RK(Rabin-Karp)算法的全称叫 Rabin-Karp 算法,是由它的两位发明者 Rabin 和 Karp 的名字来命名的。这个算法理解起来也不难,它其实就是 BF 算法的升级版。在 BF 算法中,如果主串长度为 n,模式串长度为 m,那在主串中就会有 n-m+1 个长度为 m 的子串,我们只需要暴力地对比这 n-m+1 个子串与模式串,就可以找出匹配的子串。但每次检查主串与模式串是否匹配,都需要依次比对每个字符,所以 BF 算法的时间复杂度是 O(n*m)。
算法思想
而 RK 算法的思路是:我们通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小。如果某个子串的哈希值与模式串相等,则说明对应的子串和模式串匹配(先不考虑哈希冲突)。因为哈希值是一个数字,数字之间比较是否相等是非常快速的,所以模式串和子串比较的效率就提高了。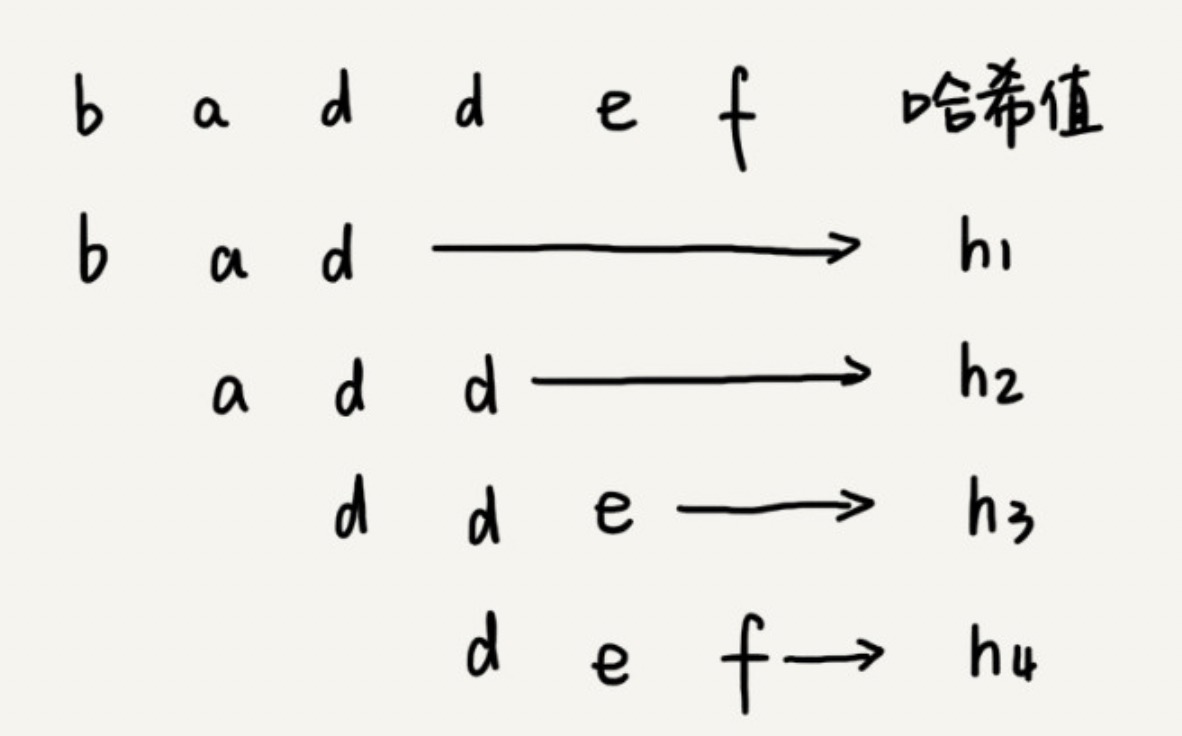
不过,通过哈希算法计算子串的哈希值时,我们仍需遍历子串中的每个字符。尽管模式串与子串比较的效率提高了,但算法整体效率并没有提高。有没有方法可以提高哈希算法计算子串哈希值的效率呢?
如何提高哈希算法计算子串哈希值的效率?
