- 请你查找employees里最晚入职员工的所有信息,以上例子输出如下:
select *from employeeswhere hire_date = (select max(hire_date) from employees);
- 因为有可能有多个在最晚那天入职的,所以可以选出入职日期等于最晚的那天的,这一定是正确。
- 如果只需要取出一个,那么可以
select *from employeesorder by hire_date desclimit 0,1;
limit 0,1;代表从0号位置开始取1个。
- 查找employees里入职员工时间排名倒数第三的员工所有信息
只有一个时候
select * from employeesorder by hire_date desclimit 2,1;
有多个时候
select emp_no,birth_date,first_name,last_name,gender,hire_datefrom employees e1where 2= ( # 有两种日期大于她自己的select count(*)from employees e2where e2.hire_date > e1.hire_date);
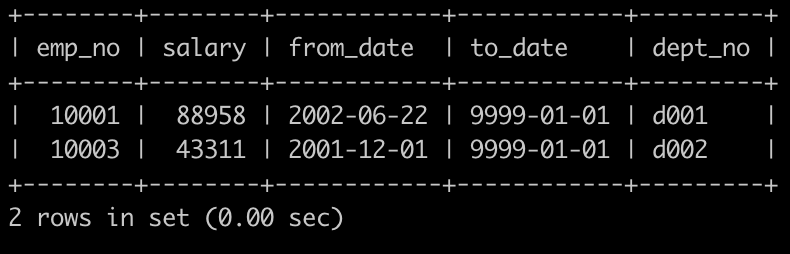
- 查找各个部门领导薪水详情以及其对应部门编号dept_no,输出结果以salaries.emp_no升序排序,并且请注意输出结果里面dept_no列是最后一列,以上例子输入如下:
select s.*,d.dept_nofrom salaries sjoin dept_manager don s.emp_no = d.emp_noorder by emp_no;
- 查找所有已经分配部门的员工的last_name和first_name以及dept_no,未分配的部门的员工不显示,以上例子如下:
只要employees表里的emp_no = dept_emp 表里的emp_no 就可以了。
select last_name,first_name,dept_nofrom employees ejoin dept_emp don e.emp_no = d.emp_no;
查找所有已经分配部门的员工的last_name和first_name以及dept_no,也包括暂时没有分配具体部门的员工
select last_name,first_name,dept_nofrom employees eleft join dept_emp don e.emp_no = d.emp_no;
