一、基本原理和用途
主成分分析是一种降维算法,当研究问题涉及到多变量且变量之间存在很强的相关性时,我们可以使用主成分分析来对数据进行简化。
主要思路是通过较少的变量来尽可能地保留原来变量所反映的信息。
主成分分析的主要用途有两个:
1、用于聚类。对降维后的数据进行聚类方便可视化。
2、用主成分回归可以解决多重共线性。逐步回归也可以解决多重共线性,但在合适的数据上用主成分回归保留的信息量大于逐步回归。
二、基本思路
主要思路是列出样本和指标的矩阵后求出其相关系数矩阵,再在相关系数矩阵的基础上求特征值和特征向量,最后根据特征值贡献度构建新的变量。



对于第6步:
主成分前的系数可以称为载荷,根据载荷的正负和大小我们可以分析每个主成分的实际意义。
主成分分析得出的新变量的意义具有模糊性(降维付出的代价),如果对于某一个主成分的实际意义解释失败,那么主成分分析就失败了。
三、具体代码(清风)
clear;clcload data1.mat % 主成分聚类% load data2.mat % 主成分回归% 注意,这里可以对数据先进行描述性统计% 描述性统计的内容见第5讲.相关系数[n,p] = size(x); % n是样本个数,p是指标个数%% 第一步:对数据x标准化为XX=zscore(x); % matlab内置的标准化函数(x-mean(x))/std(x)%% 第二步:计算样本协方差矩阵R = cov(X);%% 注意:以上两步可合并为下面一步:直接计算样本相关系数矩阵R = corrcoef(x);disp('样本相关系数矩阵为:')disp(R)%% 第三步:计算R的特征值和特征向量% 注意:R是半正定矩阵,所以其特征值不为负数% R同时是对称矩阵,Matlab计算对称矩阵时,会将特征值按照从小到大排列哦% eig函数的详解见第一讲层次分析法的视频[V,D] = eig(R); % V 特征向量矩阵 D 特征值构成的对角矩阵%% 第四步:计算主成分贡献率和累计贡献率lambda = diag(D); % diag函数用于得到一个矩阵的主对角线元素值(返回的是列向量)lambda = lambda(end:-1:1); % 因为lambda向量是从小大到排序的,我们将其调个头contribution_rate = lambda / sum(lambda); % 计算贡献率cum_contribution_rate = cumsum(lambda)/ sum(lambda); % 计算累计贡献率 cumsum是求累加值的函数disp('特征值为:')disp(lambda') % 转置为行向量,方便展示disp('贡献率为:')disp(contribution_rate')disp('累计贡献率为:')disp(cum_contribution_rate')disp('与特征值对应的特征向量矩阵为:')% 注意:这里的特征向量要和特征值一一对应,之前特征值相当于颠倒过来了,因此特征向量的各列需要颠倒过来% rot90函数可以使一个矩阵逆时针旋转90度,然后再转置,就可以实现将矩阵的列颠倒的效果V=rot90(V)';disp(V)%% 计算我们所需要的主成分的值m =input('请输入需要保存的主成分的个数: ');F = zeros(n,m); %初始化保存主成分的矩阵(每一列是一个主成分)for i = 1:mai = V(:,i)'; % 将第i个特征向量取出,并转置为行向量Ai = repmat(ai,n,1); % 将这个行向量重复n次,构成一个n*p的矩阵F(:, i) = sum(Ai .* X, 2); % 注意,对标准化的数据求了权重后要计算每一行的和end%% (1)主成分聚类 : 将主成分指标所在的F矩阵复制到Excel表格,然后再用Spss进行聚类% 在Excel第一行输入指标名称(F1,F2, ..., Fm)% 双击Matlab工作区的F,进入变量编辑中,然后复制里面的数据到Excel表格% 导出数据之后,我们后续的分析就可以在Spss中进行。%%(2)主成分回归:将x使用主成分得到主成分指标,并将y标准化,接着导出到Excel,然后再使用Stata回归% Y = zscore(y); % 一定要将y进行标准化哦~% 在Excel第一行输入指标名称(Y,F1, F2, ..., Fm)% 分别双击Matlab工作区的Y和F,进入变量编辑中,然后复制里面的数据到Excel表格% 导出数据之后,我们后续的分析就可以在Stata中进行。% % 注意:代码文件仅供参考,一定不要直接用于自己的数模论文中% % 国赛对于论文的查重要求非常严格,代码雷同也算作抄袭% % 关注我的微信公众号《数学建模学习交流》,后台发送“软件”两个字,可获得常见的建模软件下载方法;发送“数据”两个字,可获得建模数据的获取方法;发送“画图”两个字,可获得数学建模中常见的画图方法。另外,也可以看看公众号的历史文章,里面发布的都是对大家有帮助的技巧。% % 如何修改代码避免查重的方法:https://www.bilibili.com/video/av59423231(必看)
四、主成分分析在论文中的运用


五、综合评价函数的缺点

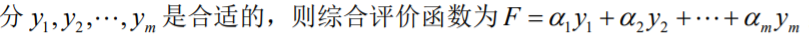
综合评价函数的问题包括:
1、信息量的减少
2、实际含义难以解释
3、对主成分在变异信息上优势的瓦解
4、第一主成分的影响过大
5、各主成分方差不同,不能使用权数a
6、主成分只包含标准化,并无正向化

若有收获,就点个赞吧
0 人点赞
