指标体系
标签作业效率(ETL)
标签监控
实时计算
画像产品化
业务应用场景和应用方式
从0到1搭建用户画像系统:
离线标签开发
用户数据分析
ETL调度
流式计算开发
打通数据服务层
应用画像数据服务业务方
获得业务增长的反馈
画像系统的子模块:
如何建立标签指标体系?
指标体系中包含哪些标签?
如何设计储存画像标签的表结构?
如何开发标签?
画像系统中涉及哪些数据存储工具?
如何打通标签数据到服务层?
如何对画像系统进行监控?
如何对整个画像系统进行调度?
如何使用画像系统服务于业务场景来驱动增长?
一套好的解决方案,需要包含的几个层面:
1)架构层
数据仓库
数据存储技术选型
整个项目的开发流程和各阶段的关键产出
2)流量层
整个方案是如何运作起来的
画像系统的作业流程调度
数据仓库和各业务系统的打通
3)业务层
画像系统的前后端交互
画像系统如何应用在业务服务层面
4)方案价值
画像系统上线后如何服务于各业务场景,产生业务价值
方案迭代
数据的最终目的是走出数据仓库,应用到业务系统和营销系统中,来驱动营收增长
电商精细化运营:人群标签
用户价值体系
我做过电商运营,电商运营中经常会用到用户画像的应用,比如在做RFM用户价值分析的时候,…..。对用户画像的数据有业务上的理解。相对更能理解数据和标签在业务上的含义。
使用用户画像。把产品推给有xx标签的用户群体。(b站视频回看复习。简历里面添加作品 Excel talebu 词云)
目标用户
用户标签=固定属性+用户路径+用户场景
短时间内不会发生变化,包括用户年龄、性别、职业、地区、学历等。
用户标签只是用户画像的中间过程,呈现的只是用户画像的基本轮廓,而不是的画像结果。新媒体运营者需要在用户标签的基础上进行画像描述,以呈现完整的用户特征。
描述用户画像看起来只是一个写作文或写剧本的过程,按照标签进行文字延展。但是在具体描述时,需要做到完整化、细节化。完整化即用户行为全过程完整表述,不能人为地跳过一些步骤;细节化即具体描述用户数场景,不可以一笔带过。
大数据不具备完整维度,百度指数只代表行业搜索大数据,微指数只代表行业讨论大数据,微信指数只代表事件热度大数据。
行业大数据不代表企业大数据,每一家企业的粉丝或消费者都有其独特性,不能用全部网民的网络行为来代表企业用户的互联网特征。
新媒体运营者需要根据企业实际情况,决定是否使用大数据进行画像。
基础数据采集→分析关键词和建模→分析用户画像
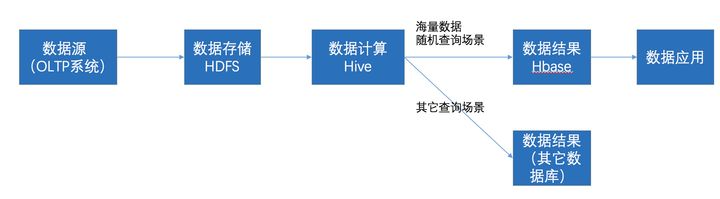
1. 用户画像基础
1.1 用户画像是什么?