查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t,以上例子输出如下: ```sql select emp_no,count() t from salaries s group by emp_no having t > 15; # 不需要计算两次count() t
select emp_no,count() t from salaries s group by emp_no having count(t) > 15; # 需要计算两次count() t ,慢
7. 有一个薪水表,请你找出所有员工具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示,以上例子输出如下: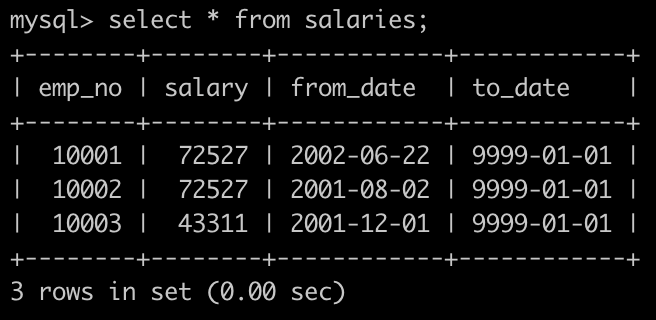<br />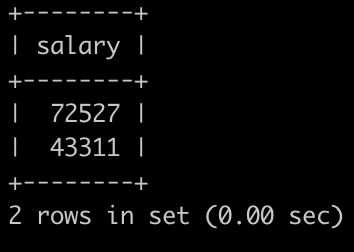- 分组+ 降序 就行了```sqlselect salaryfrom salariesgroup by salaryorder by salary desc;
- 有一个员工表employees简况如下:
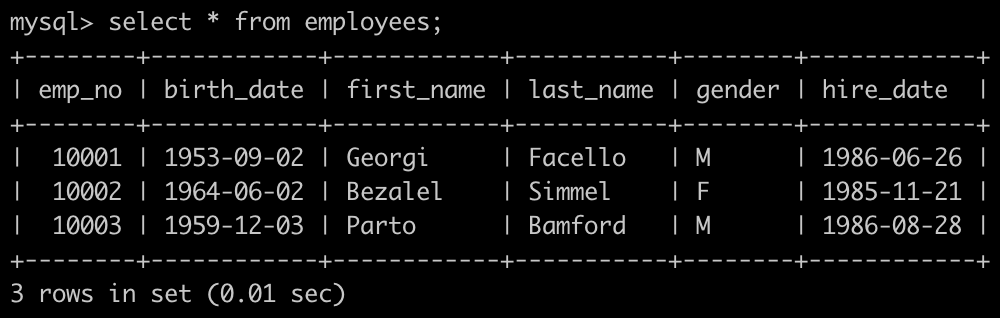
有一个部门领导表dept_manager简况如下: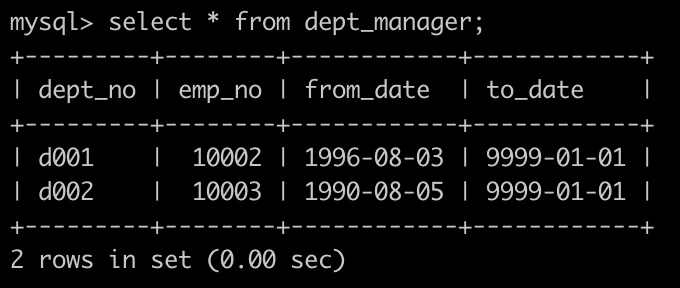
请你找出所有非部门领导的员工emp_no,以上例子输出: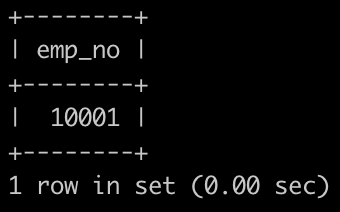
- 查找员工表的id,只要id不在领导表里面就行了
select emp_nofrom employees e1where e1.emp_no not in (select emp_nofrom dept_manager);
- 有一个员工表dept_emp简况如下:
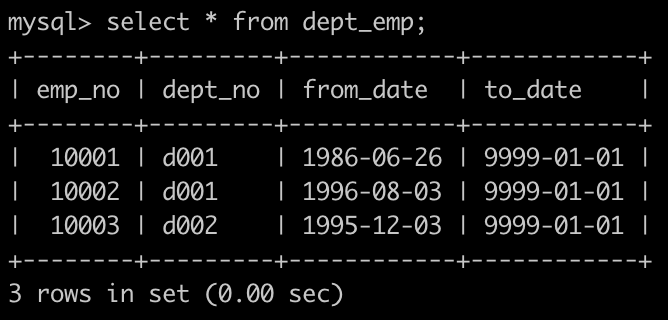
第一行表示为员工编号为10001的部门是d001部门。
有一个部门经理表dept_manager简况如下: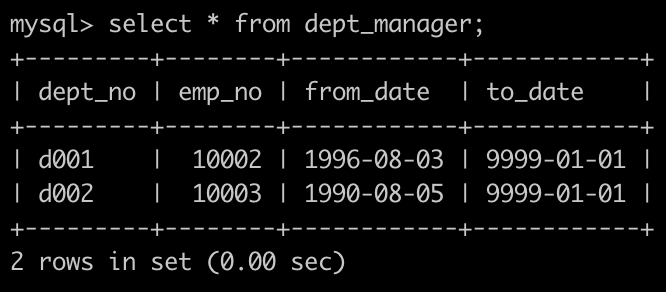
第一行表示为d001部门的经理是编号为10002的员工。
获取所有的员工和员工对应的经理,如果员工本身是经理的话则不显示,以上例子如下: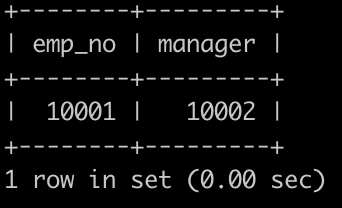
连接操作:
- 员工表和管理表部门一致
员工表和管理表的员工id不一致
select e.emp_no,m.emp_nofrom dept_emp ejoin dept_manager mon e.dept_no = m.dept_no and e.emp_no != m.emp_no;
