堆(Heap)是一种特殊的树,只要满足了以下两点要求的树,它就是一个堆。
堆是一个完全二叉树,即除最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
堆中每一个节点的值都必须大于等于(或小于等于)其左右子节点的值。对于每个节点的值都大于等于其左右子节点的堆,叫做大顶堆。对于每个节点的值都小于等于其左右子节点的堆,叫做小顶堆。
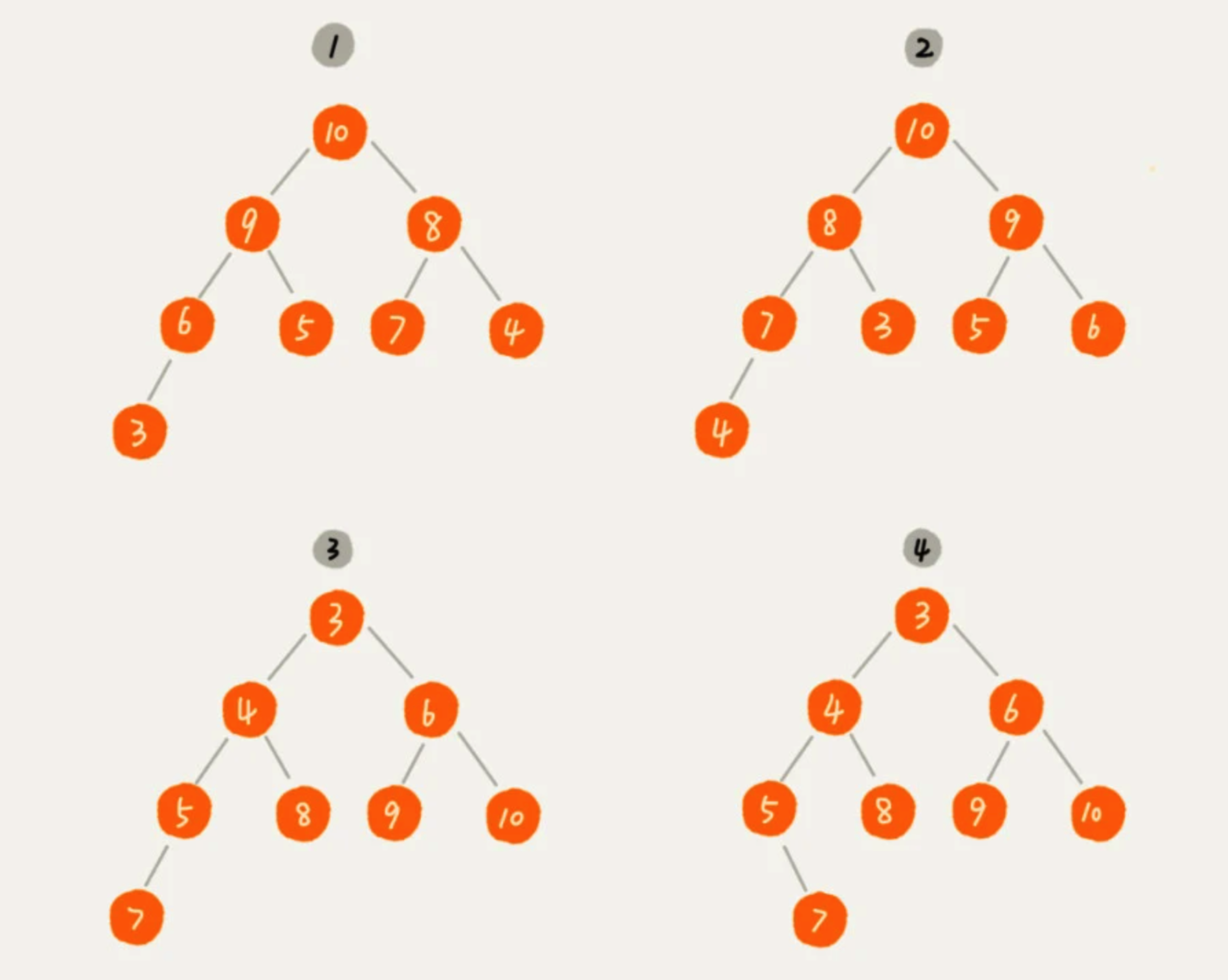
在上图中,第 1 个和第 2 个是大顶堆,第 3 个是小顶堆,第 4 个不是堆。除此之外,还可以从图中看到,对于同一组数据,我们可以构建多种不同形态的堆。
堆的实现
要实现一个堆,我们先要知道,堆都支持哪些操作以及如何存储一个堆。
1. 存储方式
前面讲过,用数组来存储完全二叉树是非常节省存储空间的,因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点,因此我们可以用数组来存储堆。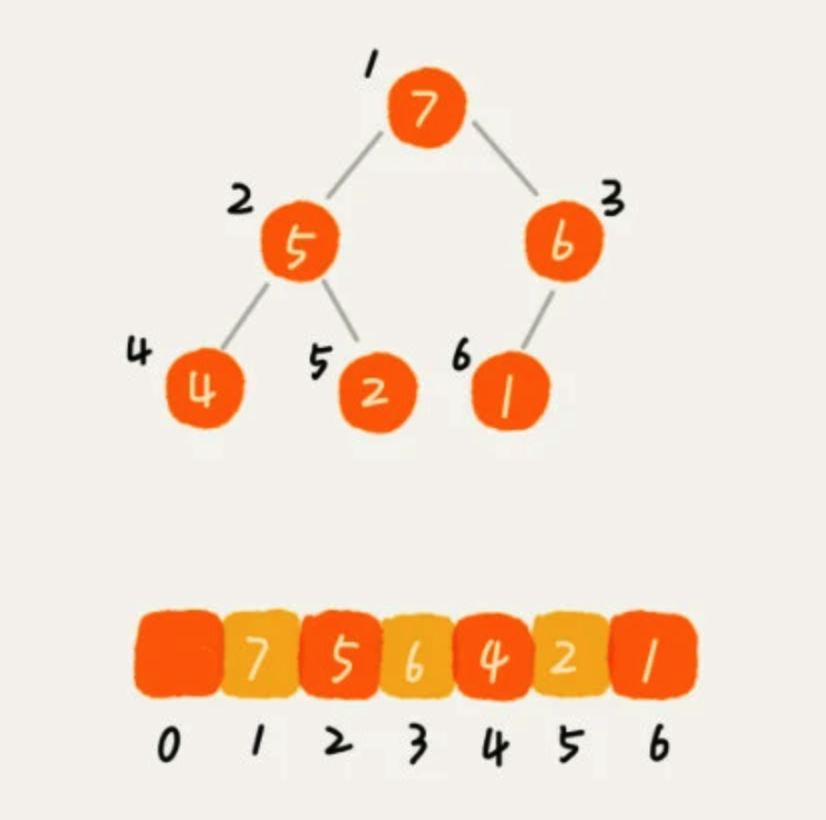
从图中可以看到,数组中下标为 i 的节点的左子节点,就是下标为 i 2 的节点,右子节点就是下标为 i 2 + 1 的节点,父节点就是下标为 i/2 的节点。
2. 插入元素
往堆中插入一个元素后,为了使插入数据后的堆继续满足堆的两个特性,我们就需要进行调整使其重新满足堆的特性,这个过程叫做堆化(heapify)。堆化实际上有两种,从下往上和从上往下。这里讲从下往上的堆化: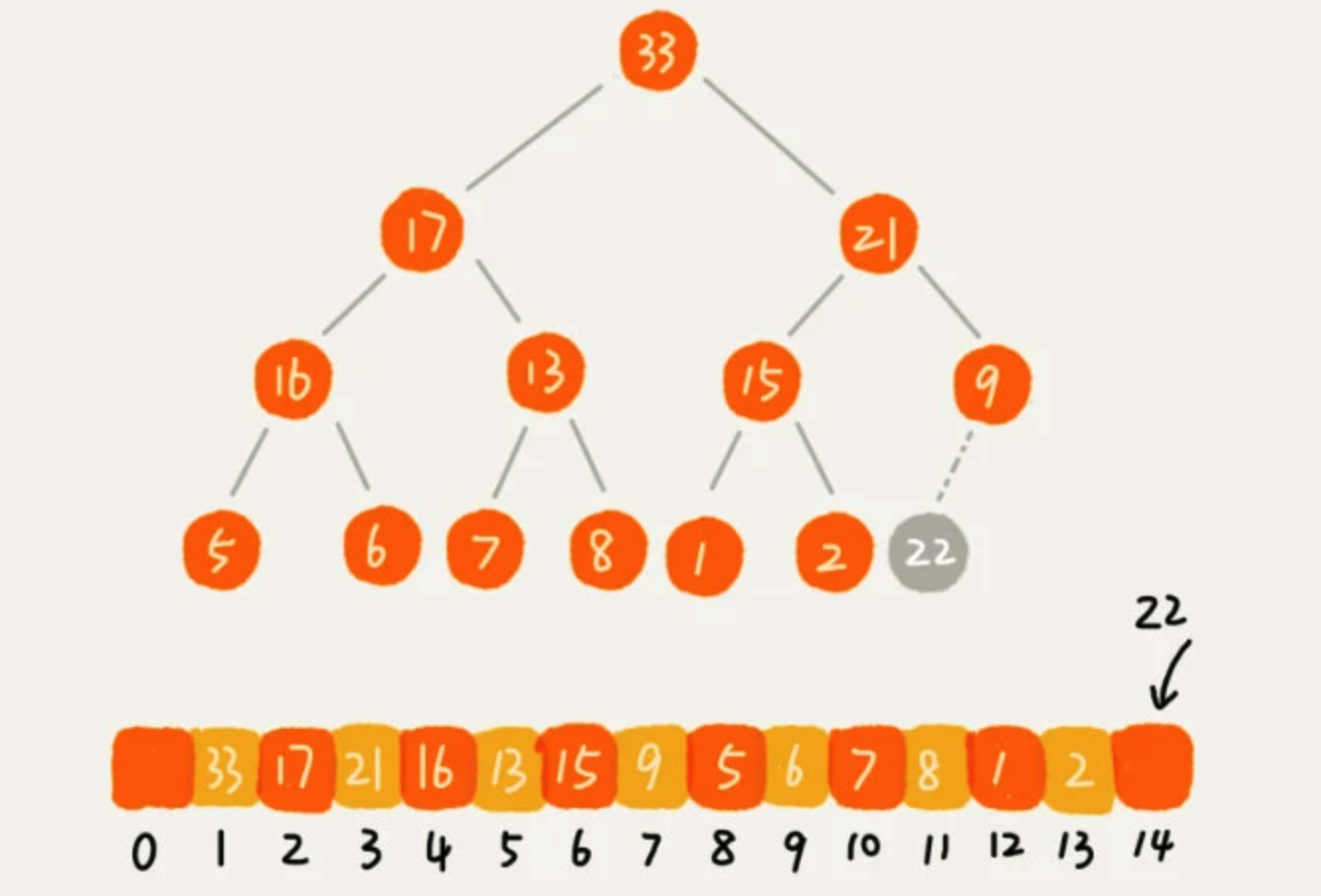
堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比然后交换。我们可以让新插入的节点与父节点比较。如果不满足子节点小于等于父节点的大小关系就互换两个节点。重复这个过程,直到父子节点之间满足刚说的那种大小关系。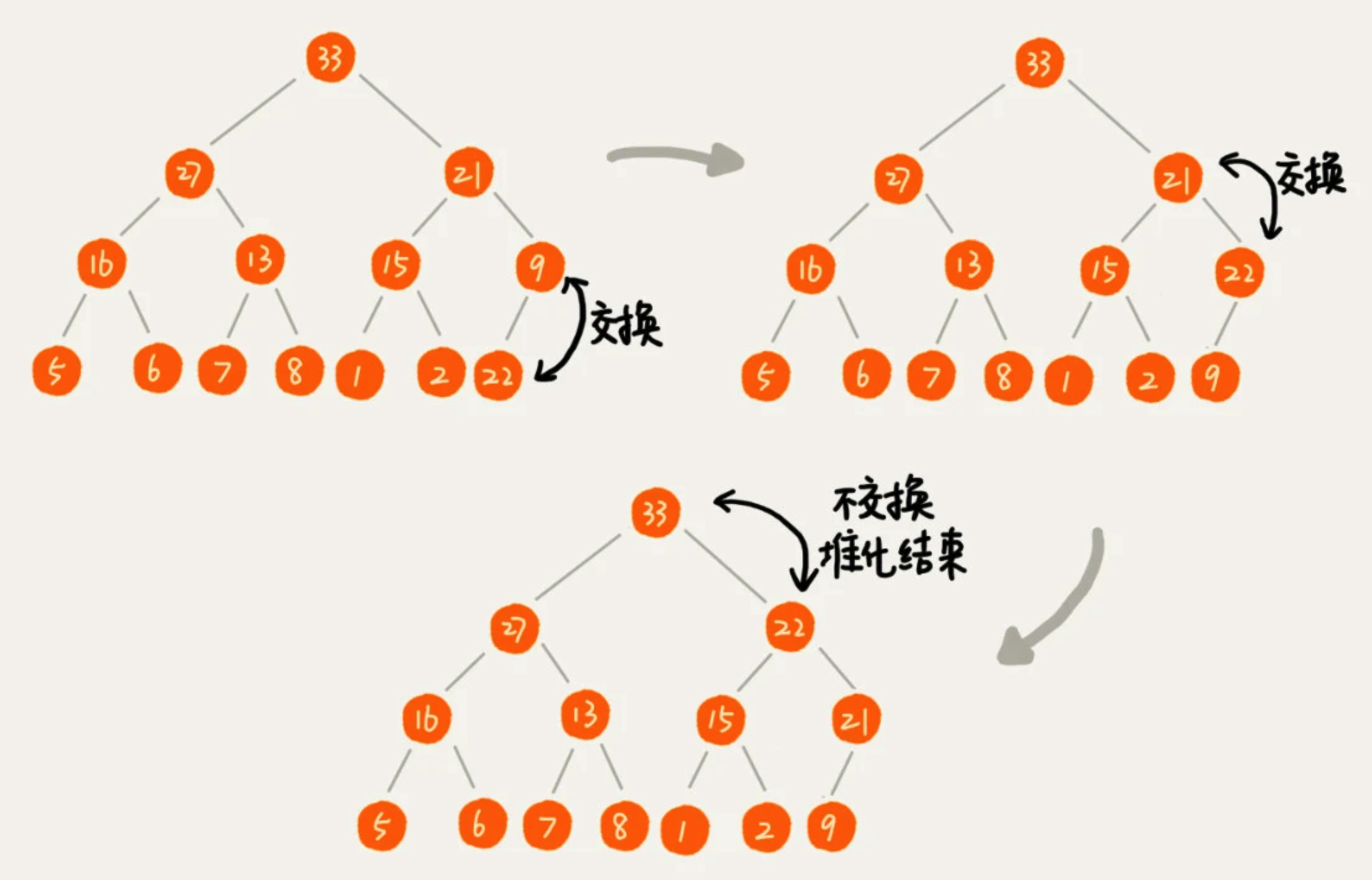
