位图
在讲布隆过滤器前,先讲一下位图(BitMap)。因为,布隆过滤器本身就是基于位图的,是对位图的一种改进。我们先来看一个问题:假设 QQ 号是一个 10 位以内的数字,用一个长整型是可以存储得下的。
现在,有一个文件里存储了很多个 QQ 号,但可能会有一定的重复,现在让你遍历一遍文件把其中重复的 QQ 号都过滤掉,然后把结果输出到一个新的文件中,你会怎么做?如果文件中存储的 QQ 号多达 40 亿个,但是你的内存又比较有限,比如只有 1GB,那你会怎么做呢?
先说下常规思路。假设内存没有限制,那我们可以直接采用基于散列思想的 HashSet 或基于树状结构的 Set,前者可以在 O(1) 的时间复杂度内,判断某个元素是否存在于集合中,后者虽然需要 O(logN) 的时间复杂度,但是在十亿的数量级下,其实也就是比较 30 次左右,代价也并不高。当然,我们也可以先用数组把所有 QQ 号存储下来进行排序;然后顺次遍历,跳过所有和前个 QQ 号相同的 QQ 号,也能实现去重。
但是这个题的核心在于空间限制,因为存储的是 10 位数的 QQ 号,这意味着我们的数组至少要有 10 位数以上的 index,假设最高位以 1、2、3、4 开头,也就是说数组至少要存放 40 亿级别的数据。假设数组类型是 bool,表示对应 index 的 QQ 号是否存在,那我们所需要的内存空间大约是 4GB。虽然这对目前的硬件来说不是一个特别高的内存要求,但如果存 11 位的 QQ 号或其他更大的数据量,显然就不够用了。而且这道题的原始版本要求我们用 1GB 的内存实现去重。总之,如果有办法用更低的内存,我们应该想办法去发掘。
换个思路,我们可以借鉴外部排序的思想,逐行读入大文件,根据 QQ 号的范围,切分成多个可以一次性加载进内存的小文件。比如切分为 400 个文件。这样每个文件再用 HashSet 之类的手段去重,最后合并就可以了。外部排序是一个可行的解决办法,而且理论上来说,利用类似的思路,我们还可以实现更大数量级的去重任务,但是代价是要进行更多次的 IO,性能比较差。事实上,40 亿级的数据范围,在 1GB 的内存下,我们是有办法直接在内存中处理去重的,这就是 Bitmap。
1. 设计思想
前面通过数组存 bool 值的方式,显然不是最经济的一种存储方式,因为每个 bool 类型在数组中占据了一个字节的数据,也就是 8 个 bit。但存储一个数字是否出现,我们只需要用一个 bit 来记录。Bitmap 的核心就是用数字二进制的每一位去标记某个二值的状态,比如是否存在,用 0 表示不存在,用 1 表示存在,所以可以在非常高的空间利用率下保存大量二值的状态。一个基本的 Bitmap 如下图所示: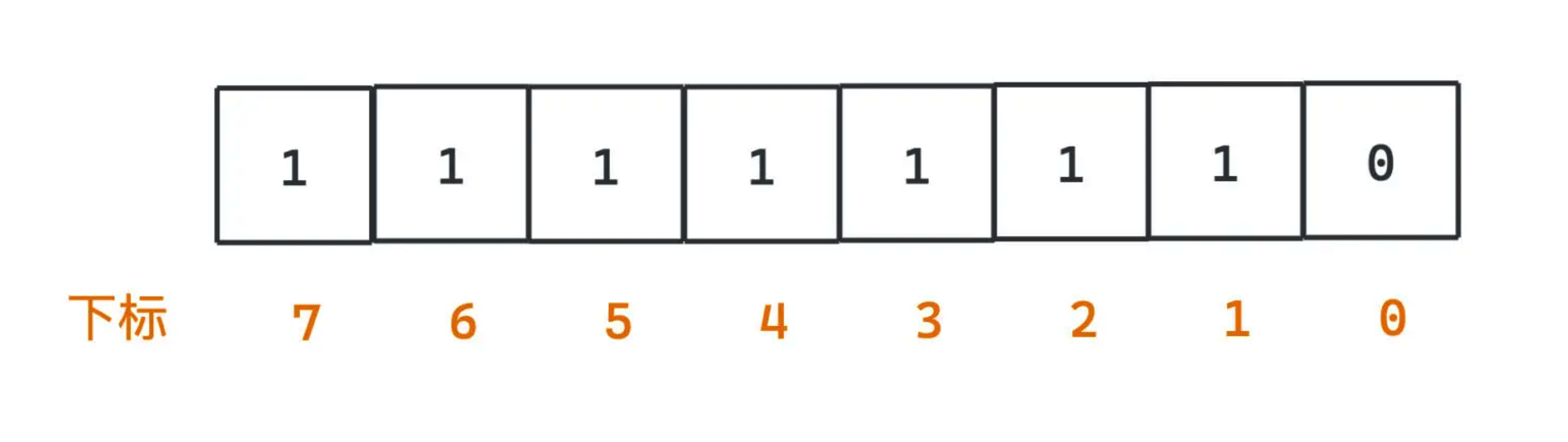