有一个员工表dept_emp简况如下:
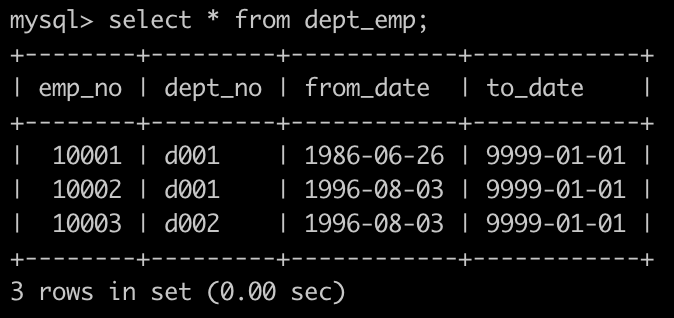
有一个薪水表salaries简况如下: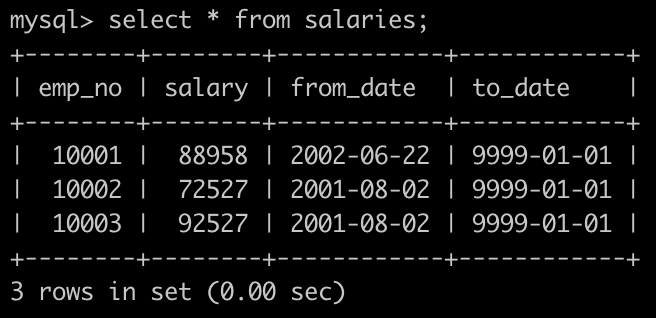
获取所有部门中员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列,以上例子输出如下: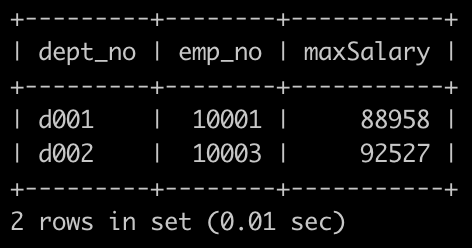
- 很复杂,需要使用多次连接
- 写了很久
select d2.dept_no,d2.emp_no,maxSalaryfrom ( # 选出每组的最大的select dept_no,max(salary) maxSalaryfrom dept_emp e1join salaries s1on e1.emp_no = s1.emp_nogroup by dept_no) d1,dept_emp d2,salaries d3# 按员工编号,组号,工资进行连接判断where d1.dept_no = d2.dept_noand d1.maxSalary = d3.salaryand d2.emp_no = d3.emp_noorder by d2.dept_no;
- 有一个员工表employees简况如下:
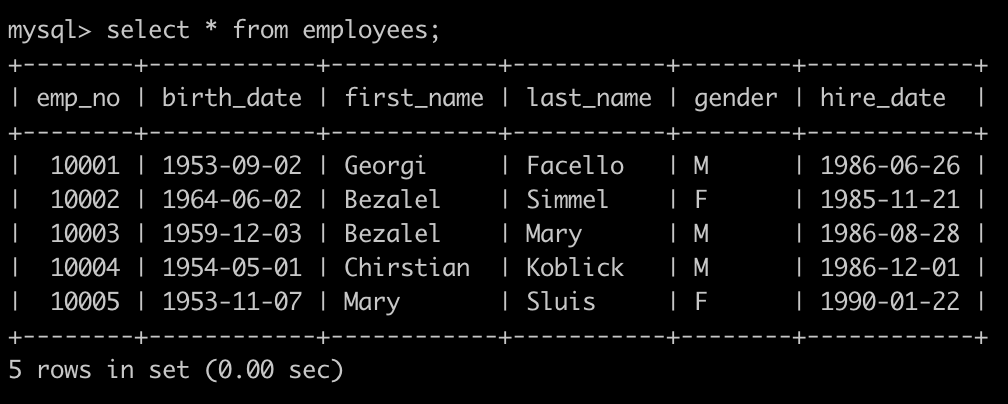
建表语句如下:
| 1 2 3 4 5 6 7 8 |
CREATE TABLEemployees(emp_no` int(11) NOT NULL,`<br />birth_datedate NOT NULL,first_name` varchar(14) NOT NULL,`<br />last_namevarchar(16) NOT NULL,gender` char(1) NOT NULL,`<br />hire_datedate NOT NULL,PRIMARY KEY (emp_no)); |
|---|---|
请你查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列,以上例子查询结果如下: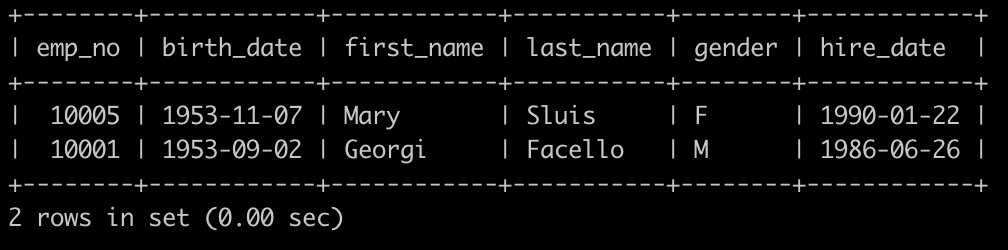
select *from employeeswhere emp_no & 1 = 1 # 取余使用mod的,使用位运算比较快and last_name != 'Mary'order by hire_date desc;
