判断对象存活情况
引用计数
为对象添加一个引用计数,每当有一个地方引用它,计数值+1;引用失效时候,计数值-1;计数值=0的对象不会被再使用.
缺点
- 无法解决循环引用 ```java /**
- testGC()方法执行后,objA和objB会不会被GC呢?
@author zzm */ public class ReferenceCountingGC {
public Object instance = null;
private static final int _1MB = 1024 * 1024;
/**
- 这个成员属性的唯一意义就是占点内存,以便在能在GC日志中看清楚是否有回收过 / private byte[] bigSize = new byte[2 _1MB];
public static void testGC() { ReferenceCountingGC objA = new ReferenceCountingGC(); ReferenceCountingGC objB = new ReferenceCountingGC(); objA.instance = objB; objB.instance = objA;
objA = null; objB = null;
// 假设在这行发生GC,objA和objB是否能被回收? System.gc(); } } ```
可达性分析
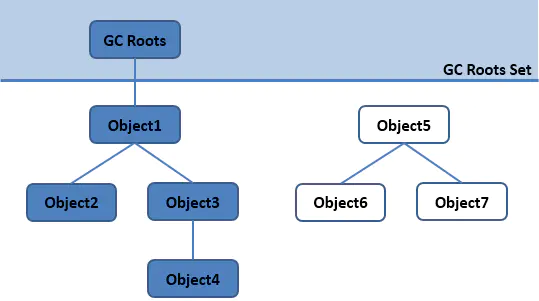
- 通过一系列
“GC Roots”作为``起始节点集,从这些集合开始,根据引用关系向下搜索“引用链” - 如果一个对象到GC Roots没有引用链相连接,那么证明对象是不可用的。
GC Roots:
- 虚拟机栈中引用的对象
- 类静态属性引用的对象
- 常量引用的对象,比如常量池的引用
- 本地方法栈中引用的对象
- 虚拟机内部的引用,例如异常、基本类型对应的Class对象、系统类加载器
- 被同步锁持有的对象
- 以及其他内存区域的“临时性”加入的对象
- 如果只针对某一块区域发起垃圾回收(比如新生代),此区域的对象有可能被堆中其他区域的对象所引用,这时候就需将这些关联区域的对象一并加入到GC Roots中去
引用
- 强引用
- 类似
Object c = new Object() - 强引用还在,那么对象就永远不能被回收
- 类似
- 软引用
- 还有用但非必须的对象
- 只被弱引用关联,则系统内存溢出之前,回把这些对象进行二次回收
- 弱引用
- 只能存活到下次垃圾回收发生
- 虚引用
- 唯一目的是为了能在这个对象被回收时收到一个系统通知
finalize()
- finalize只会被系统调用
一次。 - 尽量避免使用此方法
真正宣告对象的死亡,有两个步骤:
- 没有引用链可达,第一次被标记
- 随后进行筛选,筛选的条件是此对象是否有必要执行finalize()方法
- 如果对象没有重写finaize或者finalize已经调用过一次,那么都视作没必要执行finalize
