练习一: 各部门工资最高的员工(难度:中等)
创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
创建Department 表,包含公司所有部门的信息。
| Id | Name |
|---|---|
| 1 | IT |
| 2 | Sales |
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| Sales | Henry | 80000 |
回答:
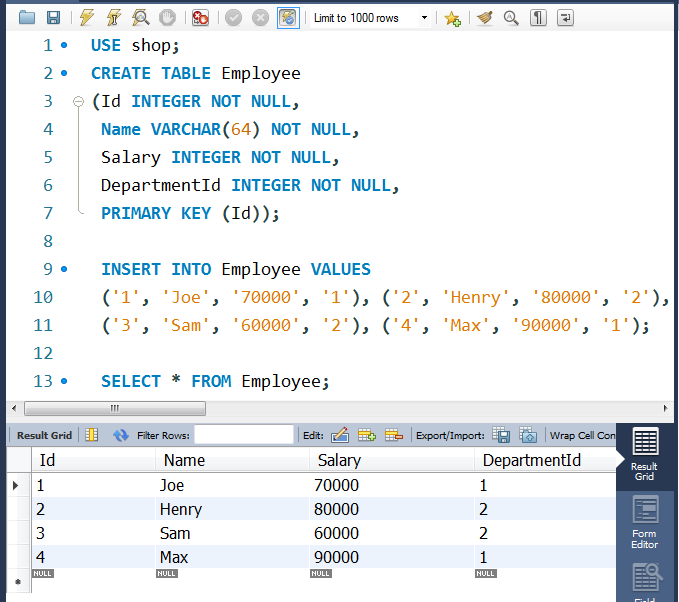
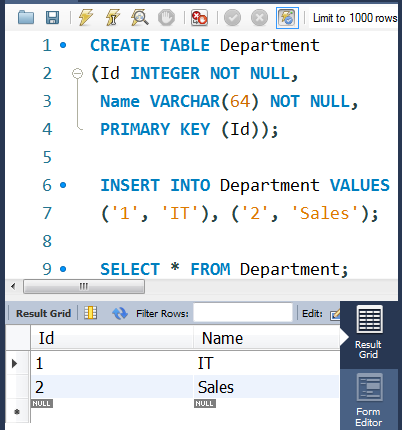
①创表和更新数据
-- 员工信息表-- USE shop;CREATE TABLE Employee(Id INTEGER NOT NULL,Name VARCHAR(64) NOT NULL,Salary INTEGER NOT NULL,DepartmentId INTEGER NOT NULL,PRIMARY KEY (Id));INSERT INTO Employee VALUES('1', 'Joe', '70000', '1'), ('2', 'Henry', '80000', '2'),('3', 'Sam', '60000', '2'), ('4', 'Max', '90000', '1');-- SELECT * FROM Employee;-- 部门信息表CREATE TABLE Department(Id INTEGER NOT NULL,Name VARCHAR(64) NOT NULL,PRIMARY KEY (Id));INSERT INTO Department VALUES('1', 'IT'), ('2', 'Sales');-- SELECT * FROM Department;
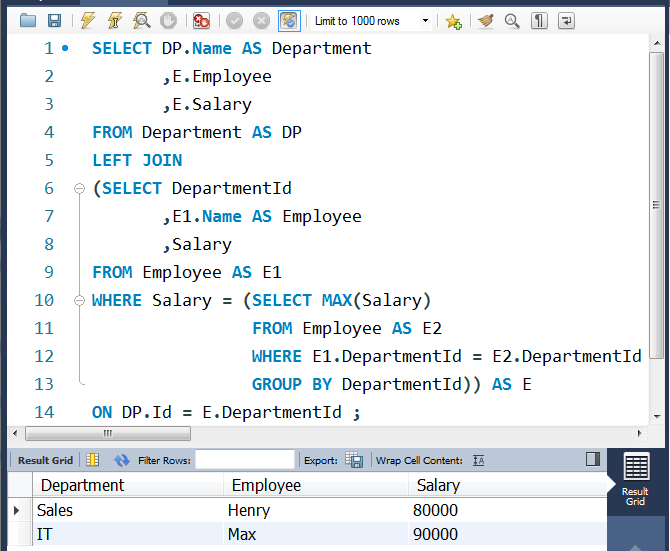
②查询每个部门工资最高的员工
SELECT DP.Name AS Department
,E.Employee
,E.Salary
FROM Department AS DP
LEFT JOIN
(SELECT DepartmentId
,E1.Name AS Employee
,Salary
FROM Employee AS E1
WHERE Salary = (SELECT MAX(Salary)
FROM Employee AS E2
WHERE E1.DepartmentId = E2.DepartmentId
GROUP BY DepartmentId)) AS E
ON DP.Id = E.DepartmentId ;
练习二: 换座位(难度:中等)
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。其中纵列的id是连续递增的。
小美想改变相邻俩学生的座位。你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
请创建如下所示seat表:
示例:
| id | student |
|---|---|
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
假如数据输入的是上表,则输出结果如下:
| id | student |
|---|---|
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
