很多支持用户发表文本内容的网站,大都会有敏感词过滤功能,用来过滤掉用户输入的一些淫秽、反动、谩骂等内容。实际上,这些功能最基本的原理就是字符串匹配算法,也就是通过维护一个敏感词的字典,当用户输入一段文字内容之后,通过字符串匹配算法,来查找用户输入的这段文字,是否包含敏感词。如果有,就用“*”把它替代掉。前面讲过的好几种字符串匹配算法,它们都可以处理这个问题。但对于访问量巨大的淘宝来说,用户每天的评论数有几亿、甚至几十亿。这时候,我们对敏感词过滤系统的性能要求就要很高。那如何才能实现一个高性能的敏感词过滤系统呢?这就要用到今天的多模式串匹配算法。
单模式串匹配算法就是在一个模式串和一个主串之间进行匹配,而多模式串匹配算法是在多个模式串和一个主串之间进行匹配。尽管,单模式串匹配算法也能完成多模式串的匹配工作,但如果这样做的话,每个匹配过程都需要扫描一遍模式串的内容,整个过程下来就要扫描很多遍模式串的内容。显然,这种处理思路比较低效。
与单模式匹配算法相比,多模式匹配算法在这个问题的处理上就很高效了。它只需要扫描一遍主串,就能在主串中一次性查找多个模式串是否存在,从而大大提高匹配效率。实际上,Trie 树就是一种多模式串匹配算法。我们可以对要匹配的多个模式串进行预处理,构建成 Trie 树结构。这个预处理的操作只需要做一次。当与主串进行匹配时,我们从主串的第一个字符开始,在 Trie 树中匹配。当匹配到 Trie 树的叶子节点,或者中途遇到不匹配字符时,我们将主串的开始匹配位置后移一位,然后重新在 Trie 树中匹配。