用户的一切行为在企业面前是可“追溯”“分析”的。
1.1.1 画像简介
用户画像,即用户信息标签化,通过收集用户的社会属性、消费习惯、偏好特征等各个维度的数据,进而对用户或者产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘潜在价值信息,从而抽象出用户的信息全貌。
用户画像是企业应用大数据的根基,是定向广告投放与个性化推荐的前置条件,为数据驱动运营奠定了基础。
传统报表和大数据的区别:
“数据静止在数据仓库,是死的”
用户画像可以帮助大数据“走出”数据仓库,针对用户进行个性化推荐、精准营销、个性化服务等多样化服务,是大数据落地应用的一个重要方向。
1.1.2 标签类型
用户建模就是对用户“打标签”。
标签的3种类型:
①统计类标签
性别、年龄、城市、近7日活跃时长、近7日活跃天数
可以从用户注册数据、用户访问、消费数据中统计得出。
②规则类标签
“近30天交易次数≥2” →打标签→ “消费活跃”
基于用户行为及确定的规则产生。
运营人员熟悉业务,数据人员熟悉数据:由运营人员和数据人员共同协商确定。
③机器学习挖掘类标签
用户行为习惯\消费习惯→打标签→“性别”
机器学习算法挖掘数据隐含信息
在项目工程实践中,一般统计类和规则类的标签即可以满足应用需求,在开发中占有较大比例。
机器学习挖掘类标签多用于预测场景,如判断用户性别、用户购买商品偏好、用户流失意向等。
一般地,机器学习标签开发周期较长,开发成本较高,因此其开发所占用比例较小。
1.2 数据架构
在整个工程化方中,系统依赖的础设施包括Spark、Hive、HBase、Airflow、MySQL、Redis、Elasticsearch。除去基础设施外,系统主题还包括 Spark Streaming、ETL、产品端3个重要组成部分。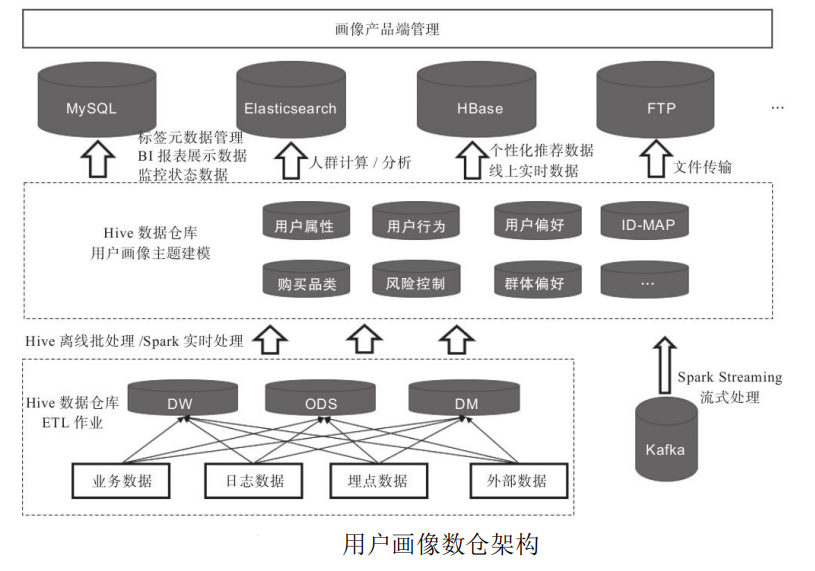
业务数据、日志数据、埋点数据 →[ ETL ]→ 数据仓库对应的ODS层、DW层、DM层
↓
MySQL、HBase、Elasticsearch ← [ 同步 ] ← 用户标签(HIVE) ← [ 二次建模加工 ]