回答:
①数据准备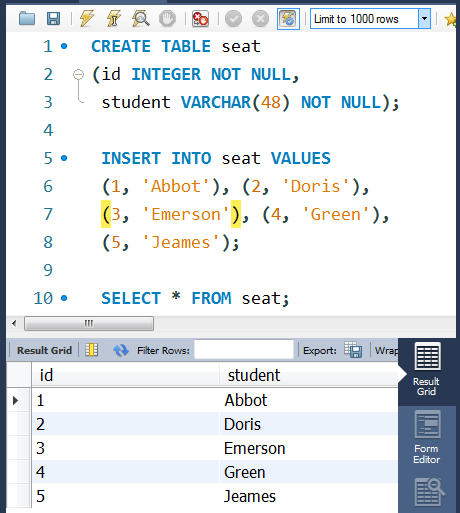
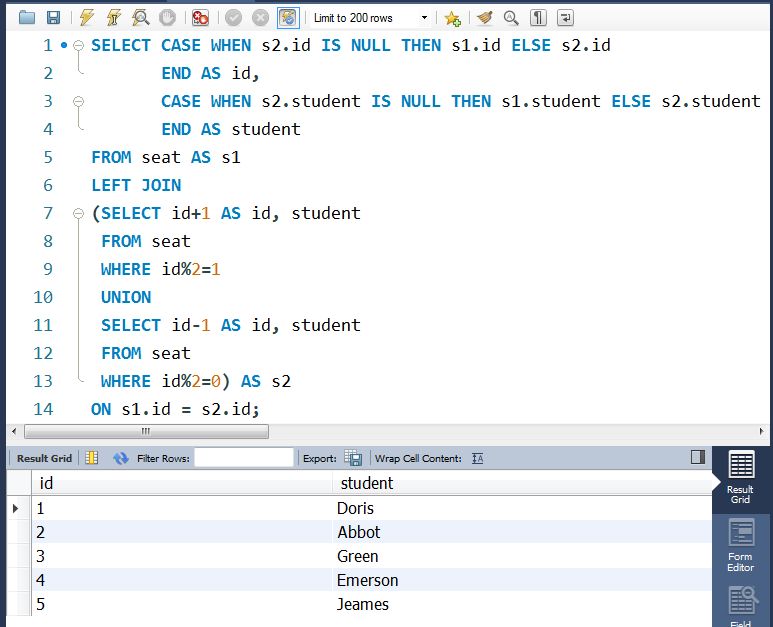
②编写SQL语句:
SELECT CASE WHEN s2.id IS NULL THEN s1.id
ELSE s2.id
END AS id,
CASE WHEN s2.student IS NULL THEN s1.student
ELSE s2.student
END AS student
FROM seat AS s1
LEFT JOIN
(SELECT id+1 AS id, student
FROM seat
WHERE id%2=1
UNION
SELECT id-1 AS id, student
FROM seat
WHERE id%2=0) AS s2
ON s1.id = s2.id;
练习三: 分数排名(难度:中等)
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
创建以下Scores表:
| Id | Score |
|---|---|
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
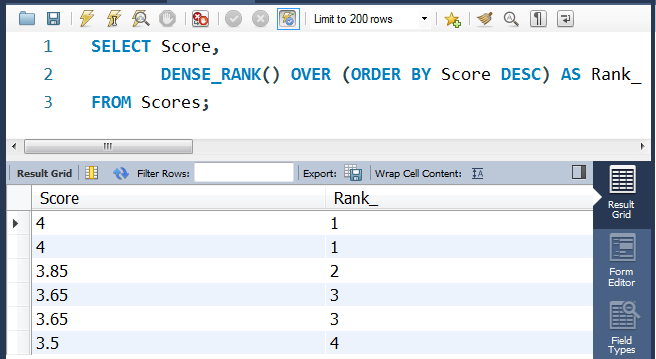
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
| Score | Rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
回答:
①数据准备: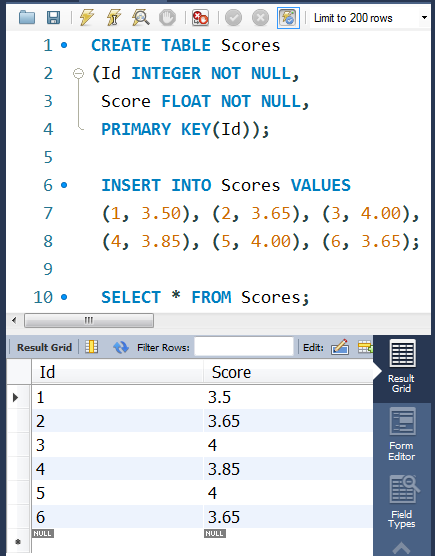
②编写SQL语句:
SELECT Score,
DENSE_RANK() OVER (ORDER BY Score DESC) AS Rank_
FROM Scores;
练习四:连续出现的数字(难度:中等)
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
| Id | Num |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
例如,给定上面的 Logs 表, 1 是唯一连续出现至少三次的数字。
| ConsecutiveNums |
|---|
| 1 |
回答:
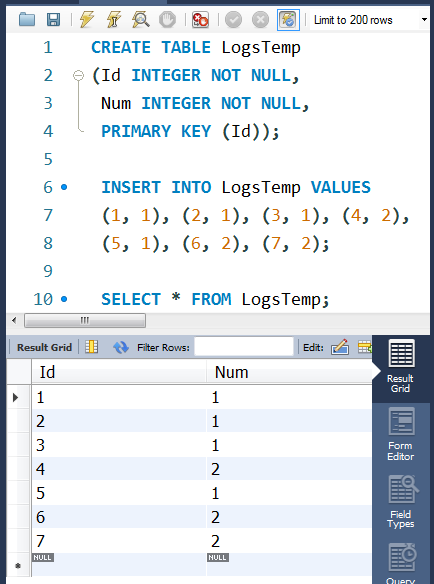
①数据准备:Logs好像会和MySQL关键字冲突。这里避免冲突,改了一下表名。
CREATE TABLE LogsTemp
(Id INTEGER NOT NULL,
Num INTEGER NOT NULL,
PRIMARY KEY (Id));
INSERT INTO LogsTemp VALUES
(1, 1), (2, 1), (3, 1), (4, 2),
(5, 1), (6, 2), (7, 2);
-- SELECT * FROM LogsTemp;
②编写SQL语句:
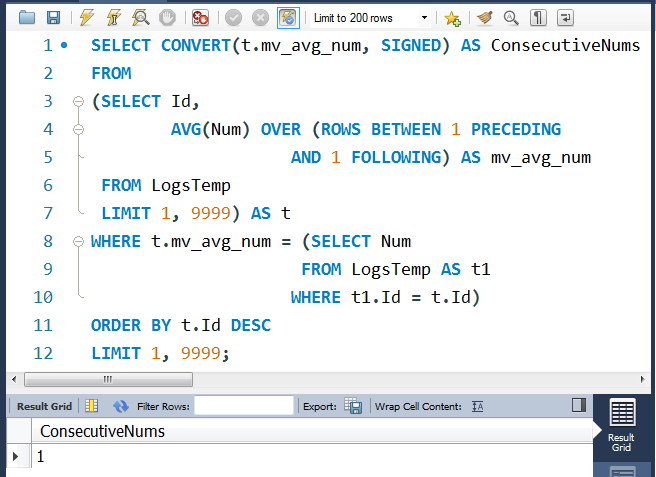
SELECT CONVERT(t.mv_avg_num, SIGNED) AS ConsecutiveNums
FROM
(SELECT Id,
AVG(Num) OVER (ROWS BETWEEN 1 PRECEDING