基于 Trie 树的这种处理方法类似单模式串匹配的 BF 算法。我们知道,单模式串匹配算法中,KMP 算法对 BF 算法进行改进,引入了 next 数组,让匹配失败时,尽可能将模式串往后多滑动几位。借鉴单模式串的优化改进方法,我们能否对多模式串 Trie 树进行改进,进一步提高 Trie 树的效率呢?这就要用到 AC 自动机算法了。
基本原理
AC 自动机算法,全称是 Aho-Corasick 算法。其实,Trie 树跟 AC 自动机之间的关系,就像单模式串匹配算法中的 BF 算法跟 KMP 算法。所以,AC 自动机实际上就是在 Trie 树的基础上,增加了类似 KMP 算法中的 next 数组,只不过此处的 next 数组是构建在树上的。如果用代码表示,就是下面这个样子:
public class AcNode {public char data;public AcNode[] children = new AcNode[26]; // 字符集只包含a~z这26个字符public boolean isEndingChar = false; // 结尾字符为truepublic int length = -1; // 当isEndingChar=true时,记录模式串长度public AcNode fail; // 失败指针}
1. 构建过程
所以,AC 自动机的构建包含两个操作:
- 将多个模式串构建成 Trie 树
- 在 Trie 树上构建失败指针(相当于 KMP 算法中的失效函数 next 数组)
这里我们重点看下,构建好 Trie 树后,如何在它之上构建失败指针?以下图为例。这里有一个已经构建好的 Trie 树,它包含了 4 个模式串,分别是 c,bc,bcd,abcd。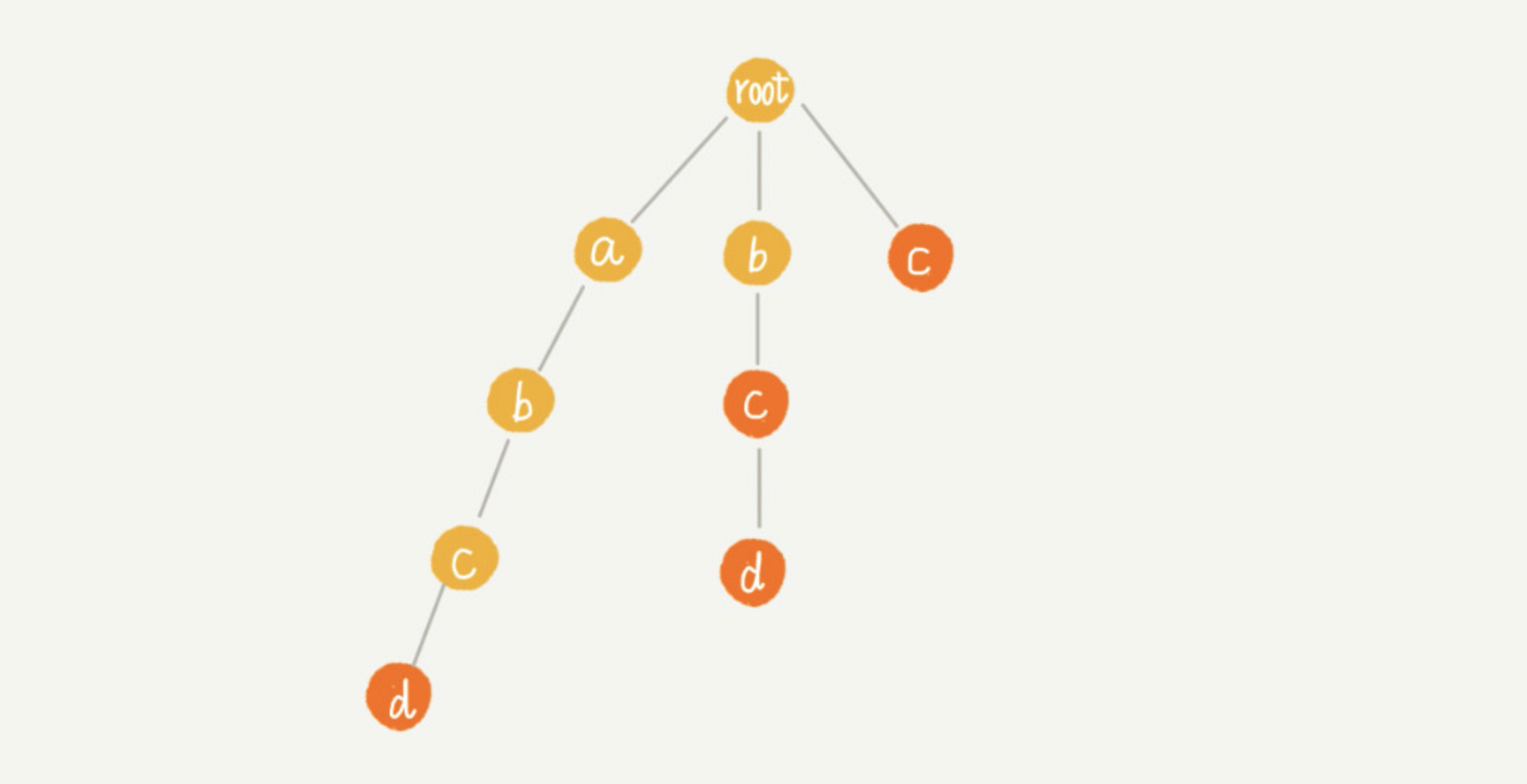
如何构建失败指针?
在 Trie 树中的每一个节点都有一个失败指针,它的作用和构建过程,跟 KMP 算法中的 next 数组极其相似。假设我们沿 Trie树走到了下图中的紫色节点(我们称该节点为 p 节点),那 p 节点的失败指针就是从 root 走到紫色节点形成的字符串 abc,跟所有模式串前缀匹配的最长可匹配后缀子串,就是箭头指的 bc 模式串。
这里讲解一下,字符串 abc 的后缀子串有 bc,c,我们拿它们与其他模式串匹配,如果某个后缀子串可以匹配某个模式串的前缀,那我们就把这个后缀子串叫作可匹配后缀子串。我们从可匹配后缀子串中找出最长的一个,就是最长可匹配后缀子串。我们将 p 节点的失败指针指向那个最长匹配后缀子串(bc)对应匹配的那个模式串的前缀(bc)的最后一个节点,即下图中箭头指向的节点。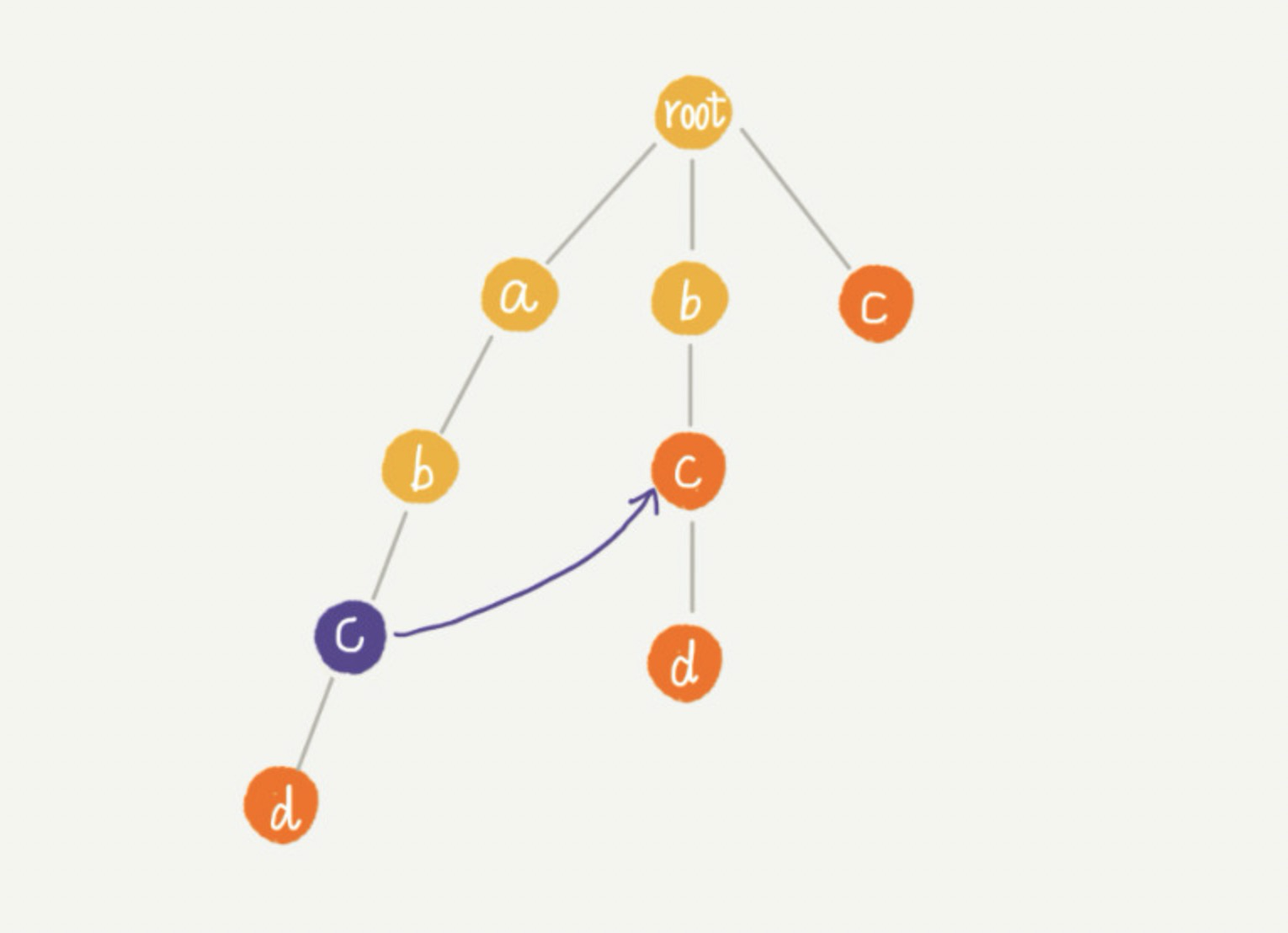