代码实现
public class Heap {// 通过数组来存储堆,最节省内存private final int[] array;// 数组最大容量(假设没有扩缩容)private final int capacity;// 当前已存储的元素个数private int count;public Heap(int capacity) {this.array = new int[capacity];this.capacity = capacity;}/*** 插入元素,从下往上的堆化方法*/public void insertNode(int data) {if (count >= capacity) {return;}// 堆元素数量加一,用来存放新元素count++;// 因为堆从array[1]开始,所以可以直接用count表示堆尾下标array[count] = data;int index = count;// 比较该节点与父节点的大小,这里大于0是因为array[0]不存储堆元素,(除以2可通过右移1位来实现)while (index / 2 > 0 && array[index] > array[index / 2]) {int temp = array[index];array[index] = array[index / 2];array[index / 2] = temp;index = index / 2;}}}
3. 删除堆顶元素
因为堆的任何节点的值都大于等于(或小于等于)子树节点的值,所以堆顶元素存储的就是堆的最大值或最小值。假设我们构造的是大顶堆,堆顶元素是最大的元素。当我们删除堆顶元素之后,就需要把第二大的元素放到堆顶,那第二大元素肯定会出现在左右子节点中。然后我们再迭代地删除第二大节点,以此类推,直到叶子节点被删除。如下图所示: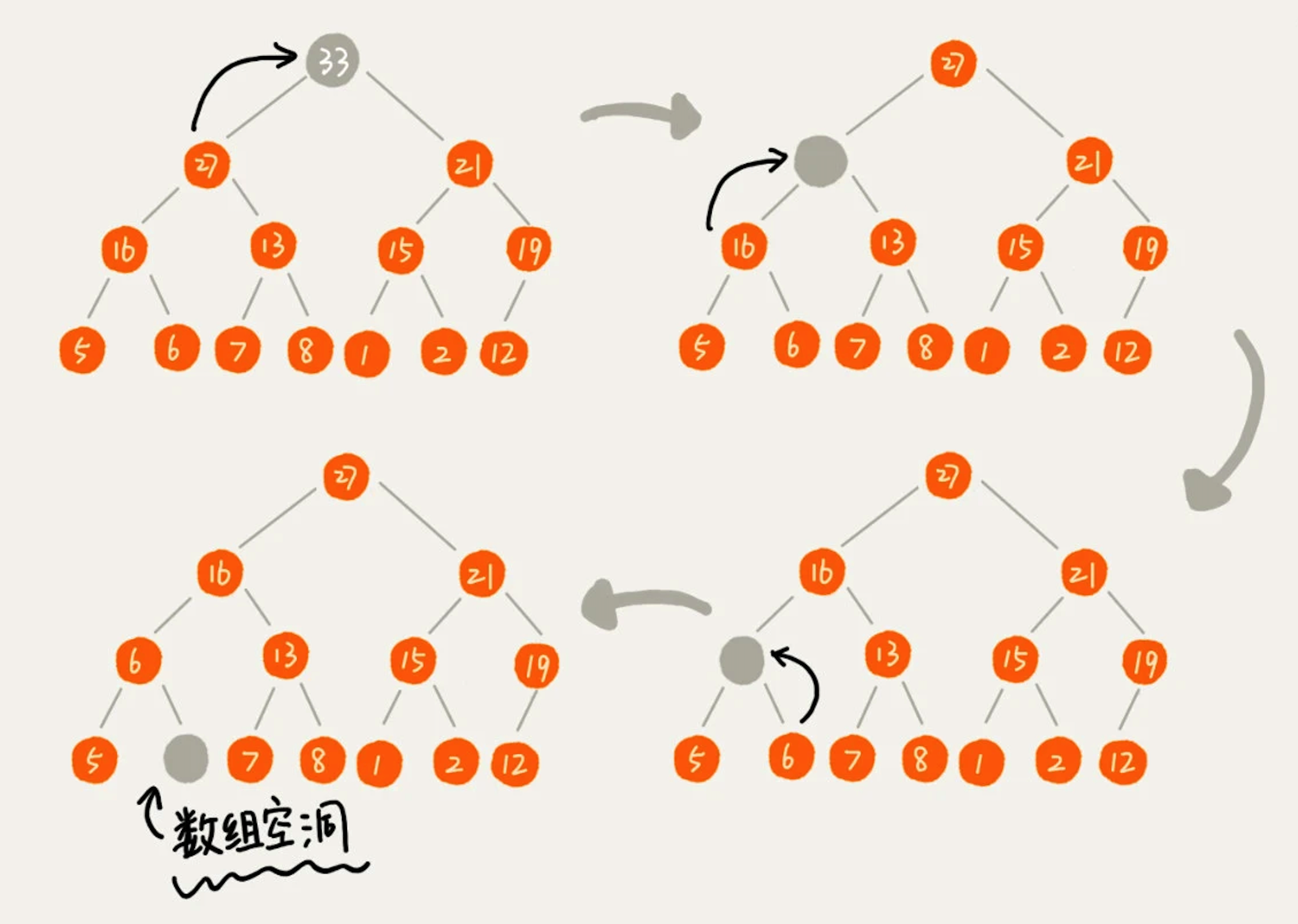