AND 1 FOLLOWING) AS mv_avg_num
FROM LogsTemp
LIMIT 1, 9999) AS t
WHERE t.mv_avg_num = (SELECT Num
FROM LogsTemp AS t1
WHERE t1.Id = t.Id)
ORDER BY t.Id DESC
LIMIT 1, 9999;
练习五:树节点 (难度:中等)
对于tree表,id是树节点的标识,p_id是其父节点的id。
| id | p_id |
|---|---|
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
每个节点都是以下三种类型中的一种:
- Root: 如果节点是根节点。
- Leaf: 如果节点是叶子节点。
- Inner: 如果节点既不是根节点也不是叶子节点。
写一条查询语句打印节点id及对应的节点类型。按照节点id排序。上面例子的对应结果为:
| id | Type |
|---|---|
| 1 | Root |
| 2 | Inner |
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
说明
- 节点‘1’是根节点,因为它的父节点为NULL,有‘2’和‘3’两个子节点。
- 节点‘2’是内部节点,因为它的父节点是‘1’,有子节点‘4’和‘5’。
- 节点‘3’,‘4’,’5’是叶子节点,因为它们有父节点但没有子节点。
下面是树的图形:
1/ \
2 3
/ \ 4 5
注意:
如果一个树只有一个节点,只需要输出根节点属性。
回答:
①数据准备:
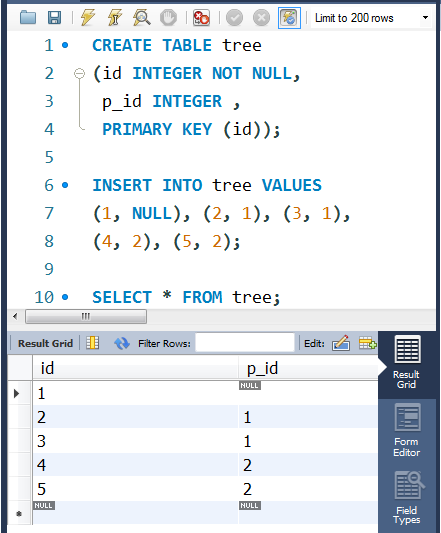
CREATE TABLE tree
(id INTEGER NOT NULL,
p_id INTEGER ,
PRIMARY KEY (id));
INSERT INTO tree VALUES
(1, NULL), (2, 1), (3, 1),
(4, 2), (5, 2);
-- SELECT * FROM tree;
②编写SQL语句:
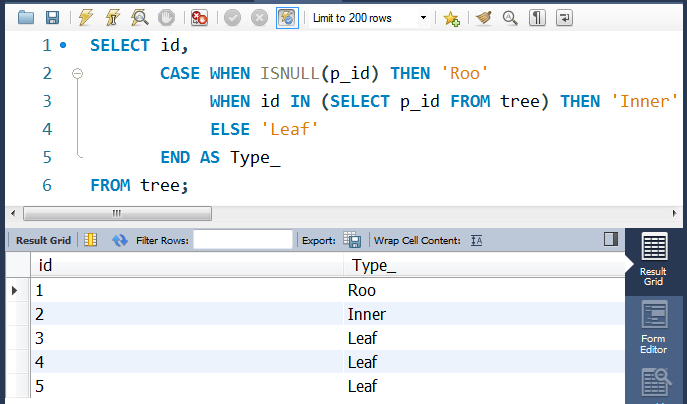
SELECT id,
CASE WHEN ISNULL(p_id) THEN 'Roo'
WHEN id IN (SELECT p_id FROM tree) THEN 'Inner'
ELSE 'Leaf'
END AS Type_
FROM tree;
练习六:至少有五名直接下属的经理 (难度:中等)
Employee表包含所有员工及其上级的信息。每位员工都有一个Id,并且还有一个对应主管的Id(ManagerId)。
| Id | Name | Department | ManagerId |
|---|---|---|---|
| 101 | John | A | null |
| 102 | Dan | A | 101 |
| 103 | James | A | 101 |
| 104 | Amy | A | 101 |
| 105 | Anne | A | 101 |
| 106 | Ron | B | 101 |
针对Employee表,写一条SQL语句找出有5个下属的主管。对于上面的表,结果应输出:
| Name |
|---|
| John |
注意:
没有人向自己汇报。
回答:
①数据准备:
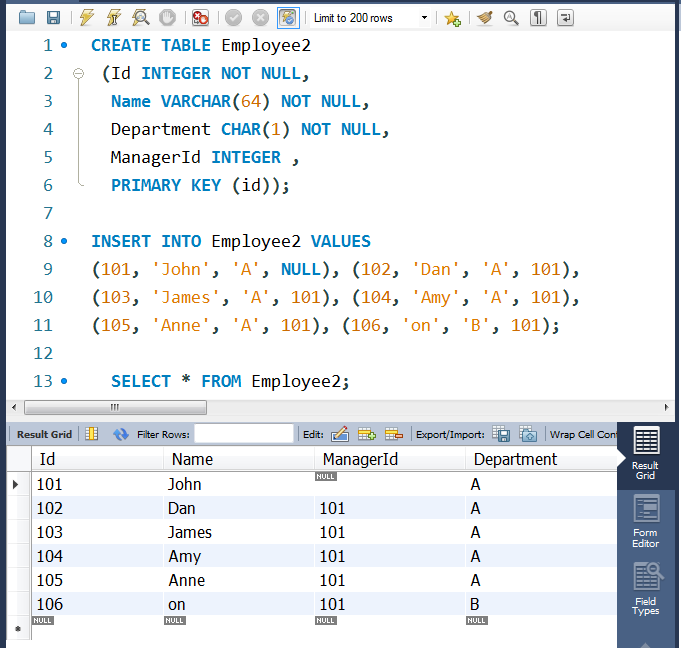
