题目描述

题目链接
https://leetcode.cn/problems/substring-with-concatenation-of-all-words/
思路
1. 暴力匹配
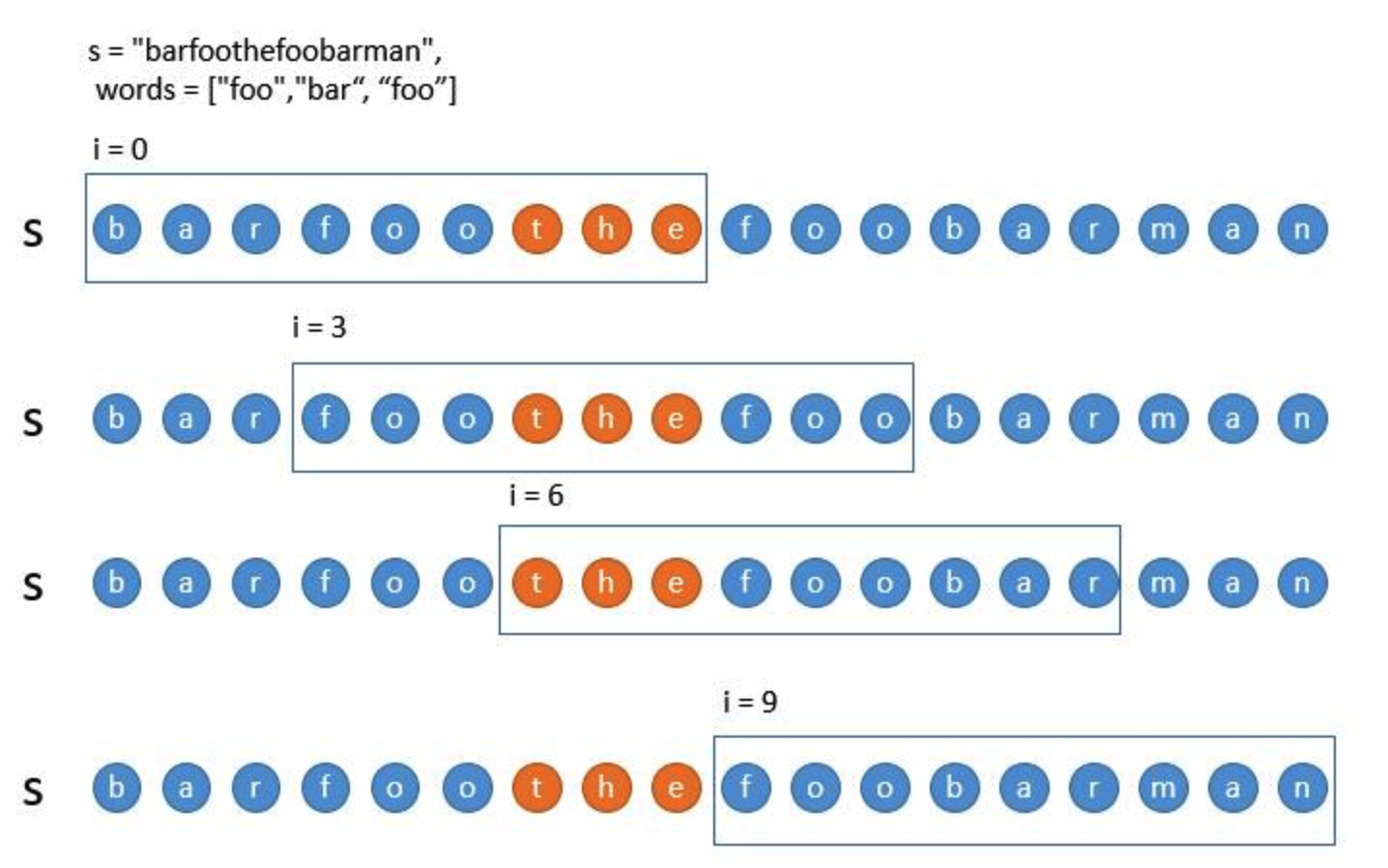
首先,最直接的思路,就是以字符串 的每个下标为子串的起始位置来暴力判断是否匹配
的每个下标为子串的起始位置来暴力判断是否匹配 数组中的所有单词,符合的就把下标保存起来,最后返回即可。
数组中的所有单词,符合的就把下标保存起来,最后返回即可。
如上图,利用循环变量 ,依次后移,判断每个子串是否完全匹配
,依次后移,判断每个子串是否完全匹配 中的所有单词即可。
中的所有单词即可。
那怎么判断子串是否匹配呢?由于不需要考虑 中单词串联的顺序,可以考虑利用哈希表来解决。首先,我们把
中单词串联的顺序,可以考虑利用哈希表来解决。首先,我们把 中的所有的单词添加到哈希表
中的所有的单词添加到哈希表 里,其中,键为单词,值为单词出现的个数(因为
里,其中,键为单词,值为单词出现的个数(因为 中的单词可能会有重复)。然后遍历子串,判断子串中的单词及单词出现的次数是否完全匹配
中的单词可能会有重复)。然后遍历子串,判断子串中的单词及单词出现的次数是否完全匹配 。如果遍历子串时发现有
。如果遍历子串时发现有 中不存在的单词,或者单词数量超过了
中不存在的单词,或者单词数量超过了 中记录的数量,则可以提前结束遍历。
