类型
类型问题
基本类型
Java中的8个数据类型
| 类型 | 字节数 | bit |
|---|---|---|
| byte | 1 | 8 |
| char | 2 | 16 |
| short | 2 | 16 |
| int | 4 | 32 |
| float | 4 | 32 |
| long | 8 | 64 |
| double | 8 | 64 |
| boolean | 不确定,一个字节或者四个字节,单独使用视为int是四个字节,在boolean数组中使用视为byte一个字节 | 不确定了 |
对虚拟机来说根本就不存在 boolean 这个类型。在《Java虚拟机规范》中给出了两种定义,分别是4个字节和boolean数组时1个字节的定义,但是具体还要看虚拟机实现是否按照规范来,1个字节、4个字节都是有可能的。这其实是运算效率和存储空间之间的博弈,两者都非常的重要。
Integer是作为包装类型的,基本类型与对应类型之间的赋值是自动装箱与拆箱完成的.
Integer number1 = 2; // 装箱 调用了 Integer.valueOf(2)int number2 = number1; // 拆箱 调用了 number1.intValue()
new Integer(1024) 和Integer.valueOf(1024) 有没有什么区别呢?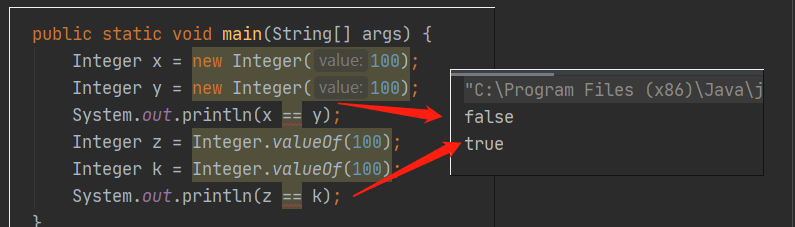
new Integer(1024) 每次都会新建一个对象,而Integer.valueOf(1024) 会使用缓冲池中的对象,多次调用会取得同一个对象的引用public static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);}
Integer.valueOf(1024) 和Integer.valueOf(1024) 缺不等于true,而是false。Integer.valueOf从缓冲池取的数值是有大小限制的,并不是任何数
我们可以看看valueOf() 的源码,其实也比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓冲池的内容。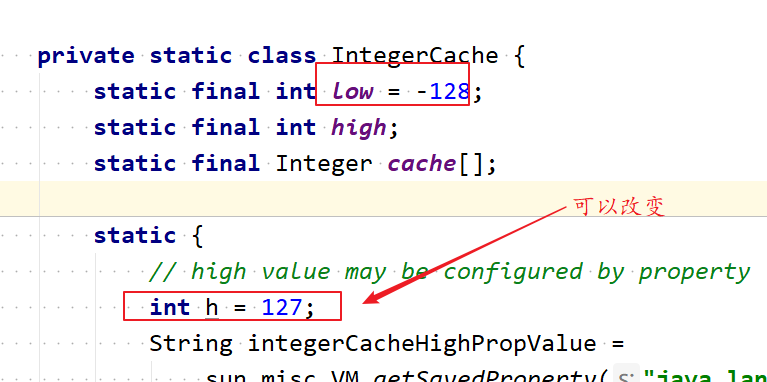

对自动拆箱和装箱的理解
编译器会在自动装箱过程中调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象,因此对比的时候会返回true。
说说看你知道的缓冲池有哪些?boolean 缓冲池,true and false
- byte缓冲池
- short 缓冲池
- int 缓冲池
- char 缓冲池
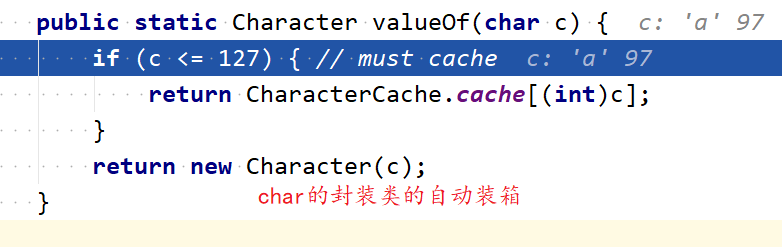
因此我们在使用这些基本类型对应的包装类型时,如果该数值范围在缓冲池范围内,那么就可以直接使用缓冲池中的对象。
这些缓冲池的上限下限**都是不变的吗?还是说可以设定的?**
基本上都是不可变的,不过在 jdk 1.8 中,Integer 的缓冲池 IntegerCache 很特殊,这个缓冲池的下界是 - 128,上界默认是 127,但是这个上界是可调的。