上图中 Bitmap 的值为 254,表示下标 1~7 的元素都有出现,而下标 0 的元素没有出现。这样仅仅用了一个字节就表示了 8 个元素是否出现的情况,而如果用数组,则至少需要 8 个 bool 值也就是 8 个字节大小的空间,这样我们就节约了 8 倍的空间。如果要存储 40 亿个 QQ 号,采用 Bitmap 最少只需要 40 亿个 bits,所占据的空间大约是 500M 左右,这样,我们就大大压缩了内存的使用空间,在 1GB 内就可以完成去重工作。
2. 代码实现
许多编程语言内置了 Bitmap 这种数据类型,例如,Java 中 BitMap 的实现如下:
// Java中char类型占16bit,也即是2个字节public class BitMap {private char[] bytes;private int nbits;public BitMap(int nbits) {this.nbits = nbits;this.bytes = new char[nbits/16+1];}public void set(int k) {if (k > nbits) return;int byteIndex = k / 16;int bitIndex = k % 16;bytes[byteIndex] |= (1 << bitIndex);}public boolean get(int k) {if (k > nbits) return false;int byteIndex = k / 16;int bitIndex = k % 16;return (bytes[byteIndex] & (1 << bitIndex)) != 0;}}
位图通过数组下标来定位数据,访问效率非常高。而且,每个数字用一个二进制位来表示,在数字范围不大的情况下,所需要的内存空间非常节省。不过,这里我们有个假设,就是数字所在的范围不是很大。如果数字的范围很大,比如数字范围是一到一千亿,那位图的大小就是一千亿个二进制位,而我们需要去重的数字只有十亿个,这时,采用 Bitmap 消耗的内存空间不降反增。这个时候,布隆过滤器就要出场了。
布隆过滤器
1. 设计思想
布隆过滤器就是为了解决上面那个问题,对位图这种数据结构的一种改进。如果数据个数只有十亿,但数据的范围是一到一千亿。布隆过滤器的做法是:我们仍使用十亿个二进制大小的位图,然后通过哈希函数对数字进行处理,让它落在这一到一千亿的范围内。
但哈希函数会存在冲突的问题,布隆过滤器的处理方法是:既然一个哈希函数可能会存在冲突,那用多个哈希函数一块儿定位一个数据,是否能降低冲突的概率呢?