反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。 搜索引擎原理就是建立反向索引。 Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。 Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。 Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。 Elasticsearch 一个典型应用就是 ELK 日志分析系统。
[
](https://developer.51cto.com/art/201904/594615.htm)
1.3 主要覆盖模块
搭建一套用户画像方案整体来说,需要考虑以下8个看的建设:
1)用户画像基础:需要了解、明确用户画像是什么,包含哪些模块,数据仓库架构是什么样子,开发流程,表结构设计,ETL设计等。
这些都是框架,大方向的规划。只有明确了方向,后续才能做好项目的排期和人员投入预算。这对于评估每个开发阶段重要指标和关键产出非常重要。
2)数据指标体系:根据业务线梳理,包括用户属性、用户行为、用户消费、风险控制等维度的指标体系。
3)标签数据储存:标签相关数据可储存在Hive、Mysql、HBase、Elasticsearch等数据库中,不同储存方式适用于不同的应用场景。
4)标签数据开发:用户画像工程化的重点模块,包含统计类、规则类、挖掘类、流式计算标签的开发,以及人群计算功能的开发,打通画像数据和各业务系统之间的道路,提供接口服务等开发内容。
5)开发性能调优:标签加工、人群计算等脚本上线调度后,为了缩短调度时间、保障数据的稳定性等,需要对开发的脚本进行迭代重构、调优。
6)作业流程调度:标签加工、人群计算、同步数据到业务系统、数据监控预警等脚本开发完成后,需要调度工具把整套流程调度起来。本书讲解了Airflow这款开源ETL工具在调度画像相关任务脚本上的应用。
7)用户画像产品化:为了能让用户数据更好地服务于业务方,需要以产品话的形态应用在业务上。产品化的模块主要包括标签视图、用户标签查询、用户分群、透视分析。
8)用户画像应用:画像的应用场景包括用户特征分析、短信、邮件、站内信、Push信息的精准推送、客服针对用户的不同话术、针对高价值用户的极速退货退款等VIP服务应用。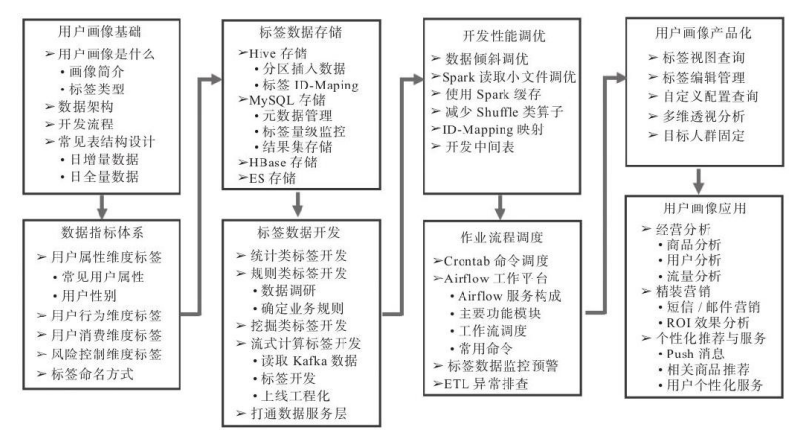
1.4 开发阶段流程
1.4.1 开发上线流程
