重点概要:
1. 引言
在实际场景中,很多数据集都是多维度的。随着维度的增加,数据空间的大小(体积)会以指数级别增长,使数据变得稀疏,这便是维度诅咒的难题。维度诅咒不止给异常检测带来了挑战,对距离的计算,聚类都带来了难题。例如基于邻近度的方法是在所有维度使用距离函数来定义局部性,但是,在高维空间中,所有点对的距离几乎都是相等的(距离集中),这使得一些基于距离的方法失效。在高维场景下,一个常用的方法是子空间方法。
集成(Ensemble)是子空间思想中常用的方法之一,可以有效提高数据挖掘算法精度。集成方法将多个算法或多个基检测器的输出结合起来。其基本思想是一些算法在某些子集上表现很好,一些算法在其他子集上表现很好,然后集成起来使得输出更加鲁棒。集成方法与基于子空间方法有着天然的相似性,子空间与不同的点集相关,而集成方法使用基检测器来探索不同维度的子集,将这些基学习器集合起来。
下面来介绍两种常见的集成方法:
2. Feature Bagging
2.1 Bagging思想
Bagging一词是bootstrap aggregating(自助法聚合)的缩写,是对数据使用自助法构建一组(多个)模型的通用方法。
2.1.1 Bootstrap(自助法)
估计统计量或模型参数的抽样分布,一个简单而有效的方法是,从样本本身中有放回地抽取更多的样本,并对每次重抽样重新计算统计量或模型。这一过程被称为自助法。自助法无须假设数据或抽样统计量符合正态分布。
从概念上看,我们可以这样理解自助法:将原始样本复制成千上万次,得到一个假想的总体,其中包括了原始样本中的全部信息,只是规模更大。然后我们从这一假想总体中抽取样本,用于估计抽样分布。自助法的理念如图所示。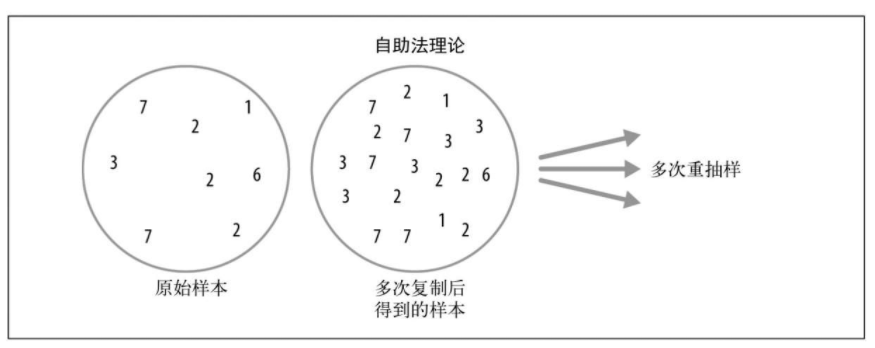
在实践中,完全不必真正地多次复制样本。只需在每次抽取后,将观测值再放回总体中,即有放回地抽样。这一方式有效地创建了一个无限的总体,其中任意一个元素被抽取的概率在各次抽取中保持不变。使用自助法对规模为n的样本做均值重抽样的算法实现如下。
(1)抽取一个样本值,记录后放回总体。
(2)重复n次。
(3)记录n个重抽样的均值。
(4)重复步骤1~3多次,例如r次。
(5)使用r个结果:
a.计算它们的标准偏差(估计抽样均值的标准误差);
b.生成直方图或箱线图;
c.找出置信区间。
我们称r为自助法的迭代次数,r的值可任意指定。迭代的次数越多,对标准误差或置信区间的估计就越准确。上述过程的结果给出了样本统计量或估计模型参数的一个自助集,可以从该自助集查看统计量或参数的变异性。
例子。下面的代码实现将自助法用于借款者的收入数据。
import pandas as pdimport numpy as npdef boost(data, R, n=None, statistic='median'):"""R: Number of bootstrap smaplesn: Size of each bootstrap sample"""# n = [n, n*len(data)][0<n<1] if n else len(data)m = n if n else len(data) # 默认自助样本大小等于真实样本大小n = int(m*len(data)) if 0<m<1 else m # 可指定自助样本的大小,可以是真实样本大小的一定比例samples = np.random.choice(data, (R, n),replace=True) # 有放回抽样stat_dict = {'median': np.median, 'mean': np.mean}if isinstance(statistic, str):# assert statistic in stat_dict, f'Unrecognized sampling statistic "{statistic}"'if statistic in stat_dict:samples_stat = stat_dict[statistic](samples, axis=1) # 计算所有自助样本的统计量estimate = np.mean(samples_stat) # 计算所有自助样本的统计量的均值,作为整体统计量的点估计data_stat = stat_dict[statistic](data) # 真实样本的统计量else:# assert callable(statistic), '{} is not callable'.format(statistic)samples_stat = statistic(samples)estimate = np.mean(samples_stat)data_stat = stat_dict(data)bias = estimate - data_stat # 偏差=真实值-估计值std = np.std(samples_stat, ddof=1)result = pd.DataFrame({'original': [data_stat], 'bias': [bias], 'std. error': [std]})return result
