第一部分 事务
事务概念
是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行
开始于
-
结束于
结束于 commit提交,rollback回滚,ddl,正常执行,异常执行
特性
特性:原子性、一致性、隔离性、持久性。
原子性:一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做
- 一致性:事务必须是数据库从一个一致性状态变到另一个一致性状态,一致性与原子性是密切相关的
- 隔离性:一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据,对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰
持久性:持久性也称永久性,指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,接下来的其他操作或故障不应该对其有任何影响
事务控制
使用COMMIT和ROLLBACK实现事务控制
- COMMIT:提交事务,即把事务中对数据库的修改进行永久保存
- ROLLBACK:回滚事务,即取消对数据库所做的增删改
使用AUTOCOMMIT实现事务的自动提交
- 设置AUTOCOMMIT为ON
SQL>set autocommit on示例
新建一个表,
打开两个sql窗口create table dept( -- 部门表dept_no number NOT NULL primary key, -- 部门编号dept_name varchar2(50) NOT NULL -- 部门名称)
在窗口1中执行
在窗口2中执行insert into dept values(1,'销售部'); -- 插入1行数据select count(1) from dept; -- 结果是1
在窗口1中执行select count(1) from dept; -- 结果是0
在窗口2中执行commit; -- 提交事务select count(1) from dept; -- 结果是1
在窗口1中执行select count(1) from dept; -- 结果是1
在窗口2中执行delete from dept where dept_no=1; -- 删除1行数据select count(1) from dept; -- 结果是0
在窗口1中执行select count(1) from dept; -- 结果是1
在窗口2中执行rollback; -- 回滚事务select count(1) from dept; -- 结果是1
select count(1) from dept; -- 结果是1
第二部分 索引
数据库对象
Oracle 数据库对象又称模式对象
- 数据库对象是逻辑结构的集合,最基本的数据库对象是表
- 其他数据库对象包括:
-
索引概念
索引是为了对表中数据行的检索而创建的一种分散的存储结构。
在逻辑上和物理上都独立于表的数据 Oracle 自动维护索引

索引作用


反向键索引
create index emp_empno_reverse_idx on emp(empno) reverse;
说明:emp_empno_reverse_idx是索引名,emp是表名,empno 是列名

位图索引
create bitmap index emp_job_bit_idx on emp(job);
说明:emp_job_bit_idx是索引名,emp是表名,job是列名 位图索引适合创建在低基数列上