实际上,上图中的这种方法是有点问题的,就是最后堆化出来的堆会有数组空洞,不满足完全二叉树的特性。实际上,我们稍微改变下思路就可以解决这个问题。
从上往下的堆化方法
如下图所示:我们把最后一个节点放到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的,互换两个节点,重复该过程直到父子节点之间满足大小关系。这就是从上往下的堆化方法。因为我们移除的是数组中的最后一个元素,而在堆化的过程中,都是交换操作,不会出现数组空洞,所以这种方法堆化之后的结果,肯定满足完全二叉树的特性。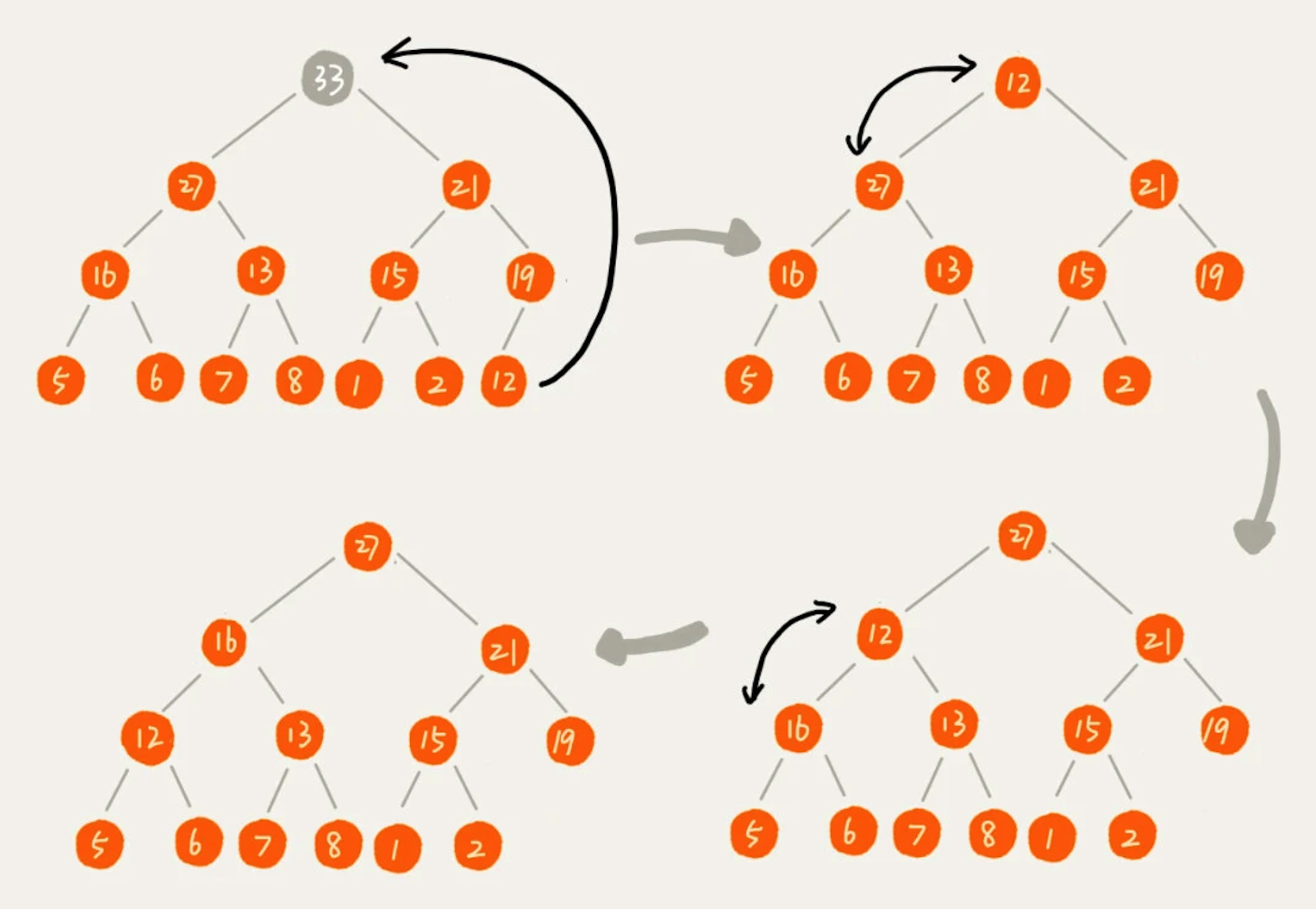
代码实现
public void removeTopNode() {if (count == 0) {return;}// 交换堆顶和堆尾元素,count减1,相当于删除数组最后一个元素,这样不会出现数组空洞array[1] = array[count];count--;// 从堆顶节点开始往下比较与子节点的大小,堆顶下标从1开始int i = 1;while (true) {int maxIndex = i;// 先比较左子节点,如果左子节点大于父节点,则标记maxIndex为左子节点索引if (i * 2 <= count && array[i] < array[i * 2]) {maxIndex = i * 2;}// 再比较右子节点,判断左右子节点哪个大,然后更新maxIndexif (i * 2 + 1 <= count && array[maxIndex] < array[i * 2 + 1]) {maxIndex = i * 2 + 1;}// 只有一个节点if (maxIndex == i) {break;}// 将父节点与左右子节点中最大的节点进行交换int temp = array[i];array[i] = array[maxIndex];array[maxIndex] = temp;// 更新父节点i = maxIndex;}}