loans_income = pd.read_csv('loans_income.csv')boost(loans_income['x'], R=1000, statistic='median')
输出:
| original | bias | std. error | |
|---|---|---|---|
| 0 | 62000.0 | -73.1855 | 215.374728 |
2.1.2 Bagging(自助法聚合)
自助法也可用于多变量数据。这时该方法使用数据行作为抽样单元,如下图所示,进而可在自助数据上运行模型,估计模型参数的稳定性(或变异性),或是改进模型的预测能力。我们也可以使用分类和回归树(也称决策树)在自助数据上运行多个树模型,并平均多个树给出的预测值(或是使用分类,并选取多数人的投票),这通常要比使用单个树的预测性能更好。这一过程被称为Bagging方法。
随机森林是将Bagging方法应用于决策树,并做了一个重要的扩展。该算法不仅对记录做抽样,而且也对变量做抽样。
图文引用自《面向数据科学家的实用统计学》第2章——2.4自助法、第6章——6.3 Bagging和随机森林。
数据集下载:
2.2 Feature Bagging
Feature Bagging,基本思想与bagging相似,只是对象是 feature(特征),即只对变量做抽样,不对记录做抽样。Feature Bagging会按样本的特征进行重抽样得到多个数据集,再使用一组(多个)模型对这些数据集进行训练。
Feature bagging属于集成方法的一种。集成方法的设计有以下两个主要步骤:
1.选择基检测器:
这些基本检测器可以彼此完全不同,或不同的参数设置,或使用不同采样的子数据集。Feature bagging常用lof算法为基算法。下图是feature bagging的通用算法:
2.分数标准化和组合方法:
不同检测器可能会在不同的尺度上产生分数。例如,平均k近邻检测器会输出原始距离分数,而LOF算法会输出归一化值。另外,尽管一般情况是输出较大的异常值分数,但有些检测器会输出较小的异常值分数。因此,需要将来自各种检测器的分数转换成可以有意义的组合的归一化值。分数标准化之后,还要选择一个组合函数将不同基本检测器的得分进行组合,最常见的选择包括平均和最大化组合函数。
下图是两个feature bagging两个不同的组合分数方法:
- 一个是广度优先:

- 另外一个是累计求和:

基探测器的设计及其组合方法都取决于特定集成方法的特定目标。很多时候,我们无法得知数据的原始分布,只能通过部分数据去学习。除此以外,算法本身也可能存在一定问题使得其无法学习到数据完整的信息。这些问题造成的误差通常分为偏差和方差两种。
方差:是指算法输出结果与算法输出期望之间的误差,描述模型的离散程度,数据波动性。
偏差:是指预测值与真实值之间的差距。即使在离群点检测问题中没有可用的基本真值
3. Isolation Forests
孤立森林(Isolation Forest)算法是周志华教授等人于2008年提出的异常检测算法,是机器学习中少见的专门针对异常检测设计的算法之一,方法因为该算法时间效率高,能有效处理高维数据和海量数据,无须标注样本,在工业界应用广泛。
孤立森林属于非参数(Non-parametric)和无监督(unsupervised)的算法,既不需要定义数学模型也不需要训练数据有标签。孤立森林查找孤立点(isolated)的策略非常高效。假设我们用一个随机超平面来切割数据空间,切一次可以生成两个子空间。然后我们继续用随机超平面来切割每个子空间并循环,直到每个子空间只有一个数据点为止。直观上来讲,那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。
用四个样本做简单直观的理解,d是最早被孤立出来的,所以d最有可能是异常。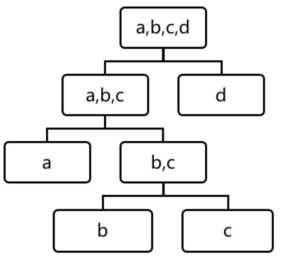
怎么来切这个数据空间是孤立森林的核心思想。因为切割是随机的,为了结果的可靠性,要用集成(ensemble)的方法来得到一个收敛值(蒙特卡洛方法),即反复从头开始切,平均每次切的结果。孤立森林由t棵孤立树组成,每棵树都是一个随机二叉树,也就是说对于树中的每个节点,要么有两个孩子节点,要么一个孩子节点都没有。树的构造方法和随机森林(random forests)中树的构造方法有些类似。流程如下:
获得t棵树之后,孤立森林的训练就结束,就可以用生成的孤立森林来评估测试数据。
孤立森林检测异常的假设是:异常点一般都是非常稀有的,在树中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径长度来判断一条记录是否是异常的。和随机森林类似,孤立森林也是采用构造好的所有树的平均结果形成最终结果的。在训练时,每棵树的训练样本是随机抽样的。从孤立森林的树的构造过程看,它不需要知道样本的标签,而是通过阈值来判断样本是否异常。因为异常点的路径比较短,正常点的路径比较长,孤立森林根据路径长度来估计每个样本点的异常程度。
路径长度计算方法:
孤立森林也是一种基于子空间的方法,不同的分支对应于数据的不同局部子空间区域,较小的路径对应于孤立子空间的低维
4. 总结
1.feature bagging可以降低方差。
2.孤立森林的优势在于:
- 计算成本相比基于距离或基于密度的算法更小。
- 具有线性的时间复杂度。
- 在处理大数据集上有优势。
3.孤立森林不适用于超高维数据,因为鼓励森林每次都是随机选取维度,如果维度过高,则会存在过多噪音。
5. 练习
5.1 使用PyOD库生成toy example并调用feature bagging
from pyod.models.feature_bagging import FeatureBaggingfrom pyod.utils.data import generate_datafrom pyod.utils.data import evaluate_printcontamination = 0.05 # 异常值的比例n_train = 20000 # 训练集样本容量n_test = 10000 # 测试样本容量# 生成样本数据集X_train, y_train, X_test, y_test = generate_data(n_train=n_train, n_test=n_test,n_features=10, contamination=contamination,random_state=2021)# 模型训练model_name = 'FeatureBagging'model = FeatureBagging()model.fit(X_train)y_train_pred = model.labels_ # 训练集训练后生成的标签,0为正常值,1为异常值y_train_scores = model.decision_scores_ # 训练数据的异常值得分params = model.get_params() # 模型参数的估计量# 对测试集进行预测y_test_pred = model.predict(X_test) # 生成测试集的预测标签y_test_scores = model.decision_function(X_test) # 使用合适的探测器预测X的原始异常分数。# 打印评估结果print("\nParams: ", params)print("\nOn Training Data:")evaluate_print(model_name, y_train, y_train_scores)print("\nOn Test Data:")evaluate_print(model_name, y_test, y_test_scores)
Params: {‘base_estimator’: None, ‘bootstrap_features’: False, ‘check_detector’: True, ‘check_estimator’: False, ‘combination’: ‘average’, ‘contamination’: 0.1, ‘estimator_params’: {}, ‘max_features’: 1.0, ‘n_estimators’: 10, ‘n_jobs’: 1, ‘random_state’: None, ‘verbose’: 0}
On Training Data: FeatureBagging ROC:0.3055, precision @ rank n:0.023
On Test Data: FeatureBagging ROC:0.2987, precision @ rank n:0.022
拟合效果看起来很差,稍微调整一下模型参数试试:
model_name = 'FeatureBagging'model = FeatureBagging(contamination=0.05,n_estimators = 30,combination='max',max_features=0.5)model.fit(X_train)y_train_pred = model.labels_y_train_scores = model.decision_scores_params = model.get_params()# 对测试集进行预测y_test_pred = model.predict(X_test)y_test_scores = model.decision_function(X_test)# 打印评估结果print("\nParams: ", params)print("\nOn Training Data:")evaluate_print(model_name, y_train, y_train_scores)print("\nOn Test Data:")evaluate_print(model_name, y_test, y_test_scores)
Params: {‘base_estimator’: None, ‘bootstrap_features’: False, ‘check_detector’: True, ‘check_estimator’: False, ‘combination’: ‘max’, ‘contamination’: 0.05, ‘estimator_params’: {}, ‘max_features’: 0.5, ‘n_estimators’: 30, ‘n_jobs’: 1, ‘random_state’: None, ‘verbose’: 0}
