Trie 树,也叫字典树。顾名思义,它是一个树形结构。是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。虽然散列表、红黑树,或之前讲到的一些字符串匹配算法都可以解决这类问题,但 Trie 树在这个问题的解决上,有它特有的优点。不仅如此,Trie 树能解决的问题也不限于此。
基本结构
我们先来看下,Trie 树到底长什么样子。假设有 6 个字符串,它们分别是:how,hi,her,hello,so,see。我们希望在里面多次查找某个字符串是否存在。如果每次查找,都是拿要查找的字符串跟这 6 个字符串依次进行匹配,那效率就比较低,有没有更高效的方法呢?
这个时候,我们就可以先对这 6 个字符串进行预处理,组织成 Trie 树的结构,之后每次查找都在 Trie 树中进行匹配查找。Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。最后构造出来的就是下面这个图中的样子。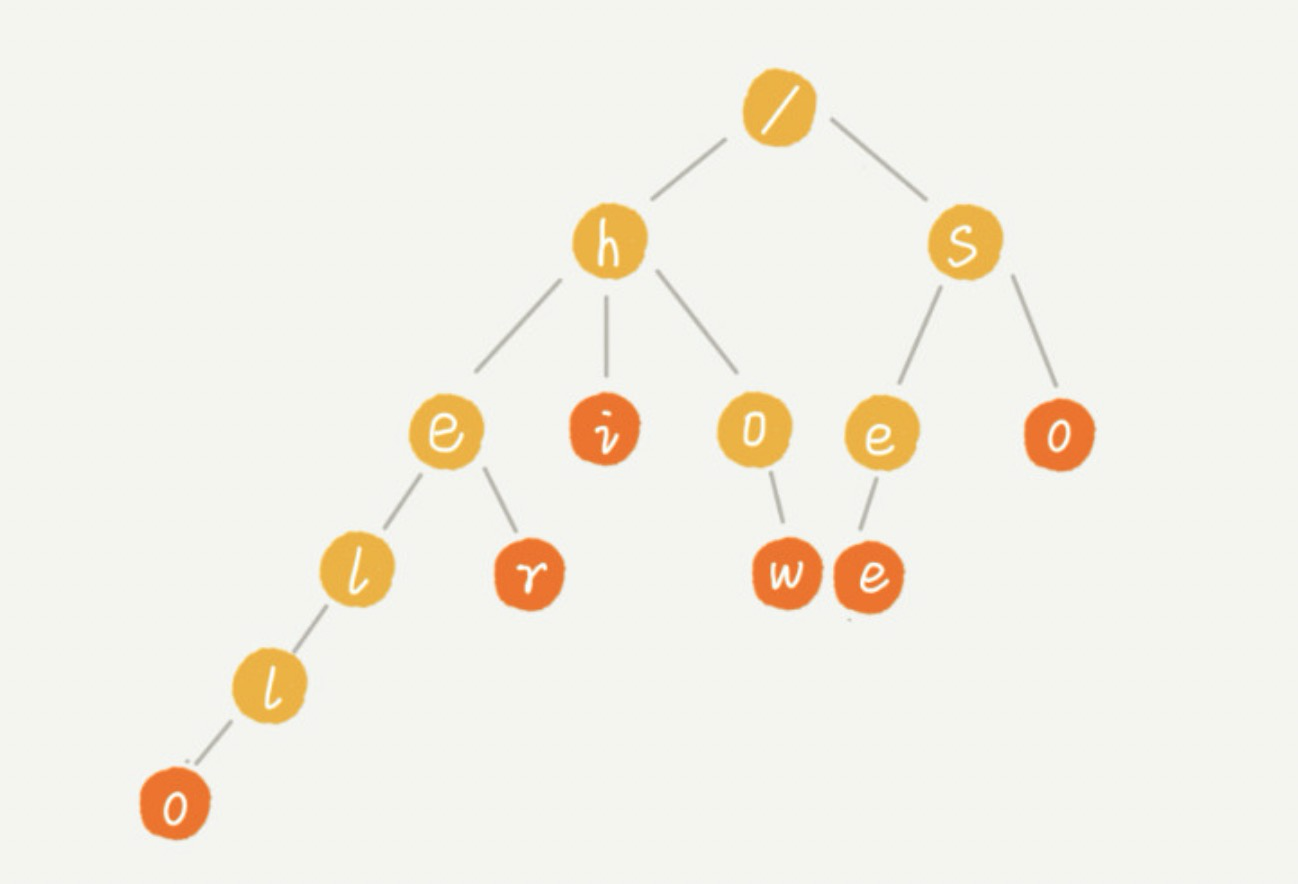
