共享内存、原子操作和屏障同步进行协作( shared memory, atomic operations and barrier synchronization )
- 不同块中的线程不能协作
线程是在内存模型在软件侧最基本的执行单位。线程块就是线程的组合体,有如下特点:
- 线程块内的线程计算、访问存储是彼此互相独立并不影响的。
- 线程块中的共享内存可以由线程块内所有线程访问。
- 用共用的时钟将线程块内的所有线程进行同步和原子操作。
例子:
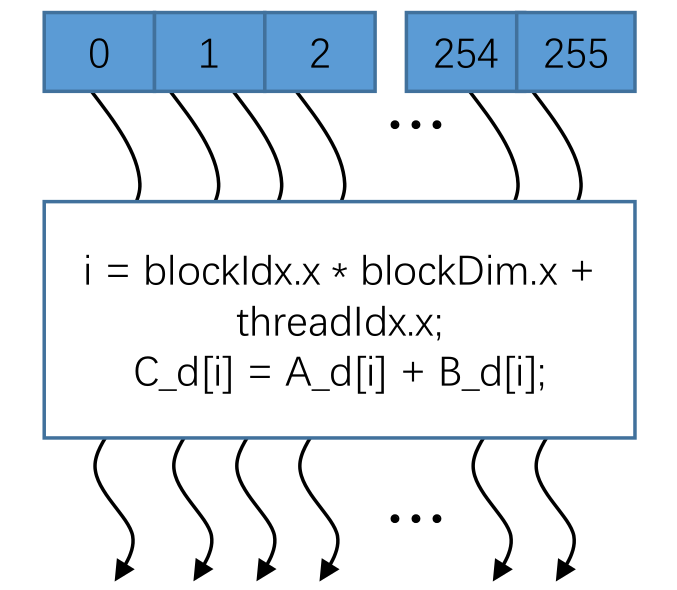 |
这个线程块是由256个线程组成,执行的任务就是向量相加操作,而这256个线程是互不影响,并行执行,i 就是之后要提到的如何去确定每一个线程块内的线程索引,代表它在显存中的位置。当计算完毕之后呢,会设置一个时钟将这256个独立线程的结果进行同步,最终将这一个256位的向量加的这么一个操作,通过并行计算的方式,得到它最终的向量相加的结果。 |
|---|---|
网格(grid): 并行线程块组合
CUDA 核函数由线程网格(数组)执行
- 每个线程都有一个索引,用于计算内存地址和做出控制决策
网格,其实就是线程块的组合体,也有如下三个特点:
- 网格内的这些线程块彼此是互相独立并不影响的;
- 网格内的全局内存是可以由该网格内的所有线程块来去进行访问;
- 用一个公有的时钟来去同步网格内所有的线程块。
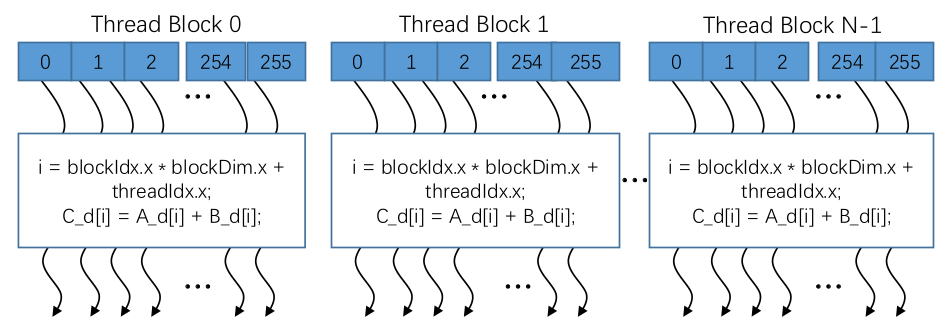
上图由N个线程块组合成了一个大的网格。这N个线程块之间呢是彼此独立互不影响的。在运算过程中的每一个线程块的内部计算各个线程的一个索引,执行这个向量相加的操作。最后将结果进行同步,得到向量相加的结果。
线程块id&线程id
定位独立线程的门牌号
每个线程使用索引来决定要处理的数据
核函数是在设备端执行的函数。而这个内存模型非常关键的一点是内存和显存之间的一个互相拷贝。那当核函数调用到每一个线程里边的局部内存和寄存器内容的时候呢,需要确定的是这个每一个线程在显存中的位置。
之前提到CUDA的核函数是要在设备端去进行计算和处理的。那么在执行核函数的过程中呢,需要访问网格中每一个线程的寄存器和独立的内存。那么在这个过程中呢,需要确定每一个线程在显存上的这个位置。那么回顾一下在CPU上,是如何确定某个寄存器在内存中的地址?是通过索引的方式来去确定每一个寄存器在内存中的地址。
与之相类似的,在gpu中,也是通过这种索引的方式来去获取一个线程在显存中的位置。与cpu不同的是:由于由线程块以及网格的形式来去组织线程的。因此不止需要线程的索引,还需要知道线程块的索引,来确定线程的具体位置。
无论是线程块索引还是线程索引,都可以是一维、二维或者三维的。
blockIdx: 1D, 2D or 3DthreadIdx: 1D, 2D or 3D |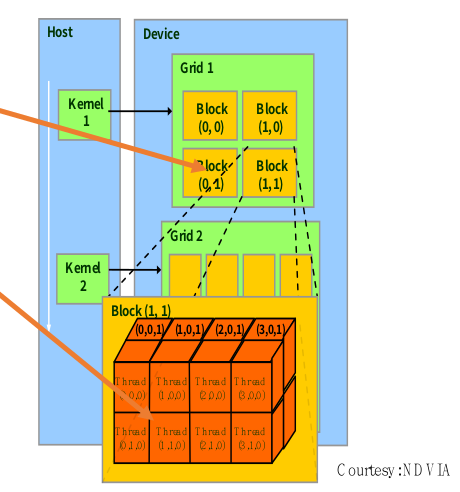 | 比如左图中的网格就是由一个2x2的线程块构成的。而这其中的每一个线程块都是由