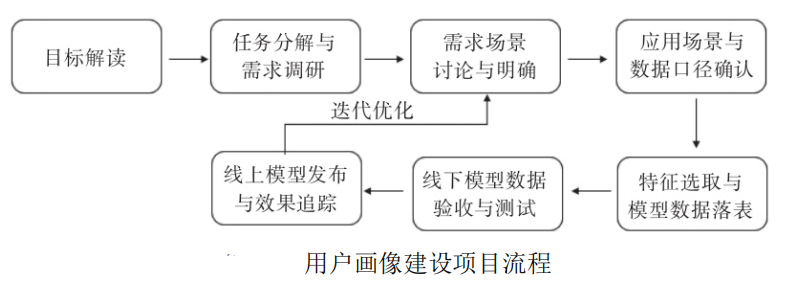
第一阶段:目标解读
在建立用户画像前,首先需要明确用户画像服务于企业的对象,再根据业务方需求,明确未来产品建设目标和用户画像分析之后的预期效果。
一般而言,用户画像的服务对象包括运营人员和数据分析人员。不同业务方对用户画像的需求有不同的侧重点,就运营人员来说,他们需要分析用户的特征、定位用户行为偏好,做商品或内容的个性化推送以提高点击转化率,所以画像的侧重点就落在了用户个人行为偏好上;就数据分析人员来说,他们需要分析用户行为特征,做好用户的流失预警工作,还可根据用户的消费偏好做更有针对性的精准营销。
(要做什么业务,实现什么功能。运营和分析师的侧重点)
第二阶段:任务分解与需求调研
经过第一阶段的需求调研和目标解读,我们已经明确了用户画像的服务对象与应用场景,接下来需要针对服务对象的需求侧重点,结合产品现有业务体系和“数据字典”规约实体和标签之间的关联关系,明确分析维度。就后文将要介绍的案例而言,需要从用户属性画像、用户行为画像、用户偏好画像、用户群体偏好画像等角度去进行业务建模。
第三阶段:需求场景讨论与明确
在本阶段,数据运营人员需要根据与需求方的沟通结果,输出产品用户画像需求文档,在该文档中明确画像应用场景、最终开发出的标签内容与应用方式,并就该文档与需求方反复沟通并确认无误。
第四阶段:应用场景与数据口径确认
经过第三个阶段明确了需求场景与最终实现的标签维度、标签类型后,数据运营人员需要结合业务与数据仓库中已有的相关表,明确与各业务场景相关的数据口径。在该阶段中,数据运营方需要输出产品用户画像开发文档,该文档需要明确应用场景、标签开发的模型、涉及的数据库与表以及应用实施流程。该文档不需要再与运营方讨论,只需面向数据运营团队内部就开发实施流程达成一致意见即可。
第五阶段:特征选取与模型数据落表
本阶段中数据分析挖掘人员需要根据前面明确的需求场景进行业务建模,写好HQL逻辑,将相应的模型逻辑写入临时表中,并抽取数据校验是否符合业务场景需求。
第六阶段:线下模型数据验收与测试
数据仓库团队的人员将相关数据落表后,设置定时调度任务,定期增量更新数据。数据运营人员需要验收数仓加工的HQL逻辑是否符合需求,根据业务需求抽取表中数据查看其是否在合理范围内,如果发现问题要及时反馈给数据仓库人员调整代码逻辑和行为权重的数值。
第七阶段:线上模型发布与效果追踪