计算每个节点的失败指针这个过程看起来有些复杂。其实,如果我们把树中相同深度的节点放到同一层,那么某个节点的失败指针只有可能出现在它所在层的上一层。
我们可以像 KMP 算法那样,当我们要求某个节点的失败指针的时候,我们通过已经求得的、深度更小的那些节点的失败指针来推导。也就是说,我们可以逐层依次来求解每个节点的失败指针。所以,失败指针的构建过程,是一个按层遍历树的过程。
首先 root 的失败指针为 NULL,也就是指向自己。当我们已经求得某个节点 p 的失败指针之后,如何寻找它的子节点的失败指针呢?我们假设节点 p 的失败指针指向节点 q,我们看节点 p 的子节点 pc 对应的字符,是否也可以在节点 q 的子节点中找到。如果找到了节点 q 的一个子节点 qc,对应的字符跟节点 pc 对应的字符相同,则将节点 pc 的失败指针指向节点 qc。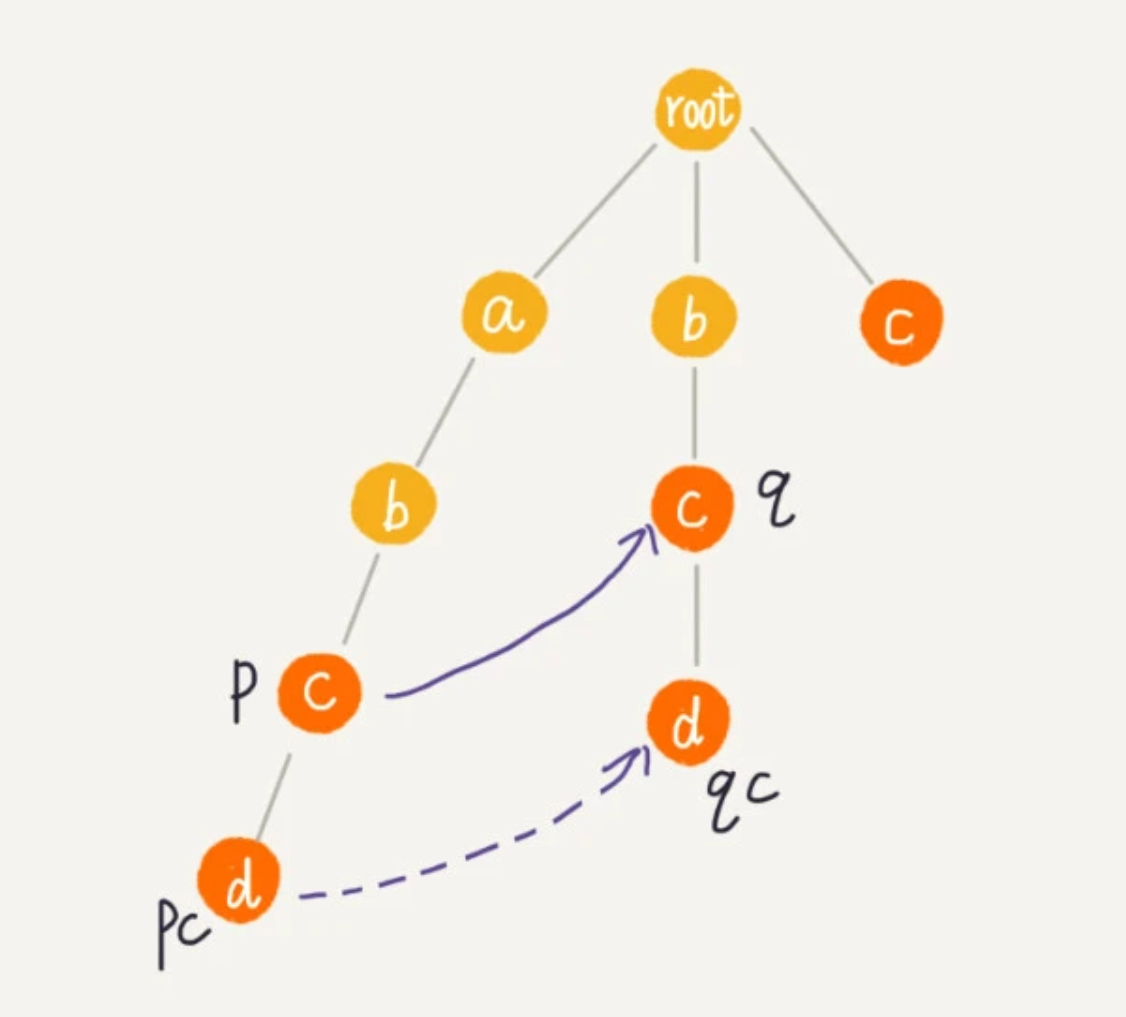
如果节点 q 中没有子节点的字符等于节点 pc 包含的字符,则令 q=q->fail(fail 表示失败指针,这里有没有很像 KMP 算法里求 next 的过程?),继续上面的查找,直到 q 是 root 为止,如果还没有找到相同字符的子节点,就让节点 pc 的失败指针指向 root。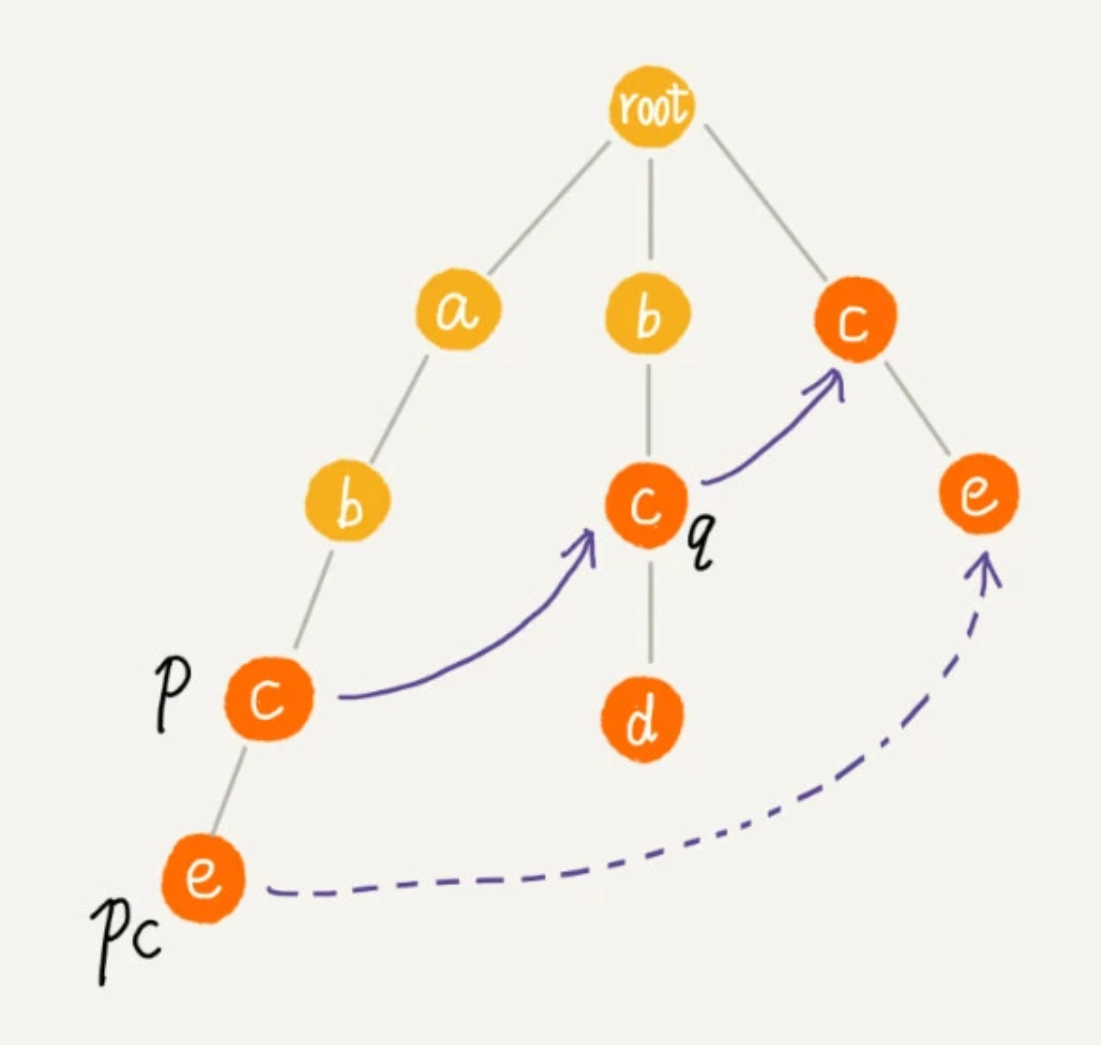