static final int low = -128;static final int high;static final Integer cache[];static {// high value may be configured by propertyint h = 127;String integerCacheHighPropValue =sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");if (integerCacheHighPropValue != null) {try {int i = parseInt(integerCacheHighPropValue);i = Math.max(i, 127);// Maximum array size is Integer.MAX_VALUEh = Math.min(i, Integer.MAX_VALUE - (-low) -1);} catch( NumberFormatException nfe) {// If the property cannot be parsed into an int, ignore it.}}high = h;cache = new Integer[(high - low) + 1];int j = low;for(int k = 0; k < cache.length; k++)cache[k] = new Integer(j++);// range [-128, 127] must be interned (JLS7 5.1.7)assert IntegerCache.high >= 127;}
7line + 15line
String类型
publicfinalclass`` String String是final类型,所以不能被继承!
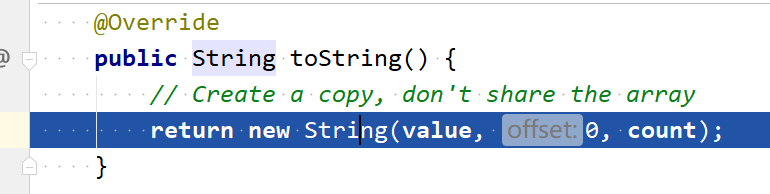
存储数据的方式:privatefinalchar value[]; char数组进行存储数据,并且是final,说明value初始化后不能再引用其它数组,String 内部也没有改变 value 数组的方法,因此可以保证 String 不可变。
- 不可变的好处
- 安全,当String 作为参数引用的时候,不可变性可以保证参数不可变。
- 可以缓存 hash 值,实际上,我们开发的时候经常会用来当做map的key,不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
- String Pool 的需要,如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用,而自然只有 String 是不可变的,才可能使用 String Pool。
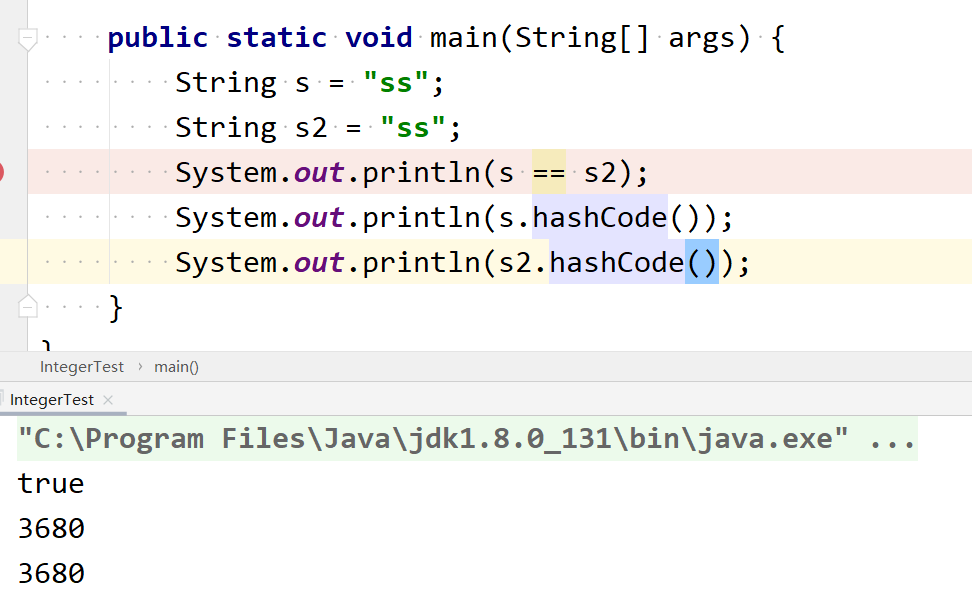
- 刚刚有说到String Pool ,说说看你的理解
- String Pool也就是我们经常说的字符串常量池,它保存着所有字符串字面量,而且是在编译时期就确定了。
- String Pool是在编译时期就确定了,那么请问是否不可变的呢?