CREATE TABLE Employee2
(Id INTEGER NOT NULL,
Name VARCHAR(64) NOT NULL,
Department CHAR(1) NOT NULL,
ManagerId INTEGER ,
PRIMARY KEY (id));
INSERT INTO Employee2 VALUES
(101, 'John', 'A', NULL), (102, 'Dan', 'A', 101),
(103, 'James', 'A', 101), (104, 'Amy', 'A', 101),
(105, 'Anne', 'A', 101), (106, 'on', 'B', 101);
-- SELECT * FROM Employee2;
②编写SQL语句:
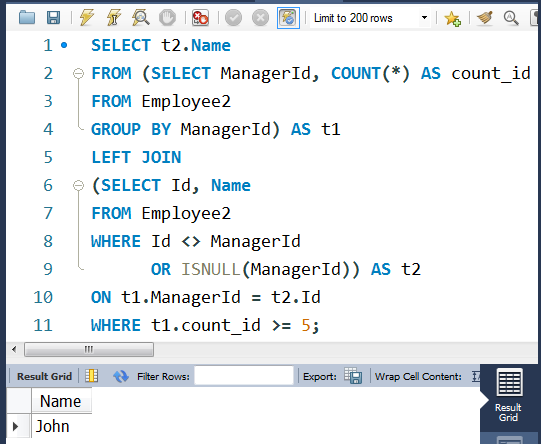
SELECT t2.Name
FROM (SELECT ManagerId, COUNT(*) AS count_id
FROM Employee2
GROUP BY ManagerId) AS t1
LEFT JOIN
(SELECT Id, Name
FROM Employee2
WHERE Id <> ManagerId
OR ISNULL(ManagerId)) AS t2
ON t1.ManagerId = t2.Id
WHERE t1.count_id >= 5;
练习七: 分数排名 (难度:中等)
练习三的分数表,实现排名功能,但是排名需要是非连续的,如下:
| Score | Rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 3 |
| 3.65 | 4 |
| 3.65 | 4 |
| 3.50 | 6 |
回答:
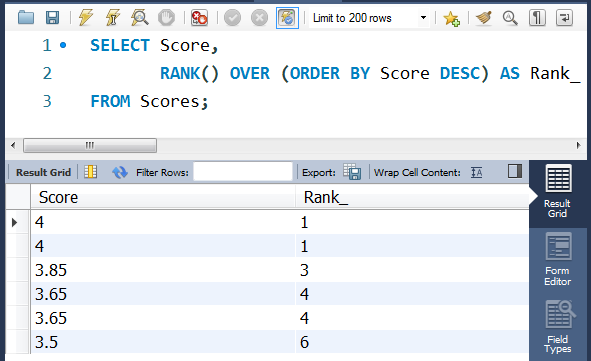
SELECT Score,
RANK() OVER (ORDER BY Score DESC) AS Rank_
FROM Scores;
练习八:查询回答率最高的问题 (难度:中等)
求出survey_log表中回答率最高的问题,表格的字段有:uid, action, question_id, answer_id, q_num, timestamp。
uid是用户id;action的值为:”show”, “answer”, “skip”;当action是”answer”时,answer_id不为空,相反,当action是”show”和”skip”时为空(null);q_num是问题的数字序号。
写一条sql语句找出回答率最高的问题。
举例:
输入
| uid | action | question_id | answer_id | q_num | timestamp |
|---|---|---|---|---|---|
| 5 | show | 285 | null | 1 | 123 |
| 5 | answer | 285 | 124124 | 1 | 124 |
| 5 | show | 369 | null | 2 | 125 |
| 5 | skip | 369 | null | 2 | 126 |
输出
| survey_log |
|---|
| 285 |
说明:
问题285的回答率为1/1,然而问题369的回答率是0/1,所以输出是285。
注意:最高回答率的意思是:同一个问题出现的次数中回答的比例。
回答:
①数据准备:
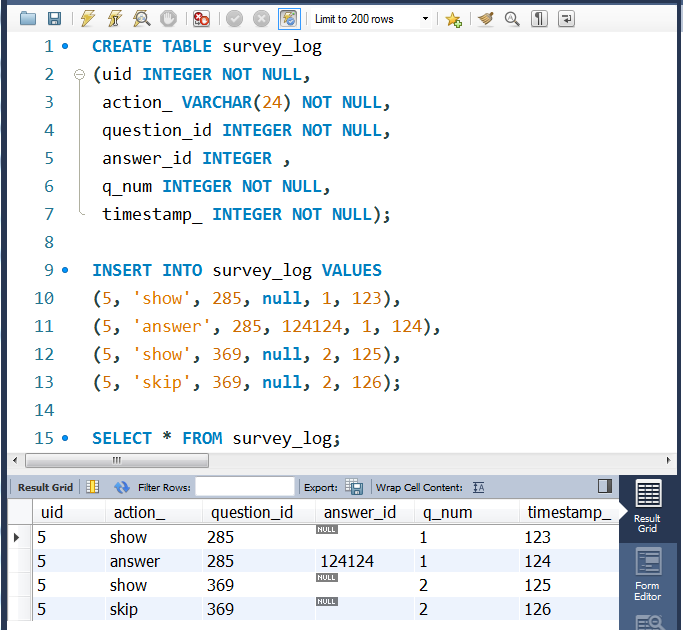
CREATE TABLE survey_log
(uid INTEGER NOT NULL,
action_ VARCHAR(24) NOT NULL,
question_id INTEGER NOT NULL,
answer_id INTEGER ,
q_num INTEGER NOT NULL,
timestamp_ INTEGER NOT NULL);
INSERT INTO survey_log VALUES
(5, 'show', 285, null, 1, 123),
(5, 'answer', 285, 124124, 1, 124),
(5, 'show', 369, null, 2, 125),
(5, 'skip', 369, null, 2, 126);
-- SELECT * FROM survey_log;
②编写SQL语句:
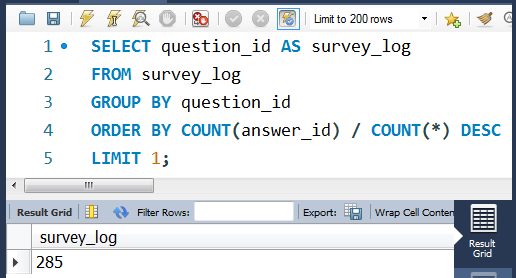
SELECT question_id AS survey_log
FROM survey_log
GROUP BY question_id
ORDER BY COUNT(answer_id) / COUNT(*) DESC -- 根据回答率进行排名
LIMIT 1; -- 取排名最高的一个
练习九:各部门前3高工资的员工(难度:中等)
将项目7练习1中的employee表清空,重新插入以下数据(其实是多插入5,6两行):
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
编写一个 SQL 查询,找出每个部门工资前三高的员工。例如,根据上述给定的表格,查询结果应返回:
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
此外,请考虑实现各部门前N高工资的员工功能。
回答:
①数据准备
INSERT INTO Employee VALUES
(5, 'Janet', 69000, 1),
(6, 'Randy', 85000, 1);
-- SELECT * FROM Employee;
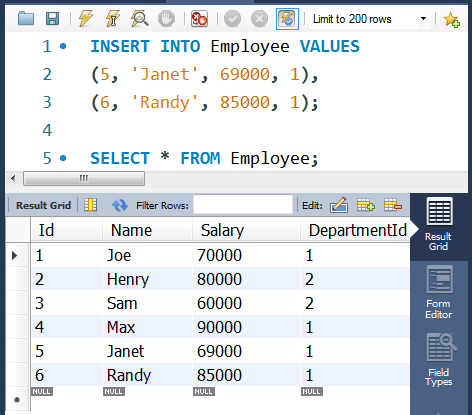
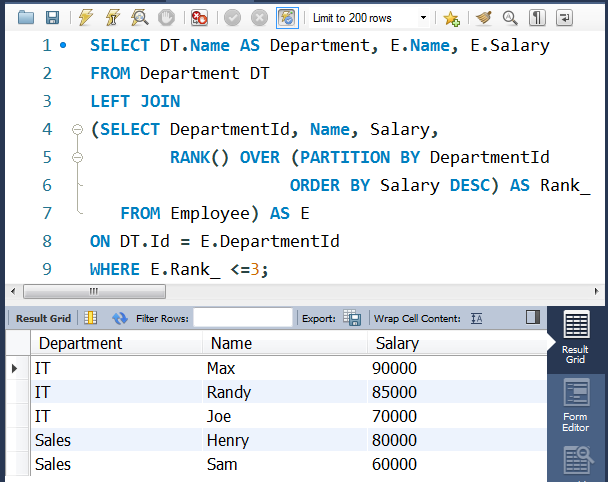
②编写SQL语句:
SELECT DT.Name AS Department,
E.Name,
E.Salary
FROM Department DT
LEFT JOIN
(SELECT DepartmentId,
Name,
Salary,
RANK() OVER (PARTITION BY DepartmentId
ORDER BY Salary DESC) AS Rank_
FROM Employee) AS E
ON DT.Id = E.DepartmentId
WHERE E.Rank_ <=3;
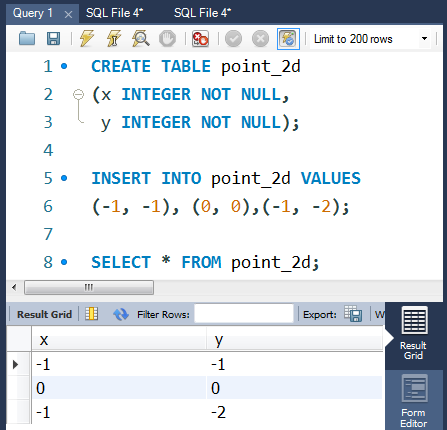
练习十:平面上最近距离 (难度: 困难)
point_2d表包含一个平面内一些点(超过两个)的坐标值(x,y)。
写一条查询语句求出这些点中的最短距离并保留2位小数。
| x | y |
|---|---|
| -1 | -1 |
| 0 | 0 |
| -1 | -2 |
最短距离是1,从点(-1,-1)到点(-1,-2)。所以输出结果为:
| shortest |
|---|
| 1.00 |