通过按层来计算每个节点的子节点的失效指针。最后构建完成之后的 AC 自动机就是下面这个样子: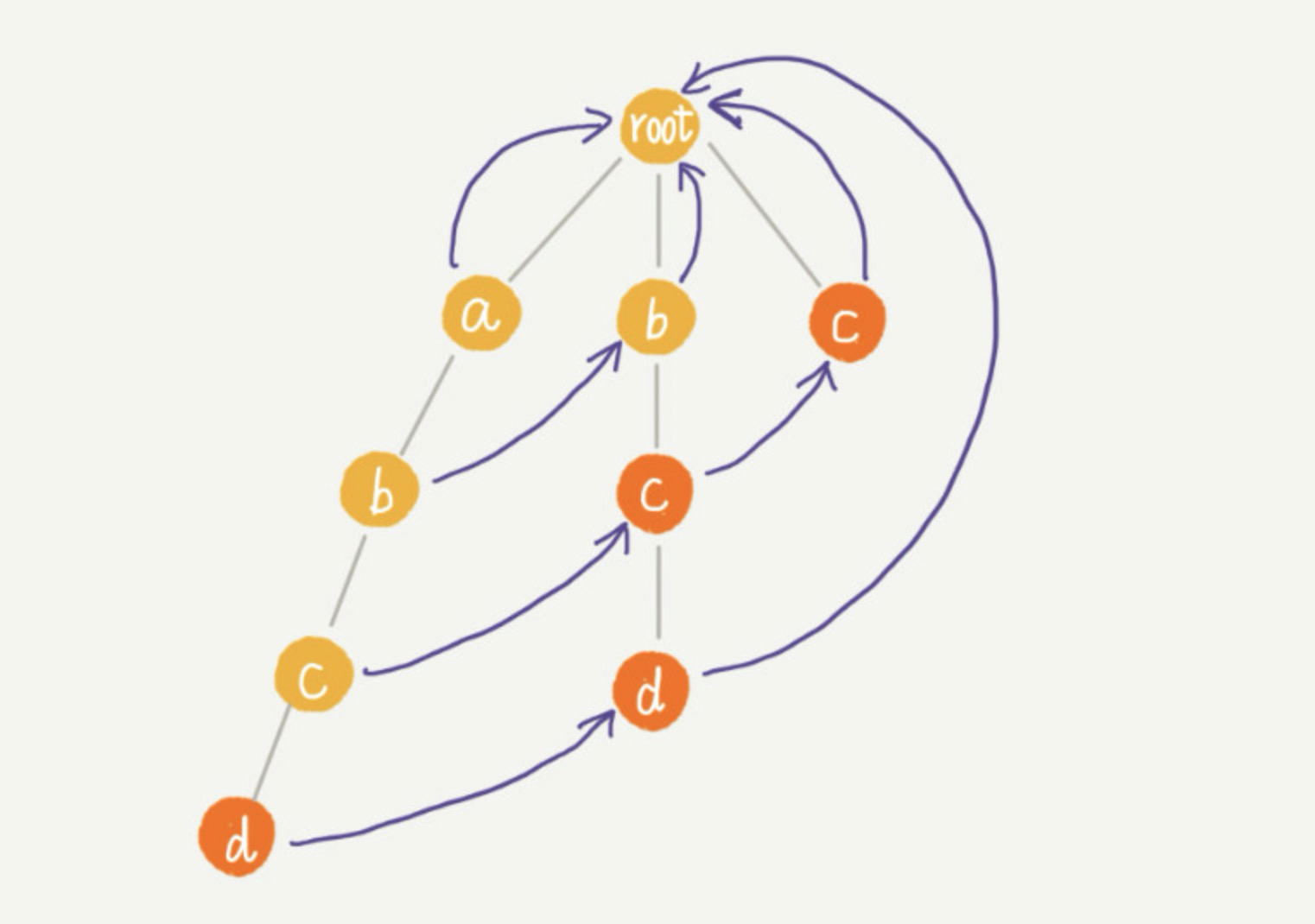
构建失效指针的完整代码如下:
public void buildFailurePointer() {Queue<AcNode> queue = new LinkedList<>();root.fail = null;queue.add(root);while (!queue.isEmpty()) {AcNode p = queue.remove();for (int i = 0; i < 26; ++i) {AcNode pc = p.children[i];if (pc == null) continue;if (p == root) {pc.fail = root;} else {AcNode q = p.fail;while (q != null) {AcNode qc = q.children[pc.data - 'a'];if (qc != null) {pc.fail = qc;break;}q = q.fail;}if (q == null) {pc.fail = root;}}queue.add(pc);}}}
2. 匹配过程
那构建完成后如何在 AC 自动机上匹配主串呢?还是以上图为例。在匹配过程中,主串从 i=0 开始,AC 自动机从指针 p=root 开始,假设模式串是 b,主串是 a。
- 如果 p 指向的节点有一个等于 b[i] 的子节点 x,我们就更新 p 指向 x,此时我们需要通过失败指针,检测一系列失败指针为结尾的路径是否是模式串。处理完之后,我们将 i 加一,继续这两个过程。
- **如果 p 指向的节点没有等于 b[i] 的子节点,通过失败指针,我们让 p=p->
匹配过程的代码实现如下:
// text是主串public void match(char[] text) {int n = text.length;AcNode p = root;for (int i = 0; i < n; ++i) {int idx = text[i] - 'a';while (p.children[idx] == null && p != root) {// 失败指针发挥作用的地方p = p.fail;}p = p.children[idx];// 如果没有匹配的,从root开始重新匹配if (p == null) {p = root;}AcNode tmp = p;while (tmp != root) { // 打印出可以匹配的模式串if (tmp.isEndingChar == true) {int pos = i-tmp.length+1;System.out.println("匹配起始下标" + pos + "; 长度" + tmp.length);}tmp = tmp.fail;}}}

若有收获,就点个赞吧
0 人点赞