- String 的 intern() 方法在运行过程将字符串添加到 String Pool 中
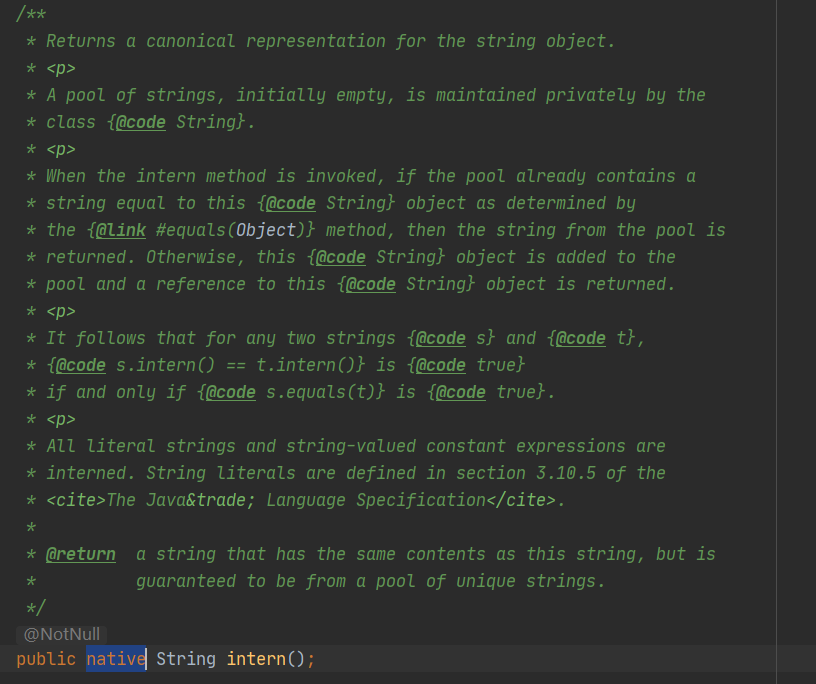
- 当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
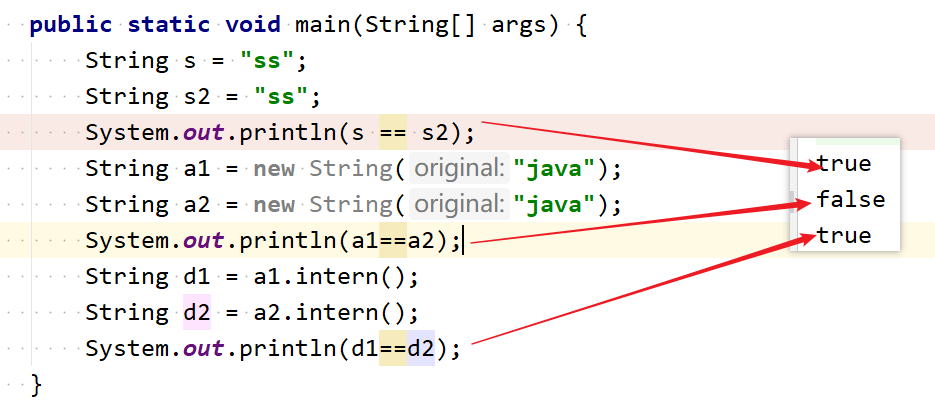
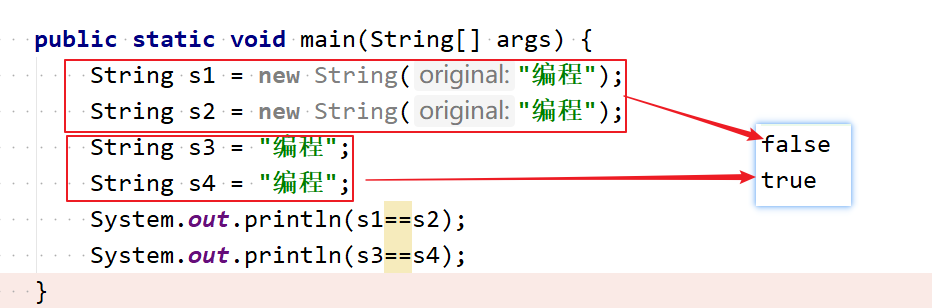
- 采用这种字面量的形式创建字符串,JVM会自动地将字符串放入 String Pool 中,因此它们两个是相等的。
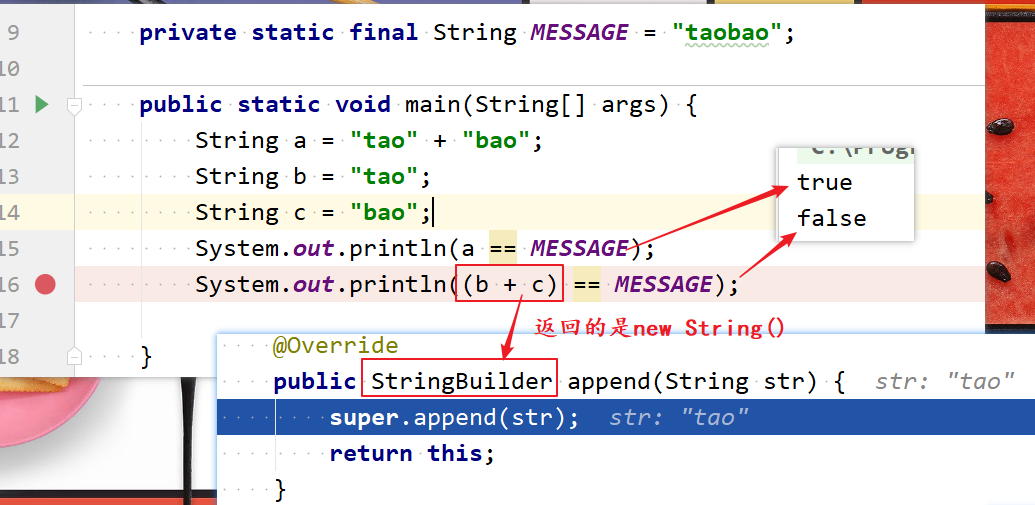
- String a = “tao” + “bao”;在编译器就可以确定;b + c运行实在才能确定,因为担心你改变b、c的值。
- new String(“饭谈编程”) JVM做了啥?
- 首先使用这种方式一共会创建两个字符串对象,当然了,前提是 String Pool 中还没有 “饭谈编程” 这个字符串对象,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 “饭谈编程” 字符串字面量。

- 在将一个字符串对象作为另一个字符串对象的构造函数参数时,JVM会从String Pool 中将这个字符串对象取出来,当做参数传进String的构造函数中,将 value 数组和hash值赋予这个新的对象。
- 有没有用过StringBuffer 和 StringBuilder,说说看String, StringBuffer 以及StringBuilder三者的区别?