这需要哈希算法设计的非常有技巧。假设要匹配的字符串的字符集中只包含 K 个字符,我们可以用一个 K 进制数来表示一个子串,然后把这个 K 进制数转化成十进制数作为子串的哈希值。
假设要处理的字符串只包含 a~z 这 26 个字符,那我们就用二十六进制来表示一个字符串。即把 a~z 这 26 个字符映射到 0~25 这 26 个数字上。在十进制的表示法中,一个数字的值是通过下面的方式计算出来的。对应到二十六进制,计算哈希值的时候,我们只需要把进位从 10 改成 26 就可以了。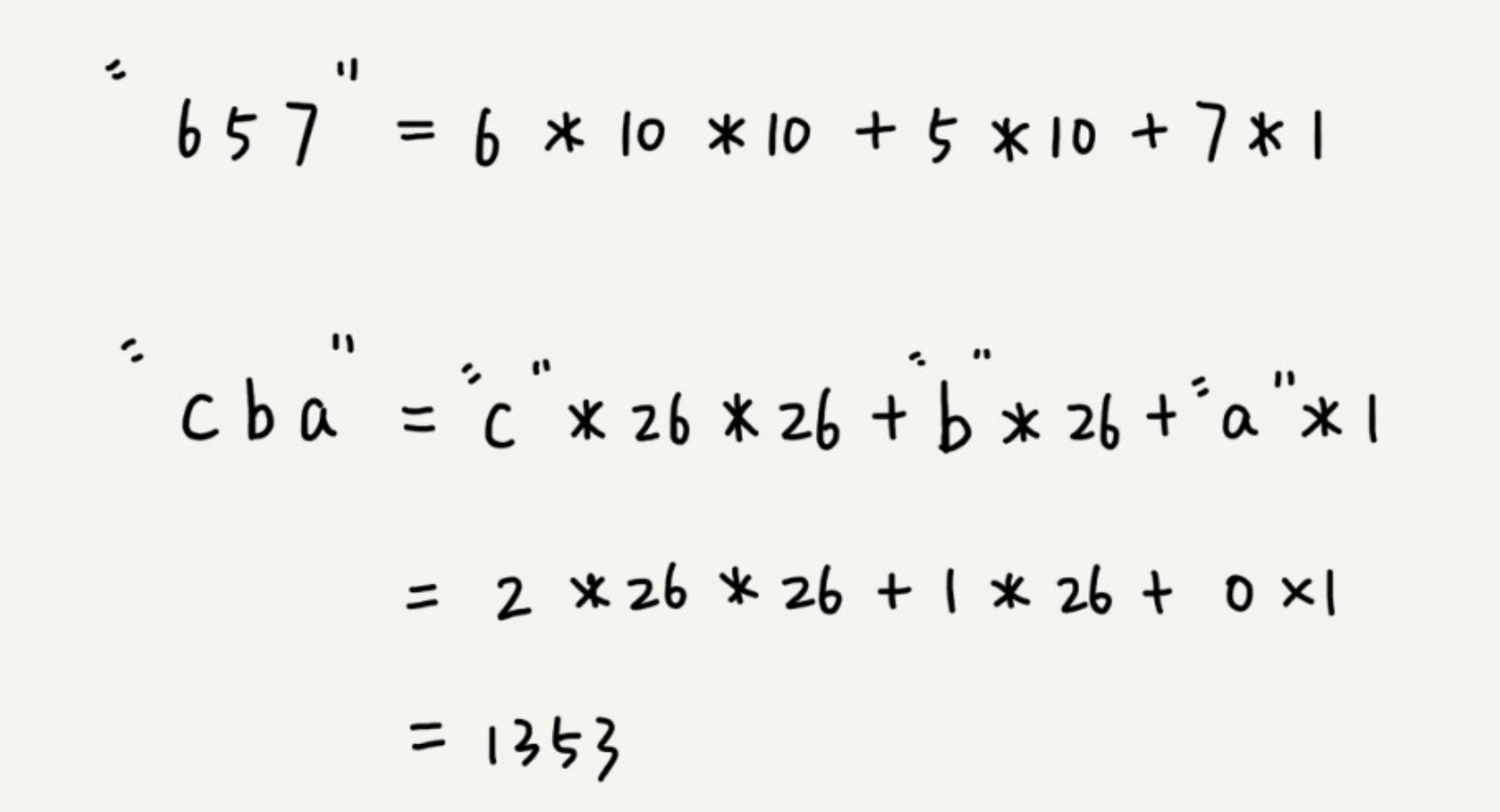
这种哈希算法有一个特点,在主串中,相邻两个子串的哈希值的计算公式有一定关系。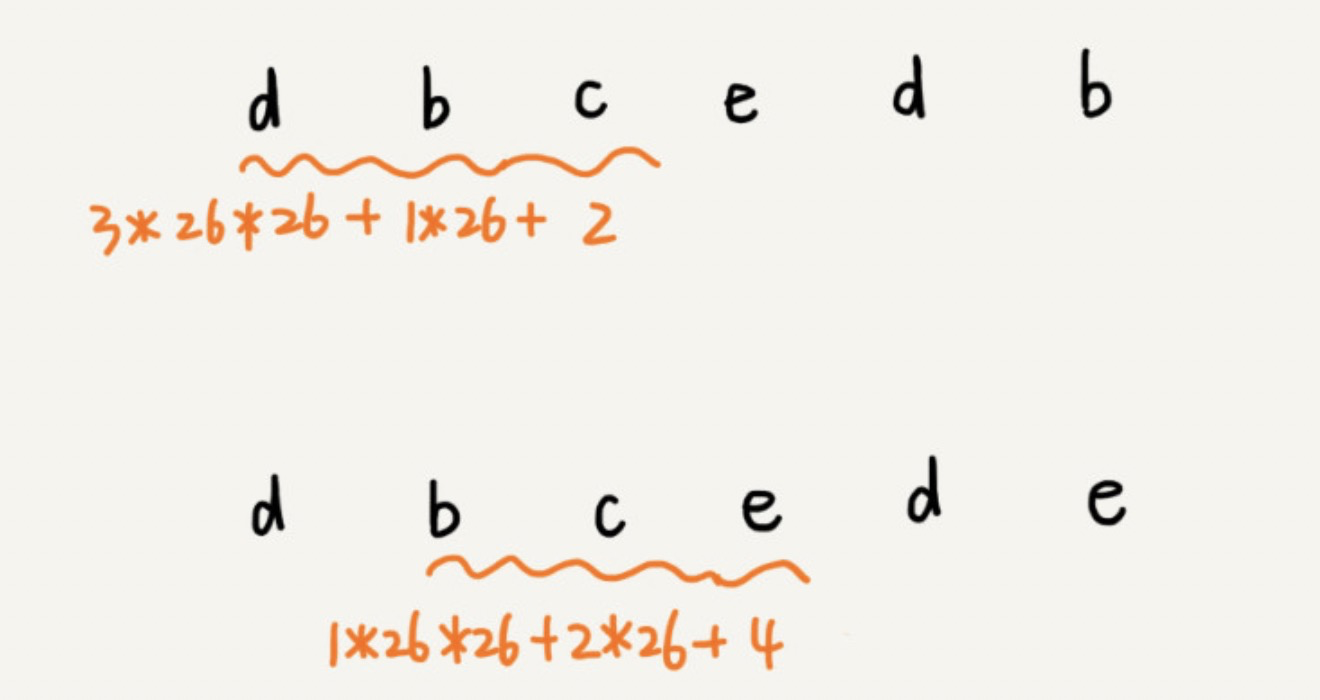
从图中我们可以很容易的得出这样的规律:相邻的两个子串 s[i-1] 和 s[i](i 表示子串在主串中的起始位置,子串的长度都为 m),对应的哈希值的计算公式是有交集的,因此我们可以用 s[i-1] 的哈希值很快的计算出 s[i] 的哈希值。
通过该公式,我们在计算每个子串的哈希值时,就不需要再遍历子串中的每个字符了,通过前一个子串的哈希值就能很快的计算出当前子串的哈希值了,所以在检查主串与模式串是否匹配这一过程,提高了很大的效率。
通过哈希表进一步优化
针对 26m-1 这部分的计算,我们可以通过查表的方法来提高效率。我们事先计算好 260、261、262……26m-1,并且存储在一个长度为 m 的数组中,公式中的“次方”就对应数组的下标。当我们需要计算 26 的 x 次方时,就可以从数组的下标为 x 的位置取值,直接使用,省去了计算的时间。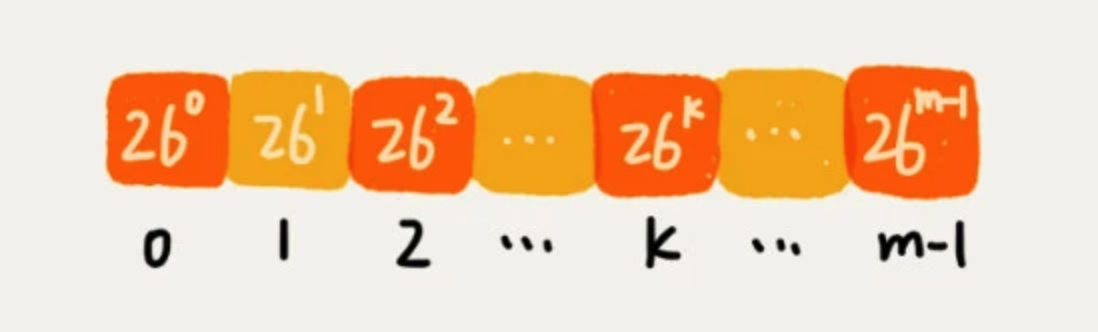
