SDS简单动态字符串
Simple Dynamic String,SDS:Redis默认的字符串表示。
使用
当Redis需要一个可以被修改的字符串值时候,就是用SDS。
包含字符串键值对在底层都是由SDS实现。
set msg "hello world"
- K是一个字符串对象,底层是一个保存着”msg”字符串的SDS
- V也是一个字符串对象,底层是保存着”hello world”的SDS
实现
struct sdshdr{// 已使用的字节的数量,即字符串长度int len;// 未使用的字节的数量int free;// 字节数组,用于保存字符串char buf[];}
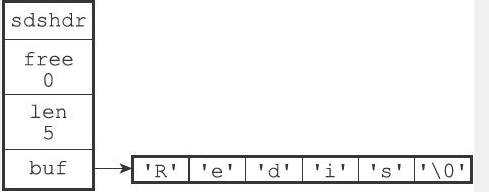
- 最后的那个\0不算在长度里面
- 保存这个\0的目的是可以直接重用C的某些函数
好处
- 杜绝了缓冲区的溢出,API先检查SDS的空间是否满足修改的需要,不满足时候自动扩展空间
- 减少修改字符串时候带来的内存重分配次数
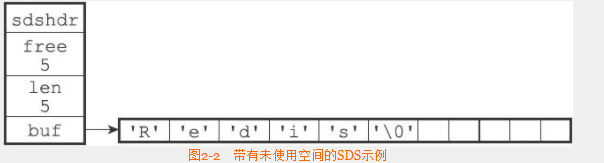
- SDS使用free属性来标识未使用的字节
- 空间预分配
- SDS空间扩展时候,不仅分配需要的空间,还分配额外不会使用的空间。
- 如果修改后,SDS的len小于1MB,那么分配和len同样大小的未使用空间
- 大与1MB,分配1MB的未使用空间
- SDS空间扩展时候,不仅分配需要的空间,还分配额外不会使用的空间。
- 惰性空间释放
- 缩短SDS保存的字符串的时候,并不立即使用内存重分配,而是使用free将这些字节的数量记录下来.
- 二进制安全
- 使用len而不是\0来判断字符串是否结束
- 不会缓冲区溢出
- 获取字符串长度的0(1)
- 兼容部分C字符串函数
链表
typedef struct listNode{struct listNode *pre;struct listNode *next;void *value;}listNode; // 节点双端链表typedef struct list{listNode *head;listNode *tail;long len; // 节点数量....// 复制函数,释放函数,对比函数}list;
双向无环
有自己的头尾指针
记录自己的长度
字典
set msg "hello world"就创建了一个"msg"的键,值为"hello world"的值
实现
struct dictht{// 每个dictEntry保存一个键值对dictEntry **table; // 哈希表数组long size; // 哈希表大小long sizemask;// 大小掩码,计算索引值,总是等于size-1long used;// 已有的节点数量}dictht;struct dictEntry{void *key;union{void *val;int u64;int s64;}v; // 值struct dictEntry *next; //下一个哈希节点,形成链表,解决键冲突};

/** 字典** 每个字典使用两个哈希表,用于实现渐进式 rehash*/typedef struct dict {// 特定于类型的处理函数dictType *type;// 类型处理函数的私有数据void *privdata;// 哈希表(2 个)dictht ht[2];// 记录 rehash 进度的标志,值为 -1 表示 rehash 未进行int rehashidx;// 当前正在运作的安全迭代器数量int iterators;} dict;
0 号哈希表(ht[0])是字典主要使用的哈希表, 而 1 号哈希表(ht[1])则只有在程序对 0 号哈希表进行 rehash 时才使用。没有进行rehash的时候,rehashidx=-1
哈希算法
- 计算hash
- 计算新键的哈希值和索引值
- 将包含键值对的哈希表节点放入对应的索引上
- 使用头插法插入到相应位置
- rehash重新散列
- 为ht[1]分配空间,大小取决于
- 如果执行扩展则:第一个大于等于ht[0].used*2的2n
- 如果执行收缩则:第一个大于等于ht[0].used的2n
- 将所有的ht[0]中的数据逐个放到ht[1]中,需要重新计算hash
- 释放ht[0],将ht[1]置为ht[0],为ht[1]创建新的空白哈希表
- 为ht[1]分配空间,大小取决于
- 渐进式rehash
- 为ht[1]分配空间,让字典同时持有ht[0],ht[1]两个哈希表
- 在字典中维持一个索引计数器rehashidx,并将它的值设置为0,表示rehash工作正式开始.