publicfinalclass StringBufferpublicfinalclass StringBuilder- 都是被final修饰的类,都是不可被继承
- 从可变性上来说,String 我们刚刚说到了,是不可变的,而StringBuffer 和 StringBuilder 可变的,这是内部结构导致的,StringBuffer 和StringBuilder 内部放数据的数组没有被final修饰 char[] value; | String | 不可变,线程安全 | | —- | —- | | StringBuilder | 可变,线程不安全 | | StringBuffer | 可变,线程安全,内部使用 synchronized 进行同步 |
Error类型
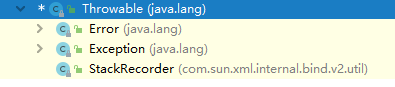
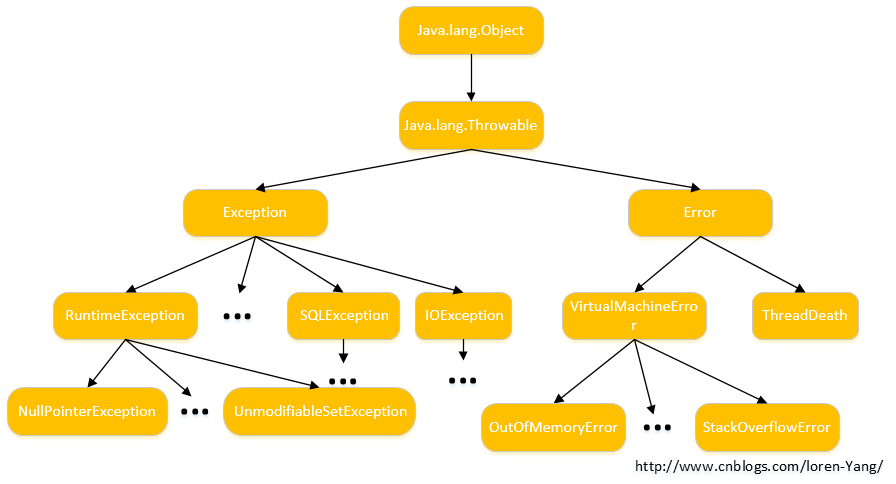
- Exception 和 Error 的区别,另外,运行时异常和一般异常有啥区别
- Exception 和 Error 都继承了 Throwable 类。
- 在 Java 中只有 Throwable 类型的实例才可以被捕获(catch)或者是抛出 (throw), 它是异常处理机制的基本组成。
- Exception 和 Error 体现了 Java 设计者对不同类型的分类。
- Exception 通常是程序正常运行,可以被预料的异常,可以被捕获并进行相应处理的。
- 例如/0异常
- Exception分为可检查类型+不可检查类型
- 可检查异常:除了RuntimeException与其子类,以及错误(Error),其他的都是检查异常(绝对的大家族),我们在代码需要显式的去捕获,并作出相应的处理,它属于编译检查的一部分
- 编译器要求你必须处置的异常。编译器要求你必须要对这段代码try…catch,或者throws exception,代码还没运行呢,编译器就会检查你的代码,会不会出现异常,要求你对可能出现的异常必须做出相应的处理。
- 解决方式
- 继续抛出,消极的方法,一直可以抛到java虚拟机来处理,就是通过throws exception抛出。
- 用try…catch捕获
- 不检查异常呢,类似 NullPointerException, ArrayIndexOutOfBoundsException 之类,我们是可以在程序中进行判断来避免的,所以编译期并不会强制要求你去捕获。
- 可检查异常:除了RuntimeException与其子类,以及错误(Error),其他的都是检查异常(绝对的大家族),我们在代码需要显式的去捕获,并作出相应的处理,它属于编译检查的一部分
- Error 指的是正常情况下不大可能会出现的异常,绝大多数 Error 都会导致程序处于非正常的,不可恢复的状态。它也是不便于也是不需要被捕获的。比如说比较经典的 OutOfMemoryError 这种 Error 的子类。
- 大多数的错误与代码编写者执行的操作无关,而是表示代码运行时 JVM(Java 虚拟机)出现的问题。
Object类的方法
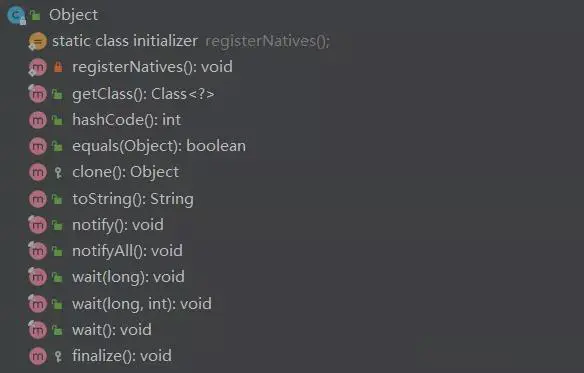
getClass
public final native Class<?> getClass();
final 方法、获取对象的运行时 class 对象,class 对象就是描述对象所属类的对象。这个方法通常是和 Java 反射机制搭配使用的。hashCode
public native int hashCode();