布隆过滤器是怎么做的。我们使用 K 个哈希函数,对同一个数字进行求哈希值,那会得到 K 个不同的哈希值,我们分别记作 X1,X2,X3 … XK。我们把这 K 个数字作为位图中的下标,将对应的 BitMap[X1],BitMap[X2],BitMap[X3] … BitMap[XK] 都设置成 true,也就是说,我们用 K 个二进制位,来表示一个数字的存在。
当我们要查询某个数字是否存在的时候,我们用同样的 K 个哈希函数,对这个数字求哈希值,分别得到 Y1,Y2,Y3 … YK。我们看这 K 个哈希值,对应位图中的数值是否都为 true,如果都是 true,则说明这个数字存在,如果有其中任意一个不为 true,那就说明这个数字不存在。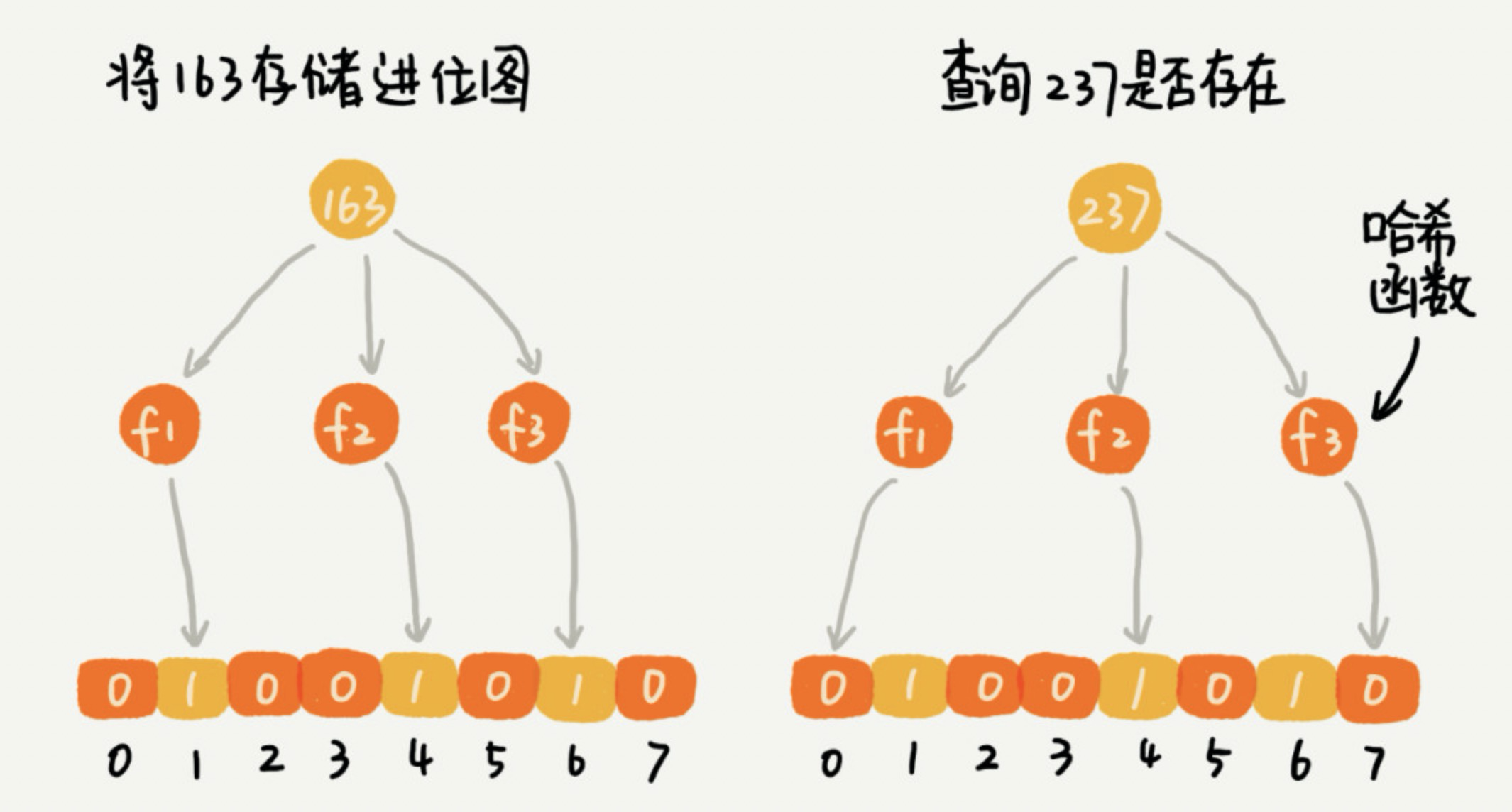
对于两个不同的数字来说,经过一个哈希函数处理之后,可能会产生相同的哈希值。但是经过 K 个哈希函数处理之后,K 个哈希值都相同的概率就非常低了。尽管采用 K 个哈希函数之后,两个数字哈希冲突的概率降低了,但这种处理方式又带来了新的问题,那就是容易误判。我们看下面这个例子。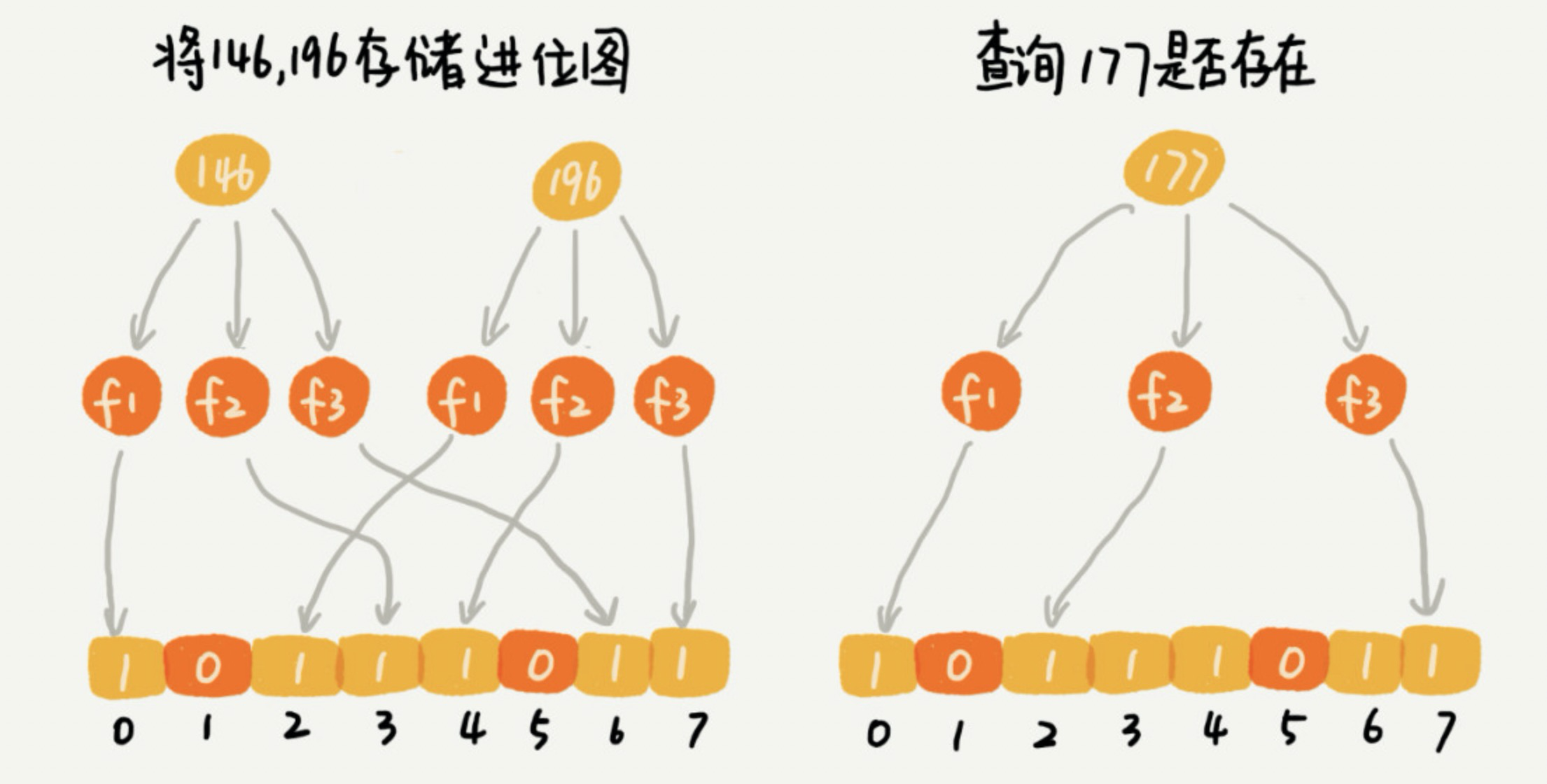
布隆过滤器的误判有一个特点,那就是,它只会对存在的情况有误判。如果某个数字经过布隆过滤器判断不存在,那说明这个数字真的不存在;如果某个数字经过布隆过滤器判断存在,此时有可能误判,值有可能并不存在。不过,只要我们调整哈希函数的个数、位图大小跟要存储数字的个数之间的比例,那就可以将这种误判的概率降到非常低。
尽管布隆过滤器会存在误判,但这并不影响它发挥大作用。很多场景对误判有一定的容忍度。比如网页爬虫中的 URL 去重问题,即便一个没有被爬取过的网页,被误判为已经被爬取,对于搜索引擎来说,也是可以容忍的。除了爬虫网页去重这个例子,还有比如统计一个大型网站每天的用户访问数,我们就可以使用布隆过滤器,对重复访问的用户进行去重。