中记录的数量,则可以提前结束遍历。
具体代码实现如下:
public static List<Integer> findSubstring(String s, String[] words) {List<Integer> res = new ArrayList<>();if (s == null || s.length() == 0 || words == null || words.length == 0) {return res;}int wordLen = words[0].length();int winSize = wordLen * words.length;// 将单词数组构建成哈希表Map<String, Integer> map = new HashMap<>();for (String word : words) {map.put(word, map.getOrDefault(word, 0) + 1);}// 遍历sfor (int i = 0; i <= s.length() - winSize; i++) {Map<String, Integer> tmp = new HashMap<>();int j = i, hit = 0;// 判断子串是否匹配while (j < i + winSize) {String word = s.substring(j, j + wordLen);j += wordLen;if (map.containsKey(word)) {int wordNum = tmp.getOrDefault(word, 0) + 1;if (map.get(word) < wordNum) {break;}tmp.put(word, wordNum);hit++;} else {break;}}// 判断是否完全匹配if (hit == words.length) {res.add(i);}}return res;}
- 时间复杂度:
 ,其中
,其中 为字符串
为字符串 的长度,
的长度, 为
为 中的单词数。
中的单词数。 - 空间复杂度:
 ,我们需要申请两个哈希表用来存储子串和
,我们需要申请两个哈希表用来存储子串和 中的单词。
中的单词。
2. 滑动窗口
记 中的单词数为
中的单词数为 ,
, 中每个单词的长度为
中每个单词的长度为 ,字符串
,字符串 的长度为
的长度为 。我们首先将
。我们首先将 划分为单词组,每个单词的大小均为
划分为单词组,每个单词的大小均为 (首尾除外)。这样的划分方法有
(首尾除外)。这样的划分方法有 种,即先删去前
种,即先删去前 个字母后,将剩下的字母进行划分,如果末尾有不到
个字母后,将剩下的字母进行划分,如果末尾有不到 个字母的单词也删去。之后,我们就可以对这
个字母的单词也删去。之后,我们就可以对这 种划分得到的单词数组分别使用滑动窗口对
种划分得到的单词数组分别使用滑动窗口对 进行搜索。
进行搜索。