其中,根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串(红色节点并不都是叶子节点,有可能被其他字符串覆盖了)。当我们在 Trie 树中查找一个字符串时,比如查找字符串“her”,那我们将要查找的字符串分割成单个的字符 h,e,r,然后从 Trie 树的根节点开始匹配。如图所示,绿色的路径就是在 Trie 树中匹配的路径。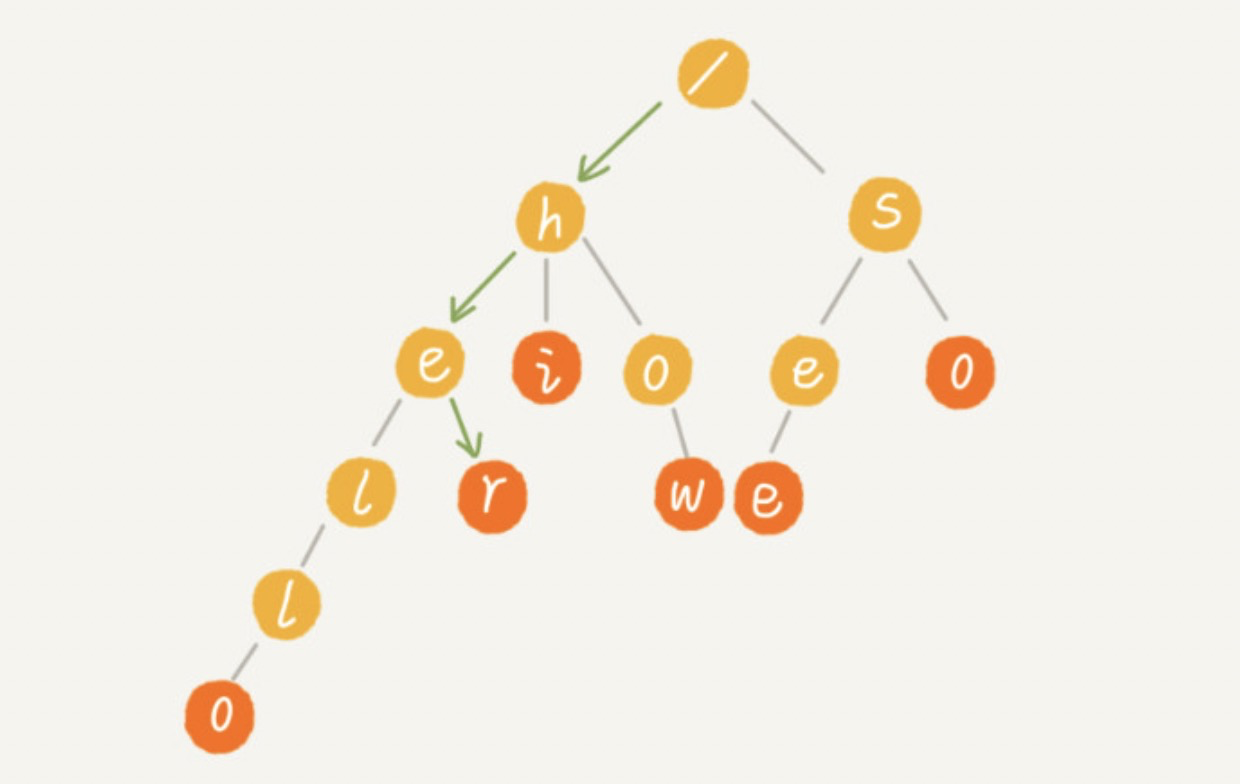
如果我们要查找的是字符串 “he” 呢?同样从根节点开始,沿某条路径来匹配。但是,因为路径的最后一个节点“e”并不是红色的。所以 “he” 只是某个字符串的前缀子串,它并不能完全匹配 Trie 树中的任何字符串。
实现方式
Trie 树主要有两个操作:一个是将字符串集合构造成 Trie 树。这个过程分解开来的话,就是一个将字符串插入到 Trie 树的过程;另一个是在 Trie 树中查询一个字符串。
如何存储一个 Trie 树?