我们知道,一个包含 n 个节点的完全二叉树的高度不超过 log2n。堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,也就是 O(logn)。而插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度也都是 O(logn)。
堆的应用
1. 优先级队列
优先级队列是一个特殊的队列。我们知道,队列最大的特性就是先进先出。但在优先级队列中,数据的出队顺序不是先进先出,而是按照优先级来,优先级最高的最先出队。
实现一个优先级队列的方法有很多,但是用堆来实现是最直接高效的。因为堆和优先级队列非常相似。一个堆就可以看作一个优先级队列。很多时候,它们只是概念上的区分而已。往优先级队列中插入一个元素,就相当于往堆中插入一个元素;从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素。
优先级队列的应用场景非常多。比如图的最短路径、最小生成树算法等。不仅如此,很多语言都提供了优先级队列的实现,比如,Java 的 PriorityQueue。下面我们看两个应用优先级队列的具体例子。
合并有序小文件
假设我们有 100 个小文件,每个文件的大小是 100MB,每个文件中存储的都是有序的字符串。我们希望将这些 100 个小文件合并成一个有序的大文件。这里就会用到优先级队列。整体思路有点像归并排序中的合并函数。我们从这 100 个文件中,各取第一个字符串,放入数组中,然后比较大小,把最小的那个字符串放入合并后的大文件中,并从数组中删除。假设,这个最小的字符串来自于 13.txt 这个小文件,我们就再从这个小文件取下一个字符串,放到数组中,重新比较大小,并且选择最小的放入合并后的大文件,将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