唯一索引
- 确保在定义索引的列中没有重复值
- Oracle 自动在表的主键列上创建唯一索引
- 使用CREATE UNIQUE INDEX语句创建唯一索引
SQL> create unique index 索引名 on 表名(列名);
基于函数的索引
- 需要创建的索引需要使用表中一列或多列的函数或表达式
语法:create index 索引名 on 表名 (函数);
示例:SQL> create index emp_ename_upper_idx on tablename (upper(columnname));
索引管理
创建标准索引
SQL> create index 索引名 on 表名(列名)tablespace 表空间名;
维护索引
合并索引碎片
重建索引
删除索引
与索引有关的数据字典视图有
- USER_INDEXES - 用户创建的索引的信息
USER_IND_COLUMNS - 与索引相关的表列的信息
示例:
-- 查询与索引相关的表列信息:select index_name, table_name, column_namefrom user_ind_columnsorder by index_name, column_position;
第三部分 视图
概念
视图是一个虚拟表,以定制的方式显示一个表或者多个表的数据
视图可以视为“虚拟表”或“存储的查询” 创建视图所依据的表称为“基表”
优点
create [or replace] [force|noforce] view视图名 [(alias[, alias]...)]as 查询语句[with check option][with read only];
语法解析:
- OR REPLACE:如果视图已经存在,则替换旧视图
- FORCE:即使基表不存在,也可以创建该视图,但是该视图不能正常使用,当基表创建成功后,视图才能正常使用
- NOFORCE:如果基表不存在,无法创建视图,该项是默认选项
- alias:为视图产生的列定义的别名
- WITH CHECK OPTION :插入或修改的数据行必须满足视图定义的约束;如果创建的视图中带有where等条件,则with check option 子句可以保证让你只能在视图的条件之内对视图进行DML
WITH READ ONLY:默认可以通过视图对基表执行增删改操作,但是有很多在基表上的限制 比如:
基表中某列不能为空, 但是该列没有出现在视图中,则不能通过视图执行insert操作<br /> WITH READ ONLY说明视图是只读视图,不能通过该视图进行增删改操作<br /> 现实开发中,基本上不通过视图对表中的数据进行增删改操作<br />示例:
-- 建表create table emp(empno number primary key,emp_name varchar2(50) not null,sex char(2) not null)
```sql — 插入数据 insert into emp values(1,’Mary’,’f’); insert into emp values(2,’Job’,’m’); insert into emp values(3,’Lily’,’f’ );
—创建视图 create view vw_emp2 as select emp_name,empno from emp where empno>=2;
—通过视图查询数据 select from vw_emp2; —通过视图插入数据 2可以删掉,如果写empno=1不能删除 delete from vw_emp2 where empno=2; —查询基表中的数据 select from emp ;
<a name="WYG33"></a>## 删除视图`drop view 视图名;`<a name="xUpbp"></a>## 视图分类<a name="ytzcE"></a>### 简单视图- 是基于单个基表,不包括函数和分组函数的视图- 可以对此视图中执行DML语句<a name="ZexUi"></a>### 复杂视图- 从多个表提取数据,包括函数和分组函数的视图- 复杂视图不一定能进行DML操作<a name="t1MQ7"></a>### 物化视图【了解】- 就是具有物理存储的特殊视图,占据物理空间,就像表一样。- 是远程数据的本地副本,或者用来生成基于数据表求和的汇总表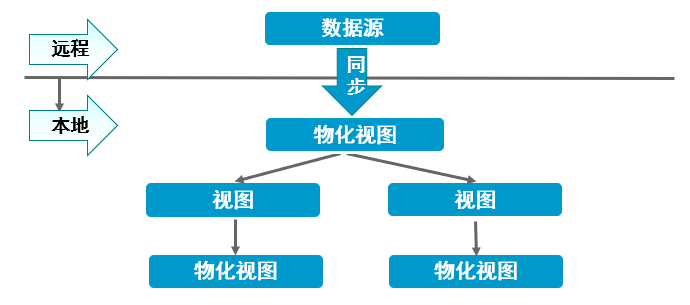<br />物化视图中有两个重要概念<a name="yqWdD"></a>#### 查询重写:- 对SQL语句进行重写- 当用户使用SQL语句对基表进行查询时,如果已经建立了基于这些基表的物化视图,Oracle将自动计算和使用- 物化视图来完成查询- 创建物化视图时需要使用 ENABLE QUERY REWRITE来启动查询重写功能<a name="Jqmnf"></a>#### 物化视图的同步- 当基表变化时,需要同步数据以更新物化视图中的数据- Oracle提供了两种物化视图的刷新方式,即ON COMMIT方式和ON DEMAND方式<a name="SiWSq"></a>#### 创建物化视图步骤1. 授予权限。创建物化视图的权限、QUERY REWRITE的权限,以及对创建物化视图所涉及的表的访问权限和创建表的权限```sql-- 授予用户创建物化视图的权限grant create any materialized view to username;-- 授予用户查询任意表的权限grant select any table to username;-- 如果要创建refresh on commit的视图,那么还需要下面这个权限:grant on commit refresh to username;
- 创建物化视图日志
create materialized view log on 表名 with rowid;
- 创建物化视图
create materialized view 视图名 build immediate /*立即执行*/ refresh fast /*快速更新*/ on commit /*基表提交数据时更新物化视图*/ enable query rewrite /*启动查询重写*/ as 查询语句删除物化视图
drop materialized view 视图名;第四部分 分区表
概念
- 允许用户将一个表分成多个分区
- 将不同的分区存储在不同的磁盘,提高访问性能和安全性
- 可以独立地备份和恢复每个分区
- 用户可以执行查询,只访问表中的特定分区

分区表优点
- 改善表的查询性能
- 表更容易管理
- 便于备份和恢复
-
分区表的条件
数据量大于2GB
- 已有的数据和新添加的数据有明显的界限划分
创建分区表
语法 ```sql create table 表名(列名 数据类型 特征,…) partition by range (列名) ( partition 分区1 values less than (值1) [tablespace 表空间1] , partition 分区2 values less than (值2) [tablespace 表空间2] , … partition 分区n values less than (maxvalue ) [tablespace tablespace 表空间n] );
示例
```sql
create table sales2 (
sales_id number,
product_id varchar2(5),
sales_date date not null
)
partition by range(sales_date)
(
partition p1 values less than (to_date('2013-04-1', 'yyyy-mm-dd')) tablespace fenquts1,
partition p2 values less than (to_date('2013-07-1', 'yyyy-mm-dd')) tablespace fenquts2,
……
partition p5 values less than (maxvalue) tablespace fenqutsn
);
操纵已分区的表
1.在已分区的表中插入数据与操作普通表完全相同, Oracle会自动将数据保存到对应的分区
插入
insert into sales2 values (1,‘p001’, ’02-3月-2013’);
insert into sales2 values (2,‘p002’, ’10-5月-2013’);
insert into sales2 values (3,‘p003’, ’05-7月-2013’);
insert into sales2 values (4,‘p004’, ’12-9月-2013’);
2.查询、修改和删除分区表时可以显式指定要操作的分区 , 也可以正常操作
select * from sales2 partition (p1);
delete from sales2 partition (p2);
update sales sales2 partition(p1) set product_id=800;
查看分区情况
select * from user_tab_partitions;

若有收获,就点个赞吧
0 人点赞