Trie 树是一个多叉树。我们知道,在二叉树中,一个节点的左右子节点是通过两个指针来存储的。那对于多叉树来说,我们要怎么存储一个节点的所有子节点的指针呢?(这里不能直接用 List,因为我们需要知道每个子节点对应存储的元素)这里介绍一种经典的存储方式,借助散列表的思想,我们可以通过一个下标与字符一一映射的数组来存储子节点的指针。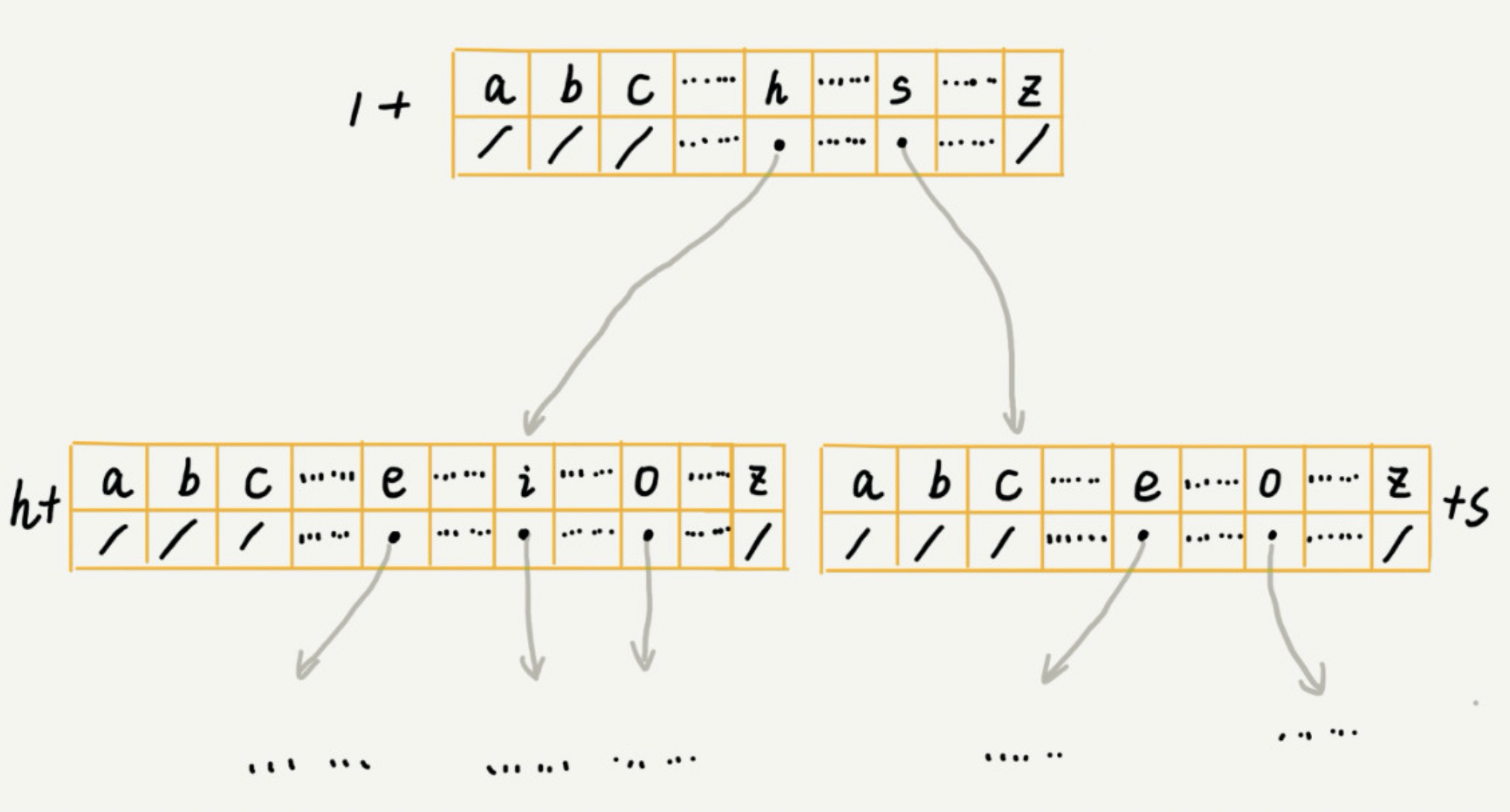
假设字符串中只有从 a 到 z 这 26 个小写字母,我们在数组中下标为 0 的位置,存储指向子节点 a 的指针,下标为 1 的位置存储指向子节点 b 的指针,以此类推,如果某个字符的子节点不存在,我们就在对应的下标的位置存储 null。
当我们在 Trie 树中查找字符串时,我们可以通过字符的 ASCII 码减去“a”的 ASCII 码,迅速找到匹配的子节点的指针。比如,d 的 ASCII 码减去 a 的 ASCII 码就是 3,那子节点 d 的指针就存储在数组中下标为 3 的位置里。
代码实现
public class TrieMatch {/** 根节点存储一个无意义字符 */private final TrieNode root = new TrieNode('/');/*** 往Trie树中插入一个字符串*/public void insert(char[] text) {TrieNode start = root;for (char c : text) {// 因为我们按顺序存储的a~z,所以直接用ASCII码相减就可以快速得到指定的子节点的元素下标int index = c - 'a';if (start.child[index] == null) {TrieNode n = new TrieNode(c);start.child[index] = n;}start = start.child[index];}start.isEndingChar = true;}/*** 从Trie树中匹配一个字符串*/public boolean findMatchText(char[] text) {TrieNode start = root;for (char c : text) {int