堆排序是一种原地的、时间复杂度为 O(nlogn) 的排序算法。这种排序方法的时间复杂度非常稳定,那么它是怎么做到的呢?一般我们把堆排序的过程大致分解成两个大的步骤:建堆和排序。
堆排序实现
1. 建堆
我们首先将数组原地建成一个堆。所谓原地就是不借助另一个数组而直接在原数组上操作。建堆的过程有两种思路:
从前往后插入
第一种是利用在堆中插入一个元素的思路。尽管数组中包含 n 个数据,但我们可以假设最开始堆中只包含一个数据,就是下标为 1 的数据。然后通过从下往上堆化来插入操作,将下标从 2 到 n 的数据依次插入到堆中。这样就组织成了堆。
从后往前插入(推荐)
第一种建堆思路是从前往后处理数组数据,而第二种建堆思路是从后往前处理数组,并且每个数据都是从上往下堆化。如图所示,因为叶子节点往下堆化只能自己跟自己比较,所以我们直接从第一个非叶子节点开始,依次堆化就行了。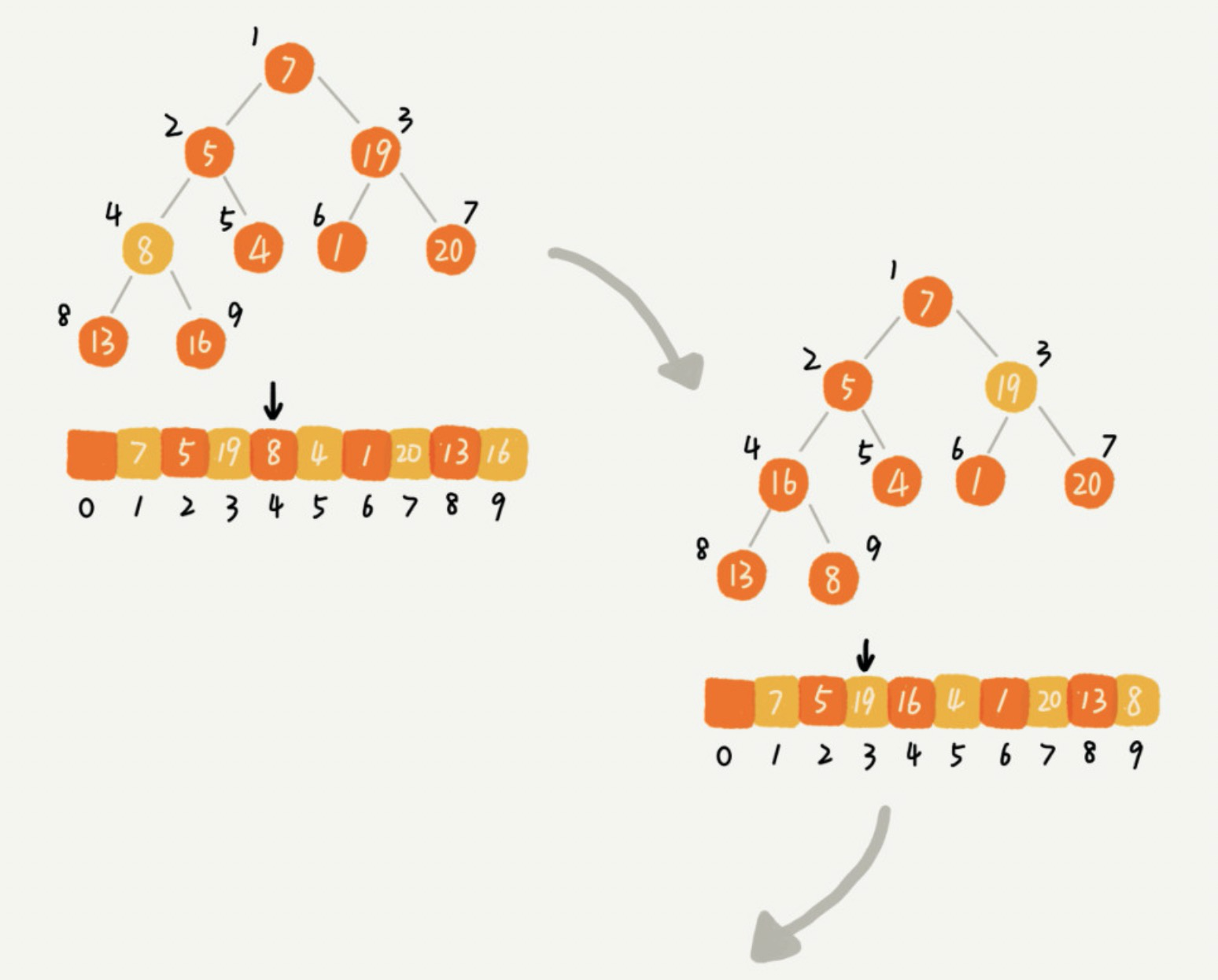
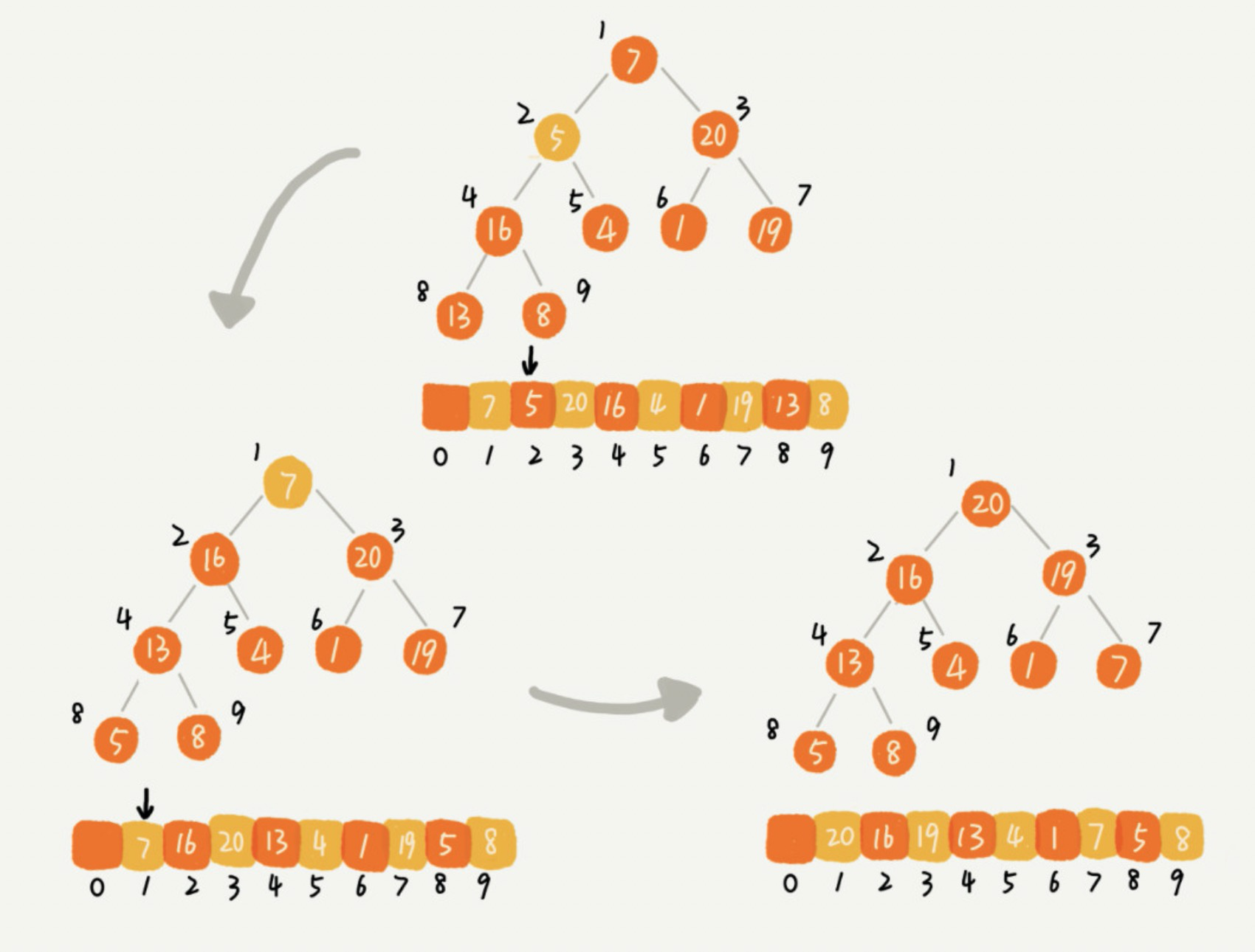
从图中看到,我们对下标从 n/2 开始到 1 的数据进行堆的,因为下标是 n/2+1 到 n 的节点都是叶子节点,我们不需要堆化。实际上,对于完全二叉树来说,下标从 n/2+1 到 n 的节点都是叶子节点。这种方式相比第一种思路的优点在于:它只需要对 n/2 个元素进行堆化,叶子节点会随着倒数第二层的堆化过程进行排序,而不需要对全部 n 个元素进行堆化。
