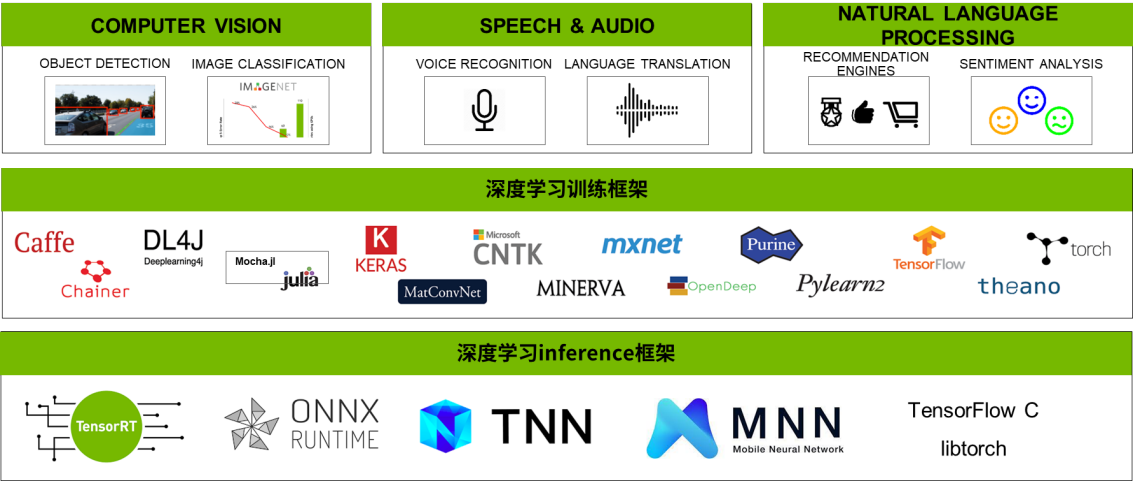
基础
- TensorRT是什么
- TensorRT工作流程介绍
- TensorRT优化策略介绍
- TensorRT的组成
- TensorRT基本使用流程
- TensorRT demo 代码-SampleMNIST 进阶
- Dynamic Shape模式介绍
- TensorRT模型转换
- TensorRT版本选择
 |
 |
|---|---|
TensorRT是什么
- 高性能深度学习推理优化器和加速库;
- 低延迟和高吞吐量;
-
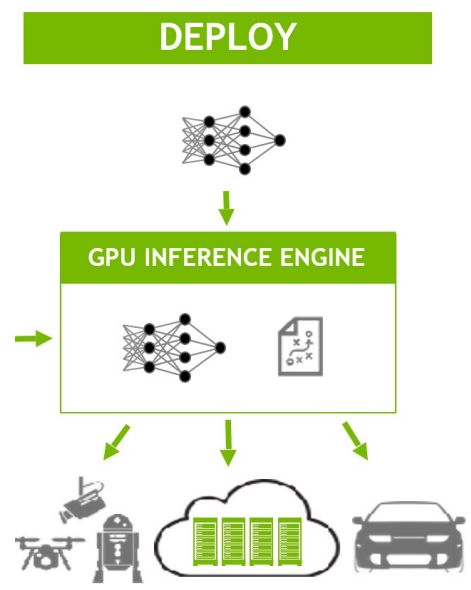
TensorRT工作流程介绍
保存好的TRT模型文件可以从磁盘重新加载到TRT执行引擎中,不需要再次执行优化步骤。
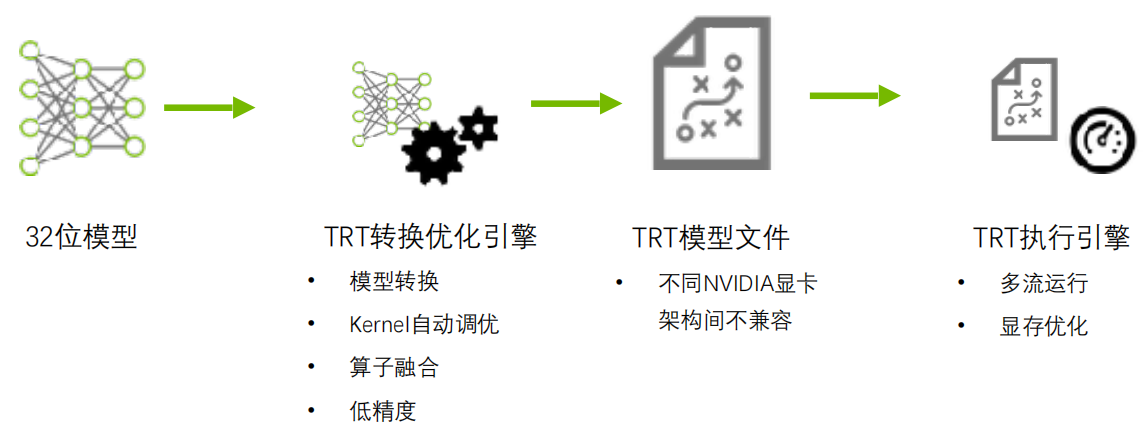