注意: 所有点的最大距离小于10000。
回答:
数据准备
CREATE TABLE point_2d
(x INTEGER NOT NULL,
y INTEGER NOT NULL);
INSERT INTO point_2d VALUES
(-1, -1), (0, 0),(-1, -2);
-- SELECT * FROM point_2d;
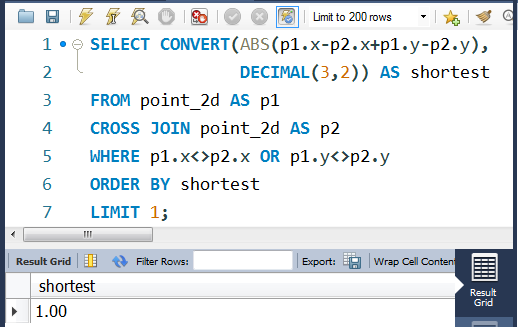
编写SQL语句:
SELECT CONVERT(ABS((p1.x-p2.x)+(p1.y-p2.y)),
DECIMAL(3,2)) AS shortest
FROM point_2d AS p1
CROSS JOIN point_2d AS p2
WHERE p1.x<>p2.x OR p1.y<>p2.y
ORDER BY shortest
LIMIT 1;
练习十一:行程和用户(难度:困难)
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
| Id | Client_Id | Driver_Id | City_Id | Status | Request_at |
|---|---|---|---|---|---|
| 1 | 1 | 10 | 1 | completed | 2013-10-1 |
| 2 | 2 | 11 | 1 | cancelled_by_driver | 2013-10-1 |
| 3 | 3 | 12 | 6 | completed | 2013-10-1 |
| 4 | 4 | 13 | 6 | cancelled_by_client | 2013-10-1 |
| 5 | 1 | 10 | 1 | completed | 2013-10-2 |
| 6 | 2 | 11 | 6 | completed | 2013-10-2 |
| 7 | 3 | 12 | 6 | completed | 2013-10-2 |
| 8 | 2 | 12 | 12 | completed | 2013-10-3 |
| 9 | 3 | 10 | 12 | completed | 2013-10-3 |
| 10 | 4 | 13 | 12 | cancelled_by_driver | 2013-10-3 |
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(’client’, ‘driver’, ‘partner’)的枚举类型。
| Users_Id | Banned | Role |
|---|---|---|
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
写一段 SQL 语句查出2013年10月1日至2013年10月3日期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
| Day | Cancellation Rate |
|---|---|
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
回答:
创表:
CREATE TABLE Trips
(Id SMALLINT UNSIGNED NOT NULL REFERENCES Users(Users_Id),
Client_Id SMALLINT UNSIGNED NOT NULL REFERENCES Users(Users_Id),