该方法主要用于获取对象的散列值。Object 中该方法默认返回的是对象的堆内存地址。equals VS ==
简单回答:equals方法比较的是字符串的内容是否相等,而 == 比较的则是对象地址。
详细点的:
Java中的数据类型可以分为两种
- 大多数的错误与代码编写者执行的操作无关,而是表示代码运行时 JVM(Java 虚拟机)出现的问题。
- Exception 通常是程序正常运行,可以被预料的异常,可以被捕获并进行相应处理的。
- Exception 和 Error 都继承了 Throwable 类。
- 基本数据类型,也称原始数据类型,如byte,short,char,int,long,float,double,boolean 他们之间的比较,应用双等号(==),比较的是他们的值。
- 复合数据类型,包括类&String,当他们用(==)进行比较的时候,比较的是他们在内存中的存放地址,所以,除非 是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。
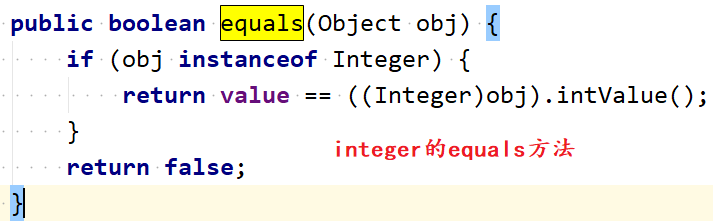
private final int value;public int intValue() {return value;}public boolean equals(Object obj) {if (obj instanceof Integer) {return value == ((Integer)obj).intValue();}return false;}
public boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String)anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;}
HashCode VS equals
如果两个对象equals方法相等,则它们的hashCode一定相同;
如果两个对象的hashCode相同,它们的equals()方法则不一定相等。
两个对象的hashCode()返回值相等不能判断这两个对象是相等的,但两个对象的hashcode()返回值不相等则可以判定两个对象一定不相等。
请问hashCode有什么作用呢?为什么要这么规范
hashCode的作用实际上是为了提高在散列结构存储中查找的效率,自然只有每个对象的hashCode尽可能的不同才能保证散列存储性能的提高,这也是为什么Object默认提供hash码都是不同的原因。
以HashSe集合中的元素不能相同为例,要想保证元素不重复则需要调用对象的equals方法比较一次,但是如果这个结构放了很多元素,比如5000次,如果没有hashCode的话则需要在每次加元素的时候对比5000次,而如果有hashCode则不一样了,当集合要添加新的元素的时候先调用hashCode方法,这样便可以定位到元素的地址,而无需多次判断。
Clone
clone方法是Object的protect方法,需要子类显示的去重写clone方法,并且实现Cloneable 接口,否则使用调用clone时候抛出异常protected native Object clone() throwsCloneNotSupportedException
实现相应接口以后,clone使用的也是浅拷贝,最终拷贝对象和原始对象的引用类型引用还是同一个对象。
直接用clone拷贝的时候是一种浅拷贝(浅拷贝,指的是对象内属性引用的对象只会拷贝引用地址,而不会将引用的对象重新分配内存),最终拷贝对象和原始对象的引用类型引用还是同一个对象。如果想要实现深拷贝,则需要开发人员自己在clone方法内自己进行重写。