时间复杂度分析
整个 RK 算法包含两部分:计算子串哈希值和模式串哈希值与子串哈希值之间的比较。第一部分可通过设计特殊的哈希算法,使得扫描一遍主串就能计算出所有子串的哈希值,所以这部分时间复杂度是 O(n)。第二部分直接比较的哈希值,单个比较操作的时间复杂度是 O(1),总共需要比较 n-m+1 个子串的哈希值,所以这部分的时间复杂度也是 O(n)。所以,RK 算法整体的时间复杂度就是 O(n)。
计算哈希值时整型溢出怎么办?
当模式串很长时,相应的主串中的子串也会很长,通过上面的哈希算法计算得到的哈希值就可能很大,如果超过了计算机中整型数据可以表示的范围,那该如何解决呢?实际上,我们为了能将哈希值落在整型数据范围内,可以牺牲一下,允许哈希冲突。比如我们可以把字符串中每个字母对应的数字相加,最后得到的和作为哈希值,而不是转换为二十六进制。这样产生的哈希值的数据范围就相对要小很多了。
哈希冲突怎么办?
当存在哈希冲突时,有可能子串和模式串的哈希值是相同的,但其实两者是并不匹配的。实际上,解决方法很简单。当我们发现一个子串的哈希值跟模式串的哈希值相等时,我们只需要再对比一下子串和模式串本身是否匹配就好了。所以,哈希算法的冲突概率要相对控制得低一些,如果存在大量冲突,就会导致 RK 算法的时间复杂度退化。极端情况下,如果存在大量的冲突,每次都要再对比子串和模式串本身,那时间复杂度就会退化成 O(n*m)。
代码实现
/*** RK算法,假设字符串中的每个字符都是a~z* 每个字符对应整数0~25,采用二十六进制计算哈希值** @param main 主串* @param pattern 模式串*/public static int rk(String main, String pattern) {int n = main.length();int m = pattern.length();// 保存子串的哈希值int[] hash = new int[n - m + 1];int[] table = new int[26];// 主串char[] mainArray = main.toCharArray();// 模式串char[] patternArray = pattern.toCharArray();// 用哈希表保存计算好的平方值,空间换时间策略int number = 1;for (int i = 0; i < table.length; i++) {table[i] = number;number *= 26;}// 循环计算每个子串的哈希值for (int i = 0; i <= n - m; i++) {int hashcode = 0;for (int j = 0; j < m; j++) {hashcode += (mainArray[i + j] - 'a') * table[m - 1 - j];}hash[i] = hashcode;}// 计算模式串的哈希值int patternHashcode = 0;for (int i = 0; i < m; i++) {patternHashcode += (patternArray[i] - 'a') * table[m- 1 - i];}// 遍历判断哈希值是否相等for (int i = 0; i < n - m + 1; i++) {if (hash[i] == patternHashcode) {return i;}}return -1;}

若有收获,就点个赞吧
0 人点赞