这里我们用数组这种数据结构,来存储从小文件中取出来的字符串。每次从数组中取最小字符串,都需要循环遍历整个数组,显然并不高效。这里就可以用到优先级队列,也可以说是堆。我们将从小文件中取出来的字符串放入到小顶堆中,那堆顶的元素,也就是优先级队列队首的元素,就是最小的字符串。我们将这个字符串放入到大文件中,并将其从堆中删除。然后再从小文件中取出下一个字符串,放入到堆中。循环这个过程,就可以将 100 个小文件中的数据依次放入到大文件中。
高性能定时器
假设我们有一个定时器,定时器中维护了很多定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间(比如 1 秒),就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达就拿出来执行。但这样每过 1 秒就扫描一遍任务列表的做法比较低效,主要原因有两点:第一,任务的约定执行时间离当前时间可能还有很久,这样前面很多次扫描其实都是徒劳的;第二,每次都要扫描整个任务列表,如果任务列表很大会比较耗时。
针对这些问题,我们就可以用优先级队列来解决。我们把这些任务按设定的执行时间存储在优先级队列中,队首(也就是小顶堆的堆顶)存储的是最先执行的任务。这样定时器就不需要每隔 1 秒扫描一遍任务列表了。它拿队首任务的执行时间点与当前时间点相减,得到一个时间间隔T。这个时间间隔 T 就是,从当前时间开始需要等待多久,才有第一个任务需要被执行。这样,定时器就可以设定在 T 秒后再来执行任务。当 T 秒时间过去后,定时器取优先级队列中队首的任务执行。然后再根据新的队首任务的执行时间点计算T,把这个值作为定时器执行下一个任务需要等待的时间。这样定时器就不用间隔 1 秒就轮询,也不用遍历整个任务列表了。
2. 利用堆求 Top K
Top K 的问题一般分成两类:一类是针对静态数据集合,也就是说数据集合中的元素是事先确定的,不会改变。另一类是针对动态数据集合,也就是说数据集合中的元素是事先并不确定,有数据会动态地加入到集合中。