如果有必要执行finalize:
- 将对象加入F-Queue队列
- 随后调用他们的finalize
- finalize是对象拯救自己的最后一次机会
- 只要重新与引用链上的一个对象建立关联,就可以避免被回收
- 否则就要被回收
垃圾回收算法
分代收集理论
- 大多数对象朝生熄灭
- 越老的对象越难死
- 跨代引用很少
- 跨代引用,使用一个
记忆集(位于新生代)的数据结构,把老年代划分成若干块,标识出老年代哪一块会存在跨代引用,此后新生代GC时候,只有包含了跨代引用的那一小块内存才会被加入GC Roots中。
- 跨代引用,使用一个
新生代GC:YoungGC/MinorGC
老年代GC:OldGC/MajorGC
所以:
收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄分配到不同的区域之中。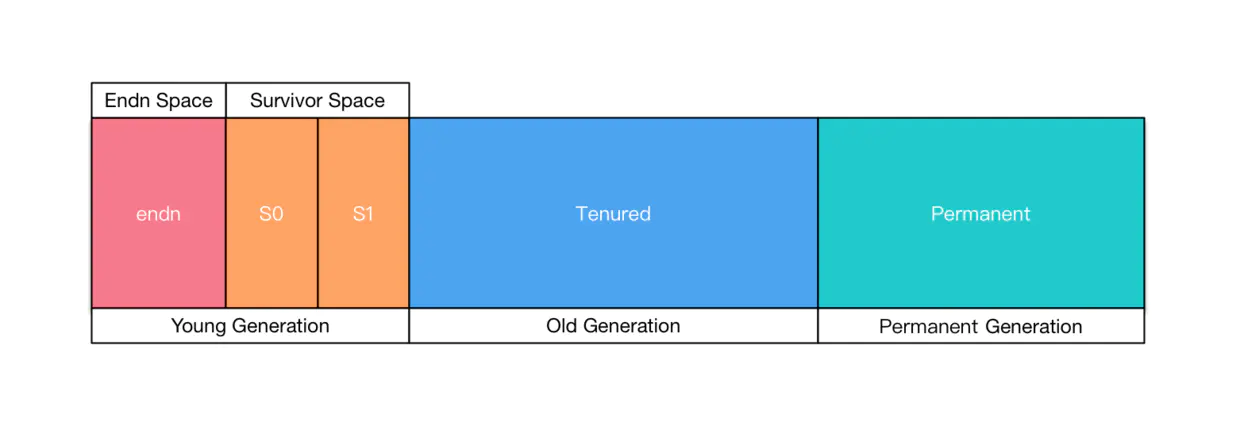
- 老年代
- 新生代
- Eden
- Survivor1
- Survivors
- https://blog.csdn.net/antony9118/article/details/51425581
- 如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。老年代很快被填满,触发Major GC(因为Major GC一般伴随着Minor GC,也可以看做触发了Full GC)。Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
- 设置两个Survivor区最大的好处就是解决了碎片化:假设现在只有一个survivor区,我们来模拟一下流程:刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
- 顺理成章的,应该建立两块Survivor区,刚刚新建的对象在Eden中,经历一次Minor GC,Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;等Eden区再满了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生)。S0和Eden被清空,然后下一轮S0与S1交换角色,如此循环往复。如果对象的复制次数达到16次,该对象就会被送到老年代中。
- 假设新生代100个对象,一次Minor GC之后存活20个,进入S0,如果只有一个S,那么假设下一次Minor GC之后S0中第一次存活的20个对象只存活5个,那么S0就有可能不连续了。所以2个S就可以保证每次S0的复制到S1,S1保证内存连续。
- 永远有一个survivor space是空的,另一个非空的survivor space无碎片。
Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