- 在rehash期间,除了每次正常执行增删改查,还将ht[0]在rehashidx索引上的所有键值对rehash到ht[1]上,完成后rehashidx++
- 随着操作不断进行,最终会rehash完毕,rehashidx设置为-1
- 删改查在两个表上同时进行;增在新表上进行
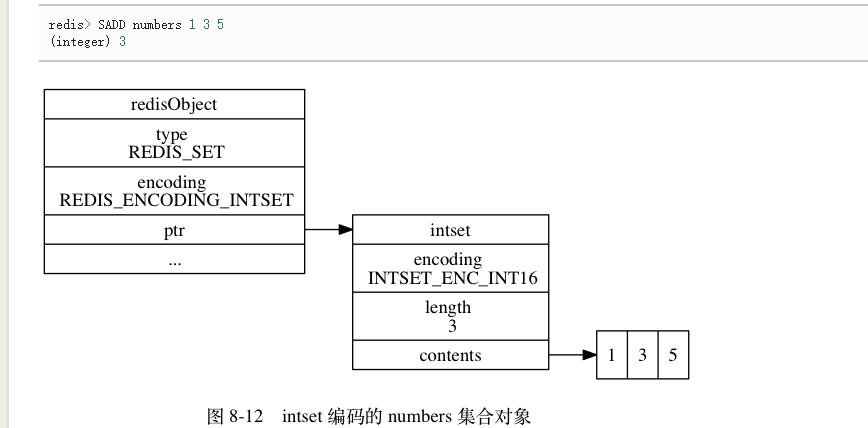
整数集合intset
如果集合中只包含整数数值,并且数量不多,则使用此结构
struct intset{int encoding;// 编码方式int length;// 元素数量int8_t contents[];// 保存元素的数组}
- 集合中的每个元素都是contents的一个项,从小打大排列
- 编码的类型取决于encoding,而不是int8_t,int8_t只是一个标识
- 升级
- 如果现在encoding是int16,这时候加入了int64的数据,则进行数据升级到int64
- 根据新元素的类型,扩展数组的大小
- 将现有的元素转换成新元素的类型,并放置到正确的位置上
- 将新元素加到数组里面
- 不存在数据降级
压缩列表ziplist
压缩列表是列表键和哈希键的底层实现之一.
- 如果列表键只有少量项,并且要么是小整数值,要么是长度比较短的字符串,就会使用压缩列表当做列表键的底层存储.
- 如果哈希键只有少量键值对,并且键\值都是小整数或短字符串,则用压缩列表作为哈希的底层实现
压缩列表记录了:
- 整个压缩列表占用的内存字节数
- 指向压缩列表表尾的指针
- 压缩列表长度
- 压缩列表存放的各个节点
- 包括了
- 当前节点前一个节点的长度:允许根据当前节点起始地址计算出前一个节点的起始地址
- encoding保存数据类型
- content记录了保存节点的值
- 包括了
连锁更新
因为当前节点前一个节点的长度,当:
前一个节点的长度小于254字节使用1字节来保存这个长度,
前一个节点的长度大于等于254字节使用5字节来保存
此时,压缩列表有多个连续250-253字节长度的节点,这个时候在其前方插入一个254字节长以上的节点,则其后的若干连续的长250-253字节的节点都将触发扩展,产生”连锁更新”,每个节点触发的更新耗时N,则连锁更新触发耗时为0(N2)
- 连锁更新触发的条件比较苛刻,所以一般来说不会影响性能