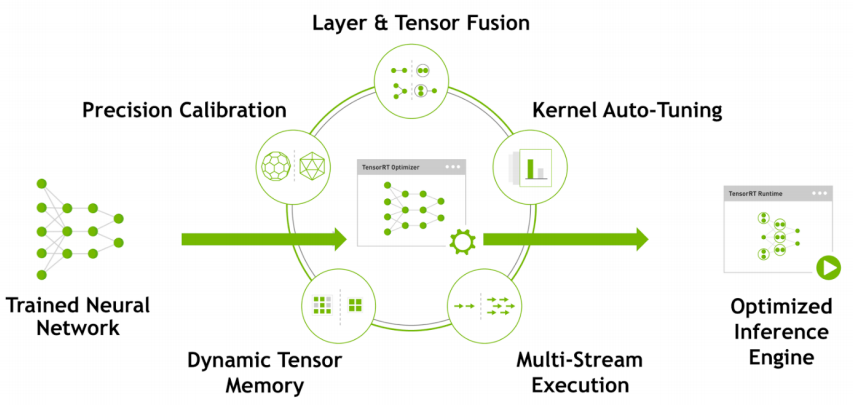
TensorRT优化策略介绍
低精度优化
- Kernel 自动调优:从多种实现中,选取性能最好的实现
- 算子融合
- 多流运行
- 显存优化
算子融合
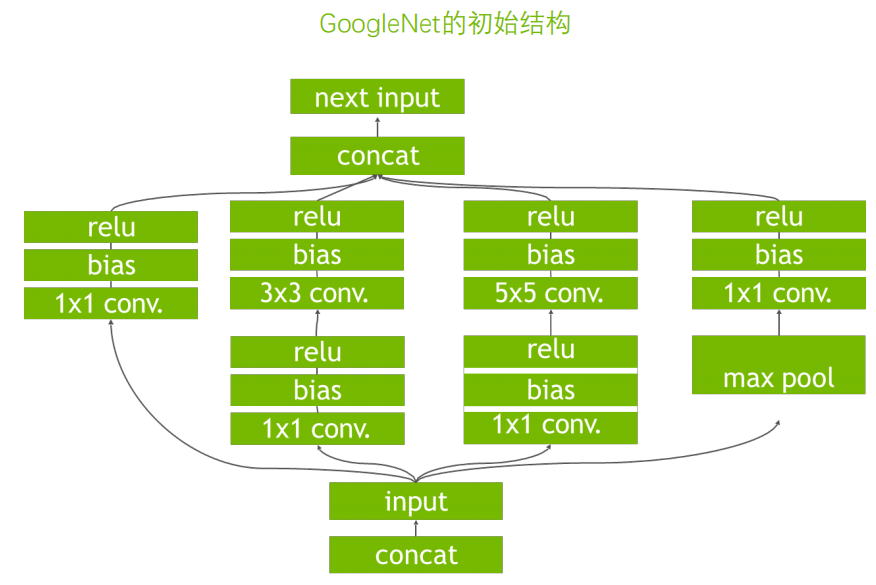 |
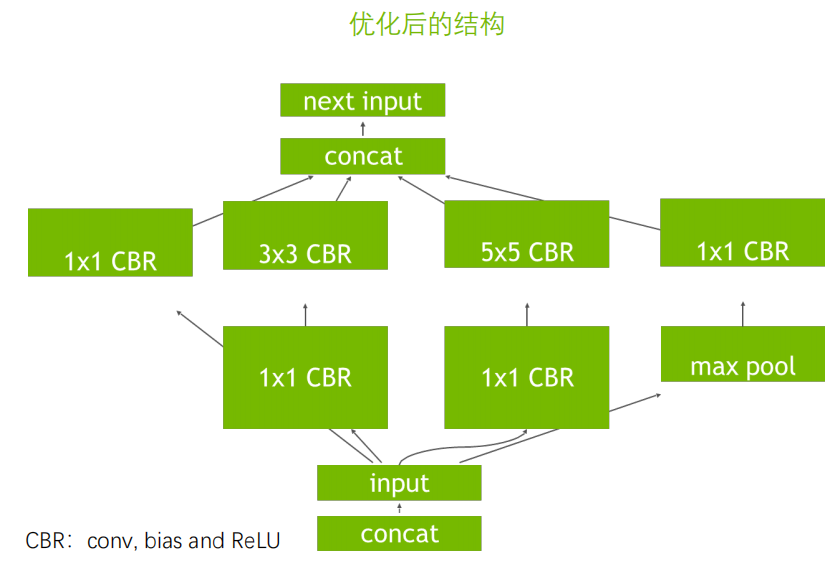 |
|---|---|
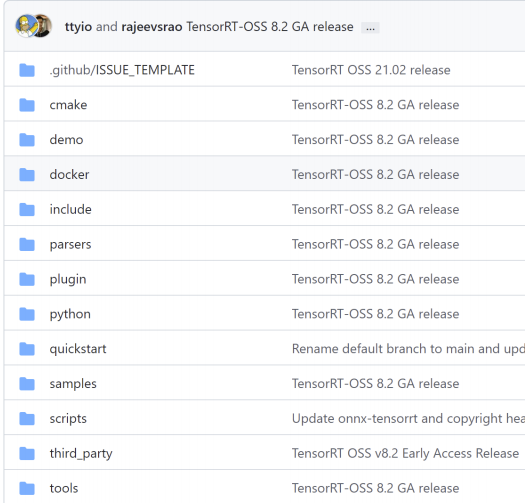
TensorRT的组成
https://github.com/NVIDIA/TensorRT
官方提供的库,闭源,是TRT的核心部分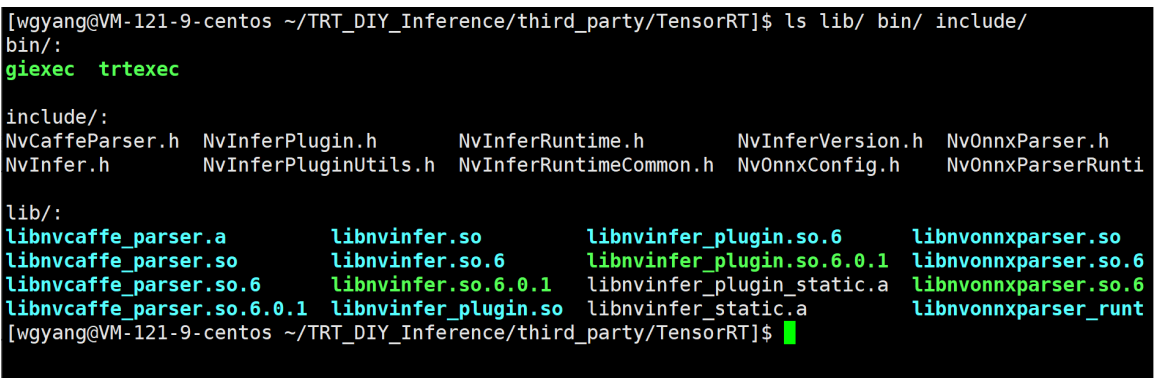
Github开源代码
- 模型解析器 parsers(caffe, onnx)- 代码样例 samples- Plugin样例 plugin |