- 有一个员工职称表titles简况如下:
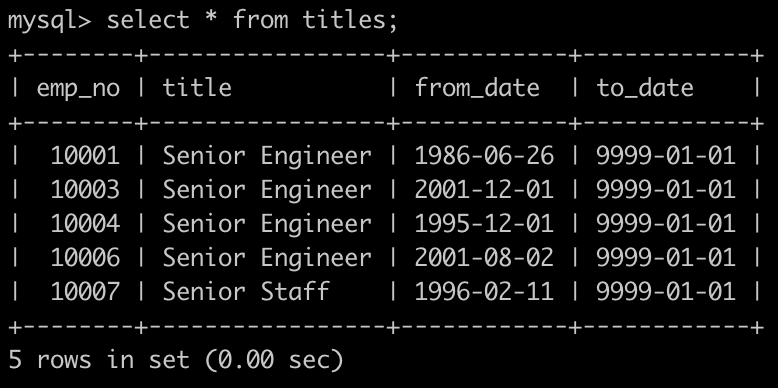
有一个薪水表salaries简况如下: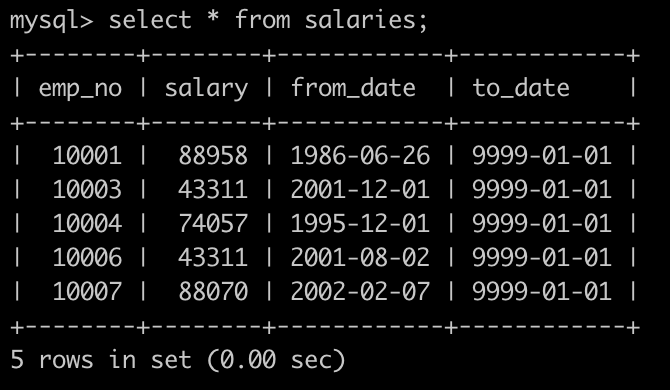
建表语句如下:
| 1 2 3 4 5 |
CREATE TABLE titles (emp_no` int(11) NOT NULL,`<br />titlevarchar(50) NOT NULL,from_date` date NOT NULL,`<br />to_datedate DEFAULT NULL); |
|---|---|
| 1 2 3 4 5 6 |
CREATE TABLEsalaries(emp_no` int(11) NOT NULL,`<br />salary``int``(11) NOT NULL,from_date` date NOT NULL,`<br />to_datedate NOT NULL,PRIMARY KEY (emp_no,from_date)); |
|---|---|
请你统计出各个title类型对应的员工薪水对应的平均工资avg。结果给出title以及平均工资avg,并且以avg升序排序,以上例子输出如下: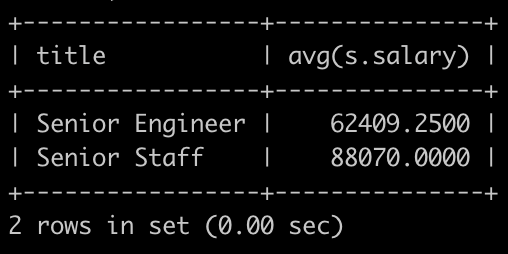
- 使用连接以及分组
select title,avg(s.salary)from titles tjoin salaries son t.emp_no = s.emp_nogroup by title;
- 有一个薪水表salaries简况如下:
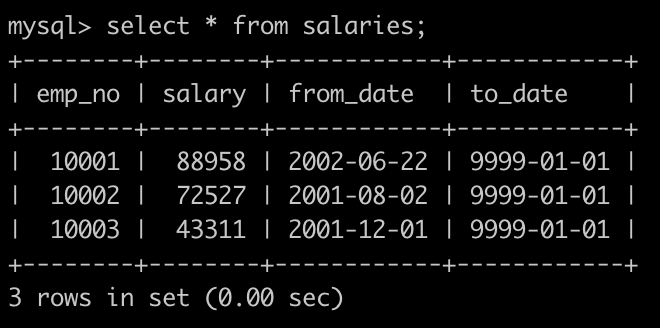
请你获取薪水第二多的员工的emp_no以及其对应的薪水salary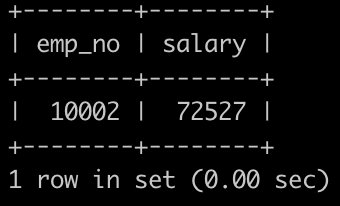
如果薪水各个不相同
select emp_no,salaryfrom salaries s1where 1 = (select count(*) from salaries s2 where s2.salary > s1.salary);
如果有多个薪水是一样的
- 按薪水进行分组,选出第二组
limit 1,1select emp_no,salaryfrom salarieswhere salary = (select salaryfrom salariesgroup by salaryorder by salary desclimit 1,1);
- 按薪水进行分组,选出第二组

若有收获,就点个赞吧
0 人点赞