经过第六阶段,数据通过验收之后,会通过Git进行版本管理,部署上线。使用Gi t进行版本管理,上线 后通过持续追踪标签应用效果及业务方反馈,调整优化模型及相关权重配置。
1.4.2 各阶段关键产出
为保证程序上线的准时性和稳定性,需要规划好各阶段的任务排期和关键产出。画像体系的开发分为几个主要阶段,包括前期指标体系梳理、用户标签开发、ETL调度开发、打通数据服务层、画像产品端开发、面向业务方推广应用、为业务方提供营销策略的解决方案等。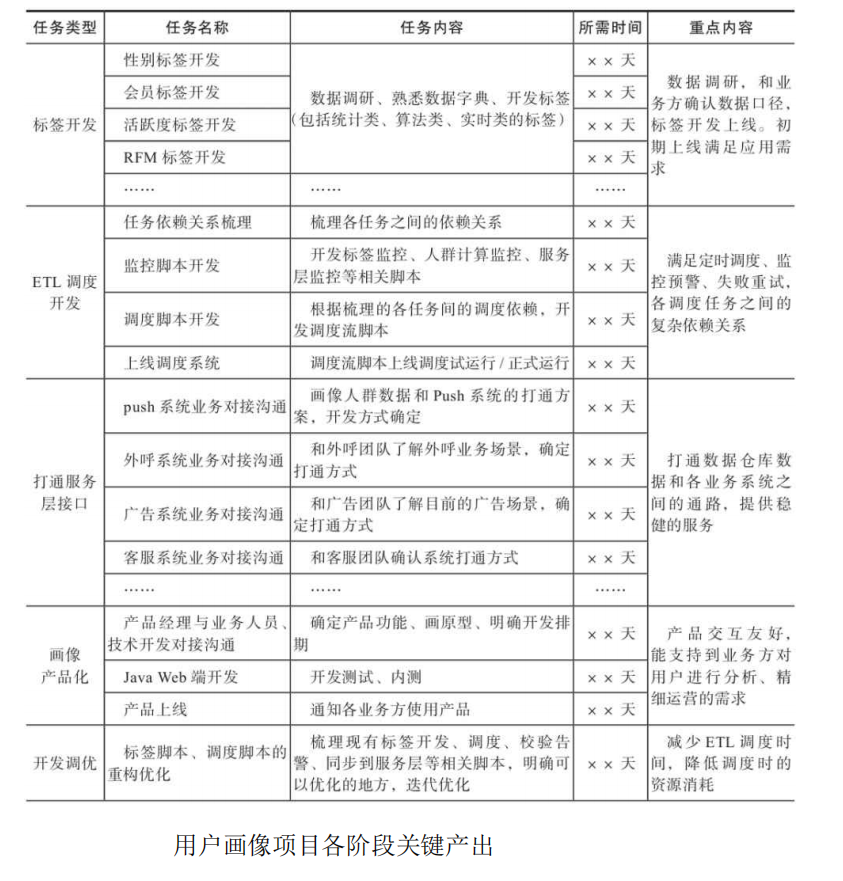
1)标签开发:根据业务需求和应用场景梳理标签指标体系,调研业务上定义的数据口径,确认数据来源,开发相应的标签。标签开发在整个画像项目周期中占有较大比重。
2)ETL调度开发:梳理需要调度的各任务之间的依赖关系,开发调度脚本及调度监控告警脚本,上线调度系统。
3)打通服务层接口:为了让画像数据走出数据仓库,应用到用户身上,需要打通数据仓库和各业务系统的接口。
4)画像产品化:需要产品经理与业务人员、技术开发人员一起对接业务需求点和产品功能实现形式,画产品原型,确定工作排期。Java Web端开发完成后,需要数据开发人员向对应的库表中灌入数据。
5)开发调优:在画像的数据和产品端搭建好架构、能提供稳定服务的基础上,为了让调度任务执行起来更加高效、提供服务更加稳健,需要对标签计算脚本、调度脚本、数据同步脚本等相关计算任务进行重构优化。
6)面向业务方推广应用:用户画像最终的价值产出点是业务方应用画像数据进行用户分析,多渠道触达运营用户,分析ROI, 提升用户活跃度或营收。因此,面向业务人员推广画像系统的使用方式、提供针对具体业务场景的解决方案显得尤为重要。在该阶段,相关人员需要撰写画像的使用文档,提供业务支持。
1.5 画像应用的落地
用户画像最终的价值还是要落地运行,为业务带来实际价值。这里需要开发标签的数据工程师和需求方相互协作,将标签应用到业务中。否则开发完标签后,数据还是只停留在数据仓库中,没有为业务决策带来积极作用。
画像开发过程中,还需要开发人员组织数据分析、运营、客服等团队的人员进行画像应用上的推广。对于数据分析人员来说,可能会关注用户画像开发了哪些表、哪些字段以及字段的口径定义;对运营、客服等业务人员来说,可能更关注用户标签定义的口径,如何在Web端使用画像产品进行分析、圈定用户进行定向营销,以及应用在业务上数据的准确性和及时性。