代码实现
/*** 建堆,这里是从array[1]开始建堆的,真正的排序需要从array[0]开始,这里是为了方便展示堆化的过程*/private static void buildHeap(int[] array) {// 这里array.length需要减1,表示从非子节点处开始构建。i>0表示array[0]的元素不会构建到堆中for (int i = (array.length - 1) / 2; i > 0; i--) {heapify(array, i, array.length);}}/*** 从上到下的堆化** @param index 要进行堆化的下标索引* @param size 堆占用的数组大小*/private static void heapify(int[] array, int index, int size) {while (true) {int maxIndex = index;if (index * 2 <= size && array[index * 2] > array[index]) {maxIndex = index * 2;}if (index * 2 + 1 <= size && array[index * 2 + 1] > array[maxIndex]) {maxIndex = index * 2 + 1;}if (maxIndex == index) {break;}int temp = array[index];array[index] = array[maxIndex];array[maxIndex] = temp;index = maxIndex;}}
建堆操作的时间复杂度
因为叶子节点不需要堆化,所以需要堆化的节点从倒数第二层开始。每个节点堆化时需要比较和交换的节点个数,跟这个节点的高度 k 成正比。因此,我们只需要将每个节点的高度求和,得出的就是建堆的时间复杂度。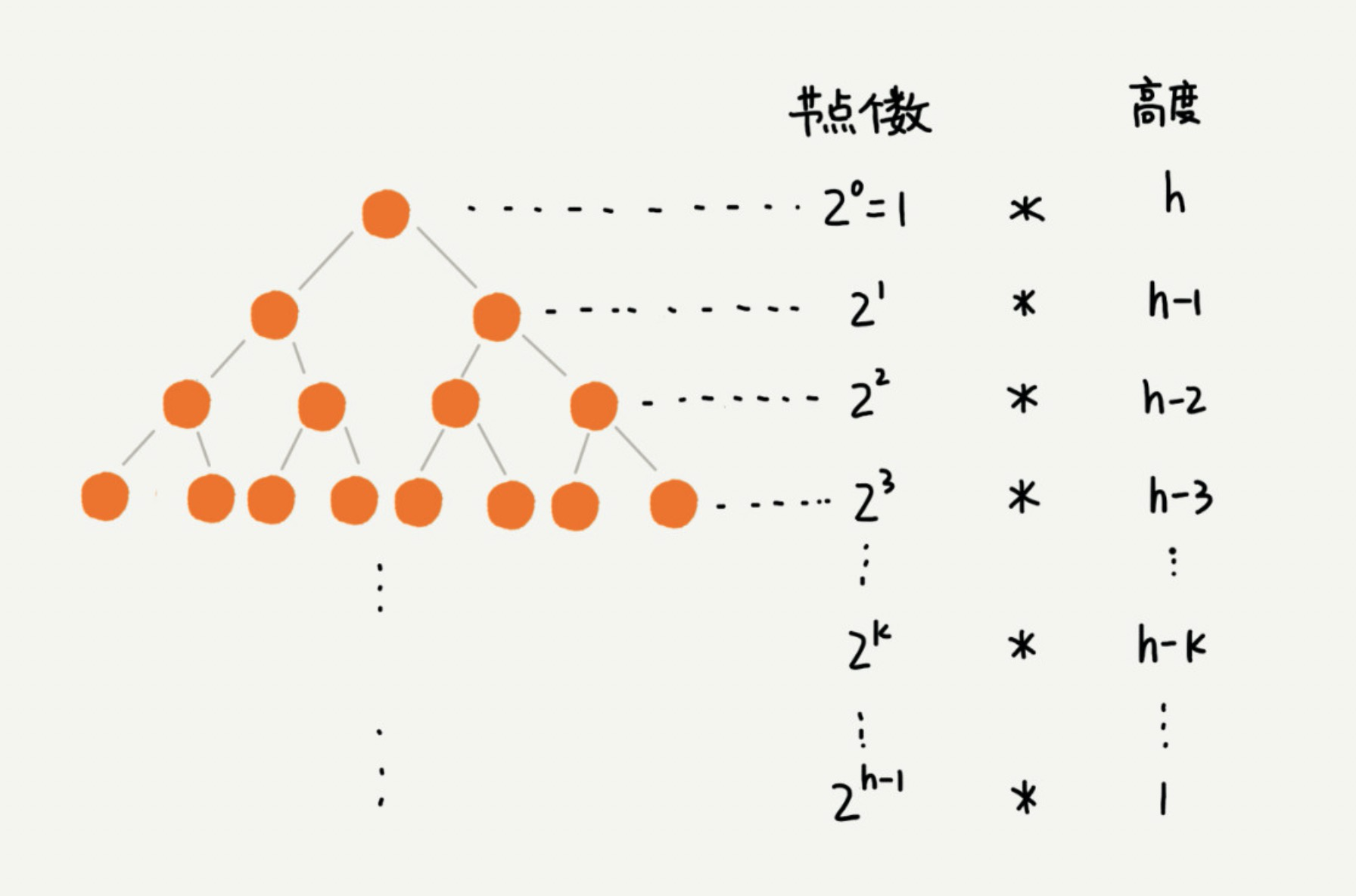
我们将每个非叶子节点的高度求和,就是下面这个公式: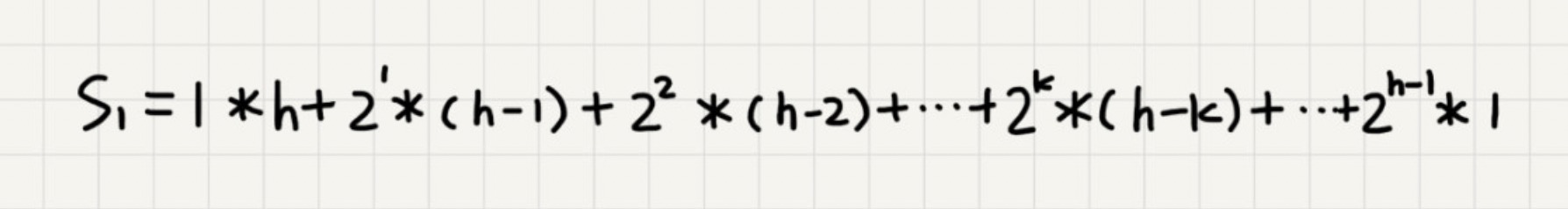
因为 h=log2n,代入公式 S 并求解,就能得到 S=O(n),所以,建堆的时间复杂度就是 O(n)。
2. 排序
建堆结束后,数组中的数据已经是按照大顶堆的特性来组织的了。数组中的第一个元素就是最大的元素。我们把它跟最后一个元素交换,那最大元素就放到了下标为 n 的位置(这个过程相当于删除堆顶元素,交换后的堆顶元素放到了数组的有序区间中,就不算在堆里的数据了)。