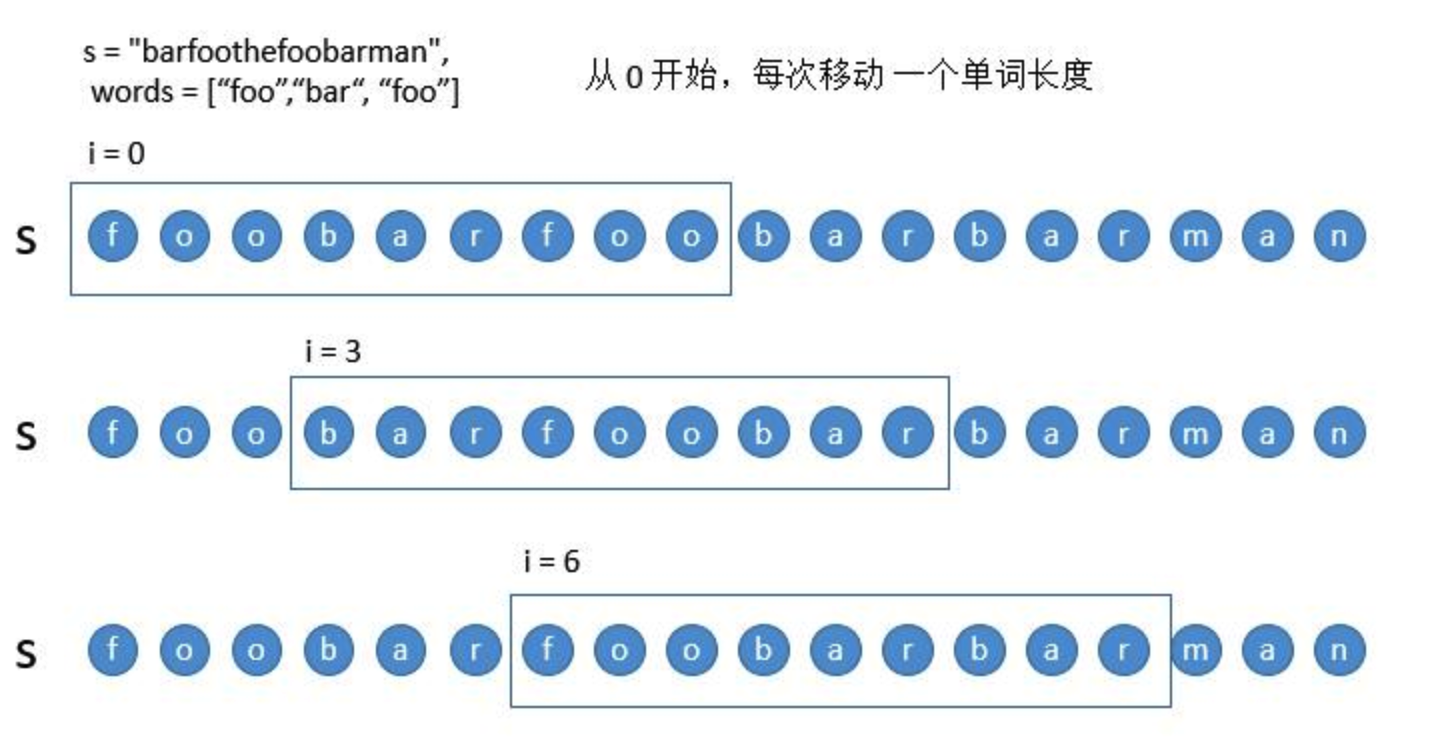
以下图为例,我们每次移动一个单词的长度,也就是 个字符,这样所有的移动被分成了三类。
个字符,这样所有的移动被分成了三类。
- 从 0 开始遍历
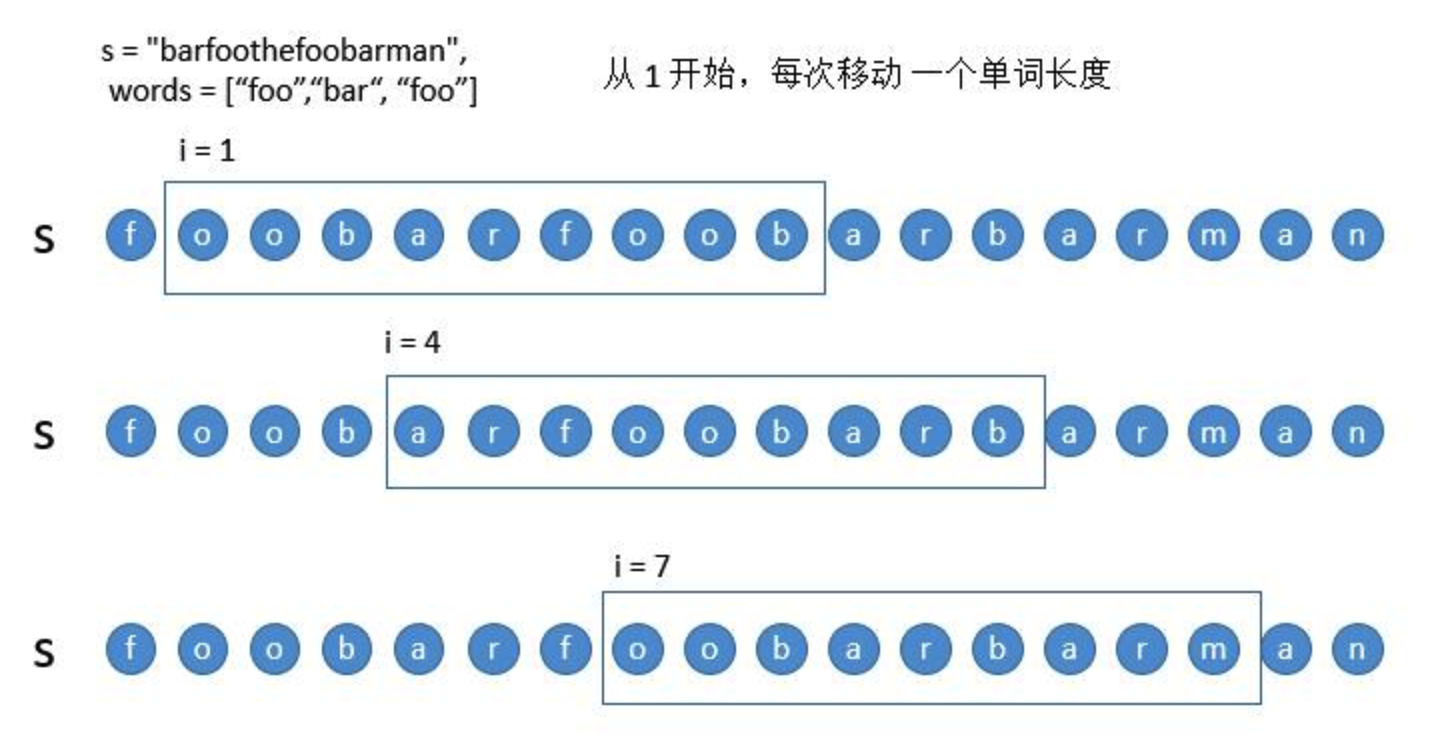
- 从 1 开始遍历
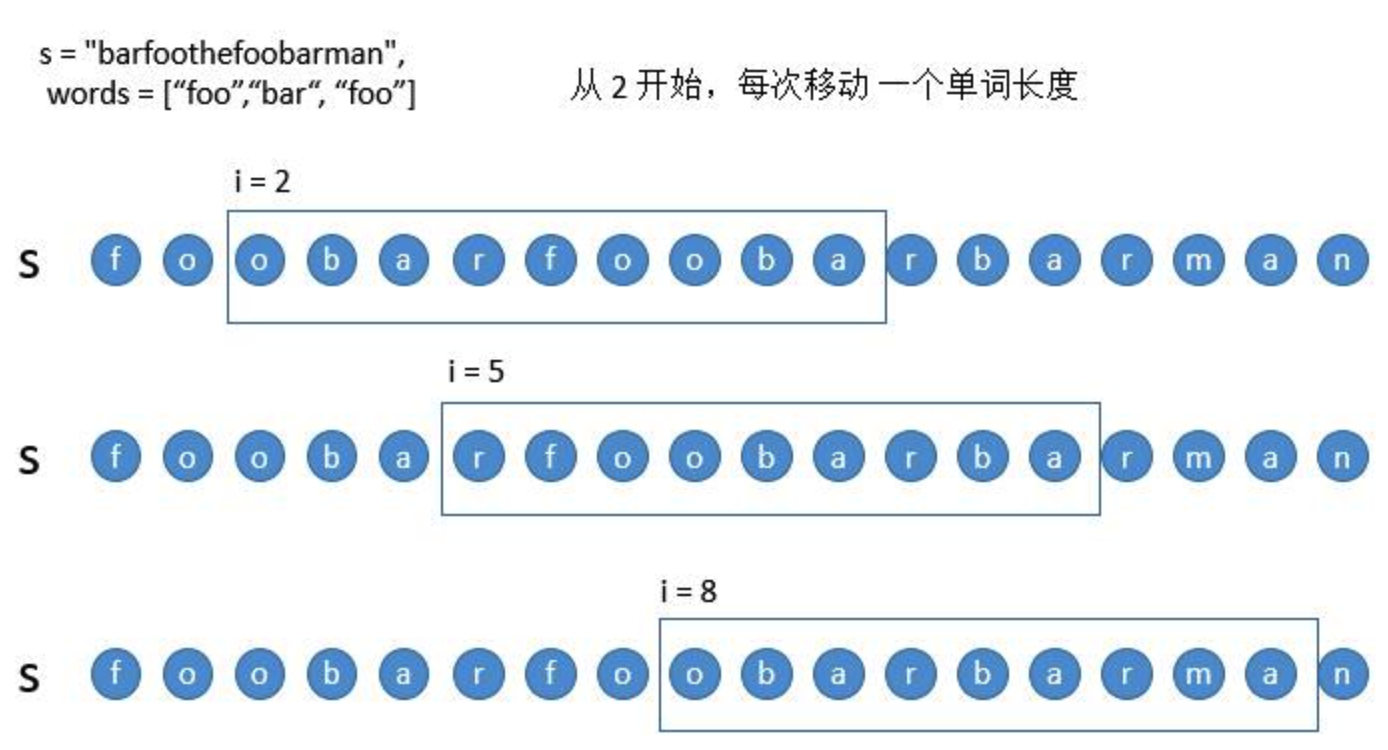
- 从 2 开始遍历
实际上,这种滑动窗口的思想还有可以优化的点,具体情况可分为以下三种:
情况一:当子串完全匹配,移动到下一个子串的时候。
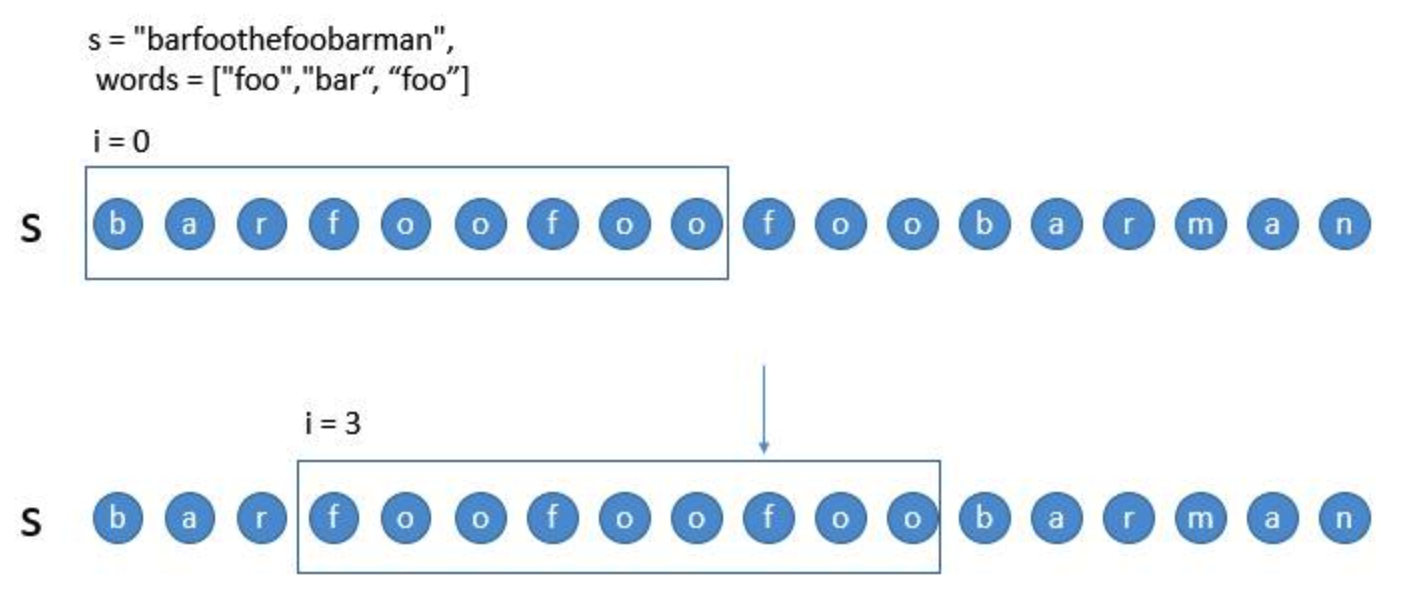
对于这种情况,当 从
从 移动到
移动到 时,由于前两个 foo 我们在第一次匹配的时候已经判断过了,所以我们只需要判断加上最后一个 foo 后是否还匹配。因此,我们就不必将哈希表
时,由于前两个 foo 我们在第一次匹配的时候已经判断过了,所以我们只需要判断加上最后一个 foo 后是否还匹配。因此,我们就不必将哈希表 清空从新开始填充,而是可以只移除之前
清空从新开始填充,而是可以只移除之前 子串的第一个单词 bar 即可,然后直接从箭头所指的 foo 开始匹配就可以了。
子串的第一个单词 bar 即可,然后直接从箭头所指的 foo 开始匹配就可以了。
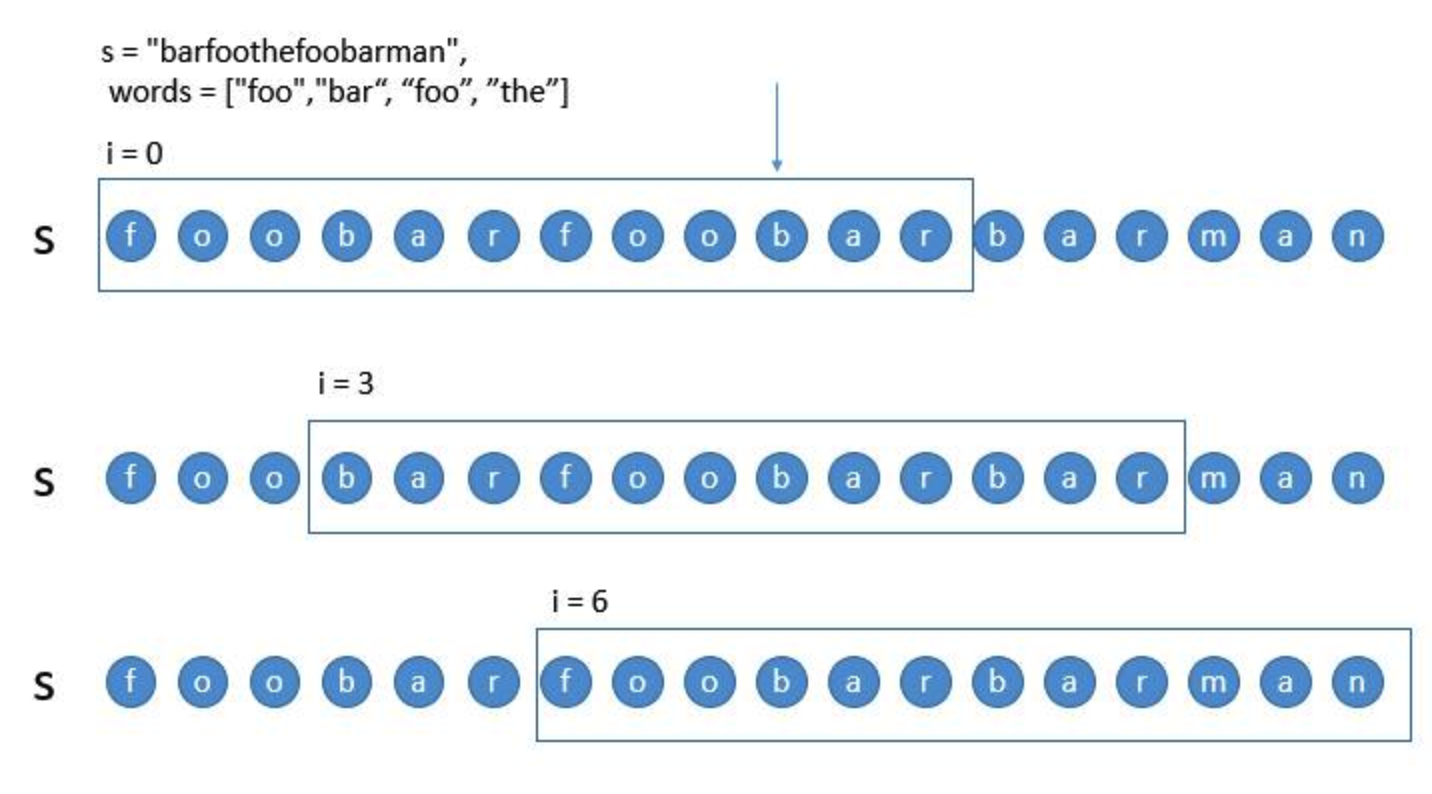
