需求:使用Fork/Join计算1-10000的和,当一个任务的计算数量大于3000时拆分任务,数量小于3000时计算。
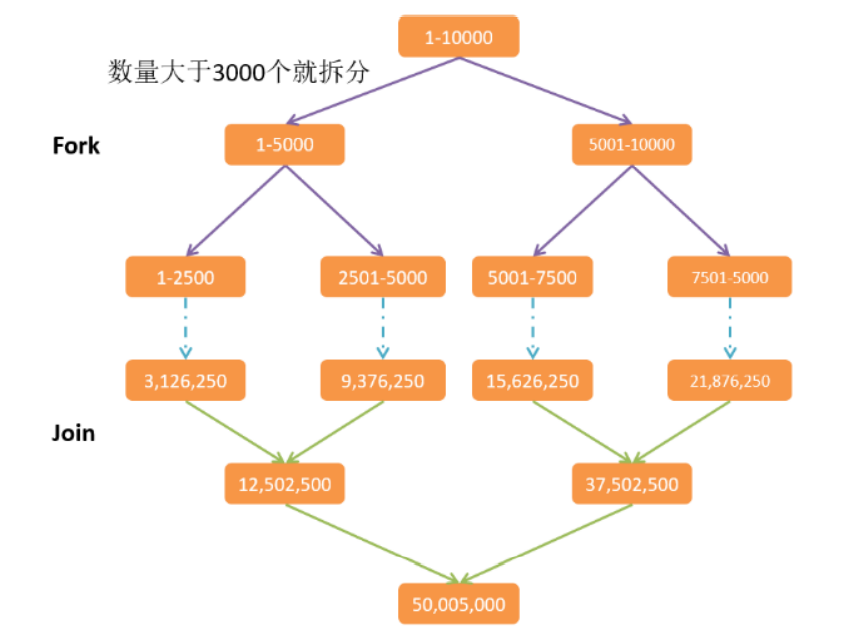
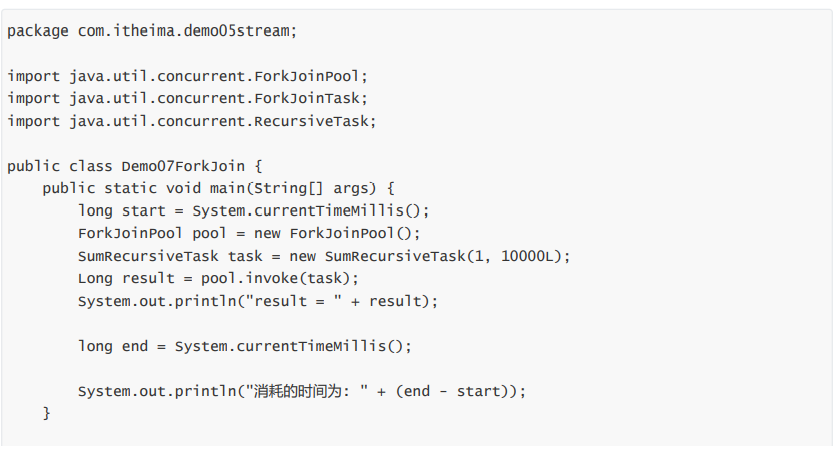

package com.itheima.demo05stream;import java.util.concurrent.ForkJoinPool;import java.util.concurrent.RecursiveTask;public class Demo08ForkJoin {public static void main(String[] args) {long start = System.currentTimeMillis();ForkJoinPool pool = new ForkJoinPool();SumRecursiveTask task = new SumRecursiveTask(1, 99999999999L);Long result = pool.invoke(task);System.out.println("result = " + result);long end = System.currentTimeMillis();System.out.println("消耗时间: " + (end - start));}}// 1.创建一个求和的任务// RecursiveTask: 一个任务class SumRecursiveTask extends RecursiveTask<Long> {// 是否要拆分的临界值private static final long THRESHOLD = 3000L;// 起始值private final long start;// 结束值private final long end;public SumRecursiveTask(long start, long end) {this.start = start;this.end = end;}@Overrideprotected Long compute() {long length = end - start;if (length < THRESHOLD) {// 计算long sum = 0;for (long i = start; i <= end; i++) {sum += i;}return sum;} else {// 拆分long middle = (start + end) / 2;SumRecursiveTask left = new SumRecursiveTask(start, middle);left.fork();SumRecursiveTask right = new SumRecursiveTask(middle + 1, end);right.fork();return left.join() + right.join();}}}
小结
1. parallelStream是线程不安全的
2. parallelStream适用的场景是CPU密集型的,只是做到别浪费CPU,假如本身电脑CPU的负载很大,那还到处用
并行流,那并不能起到作用
3. I/O密集型 磁盘I/O、网络I/O都属于I/O操作,这部分操作是较少消耗CPU资源,一般并行流中不适用于I/O密集
型的操作,就比如使用并流行进行大批量的消息推送,涉及到了大量I/O,使用并行流反而慢了很多
4. 在使用并行流的时候是无法保证元素的顺序的,也就是即使你用了同步集合也只能保证元素都正确但无法保证
其中的顺序

若有收获,就点个赞吧
0 人点赞