我们前面讲到,布隆过滤器的误判率,主要跟哈希函数的个数、位图的大小有关。当我们往布隆过滤器中不停地加入数据后,位图中不是 true 的位置就越来越少,误判率就越来越高了。所以,对于无法事先知道要判重的数据个数的情况,我们需要支持自动扩容的功能。在使用布隆过滤器的时候,当数据个数与位图大小的比例超过某个阈值时,我们就重新申请一个新的位图。把后面来的新数据,放置到新的位图中。
2. 代码实现
布隆过滤器应用非常广泛,Google 提供的经典 Java 工具库 Guava 中,就有一个对 bloom filter 的实现,它提供了很好的泛化能力,通过自己重新封装 bitset 获得了更佳的性能,同时也支持多种不同的策略。我们来看一下核心的逻辑:
MURMUR128_MITZ_64() {@Overridepublic <T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {long bitSize = bits.bitSize();// 获得带有随机性的hash种子byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();long hash1 = lowerEight(bytes);long hash2 = upperEight(bytes);boolean bitsChanged = false;long combinedHash = hash1;// 进行k次hash计算for (int i = 0; i < numHashFunctions; i++) {// Make the combined hash positive and indexablebitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);combinedHash += hash2;}return bitsChanged;}@Overridepublic <T> boolean mightContain(T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {long bitSize = bits.bitSize();byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();long hash1 = lowerEight(bytes);long hash2 = upperEight(bytes);long combinedHash = hash1;for (int i = 0; i < numHashFunctions; i++) {// Make the combined hash positive and indexableif (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {return false;}combinedHash += hash2;}return true;}}
MURMUR128_MITZ_64 是其中一种比较常见的策略,核心方法就是 put 和 mightContain 方法。put 方法的核心逻辑就是通过 murmur3_128 进行 Hash 计算,得到一个 128 位带有随机性的 byte,取其中的高位和低位作为种子,再通过简单的位运算叠加 k 次,等同了 Hash k 次的效果,最后把对应的位置都置 1 即可。mightContain 的逻辑,基本上就是相反的过程。

若有收获,就点个赞吧
0 人点赞