Driver_Id SMALLINT UNSIGNED NOT NULL,
City_Id SMALLINT UNSIGNED NOT NULL,
Status_ ENUM('completed',
'cancelled_by_driver',
'cancelled_by_client') NOT NULL,
Request_at DATE NOT NULL );
CREATE TABLE Users
(Users_Id SMALLINT UNSIGNED NOT NULL,
Banned VARCHAR(12) NOT NULL,
Role_ ENUM('client', 'driver', 'partner') NOT NULL);
更新数据:
INSERT INTO Trips VALUES
(1, 1, 10, 1, 'completed', '2013-10-1'),
(2, 2, 11, 1, 'cancelled_by_driver', '2013-10-1'),
(3, 3, 12, 6, 'completed', '2013-10-1'),
(4, 4, 13, 6, 'cancelled_by_client', '2013-10-1'),
(5, 1, 10, 1, 'completed', '2013-10-2'),
(6, 2, 11, 6, 'completed', '2013-10-2'),
(7, 3, 12, 6, 'completed', '2013-10-2'),
(8, 2, 12, 12, 'completed', '2013-10-3'),
(9, 3, 10, 12, 'completed', '2013-10-3'),
(10, 4, 13, 12, 'cancelled_by_driver', '2013-10-3');
-- SELECT * FROM Trips;
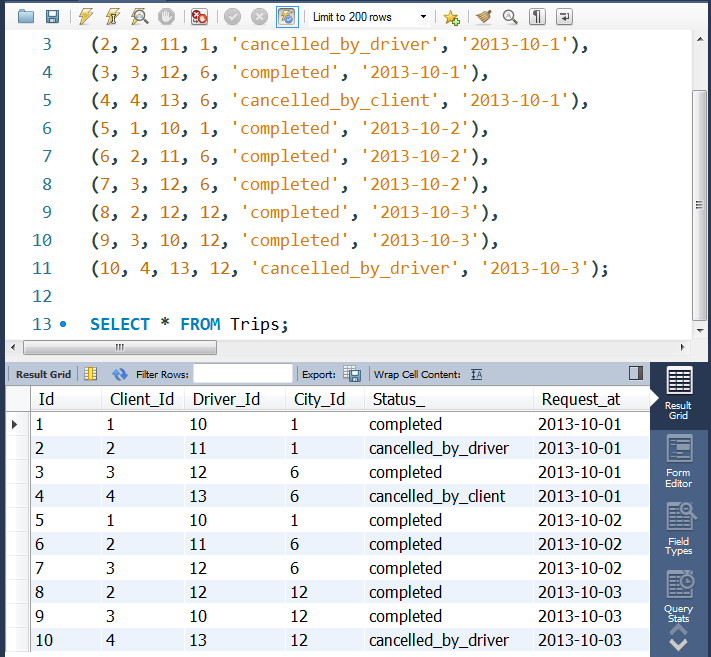
INSERT INTO Users VALUES
(1, 'No', 'client'), (2, 'Yes', 'client'),
(3, 'No', 'client'), (4, 'No', 'client'),
(10, 'No', 'driver'), (11, 'No', 'driver'),
(12, 'No', 'driver'), (13, 'No', 'driver');
-- SELECT * FROM Users;
问题拆解:
- 查询2013年10月1日至2013年10月3日期间的记录,为集合A;
- 查询非禁止用户的记录,为集合B;
- 求集合A与集合B的交集,为集合C;
汇总集合C的取消人数和总人数,计算取消率,并保留2位小数。- 按日期分组汇总集合C的取消人数,为字段cancel
- 按日期分组汇总集合C的总人数,为字段total
- cancel/total 就是所求的取消率了。
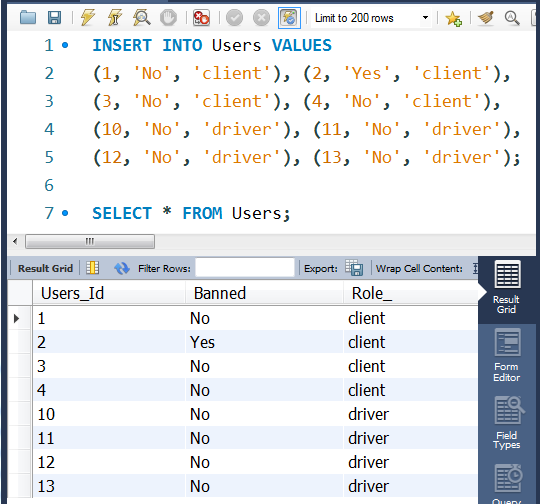
编写SQL语句:
拆解的部分
-- 查询2013年10月1日至2013年10月3日期间的记录,为集合A;
SELECT *
FROM Trips
WHERE Request_at BETWEEN '2013-10-1' AND '2013-10-3';
-- 查询非禁止用户的记录,为集合B;
SELECT Users_id
FROM Users
WHERE Banned = 'No';