toString()
public String toString() {return getClass().getName() + "@" + Integer.toHexString(hashCode());}
返回一个 String 对象,一般子类都有覆盖。默认返回格式如下:对象的 class 名称 + @ + hashCode 的十六进制字符串。
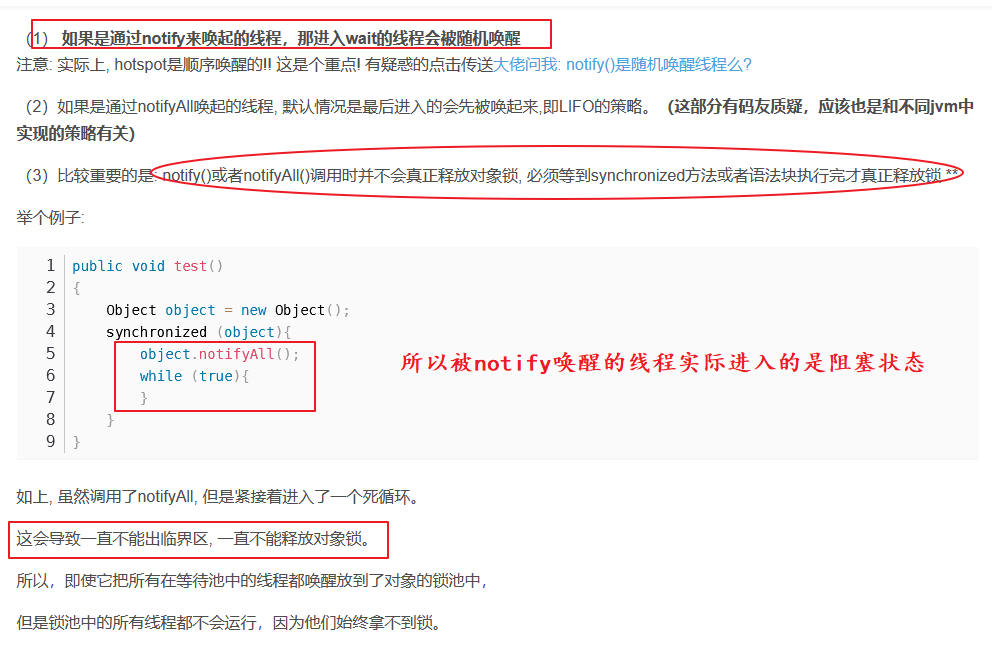
notify
public final native void notify();
final 方法,主要用于唤醒在该对象上等待的某个线程。
notify方法用于唤醒正在等待当前对象监视器的线程,唤醒的线程是随机的。
一般notify方法和wait方法配合使用来达到多线程同步的目的。
在一个线程被唤醒之后,线程必须先重新获取对象的监视器锁(线程调用对象的wait方法之后会让出对象的监视器锁),才可以继续执行。
- 一个线程在调用一个对象的notify方法之前必须获取到该对象的监视器(synchronized),否则将抛出IllegalMonitorStateException异常。
- 同样一个线程在调用一个对象的wait方法之前也必须获取到该对象的监视器。
https://blog.csdn.net/su371128017/article/details/110527980
notifyAll
public final native void notifyAll();
final 方法,主要用于唤醒在该对象上等待的所有线程。
如果当前线程不是对象监视器的所有者,那么调用notifyAll同样会发生
wait(long timeout) 方法
public final native void wait(long timeout) throws InterruptedException;
wait 方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。
wait() 方法一直等待,直到获得锁或者被中断。wait(long timeout) 设定一个超时间隔,如果在规定时间内没有获得锁就返回。
该方法导致当前线程等待,直到其他线程调用此对象的 notify() 方法或notifyAll()方法,或在指定已经过去的时间。
如果wait方法的参数timeout为0,代表等待过程是不会超时的,直到其他线程notify或者被中断。如果timeout大于0,则代表等待支持超时,超时之后线程自动被唤醒。
finalize方法
protected void finalize() throws Throwable { }
垃圾回收器在回收一个无用的对象的时候,会调用对象的finalize方法,我们可以覆写对象的finalize方法来做一些清除工作。
重写&重载
public class TestHashMap {static class A {public void show(A obj) {System.out.println("A.show(A)");}public void show(C obj) {System.out.println("A.show(C)");}}static class B extends A {public void show(A obj) {System.out.println("B.show(A)");}}static class C extends B {}static class D extends C {}public