| 比如左图中的网格就是由一个2x2的线程块构成的。而这其中的每一个线程块都是由 的线程构成的。也就是说线程块的索引是一个二维的索引;而线程的索引是一个三维的索引。 |
| —- | —- |
的线程构成的。也就是说线程块的索引是一个二维的索引;而线程的索引是一个三维的索引。 |
| —- | —- |
线程ID计算公式:
• dim3 dimGrid(M, N); // 线程块是二维的
• dim3 dimBlock(P, Q, S); // grid是三维的
threadId.x = blockIdx.x*blockDim.x+threadIdx.x;threadId.y = blockIdx.y*blockDim.y+threadIdx.y;
线程束( warp )
- SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。warp本质上是线程在GPU上运行的最小单元。
- 当一个kernel被执行时,gird中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
- 由于warp的大小为32,所以block所含的thread的大小一般要设置为32的倍数。

GPU结构示意图中有非常多的计算单元,同时有一个很小的控制单元。每一行的计算单元执行的控制指令是统一,由控制单元发出,这个就是一个非常典型的单指令多数据流机制。
也就是说他执行的指令只有1条,只不过不同的计算单元使用的数据是不一样的。这么一行(许多计算单元+一个控制单元)就称之为一个线程束。因此线程束是执行单指令多数据流最基本的单元。
通常,一个线程束包含32个并行的线程。也就是说一行包含32个计算单元(32个并行线程)。而这些线程使用不同的数据资源,执行相同的指令。因此可以说线程束本质上就是线程在gpu上运行的这么一个最小单元。也正是因为这个特点(线程束固定大小为32),在编程过程中,线程块包含的线程数的大小一般都设置为32的倍数。
每一个线程块是要包含整行的计算单元,不能是半行计算单元组成的线程块。
总结
上面就是gpu和cpu的一个这个基本的设计和基本特点,以及gpu中内存模型的基本概念。
我们这里简单的梳理回顾一下,我们从一个CUDA的基本概念,拓展基本概念的提出,然后引申出设备端、主机端以及核函数,然后引申出了内存模型。内存模型分为在硬件端和软件端解读:在硬件端是线程处理器,多核处理器以及设备端;然后再软件端对应的就是线程、线程块以及线程块组合体。
那么我们之后提到这个线程块和线程块组合体的三个基本特点:
- 内部的线程也好,线程块也好是独立的。
- 公有内存是可以被访问的,
- 用公有时钟进行同步
我们介绍了如何确定这个显存中每一个线程的具体的位置,如何计算它的索引。最后介绍了线程束的基本概念:它是执行GPU计算的最基本的单位。然后他的约束就是每一个线程块包含的线程需要是32的倍数。

若有收获,就点个赞吧
0 人点赞
