- 1.1 Stream流的forEach方法
- 1.2 Stream流的count方法
- 1.3 Stream流的filter方法
- 1.4 Stream流的limit方法
- ">
- 1.5 Stream流的skip方法
- ">
- 1.6 Stream流的map方法
- 1.7 Stream流的sorted方法
- 1.8 Stream流的distinct方法
- 1.9 Stream流的match方法
- 2.0 Stream流的find方法
- 2.1 Stream流的max和min方法
- 2.2 Stream流的reduce方法
- 2.3 Stream流的map和reduce组合使用
- 2.4 Stream流的mapToInt
- 2.5 Stream流的concat方法
- 2.6 Stream综合案例
1.1 Stream流的forEach方法
forEach 用来遍历流中的数据

该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。例如:
@Testpublic void testForEach() {List<String> one = new ArrayList<>();Collections.addAll(one, "迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");/*// 得到流// 调用流中的方法one.stream().forEach((String str) -> {System.out.println(str);});// Lambda可以省略one.stream().forEach(str -> System.out.println(str));*/// Lambda可以转成方法引用one.stream().forEach(System.out::println);}
1.2 Stream流的count方法
Stream流提供 count 方法来统计其中的元素个数:

该方法返回一个long值代表元素个数。基本使用:

@Testpublic void testCount() {List<String> one = new ArrayList<>();Collections.addAll(one, "迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");long count = one.stream().count();System.out.println(count);}
1.3 Stream流的filter方法
filter用于过滤数据,返回符合过滤条件的数据
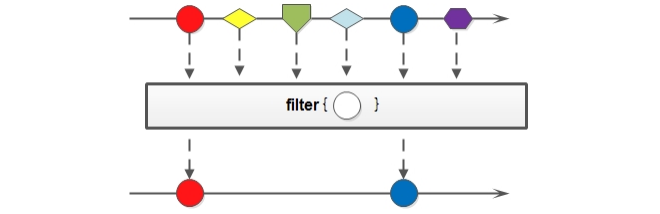
可以通过 filter 方法将一个流转换成另一个子集流。方法声明:

该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
Stream流中的 filter 方法基本使用的代码如:

@Testpublic void testFilter() {List<String> one = new ArrayList<>();Collections.addAll(one, "迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");// 得到名字长度为3个字的人(过滤)// filter(Predicate<? super T> predicate)/*one.stream().filter((String s) -> {return s.length() == 3;}).forEach(System.out::println);*/// one.stream().filter(s -> s.length() == 3).forEach(System.out::println);}
在这里通过Lambda表达式来指定了筛选的条件:姓名长度为2个字。
1.4 Stream流的limit方法
limit 方法可以对流进行截取,只取用前n个。方法签名:

参数是一个long型,如果集合当前长度大于参数则进行截取。否则不进行操作。
基本使用:

@Testpublic void testLimit() {List<String> one = new ArrayList<>();Collections.addAll(one, "迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");// 获取前3个数据one.stream().limit(3).forEach(System.out::println);}
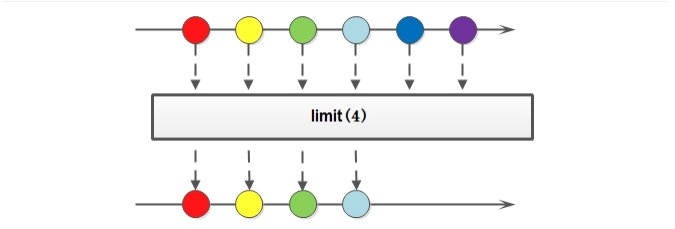
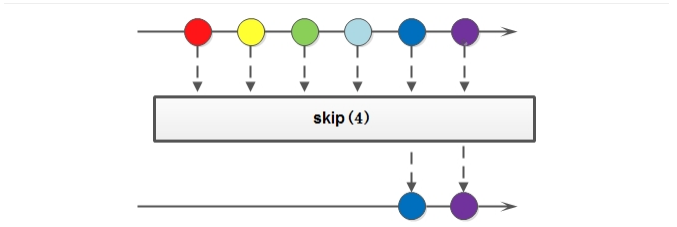
1.5 Stream流的skip方法
如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:

如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:

@Testpublic void testSkip() {List<String> one = new ArrayList<>();Collections.addAll(one, "迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");// 跳过前两个数据one.stream().skip(2).forEach(System.out::println);}
1.6 Stream流的map方法
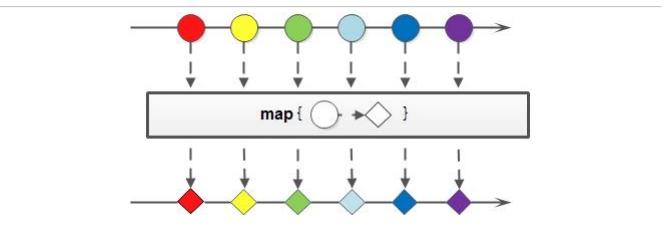
如果需要将流中的元素映射到另一个流中,可以使用 map 方法。方法签名:

该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
Stream流中的 map 方法基本使用的代码如:

@Testpublic void testMap() {Stream<String> original = Stream.of("11", "22", "33");// Map可以将一种类型的流转换成另一种类型的流// 将Stream流中的字符串转成Integer/*Stream<Integer> stream = original.map((String s) -> {return Integer.parseInt(s);});*/// original.map(s -> Integer.parseInt(s)).forEach(System.out::println);original.map(Integer::parseInt).forEach(System.out::println);}
这段代码中, map 方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为 Integer 类对象)。
1.7 Stream流的sorted方法
如果需要将数据排序,可以使用 sorted 方法。方法签名:

基本使用
Stream流中的 sorted 方法基本使用的代码如:

@Testpublic void testSorted() {// sorted(): 根据元素的自然顺序排序// sorted(Comparator<? super T> comparator): 根据比较器指定的规则排序Stream<Integer> stream = Stream.of(33, 22, 11, 55);// stream.sorted().forEach(System.out::println);/*stream.sorted((Integer i1, Integer i2) -> {return i2 - i1;}).forEach(System.out::println);*/stream.sorted((i1, i2) -> i2 - i1).forEach(System.out::println);}
这段代码中, sorted 方法根据元素的自然顺序排序,也可以指定比较器排序。
1.8 Stream流的distinct方法
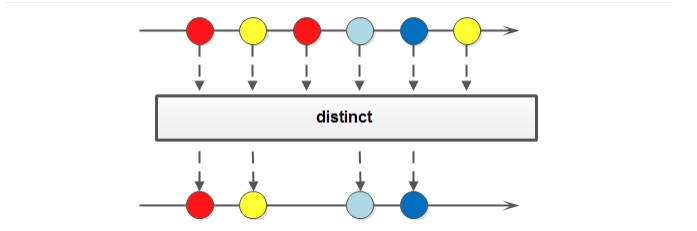
如果需要去除重复数据,可以使用 distinct 方法。方法签名:

基本使用
Stream流中的 distinct 方法基本使用的代码如:

@Testpublic void testDistinct() {Stream<Integer> stream = Stream.of(22, 33, 22, 11, 33);stream.distinct().forEach(System.out::println);Stream<String> stream1 = Stream.of("aa", "bb", "aa", "bb", "cc");stream1.distinct().forEach(System.out::println);}
如果是自定义类型如何是否也能去除重复的数据呢?


// distinct对自定义对象去除重复@Testpublic void testDistinct2() {Stream<Person> stream = Stream.of(new Person("貂蝉", 18),new Person("杨玉环", 20),new Person("杨玉环", 20),new Person("西施", 16),new Person("西施", 16),new Person("王昭君", 25));stream.distinct().forEach(System.out::println);}
自定义类型是根据对象的hashCode和equals来去除重复元素的。
1.9 Stream流的match方法
如果需要判断数据是否匹配指定的条件,可以使用 Match 相关方法。方法签名:

基本使用
Stream流中的 Match 相关方法基本使用的代码如:

@Testpublic void testMatch() {Stream<Integer> stream = Stream.of(5, 3, 6, 1);// boolean b = stream.allMatch(i -> i > 0); // allMatch: 匹配所有元素,所有元素都需要满足条件// boolean b = stream.anyMatch(i -> i > 5); // anyMatch: 匹配某个元素,只要有其中一个元素满足条件即可boolean b = stream.noneMatch(i -> i < 0); // noneMatch: 匹配所有元素,所有元素都不满足条件System.out.println(b);}
2.0 Stream流的find方法
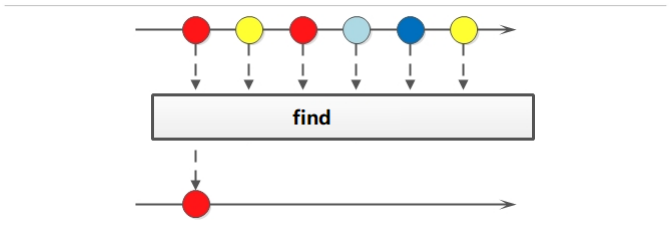
如果需要找到某些数据,可以使用 find 相关方法。方法签名:

基本使用
Stream流中的 find 相关方法基本使用的代码如:

@Testpublic void testFind() {Stream<Integer> stream = Stream.of(33, 11, 22, 5);Optional<Integer> first = stream.findFirst();// Optional<Integer> first = stream.findAny();System.out.println(first.get());}
2.1 Stream流的max和min方法
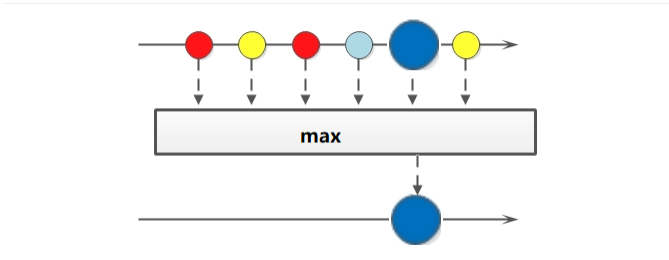
如果需要获取最大和最小值,可以使用 max 和 min 方法。方法签名:

基本使用
Stream流中的 max 和 min 相关方法基本使用的代码如:

@Testpublic void testMax_Min() {// 获取最大值// 1, 3, 5, 6Optional<Integer> max = Stream.of(5, 3, 6, 1).max((o1, o2) -> o1 - o2);System.out.println("最大值: " + max.get());// 获取最小值// 1, 3, 5, 6Optional<Integer> min = Stream.of(5, 3, 6, 1).min((o1, o2) -> o1 - o2);System.out.println("最小值: " + min.get());}
2.2 Stream流的reduce方法

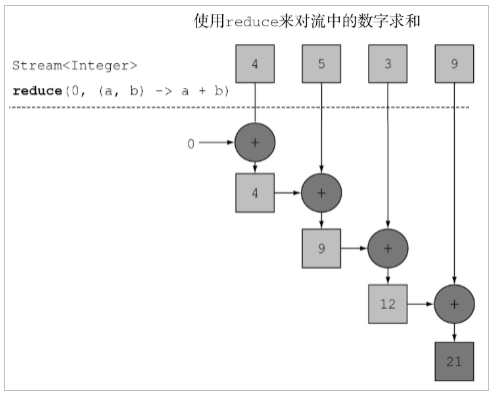
如果需要将所有数据归纳得到一个数据,可以使用 reduce 方法。方法签名:

基本使用
Stream流中的 reduce 相关方法基本使用的代码如:


@Testpublic void testReduce() {// T reduce(T identity, BinaryOperator<T> accumulator);// T identity: 默认值// BinaryOperator<T> accumulator: 对数据进行处理的方式// reduce如何执行?// 第一次, 将默认值赋值给x, 取出集合第一元素赋值给y// 第二次, 将上一次返回的结果赋值x, 取出集合第二元素赋值给y// 第三次, 将上一次返回的结果赋值x, 取出集合第三元素赋值给y// 第四次, 将上一次返回的结果赋值x, 取出集合第四元素赋值给yint reduce = Stream.of(4, 5, 3, 9).reduce(0, (x, y) -> {System.out.println("x = " + x + ", y = " + y);return x + y;});System.out.println("reduce = " + reduce); // 21// 获取最大值Integer max = Stream.of(4, 5, 3, 9).reduce(0, (x, y) -> {return x > y ? x : y;});System.out.println("max = " + max);}
2.3 Stream流的map和reduce组合使用