-- 查询取消的记录;
SELECT *
FROM Trips
WHERE Status_ <> 'completed';
-- 求集合A与集合B的交集,为集合C;
-- 并按日期分组汇总集合C的取消人数
SELECT Request_at, COUNT(*)
FROM Trips
WHERE Request_at BETWEEN '2013-10-1' AND '2013-10-3'
AND Status_ <> 'completed'
AND Client_Id in (SELECT Users_id /* 注意这里要用Client_Id */
FROM Users
WHERE Banned = 'NO')
GROUP BY Request_at;
-- 按日期分组汇总集合C的总人数
SELECT Request_at, COUNT(*) AS total
FROM Trips
WHERE Request_at BETWEEN '2013-10-1' AND '2013-10-3'
AND Client_Id in (SELECT Users_id
FROM Users
WHERE Banned = 'NO')
GROUP BY Request_at;
合并拆解的内容
SELECT t2.Request_at AS Day,
CASE WHEN t1.cancel IS NULL THEN 0
ELSE ROUND(t1.cancel/t2.total, 2)
END AS `Cancellation Rate`
FROM
(SELECT Request_at, COUNT(*) AS cancel
FROM Trips
WHERE Request_at BETWEEN '2013-10-1' AND '2013-10-3'
AND Status_ <> 'completed'
AND Client_Id in (SELECT Users_id
FROM Users
WHERE Banned = 'NO')
GROUP BY Request_at) AS t1
RIGHT JOIN
(SELECT Request_at, COUNT(*) AS total
FROM Trips
WHERE Request_at BETWEEN '2013-10-1' AND '2013-10-3'
AND Client_Id in (SELECT Users_id
FROM Users
WHERE Banned = 'NO')
GROUP BY Request_at) AS t2
ON t2.Request_at = t1.Request_at;
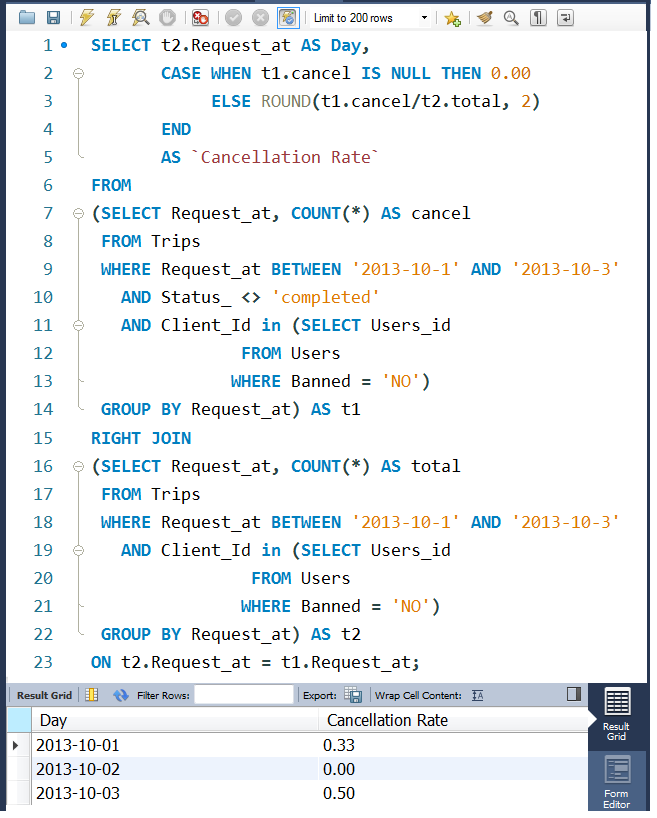
优化后的SQL语句:
SELECT t.Request_at AS Day,
ROUND(SUM(t.status_)/COUNT(*), 2) AS `Cancellation Rate`
FROM
(SELECT Request_at,
CASE WHEN Status_='completed' THEN 0 ELSE 1 END AS status_
FROM Trips
WHERE Request_at BETWEEN '2013-10-1' AND '2013-10-3'
AND Client_Id in (SELECT Users_id
FROM Users
WHERE Banned = 'NO')) AS t
GROUP BY t.Request_at;

若有收获,就点个赞吧
0 人点赞