当堆顶元素移除之后,我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了。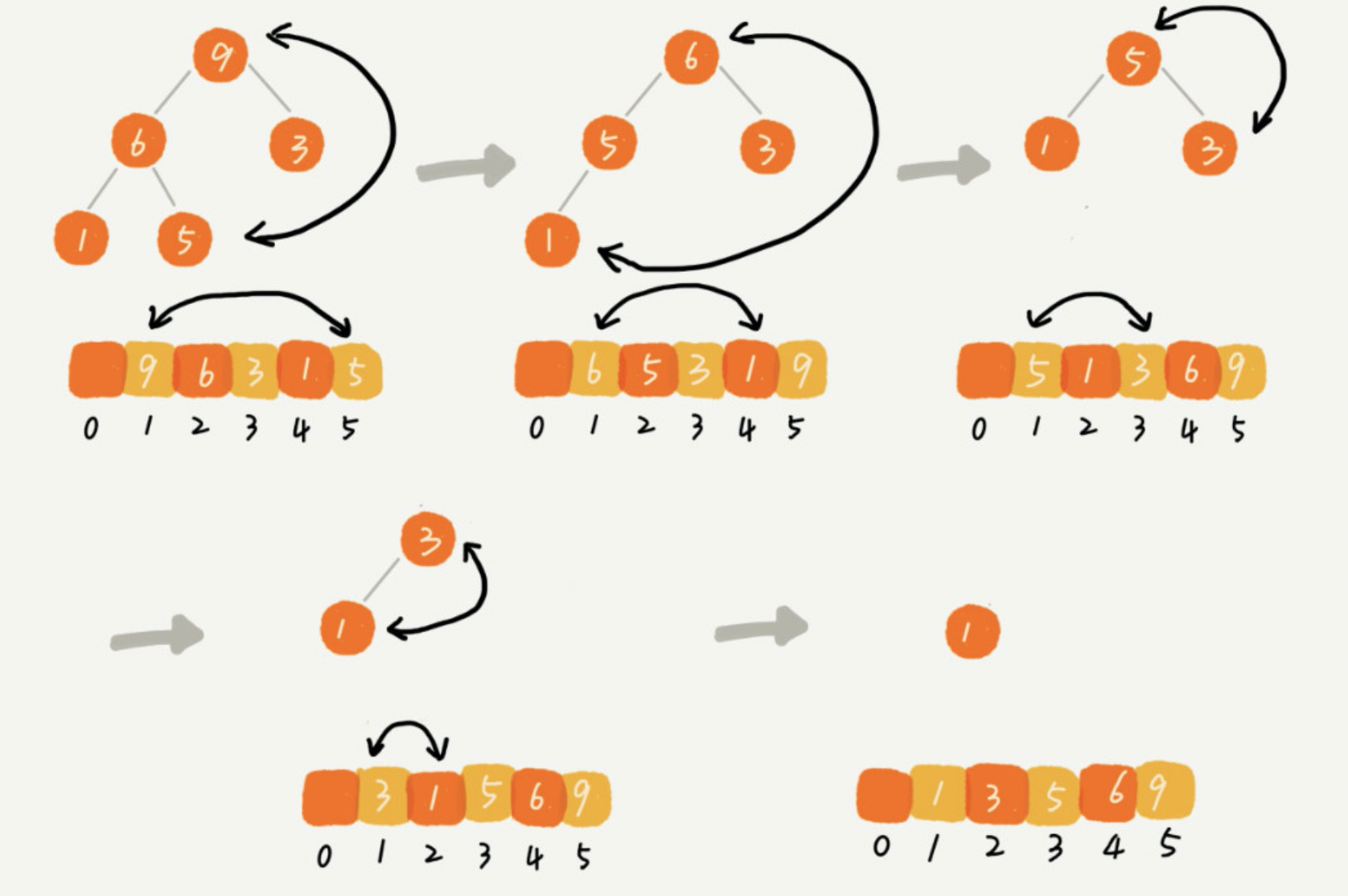
代码实现
/*** 堆排序,这里为了方便展示堆化的过程,排序是从array[1]开始的*/public static int[] sort(int[] array) {if (array.length <= 1) {return array;}buildHeap(array);int heapEndIndex = array.length - 1;while (heapEndIndex > 1) {// 交换堆顶和堆尾元素,堆尾下标减1,表示堆的大小减1int temp = array[1];array[1] = array[heapEndIndex];array[heapEndIndex] = temp;heapEndIndex--;// 每次都是从堆顶开始向下堆化,因为每次都是交换堆顶和堆尾元素heapify(array, 1, heapEndIndex + 1);}return array;}
复杂度分析
稳定性
堆排序不是稳定的排序算法,因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。前面都是假设堆中的数据是从数组下标为 1 的位置开始存储。如果从 0开始存储,处理思路是没有任何变化的,唯一变化的就是代码实现的时候,如果节点的下标是 i,那左子节点的下标就是【2i+1】,右子节点的下标就是【2i+2】,父节点的下标就是【2*i−1】。