 |
|---|---|
TensorRT基本使用流程
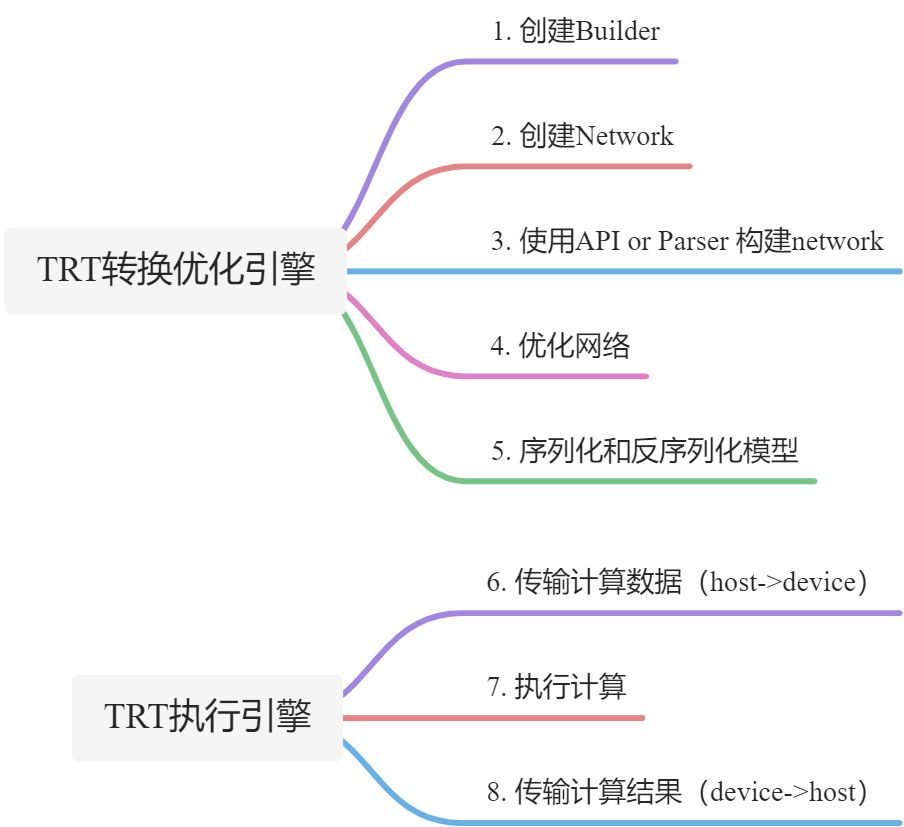
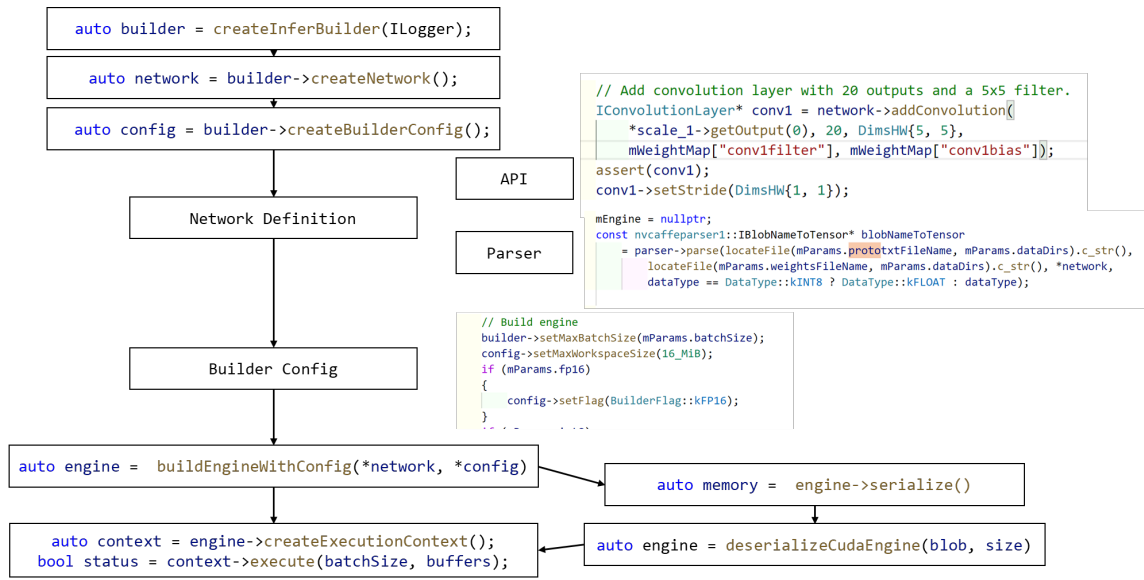
TensorRT demo 代码-SampleMNIST
build
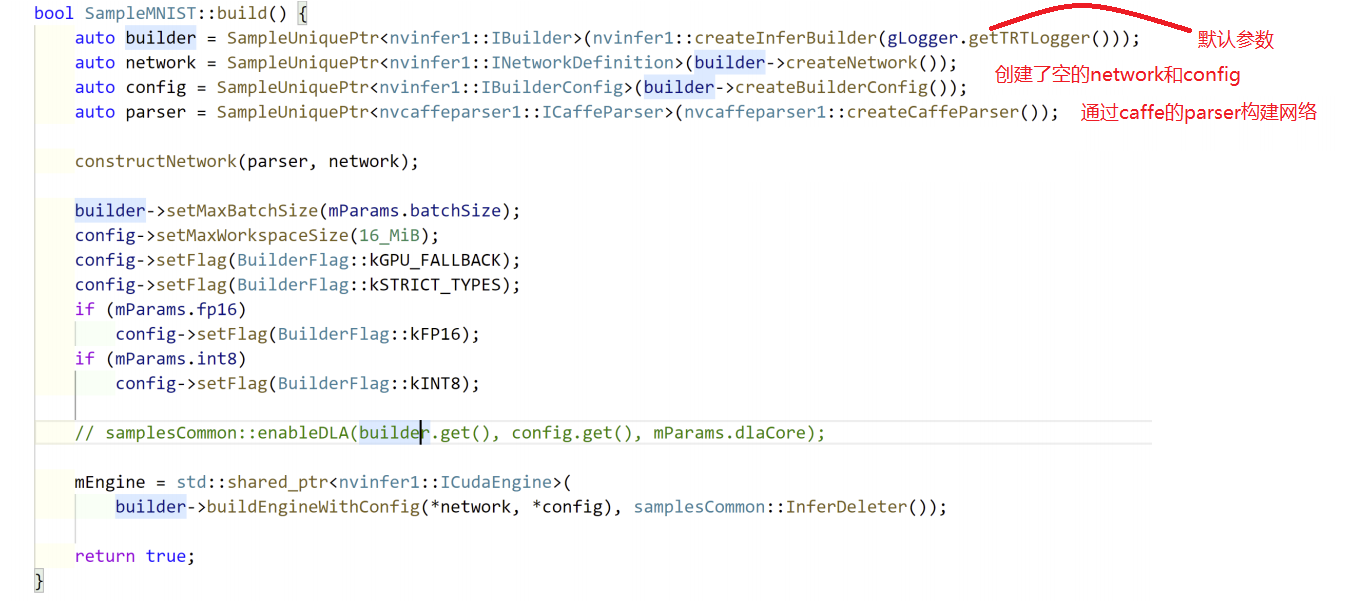
构建网络


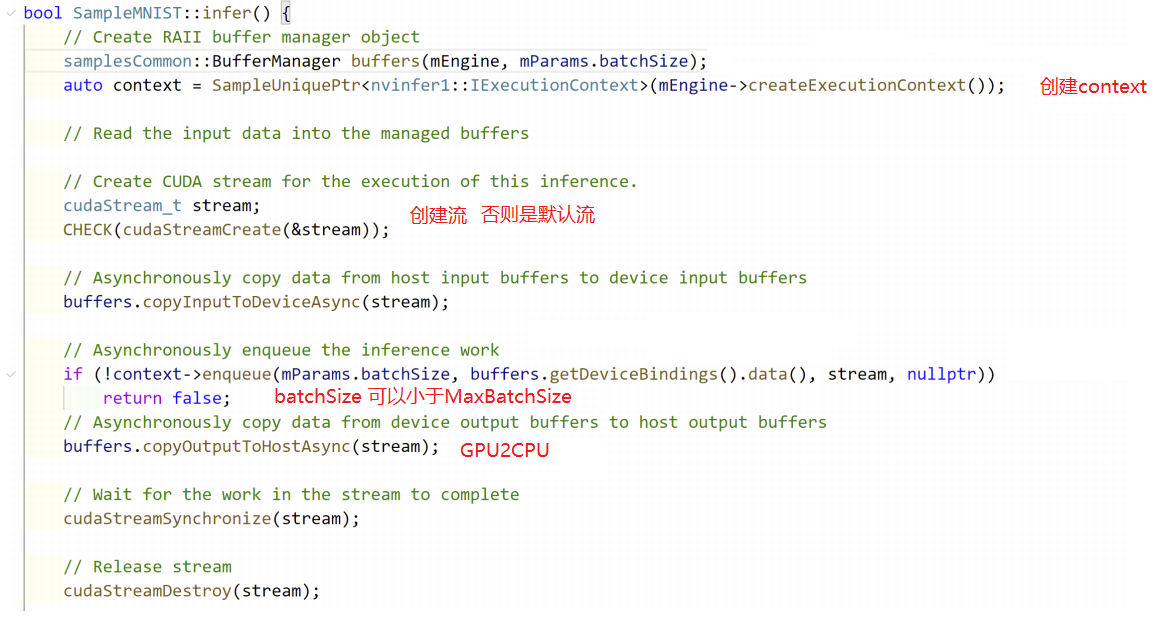
Infer阶段
Dynamic Shape模式介绍
implicit(隐式)batch
TRT 6.0 版本之前,只支持固定大小输入。
Build 阶段设置:
IBuilder:: createNetwork();IBuilder:: setMaxBatchSize(maxBatchSize);
Infer阶段:
enqueue(batchSize, data, stream, nullptr);