针对静态数据,如何在包含 n 个元素的数组中查找前 K 大数据?
我们可以维护一个大小为 K的小顶堆,顺序遍历数组,从数组中取出数据与堆顶元素比较。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆顶位置,再进行堆化(删除堆顶的前提是堆已经满了);如果比堆顶元素小则不处理,继续遍历数组。这样等数组中的数据都遍历完之后,堆中的数据就是前 K 大数据了。遍历数组需要 O(n) 的时间复杂度,一次堆化操作需要 O(logK) 的时间复杂度,所以最坏情况下,n 个元素都入堆一次,时间复杂度就是 O(nlogK)。
动态数据如何实时求 Top K?
假设一个数据集合中有两个操作,一个是添加数据,另一个是获取当前的前 K 大数据。如果每次获取前 K 大数据都基于当前的数据重新计算的话,那时间复杂度就是 O(nlogK)。
其实我们可以维护一个 K大小的小顶堆,当有数据被添加到集合中时,我们就拿它与堆顶的元素对比。如果比堆顶元素大就把堆顶元素删除,并将这个元素插入到堆顶位置,再进行堆化(删除堆顶的前提是堆已经满了);如果比堆顶元素小则不处理。这样,无论任何时候需要查询当前的前 K 大数据,我们都可以立刻返回。
3. 利用堆求中位数
下面我们讲下,如何求动态数据集合中的中位数。中位数就是处在中间位置的那个数。对于一个有序数组,如果数据个数是奇数,那第 n/2+1 就是中位数;如果数据个数是偶数,那处于中间位置的数据有两个,第 n/2个和第 n/2+1,此时我们可以随意取一个作为中位数。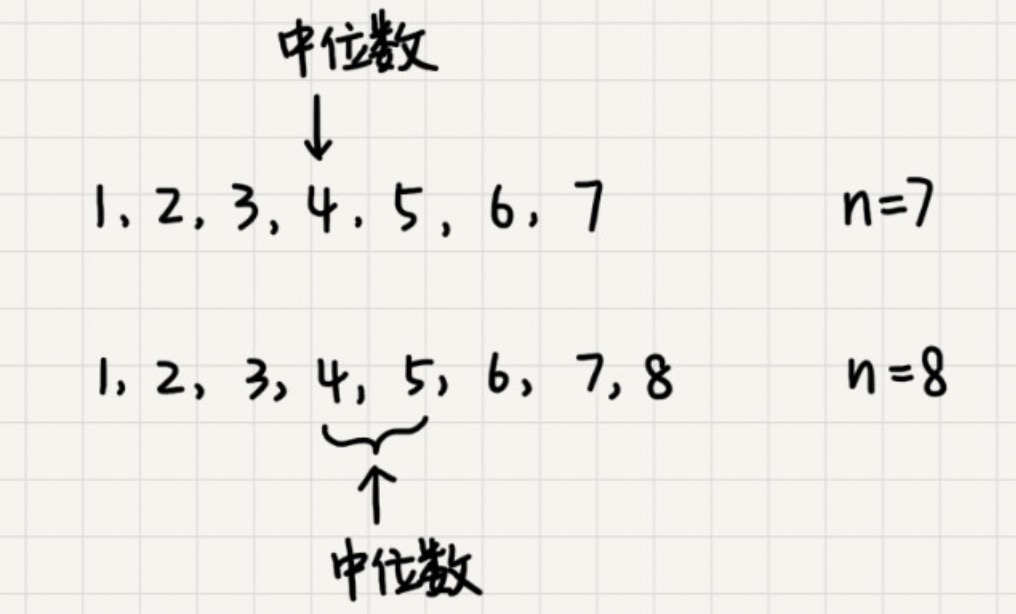
对于一组静态数据,中位数是固定的,我们可以先排序,第 n/2 个数据就是中位数。每次询问中位数的时候,我们直接返回这个固定的值就好了。但对于动态数据来说,中位数不停在变动,那要如何实时获取中位数呢?