时间复杂度
堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
空间复杂度
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法,空间复杂度是 O(1)。
为什么快排要比堆排序性能好?
第一点
堆排序数据访问的方式没有快速排序友好。对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。 比如,堆排序中,最重要的一个操作就是数据的堆化。比如下面这个例子,对堆顶节点进行堆化,会依次访问数组下标是 1,2,4,8 的元素,而不是像快速排序那样,局部顺序访问,所以,这样对 CPU 缓存是不友好的。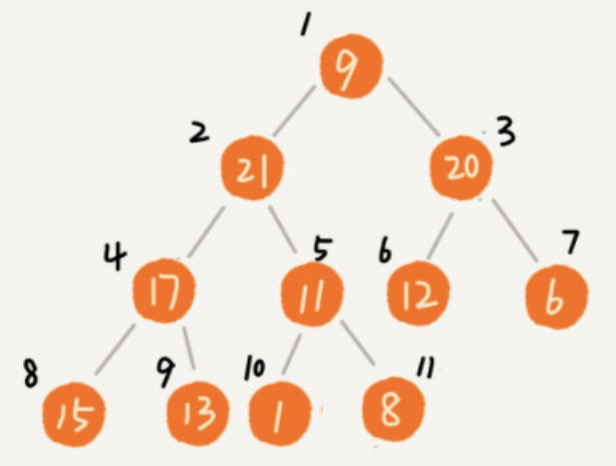
第二点
对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。对于基于比较的排序算法来说,整个排序过程就是由两个基本操作组成的,比较和交换。堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了。

若有收获,就点个赞吧
0 人点赞