explicit(显式) batch
TRT6.0 后,支持动态大小输入。
Build 阶段设置:
IBuilder::createNetworkV2(1U << static_cast<int>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH))builder->setMaxBatchSize(maxBatchSize);// 增加了profileIOptimizationProfile* profile = builder.createOptimizationProfile();profile->setDimensions("foo", OptProfileSelector::kMIN, Dims3(3,100,200); // 输入的最小维度profile->setDimensions("foo", OptProfileSelector::kOPT, Dims3(3,150,250); // 输入的最合适维度profile->setDimensions("foo", OptProfileSelector::kMAX, Dims3(3,200,300); // 输入的最大维度config.addOptimizationProfile(profile);context.setOptimizationProfile(0);
Infer阶段:
在真正的推理之前,要告诉context的输入是多大
context->setBindingDimensions(i, input_dim);context->allInputDimensionsSpecified();context->enqueueV2(data, stream, nullptr);
TensorRT模型转换
ONNX :https://github.com/NVIDIA/TensorRT/tree/main/parsers
Pytorch:https://github.com/NVIDIA-AI-IOT/torch2trt
TensorFlow:https://github.com/tensorflow/tensorflow/tree/1cca70b80504474402215d2a4e55bc44621
Tencent Forward:https://github.com/Tencent/Forward
TensorRT版本选择
TensorRT5.1 不建议使用,也不建议用最新
cuda的版本跟随硬件走,NVIDIA 发布新硬件,就会发布新的CUDA版本,从而适配新硬件。有可能对老硬件进行负优化的。
对于我来说,新版会添加很多新功能,不用最新,也会用比较新的版本。YYDS。所以选择版本时,可以根据硬件发布时间来选择。
Tesla P4 6.0Tesla T4 7.2NVIDIA A10 8.2

若有收获,就点个赞吧
0 人点赞