On Training Data: FeatureBagging ROC:0.4762, precision @ rank n:0.207
On Test Data: FeatureBagging ROC:0.4824, precision @ rank n:0.232
ROC还是小于0.5,对算法理解还不够,还需要再查查资料,了解如何优化Feature Bagging。
参考API文档 https://pyod.readthedocs.io/en/latest/pyod.models.html#module-pyod.models.feature_bagging
5.2 使用PyOD库生成toy example并调用Isolation Forests
from pyod.models.iforest import IForestfrom pyod.utils.data import generate_datafrom pyod.utils.data import evaluate_printcontamination = 0.05 # 异常值的比例n_train = 20000 # 训练集样本容量n_test = 10000 # 测试样本容量# 生成样本数据集X_train, y_train, X_test, y_test = generate_data(n_train=n_train, n_test=n_test,n_features=20, contamination=contamination,random_state=2021)# 模型训练model_name = 'IForest'model = IForest()model.fit(X_train)y_train_pred = model.labels_ # 训练集训练后生成的标签,0为正常值,1为异常值y_train_scores = model.decision_scores_ # 训练数据的异常值得分params = model.get_params() # 模型参数的估计量# 对测试集进行预测y_test_pred = model.predict(X_test) # 生成测试集的预测标签y_test_scores = model.decision_function(X_test) # 使用合适的探测器预测X的原始异常分数。# 打印评估结果print("\nParams: ", params)print("\nOn Training Data:")evaluate_print(model_name, y_train, y_train_scores)print("\nOn Test Data:")evaluate_print(model_name, y_test, y_test_scores)
Params: {‘behaviour’: ‘old’, ‘bootstrap’: False, ‘contamination’: 0.1, ‘max_features’: 1.0, ‘max_samples’: ‘auto’, ‘n_estimators’: 100, ‘n_jobs’: 1, ‘random_state’: None, ‘verbose’: 0}
On Training Data: IForest ROC:1.0, precision @ rank n:1.0
On Test Data:
IForest ROC:1.0, precision @ rank n:1.0
Isolation Forests 比 Feature Bagging快很多,而且正确率也高很多。
参考API文档
https://pyod.readthedocs.io/en/latest/pyod.models.html#module-pyod.models.iforest
5.3 (思考题:feature bagging为什么可以降低方差?)
回答:
模型的方差是由模型的期望和偏差所决定。
Bagging通常选用偏差低的强学习器,且Bagging使用自助法从同一样本进行抽样,使得Bagging整体模型的期望近似于单模型的期望,所以Bagging方法也可以降低方差。基于Bagging思想的Feature Bagging也可以降低方差。
5.4 (思考题:feature bagging存在哪些缺陷,有什么可以优化的idea?)
回答:
①缺陷:由于Bagging需要进行多次重抽样和计算,需要消耗大量的空间和时间。
②优化:在数据准备阶段,先进行预处理,尝试减少和标签相关性比较低的特征。
参考文献
[1]Goldstein, M. and Dengel, A., 2012. Histogram-based outlier score (hbos):A fast unsupervised anomaly detection algorithm . InKI-2012: Poster and Demo Track, pp.59-63.
[2]https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf
[3]《Outlier Analysis》——Charu C. Aggarwal

若有收获,就点个赞吧
0 人点赞