借助堆这种数据结构,我们不用排序就可以非常高效地实现求中位数操作。我们需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。如果有 n 个数据,n 是偶数,我们从小到大排序,那前 n/2 个数据存储在大顶堆中,后 n/2 个数据存储在小顶堆中,这样大顶堆中的堆顶元素就是中位数。如果 n 是奇数,那大顶堆就存储 n/2+1 个数据,小顶堆中就存储 n/2 个数据,同样大顶堆中的堆顶元素就是中位数。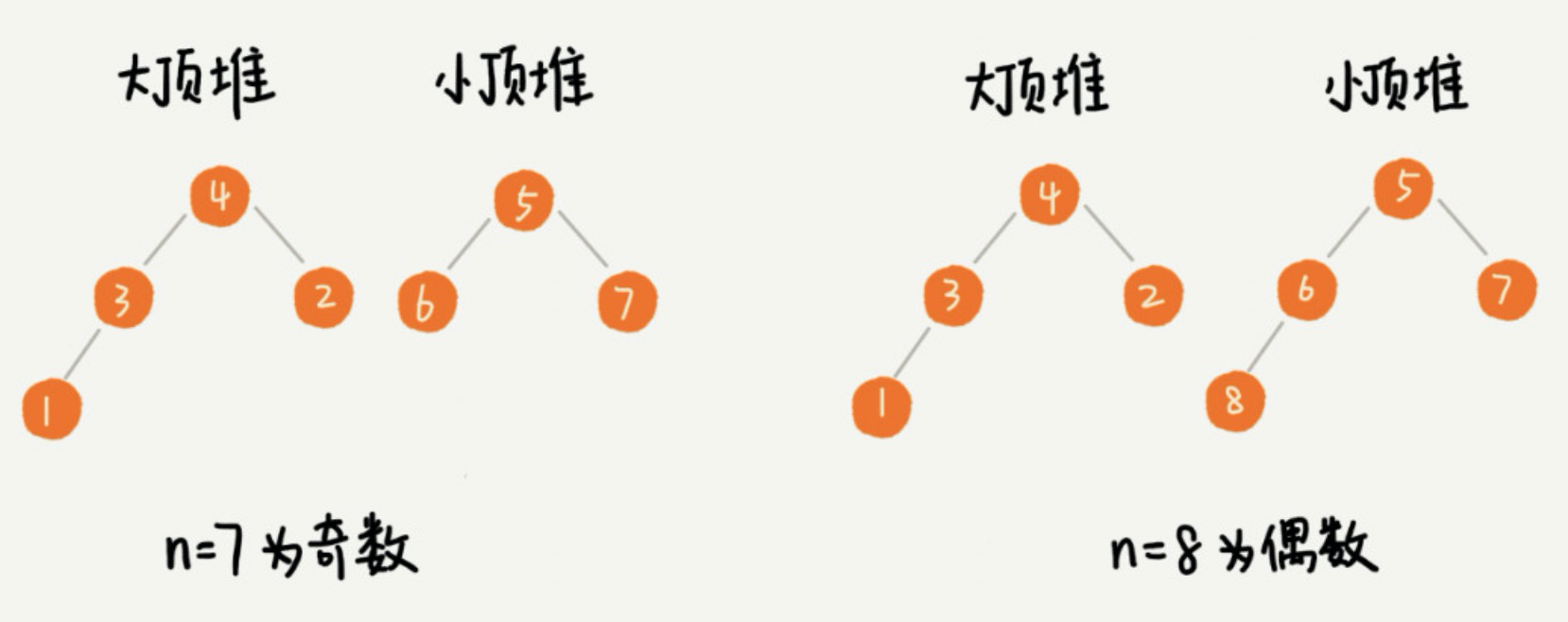
由于数据是动态变化的,当新添加一个数据时,我们需要调整两个堆,让大顶堆中的堆顶元素继续是中位数。如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;否则就将这个新数据插入到小顶堆。但插入后,两个堆中的数据个数就不符合前面约定的情况了。此时,我们需要重新比较大顶堆和小顶堆中元素的个数,把一个堆中的堆顶元素移动到另一个堆里,通过这样的调整来让两个堆中的数据满足上面的约定。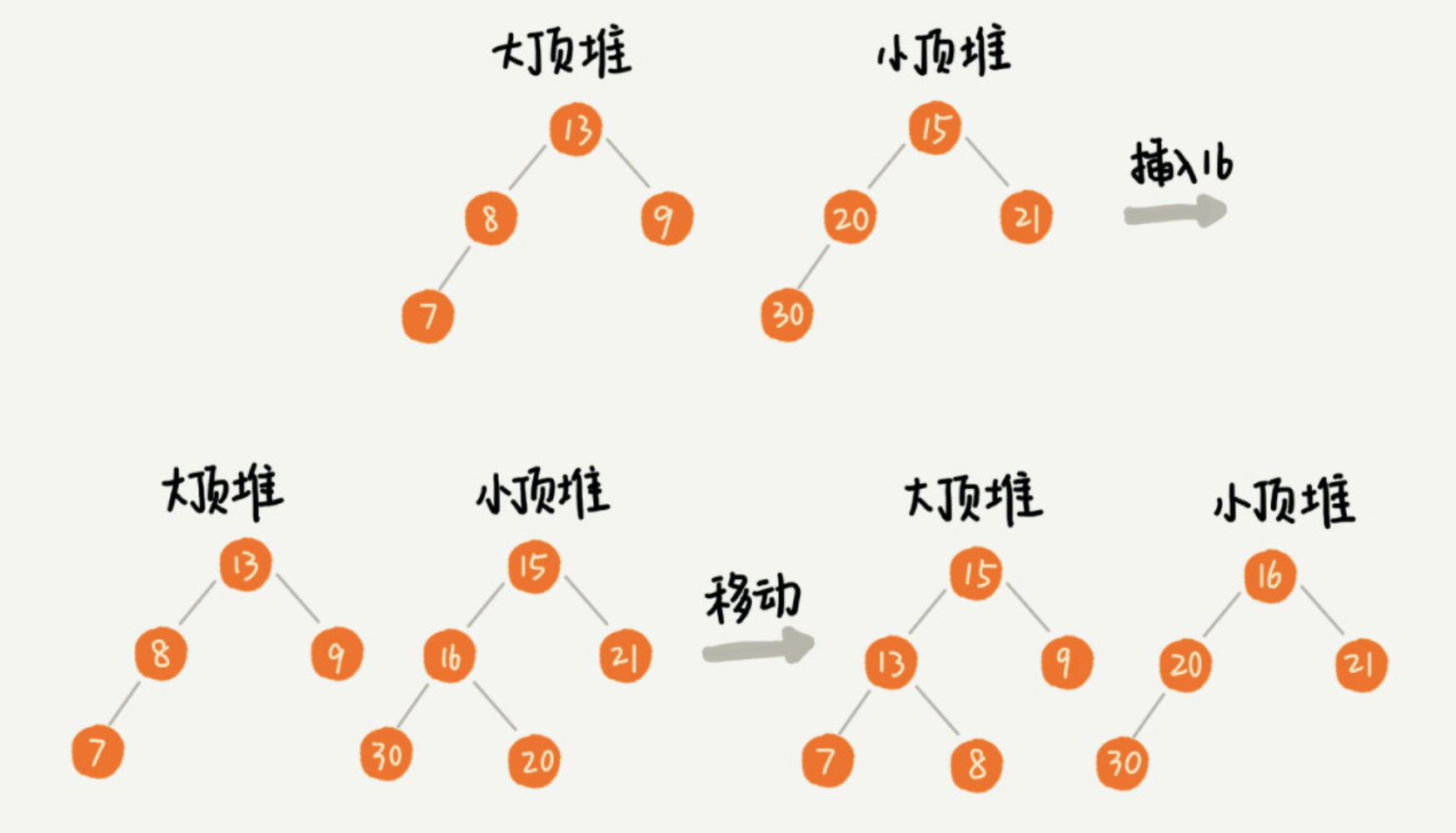
于是,我们可以利用两个堆,一个大顶堆、一个小顶堆,实现在动态数据集合中求中位数的操作。插入数据因为需要涉及堆化,所以时间复杂度变成了 O(logn),但是求中位数我们只需要返回大顶堆的堆顶元素就可以了,时间复杂度是 O(1)。