删除的时候也是一样.
对象
字符串对象
字符串对象的编码可以是int/raw/embstr
- 如果对象保存的是整数值long,使用int编码(浮点数值用下面两种方式保存)
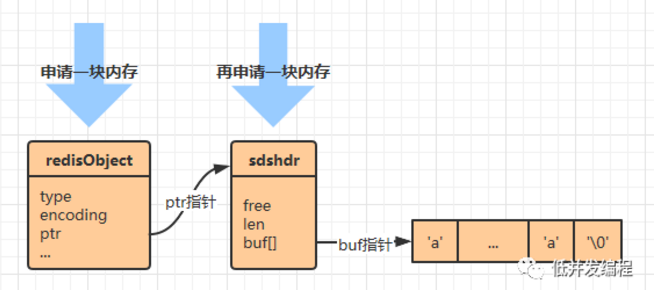
- 如果是一个字符串值,并且长度大于39字节,使用sds来保存,编码设置为raw
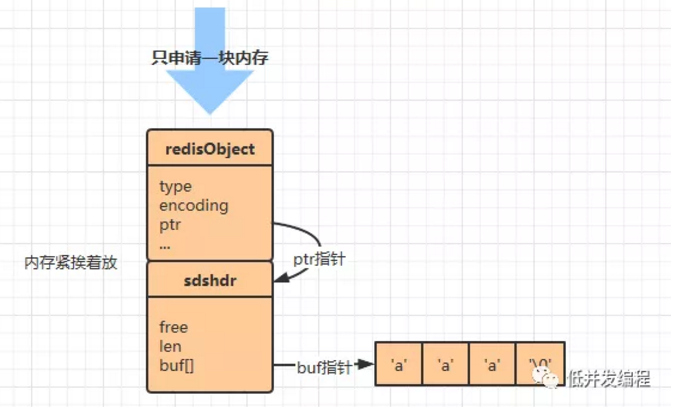
- 如果是一个字符串值,并且长度小于等于39字节,使用sds来保存,编码设置为embstr
- embstr是针对短字符串的优化方式
- raw使用两次内存分配来创建字符串对象,embstr使用一次(因为embstr使用连续内存,所以分配一次就行嘞)
- embstr是只读的,如果修改,则需要先将其转换为raw
列表对象
列表的编码可以是
- 压缩列表ziplist
- 每个压缩列表节点存一个列表元素
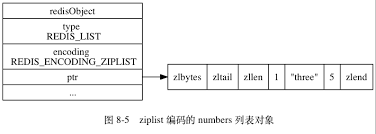
- 双向链表linkedlist
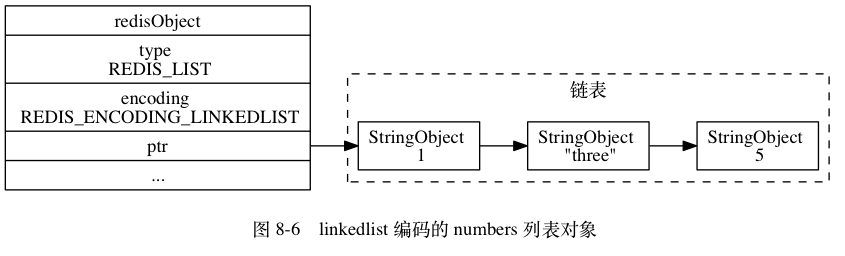
如果满足两个条件:
- 列表中的所有字符串元素都小于64字节
- 列表保存的元素数量小于512个
则使用ziplist,否则使用linkedlist
哈希对象
底层可以是ziplist/hashtable
使用ziplist:
- 先将保存了键的压缩列表的节点推入压缩列表表尾
- 再将保存了值的压缩列表节点推入表尾
所以,同一个键值对总是挨在一起的.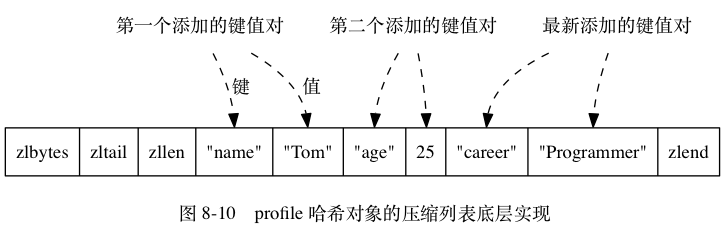 .
.
使用hashtable:
使用字典作为底层实现,每个键值对都用一个字典键值对来保存
- 字典每个键都是字符串对象,保存了键的值
- 字典每个值都是字符串对象,保存了值的值
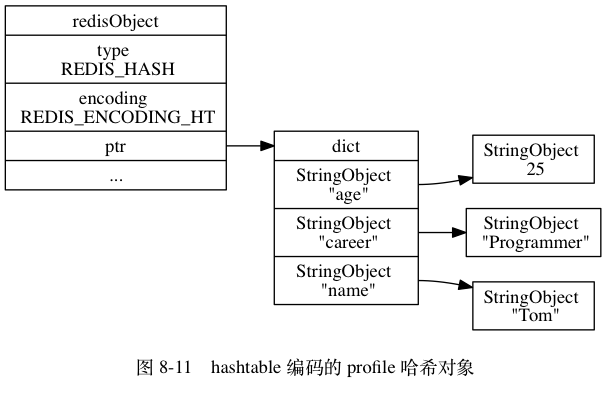
同时满足两个条件:
- 所有键值对的键和值长度都小于64字节
- 哈希表保存的键值对个数小于512
使用ziplist,否则使用hashtable
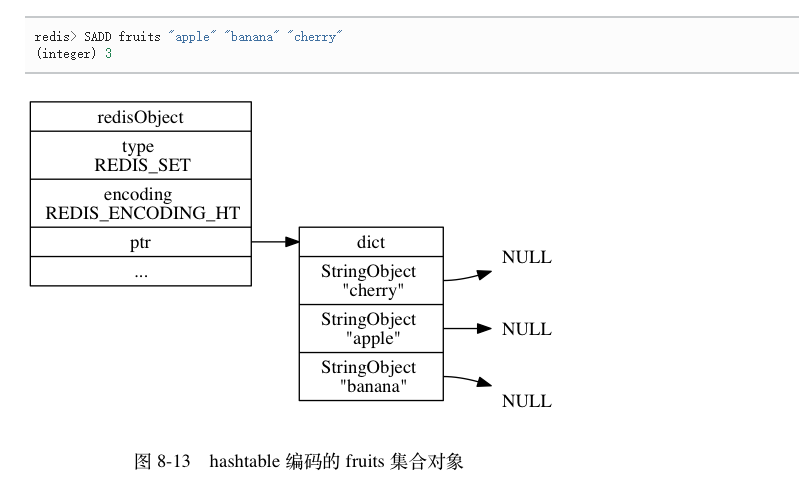
集合对象
底层使用intset或者hashtable