@Testpublic void testMapReduce() {// 求出所有年龄的总和// 1.得到所有的年龄// 2.让年龄相加Integer totalAge = Stream.of(new Person("刘德华", 58),new Person("张学友", 56),new Person("郭富城", 54),new Person("黎明", 52)).map((p) -> p.getAge()).reduce(0, Integer::sum);System.out.println("totalAge = " + totalAge);// 找出最大年龄// 1.得到所有的年龄// 2.获取最大的年龄Integer maxAge = Stream.of(new Person("刘德华", 58),new Person("张学友", 56),new Person("郭富城", 54),new Person("黎明", 52)).map(p -> p.getAge()).reduce(0, Math::max);System.out.println("maxAge = " + maxAge);// 统计 a 出现的次数// 1 0 0 1 0 1Integer count = Stream.of("a", "c", "b", "a", "b", "a").map(s -> {if (s == "a") {return 1;} else {return 0;}}).reduce(0, Integer::sum);System.out.println("count = " + count);}
2.4 Stream流的mapToInt
如果需要将Stream中的Integer类型数据转成int类型,可以使用 mapToInt 方法。方法签名:

基本使用
Stream流中的 mapToInt 相关方法基本使用的代码如:


@Test
public void testNumericStream() {
// Integer占用的内存比int多,在Stream流操作中会自动装箱和拆箱
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
// 把大于3的打印出来
// stream.filter(n -> n > 3).forEach(System.out::println);
// IntStream mapToInt(ToIntFunction<? super T> mapper);
// IntStream: 内部操作的是int类型的数据,就可以节省内存,减少自动装箱和拆箱
/*IntStream intStream = Stream.of(1, 2, 3, 4, 5).mapToInt((Integer n) -> {
return n.intValue();
});*/
IntStream intStream = Stream.of(1, 2, 3, 4, 5).mapToInt(Integer::intValue);
intStream.filter(n -> n > 3).forEach(System.out::println);
}
2.5 Stream流的concat方法
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :

备注:这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的。
该方法的基本使用代码如:

@Test
public void testContact() {
Stream<String> streamA = Stream.of("张三");
Stream<String> streamB = Stream.of("李四");
// 合并成一个流
Stream<String> newStream = Stream.concat(streamA, streamB);
// 注意:合并流之后,不能操作之前的流啦.
// streamA.forEach(System.out::println);
newStream.forEach(System.out::println);
}
2.6 Stream综合案例
现在有两个 ArrayList 集合存储队伍当中的多个成员姓名,要求使用传统的for循环(或增强for循环)依次进行以下
若干操作步骤:
1. 第一个队伍只要名字为3个字的成员姓名;
2. 第一个队伍筛选之后只要前3个人;
3. 第二个队伍只要姓张的成员姓名;
4. 第二个队伍筛选之后不要前2个人;
5. 将两个队伍合并为一个队伍;
6. 根据姓名创建 Person 对象;
7. 打印整个队伍的Person对象信息。
两个队伍(集合)的代码如下:

而 Person 类的代码为:

传统方式
使用for循环 , 示例代码:


运行结果为:

Stream方式
等效的Stream流式处理代码为:

运行效果完全一样:

package com.itheima.demo05stream;
import java.util.List;
import java.util.stream.Stream;
public class Demo05 {
public static void main(String[] args) {
// 第一个队伍
List<String> one = List.of("迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子", "洪七公");
// 第二个队伍
List<String> two = List.of("古力娜扎", "张无忌", "张三丰", "赵丽颖", "张二狗", "张天爱", "张三");
// 1.第一个队伍只要名字为3个字的成员姓名;
// 2.第一个队伍筛选之后只要前3个人;
Stream<String> streamA = one.stream()
.filter(s -> s.length() == 3)
.limit(3);
// 3.第二个队伍只要姓张的成员姓名;
// 4.第二个队伍筛选之后不要前2个人;
Stream<String> streamB = two.stream()
.filter(s -> s.startsWith("张"))
.skip(2);
// 5.将两个队伍合并为一个队伍;
Stream<String> streamAB = Stream.concat(streamA, streamB);
// 6.根据姓名创建`Person`对象;
// 7.打印整个队伍的Person对象信息。
streamAB.map(Person2::new).forEach(System.out::println);
}
}

若有收获,就点个赞吧
0 人点赞