建立两块Survivor区,刚刚新建的对象在Eden中
- 经历一次
Minor GC:
Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;
等Eden区再满``了,就再触发一次Minor GC:Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了**S1**中来自**S0**和**Eden**两部分的存活对象占用**连续**的内存空间,避免了碎片化的发生)。
S0和Eden被清空,然后下一轮S0与S1交换角色,如此循环往复。如果对象的复制次数达到16次,该对象就会被送到老年代中。
上述机制最大的好处就是,整个过程中,永远有一个survivor space是空的,另一个非空的survivor space无碎片。
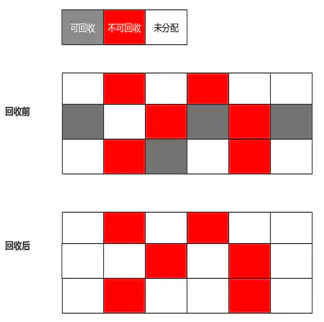
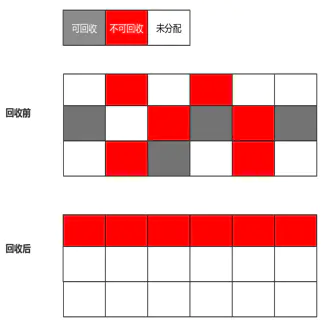
标记清除算法
标记处所有需要回收的对象,标记完成后,统一回收掉被标记的对象
缺点:
- 效率低,必须进行大量的标记和清除
- 内存碎片化,清除之后会有大量的碎片存在
标记复制算法
主要用于新生代
半区复制
将内存按容量分为两份,每次使用其中一块,一块内存用完,则将其中活着的复制到另外一块上,然后把本块内存一次性清理掉。
缺点:
- 空间浪费太多
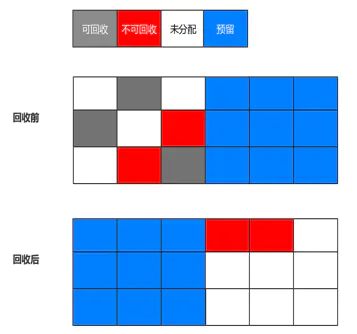
- 改进
- 分成Eden+Survivor1&2(参考上面的)
- 如果一块Survivor无法完全存放收集完毕后的存活对象,则将部分对象直接进入老年代。
标记整理算法
主要用于老年代
标记清除是非移动式
标记整理是移动式
让所有存活的对象向内存空间一端进行移动,然后直接清理掉边界以外的内存。
优缺点并存:
- 缺点:存活大量对象的区域进行回收,会更新所有存活对象的引用,开销很大,并且
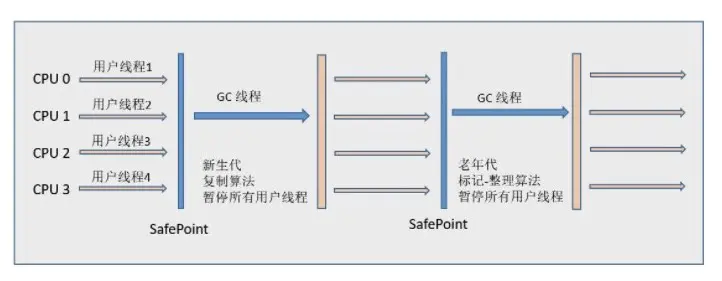
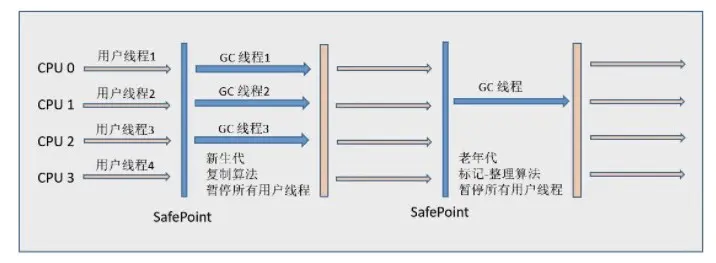
STOP THE WORLD
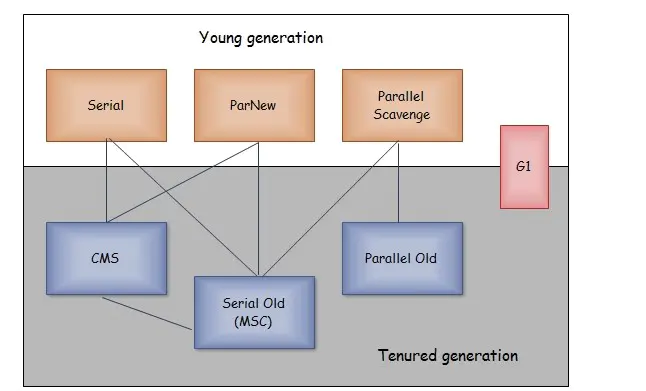
连线说明可以搭配使用。
Serial收集器
- 单线程
- 标记复制
- STOP THE WORLD
新生代基于复制算法,老年代基于整理算法
- 优点:简单高效、额外内存消耗小
ParNew收集器
- Serial的多线程版本
- 与老年代的CMS配合使用
Parallel Scavenge(java8默认)
吞吐量最优收集器
8默认:
- 新生代:Paraller Scavenge
老年代:Parallel Old
新生代
- 标记复制
- 并行
- 关注:达到一个可控制的吞吐量
- 吞吐量=(运行用户代码时间)/(垃圾收集时间+运行用户代码时间)