index = c - 'a';if (start.child[index] == null) {return false;}start = start.child[index];}// 判断是否是结束节点,还是只是部分匹配return start.isEndingChar;}private static class TrieNode {/** 假设每个节点内存储的数据只有a~z */private final char data;/** a元素的下标为0,b元素的下标为1,以此类推,z的下标为25 */private final TrieNode[] child = new TrieNode[26];/** 是否是结束节点,结束节点不一定是根节点,比如字符abc和ab中的节点b,它是结束节点但不是根节点 */private boolean isEndingChar;public TrieNode(char data) {this.data = data;}}}
在 Trie 树中,查找某个字符串的时间复杂度是多少?
如果要在一组字符串中频繁地查询某些字符串,那用 Trie 树会非常高效。构建 Trie 树的过程,需要扫描所有的字符串,时间复杂度是 O(n)(n 表示所有字符串的长度和)。但是一旦构建成功之后,后续的查询操作会非常高效。每次查询时,如果要查询的字符串长度是 k,那我们只需要比对 k 个节点,就能完成查询操作。跟原本那组字符串的长度和个数没有任何关系。所以构建好 Trie 树后,在其中查找字符串的时间复杂度是 O(k),k 表示要查找的字符串长度。
Trie 树的内存消耗
Trie 树是一种非常独特的、高效的字符串匹配方法。但其实 Trie 树是非常耗内存的,它采用的是一种空间换时间的思路。
上面我们在讲 Trie 树的实现时,是用数组来存储一个节点的子节点的指针。如果字符串中包含 a~z 这 26 个字符,那每个节点都要存储一个长度为 26 的数组,并且每个数组元素要存储一个指针。而且,即便一个节点只有很少的子节点,远小于 26 个,比如 3、4 个,我们也要维护一个长度为 26 的数组。而且这还是只包含 26 个字符的情况。如果字符串中不仅包含小写字母,还包含大写字母、数字、甚至是中文,那需要的存储空间就更多了。