static void main(String[] args) {A a = new A();B b = new B();C c = new C();D d = new D();a.show(a);a.show(b);b.show(c);b.show(d);A ba = new B();ba.show(c);ba.show(d);ba.show(a);}}A.show(A)A.show(A)A.show(C)A.show(C)A.show(C)A.show(C)B.show(A)
JVM在调用一个方法时,会优先从本类中查找看是否有对应的方法,如果没有再到父类中查看是否从父类继承来。如果没有怎么办?那JVM就会对参数进行转型,转成父类之后看是否有对应的方法。 调用方法时候先从本类进行操作,如果本类及父类做不到,就将参数转型为父类进行操作. ``本类->父类->类型转换
重载的定义是:在同一个类中,一个方法与已经存在的方法名称上相同,并且参数类型、个数、**顺序**至少有一个不同。这句话里边并没有包含着返回值,如果只是返回值不同,其它都相同根本不算是重载。
传值
- 在Java中方法参数的传递方式是引用传递呢?还是值传递呢?
错误答案:这个要分情况,如果参数是基本类型的话,就是值传递,如果是引用类型的话,则是引用传递。
Java 的参数全都是是以值传递的形式传入方法中,而不是引用传递。
- 如果参数是基本类型,则传递的是基本类型的**字面量值的拷贝**。
- 如果参数是引用类型的话,传递的则值该参数**所引用的对象在堆中地址值的拷贝**。
精度
float f = 2.2,这么写有没有问题?
2.2这个字面量属于 double 类型的,因此不能直接将 2.2 直接赋值给 float 变量,因为这是向下转型,
记住Java 不能隐式执行向下转型,因为这会使得精度降低。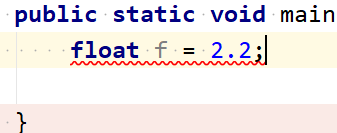
正确写法float f = 2.2f;
那么float f = 2.2f; f += 2.2;可以吗
是可以的,因为使用 += 或者 ++ 运算符,JVM会执行隐式类型转换。
上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:f = (float) (f + 2.2);
Java8新特性
JDK 8
1、接口可以添加默认方法default + 静态方法;
interface In8 {void f();default void g() { //默认方法System.out.println("default");}static void h() { // 静态方法System.out.println("static");}}
2、lambda表达式+方法引用(方法引用指的是可以直接使用java类或对象的方法),对于接口可以直接用()->{}方式来表达,小括号表示方法入参,花括号内表示方法返回值,如Collections的sort()方法:
3、函数式接口
4、新的日期和时间API
5、并发增强
6、支持多重注解
7、反射加强 。JDK8加强了反射,它允许你直接通过反射获取参数的名字
8、Stream API
9、JavaScript引擎Nashorn
10、Java虚拟机(JVM)的新特性:PermGen空间被移除了,取而代之的是Metaspace(JEP 122)。JVM选项-XX:PermSize与-XX:MaxPermSize分别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替。

若有收获,就点个赞吧
0 人点赞