求中位数问题的变形
求中位数实际上还有很多变形,比如求 99 百分位数据、90 百分位数据等,处理思路都是一样的,即利用两个堆,一个大顶堆,一个小顶堆,随着数据的动态添加而动态调整两个堆中的数据,最后大顶堆的堆顶元素就是要求的数据。以求 99 百分位数据为例进行讲解:
我们维护两个堆,一个大顶堆,一个小顶堆。假设当前总数据的个数是 n,大顶堆中保存 n99% 个数据,小顶堆中保存 n1% 个数据。大顶堆堆顶的数据就是我们要找的 99% 响应时间。每次插入一个数据的时候,我们要判断这个数据跟大顶堆和小顶堆堆顶数据的大小关系,然后决定插入到哪个堆中。如果这个新插入的数据比大顶堆的堆顶数据小,那就插入大顶堆;如果这个新插入的数据比小顶堆的堆顶数据大,那就插入小顶堆。但是,为了保持大顶堆中的数据占 99%,小顶堆中的数据占 1%,在每次新插入数据之后,我们都要重新计算,这个时候大顶堆和小顶堆中的数据个数,是否还符合 99:1 这个比例。如果不符合,我们就将一个堆中的数据移动到另一个堆,直到满足这个比例。移动的方法类似前面求中位数的方法。
通过这样的方法,每次插入数据,可能会涉及几个数据的堆化操作,所以时间复杂度是 O(logn)。每次求 99% 响应时间的时候,直接返回大顶堆中的堆顶数据即可,时间复杂度是 O(1)。

若有收获,就点个赞吧
0 人点赞