只有业务人员在日常工作中真正应用画像数据、画像产品,才能更好地推动画像标签的迭代优化,带来流量提升和营收增长,产出业绩价值。
1.6 案例
略
1.7 定性类画像
本书重点讲解如何运用大数据定量刻画用户画像,然而对于用户的刻画除了定量维度外,定性刻画也是常见手段。定性类画像多见于用户研究等运营类岗位,通过电话调研、网络调研问卷、当面深入访谈、网上第三方权威数据等方式收集用户信息,帮助其理解用户。这种定性类调研相比大数据定量刻画用户来说,可以更精确地了解用户需求和行为特征,但这个样本量是有限的,得出的结论也不一定能代表大部分用户的观点。
通过制定调研问卷表,我们可以收集用户基本信息以及设置一个或多个场景,专访用户或网络回收调研问卷,在分析问卷数据后获取用户的画像特征。目前市场上“问卷星”等第三方问卷调查平台可提供用户问卷设计、链接发放、采集数据和信息、调研结果分析等一系列功能。
根据回收的调研问卷,可结合统计数据进一步分析用户画像特征。
第2章数据指标体系
数据指标体系是建立用户画像的关键环节,也是在标签开发前要进行的工作,具体来说就是需要结合企业的业务情况设定相关的指标。
互联网相关企业在建立用户画像时一般除了基于用户维度(userid)建立一套用户标签体系外,还会基于用户使用设备维度(cookieid)建立相应的标签体系。基于cookieid维度的标签应用也很容易理解,当用户没有登录账户而访问设备时,也可以基于用户在设备上的行为对该设备推送相关的广告、产品和服务。建立的用户标签按标签类型可以分为统计类、规则类和机器学习挖掘类,相关内容在1. 1. 2节中有详细介绍。从建立的标签维度来看, 可以将其分为用户属性类、用户行为类、用户消费类和风险控制类等常见类型。
下面详细介绍用户标签体系的构成及应用场景。
2.1 用户属性维度
2.1.1 常见用户属性
用户属性是刻画用户的基础。常见用户属性指标包括:用户的年龄、性别、安装时间、注册状态、城市、省份、跃登录地、历史购买状态、历史购买金额等。
用户属性维度的标签建成后可以提供客服电话服务,为运营人员了解用户基本情况提供帮助。
用户属性标签包含统计类、规则类、机器学习挖掘类等类型。统计类标签的开发较为简单,机器学习挖掘类标签将在4.3节中通过具体案例进行讲解。本节主要介绍常见用户属性标签主要包括的维度。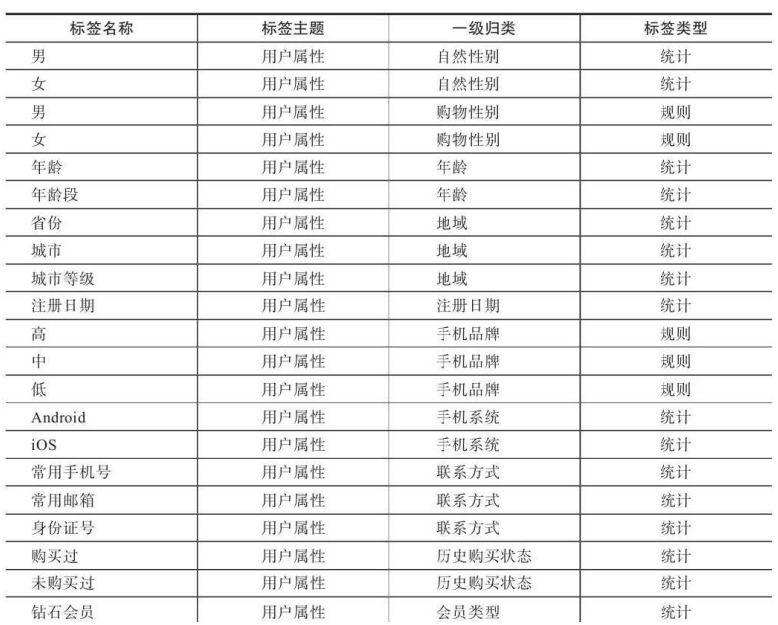