情况二:当判断过程中,出现不符合的单词。
在判断 的子串时,出现了一个并不在
的子串时,出现了一个并不在 中的单词 the,只要包含这个单词的子串肯定也是不能匹配的,所以此时
中的单词 the,只要包含这个单词的子串肯定也是不能匹配的,所以此时 的子串,我们就不需要判断了,可以直接从
的子串,我们就不需要判断了,可以直接从 继续匹配。
继续匹配。
情况三:判断过程中,出现的是符合的单词,但是次数超了。
对于 的子串,在判断第二个单词 bar 时,由于之前已经出现了一次 bar,所以
的子串,在判断第二个单词 bar 时,由于之前已经出现了一次 bar,所以 的子串是不符合要求的。继续往后移动窗口,当
的子串是不符合要求的。继续往后移动窗口,当 从
从 移动到
移动到 时将 foo 移除了,此时子串还是有两个 bar,所以该子串也一定是不符合的。继续往后移动,当之前的 bar 被移除后,此时
时将 foo 移除了,此时子串还是有两个 bar,所以该子串也一定是不符合的。继续往后移动,当之前的 bar 被移除后,此时 的子串,就可以接着按正常的方法判断了。
的子串,就可以接着按正常的方法判断了。
具体代码实现如下:
public static List<Integer> findSubstring(String s, String[] words) {List<Integer> res = new ArrayList<>();if (s == null || s.length() == 0 || words == null || words.length == 0) {return res;}int wordNum = words.length;int wordLen = words[0].length();// 将单词数组构建成哈希表Map<String, Integer> map = new HashMap<>();for (String word : words) {map.put(word, map.getOrDefault(word, 0) + 1);}// 这里只需遍历0~wordLen即可,因为滑动窗口都是按照wordLen的倍数进行滑动的for (int i = 0; i < wordLen; i++) {Map<String, Integer> tmp = new HashMap<>();// 滑动窗口int left = i, right = i, hit = 0;while (right + wordLen <= s.length()) {String word = s.substring(right, right + wordLen);right += wordLen;if (map.containsKey(word)) {int num = tmp.getOrDefault(word, 0) + 1;tmp.put(word, num);hit++;// 出现情况三,遇到了符合的单词,但是次数超了if (map.get(word) < num) {// 从left开始移除单词,直到次数符合while (map.get(word) < tmp.get(word)) {String deleteWord = s.substring(left, left + wordLen);tmp.put(deleteWord, tmp.get(deleteWord) - 1);left += wordLen;hit--;}}} else {// 出现情况二,遇到了不匹配的单词,直接将 left 移动到该单词的后边tmp.clear();hit = 0;left = right;}if (hit == wordNum) {res.add(left);// 出现情况一,子串完全匹配,我们将上一个子串的第一个单词从tmp中移除,窗口后移wordLenString firstWord = s.substring(left, left + wordLen);tmp.put(firstWord, tmp.get(firstWord) - 1);hit--;left = left + wordLen;}}}return res;}
- 时间复杂度:
 ,其中
,其中 为字符串
为字符串 的长度。
的长度。 - 空间复杂度:
 ,我们需要申请两个哈希表用来存储子串和
,我们需要申请两个哈希表用来存储子串和 中的单词。
中的单词。

若有收获,就点个赞吧
0 人点赞