- 可以精确控制最大垃圾回收停顿时间、吞吐量大小
Serial Old收集器
- 老年代
- 单线程
- 标记整理算法
- CMS失败时候作为后备的预案
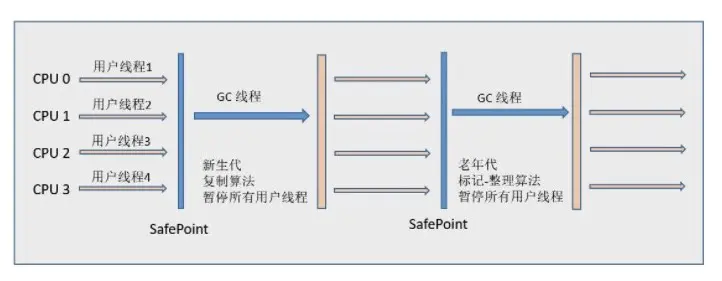
Parallel Old
- Parallel Scavenge的老年代版本
- 多线程
- 标记整理
CMS收集器:最短回收停顿时间为目标
Concurrent Mark Sweep
- 最短回收停顿时间为目标,注重响应速度,可用在B/S中
- 标记清除Mark Sweep
为什么采用标记清除算法?**
- CMS主要关注低延迟,于是采用并发方式,清理垃圾时,应用程序还在运行,如何采用压缩算法,则涉及到要移动应用程序的存活对象,此时不停顿,是很难处理的,通常须要- 停顿下,移动存活对象,再让应用程序继续运行,但这样停顿时间变长,延迟变大,因此CMS采用清除算法。
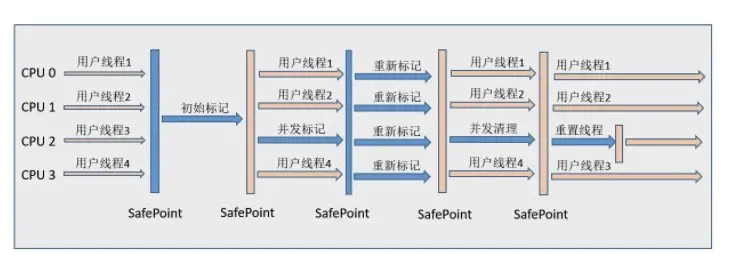
四个步骤
- 初始标记STOP THE WORLD
- 标记下GC Roots直接关联到的对象
- 并发标记
- 从GC Roots 遍历整个对象图
- 与用户线程并发
- 重新标记STOP THE WORLD
- 修正并发标记期间,因用户线程持续运作而导致标记变动的一部分对象
- 并发清除
- 清除掉已经判断死亡的对象
- 不需要移动存活的对象,因为是标记清除算法
**
缺点:
- 对处理器资源敏感(因为并发)
- 无法处理浮动垃圾
- 并发标记和并发清理阶段可能由于用户程序运行产生新的垃圾,导致无法标记,只能等下一次进行清理
- 因为基于标记清除,会产生大量的空间碎片
Garbage First :G1
- 面向局部收集+基于Region的内存布局
- 面向服务端
- 局部是标记复制,整体是标记整理:不会有内存碎片
在其之间的所有垃圾收集器,都是面向要么整个新生代,要么整个老年代,要么就是整个堆,但是G1可以面向堆内存任何部分来组成回收集进行回收,衡量标准变成了哪块内存中存放的垃圾最多,回收收益最大。
- 把堆划分为多个大小相等的独立区域Region,每个区域根据需要扮演Eden、Survivor、Region
- 收集器能够对不同角色的Region采用不同的策略去处理。
- Humongous区域专门来存储大对象(大小超过一半Region的对象),会被放在多个连续的Humongous区域中,G1通常把大对象当作老年代的一部分来看待
- 如果一个 Humongous Region 装不下一个巨型对象,G1会寻找连续的 Humongous Region 来存储,为了能找到连续的 H 区,有时候不得不启动 Full GC。
- 每次回收的内存空间都是Region的整数倍
- 使用一个优先级列表来决定优先回收价值收益最大的Region

- 处理跨region引用很复杂
**

若有收获,就点个赞吧
0 人点赞
