1.1 目标
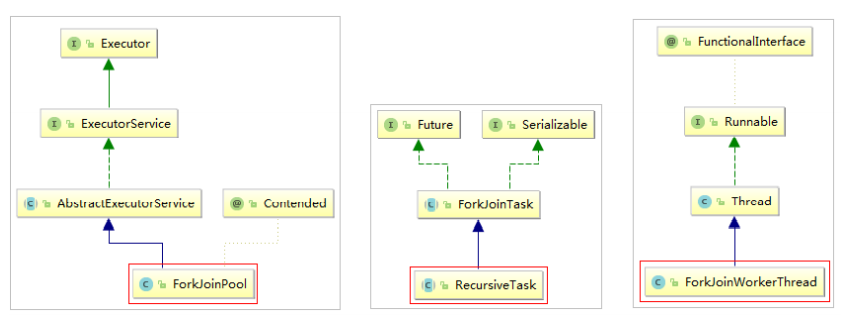
1.2 Fork/Join框架介绍
parallelStream使用的是Fork/Join框架。Fork/Join框架自JDK 7引入。Fork/Join框架可以将一个大任务拆分为很多小
任务来异步执行。 Fork/Join框架主要包含三个模块:
1. 线程池:ForkJoinPool
2. 任务对象:ForkJoinTask
3. 执行任务的线程:ForkJoinWorkerThread
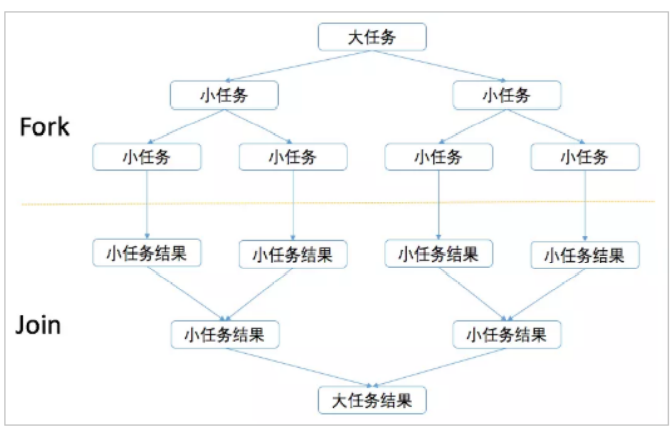
1.3 Fork/Join原理-分治法
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法,
ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成
两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处
理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停
止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在
于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
1.4 Fork/Join原理-工作窃取算法
Fork/Join最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的
cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个Fork/Join框架的核心理念
Fork/Join工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
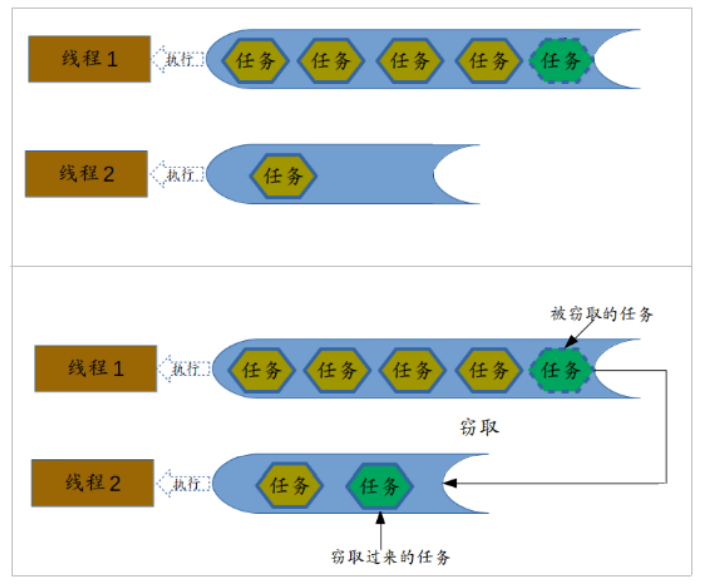
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖
的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来
执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的
任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就
去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任
务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永
远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,
比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
上文中已经提到了在Java 8引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,也就是我
们使用了ForkJoinPool的ParallelStream。
对于ForkJoinPool通用线程池的线程数量,通常使用默认值就可以了,即运行时计算机的处理器数量。可以通过设置
系统属性:java.util.concurrent.ForkJoinPool.common.parallelism=N (N为线程数量),来调整ForkJoinPool的线
程数量,可以尝试调整成不同的参数来观察每次的输出结果。
1.5 小结
1. 介绍了Fork/Join框架,他是JDK7推出的一套新的线程框架
2. Fork/Join框架-分治法,工作窃取算法

若有收获,就点个赞吧
0 人点赞