因此,在某些情况下,Trie树不一定会节省存储空间。在重复的前缀并不多的情况下,Trie 树不但不能节省内存,还有可能会浪费更多的内存。当然,我们不可否认,Trie 树尽管有可能很浪费内存,但是确实非常高效。那为了解决这个内存问题,我们是否有其他办法呢?
优化方式
为了解决内存占用过多的问题,我们可以稍微牺牲一点查询的效率,将每个节点中的数组换成其他数据结构,比如有序数组、跳表、散列表、红黑树等。假设我们用有序数组,数组中的指针按照所指向的子节点中的字符的大小顺序排列。查询时,我们可以通过二分查找快速查找到某个字符应该匹配的子节点的指针。但是,我们在往 Trie树中插入一个字符串的时候,为了维护数组中数据的有序性,就会稍微慢了点。
实际上,Trie 树的变体有很多,都可以在一定程度上解决内存消耗的问题。比如,缩点优化,就是对只有一个子节点的节点,而且此节点不是一个串的结束节点,可以将此节点与子节点合并。这样可以节省空间,但却增加了编码难度。这里就不展开详细讲解了,如果感兴趣,可以自行研究下。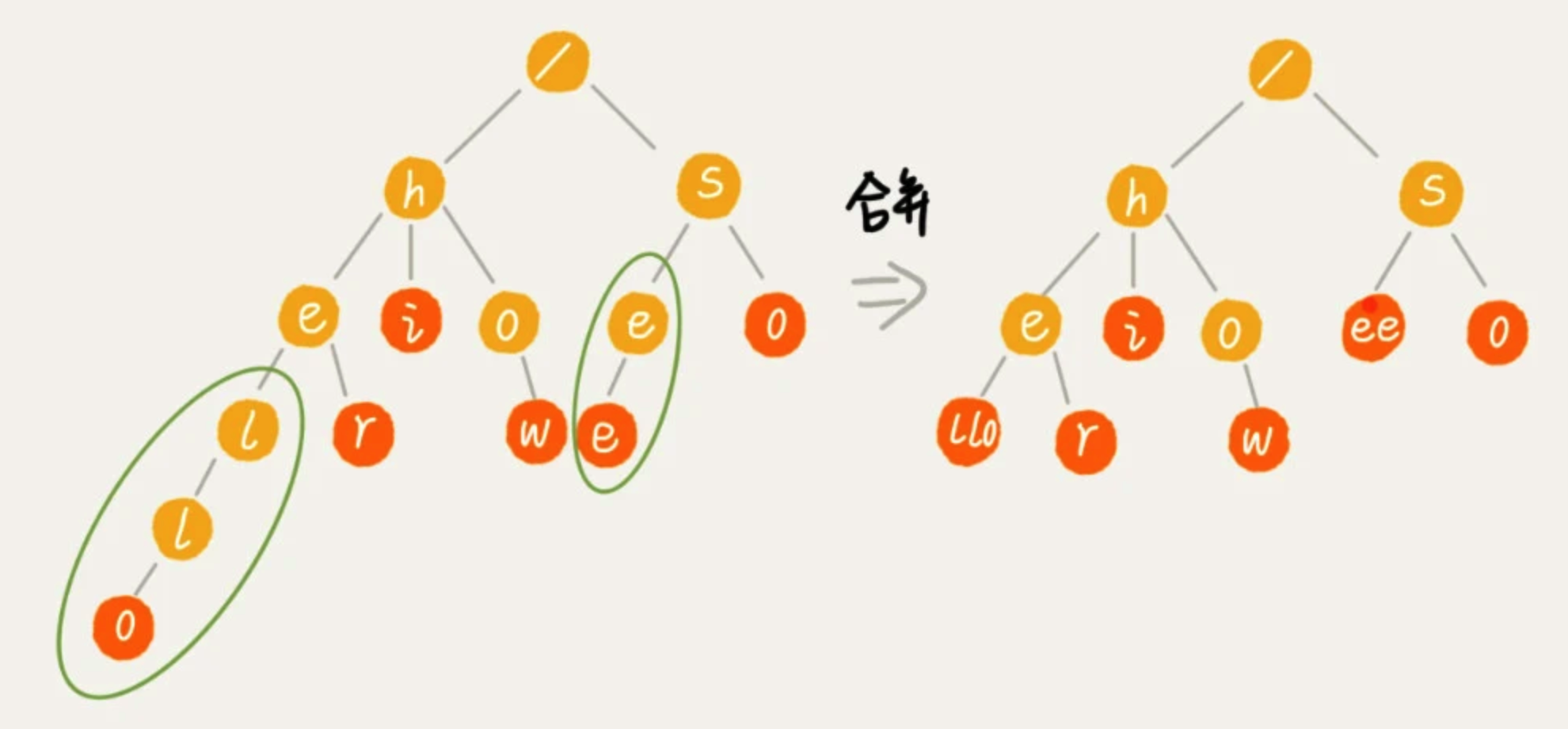
使用场景
实际上,字符串的匹配问题,笼统上讲,其实就是数据的查找问题。对于支持动态数据高效操作的数据结构,比如散列表、红黑树、跳表等。这些数据结构也可以实现在一组字符串中查找字符串的功能。
Trie 树与散列表、红黑树的比较
在一组字符串中查找字符串,Trie 树实际上表现得并不好。它对要处理的字符串有及其严苛的要求
- 字符串中包含的字符集不能太大,如果字符集太大,那存储空间可能会浪费很多。
- 要求字符串的前缀重合比较多,不然空间消耗会变大很多。
- 通过指针串起来的数据块是不连续的,而 Trie 树中用到了指针,所以对缓存并不友好,性能会稍差些。
因此,针对在一组字符串中查找字符串的问题,我们在工程中更倾向于用散列表或红黑树。因为这两种数据结构,我们都不需要自己去实现,直接利用编程语言中提供的现成类库就行了。实际上,Trie 树只是不适合精确匹配查找,这种问题更适合用散列表或者红黑树来解决。Trie 树比较适合的是查找前缀匹配的字符串,比如搜索引擎中的关键词提示的功能。

若有收获,就点个赞吧
0 人点赞