- intset实现时候,把所有的元素保存到整数集合里面
- hashtable的时候,每个键都是一个字符串对象,而字典的值是null
满足两个条件:
- 集合保存的对象都是整数
- 元素数量小于512个
使用intset,否则使用hashtable
有序集合
底层使用ziplist/skiplist
- ziplist:每个集合元素使用两个爱在一起的压缩列表节点来表示,第一个节点保存的是元素的成员,第二个保存的是元素的分值
- 按分值大小排序
skiplist:使用zset作为底层,一个zset同时包含了一个字典和一个跳跃表
使用跳表来保存有序集合再使用字典来构建(成员,分值)映射 ```c typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;
``
zset结构中的zsl跳跃表按分值从小到大保存了所有集合元素, 每个跳跃表节点都保存了一个集合元素.<br />zset结构中的dict` 字典为有序集合创建了一个从成员到分值的映射, 字典中的每个键值对都保存了一个集合元素.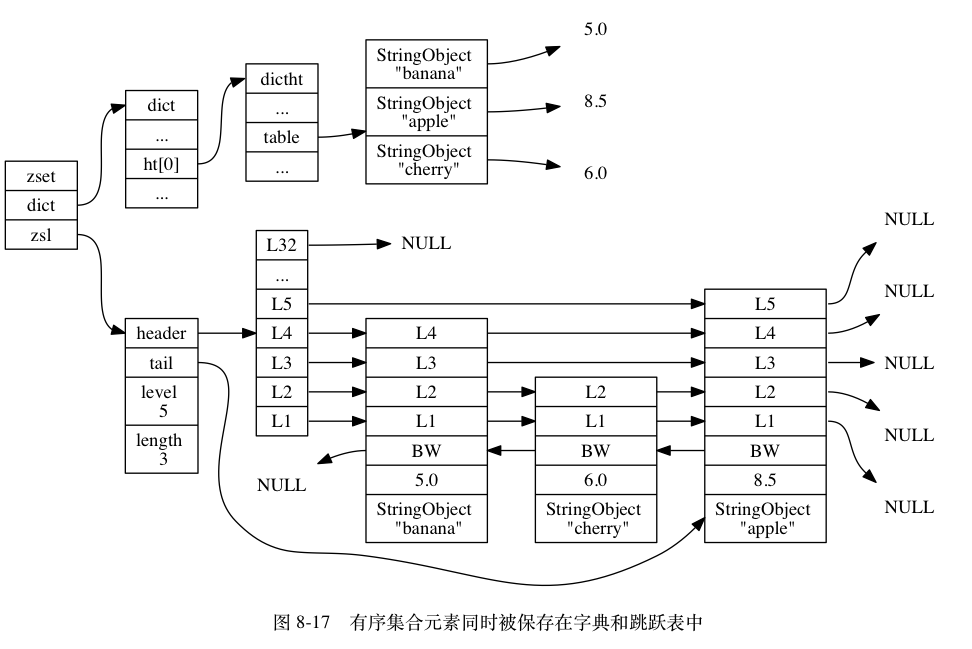
为了展示方便, 图 8-17 在字典和跳跃表中重复展示了各个元素的成员和分值, 但在实际中, 字典和跳跃表会共享元素的成员和分值, 所以并不会造成任何数据重复, 也不会因此而浪费任何内存。
满足下面两个条件:
- 有序集合的元素数量小于128个
- 所有元素长度小于64字节
使用ziplist,否则使用skiplist
总结
字符串的编码类型
- int:8 个字节的长整型
- embstr:小于等于 39 字节的字符串
- raw:大于 39 字节的字符串
哈希的编码类型
- ziplist:元素个数小于 512,且所有值都小于 64 字节
- hashtable:除上述条件外
列表的编码类型
- ziplist:元素个数小于 512,且所有值都小于 64 字节
- hashtable:除上述条件外
集合的编码类型
- intset:元素个数小于 512,且所有值都是整数
- hashtable:除上述条件外
有序集合的编码类型
- ziplist:元素个数小于 128,且所有值都小于 64 字节
- hashtable:除上述条件外

若有收获,就点个赞吧
0 人点赞