 上表对于相同的一级标签类型,需要判断多个标签之间的关系为互斥关系还是非互斥关系。例如,在判断性别时,用户性别为男的情况下就不能同时为女,所以标签之,间为互斥关系;在判断用户是否在黑名单内时,用户既可能在短信黑名单中,也可能同时在邮件黑名单中,所以这种就为非互斥关系。
上表对于相同的一级标签类型,需要判断多个标签之间的关系为互斥关系还是非互斥关系。例如,在判断性别时,用户性别为男的情况下就不能同时为女,所以标签之,间为互斥关系;在判断用户是否在黑名单内时,用户既可能在短信黑名单中,也可能同时在邮件黑名单中,所以这种就为非互斥关系。
对于根据数值进行统计、分类的标签开发相对容易。例如,用户的“性别”“年龄”“城市”“历史购买金额”等确定性的标签。而在对规则类的标签进行开发前则首先需要进行数据调研。例如,对于用户价值度划分(RFM),如何确定一个用户是重要价值用户还是一般价值用户,对于用户活跃度的划分如何确定是高活跃、中活跃、低活跃还是已经流失,需要结合数据调研情况给出科学的规则并进行划分。在4.2节中,将会通过两个案例介绍规则类标签如何开发。
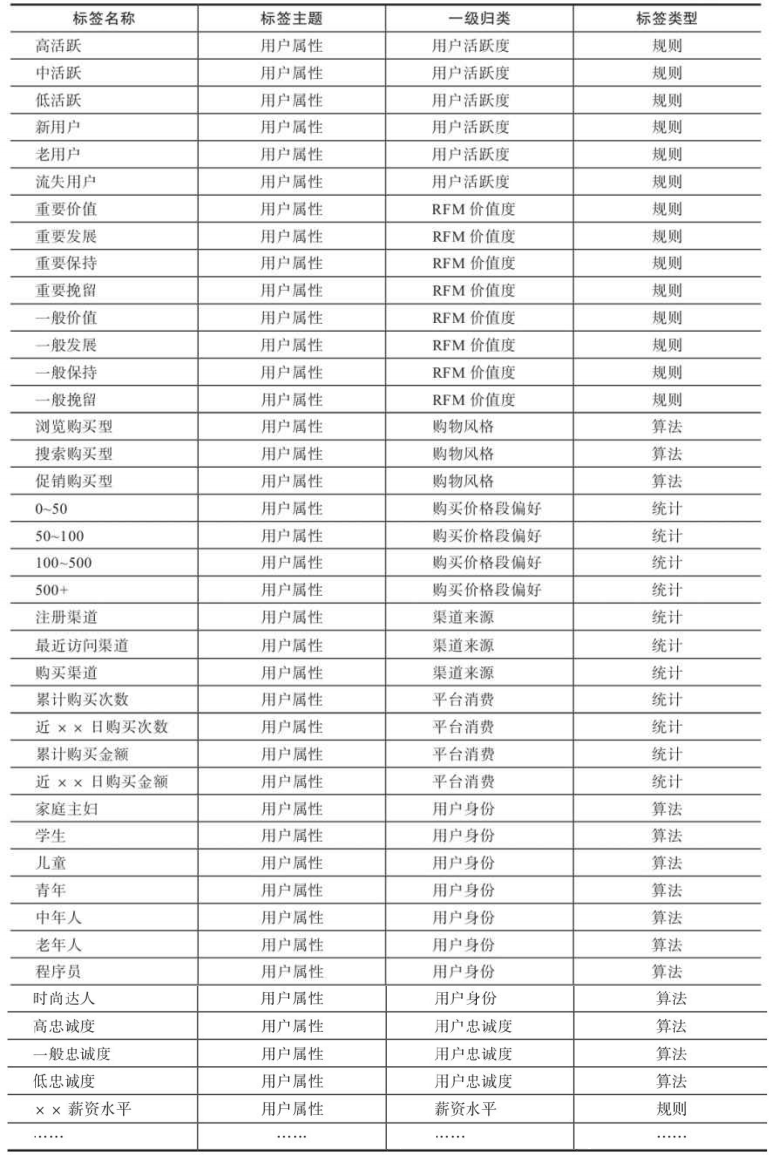
2.1.2 用户性别
用户性别可细分为自然性别和购物性别两种。
自然性别是指用户的实际性别,一般可通过用户注册信息、填写调查问卷表单等途径获得。该标签只需要从相应的表中抽取数据即可,加工起来较为方便。
用户购物性别是指用户购买物品时的性别取向。例如,一位实际性别为男性的用户,可能经常给妻子购买女性的衣物、包等商品,那么这位用户的购物性别则是女性。
2.2 用户行为维度
用户行为是另一种刻画用户的常见维度,通过用户行为可以挖掘其偏好和特征。常见用户行为维度指标(见下表)包括:用户订单相关行为、下单/访问行为、用户近30天行为类型指标、用户高频活跃时间段、用户购买品类、点击偏好、营销敏感度等相关行为。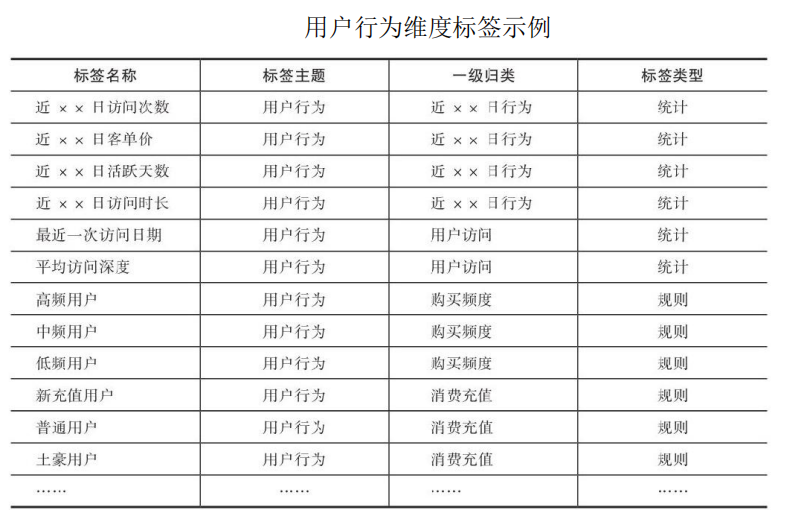
2.3 用户消费维度
对于用户消费维度指标体系的建设,可从用户浏览、加购、下单、收藏、搜索商品对应的品类入手,品类越细越精确,给用户推荐或营销商品的准确性越高。如下图所示,根据用户相关行为对应商品品类建设指标体系,本案例精确到商品三级品类。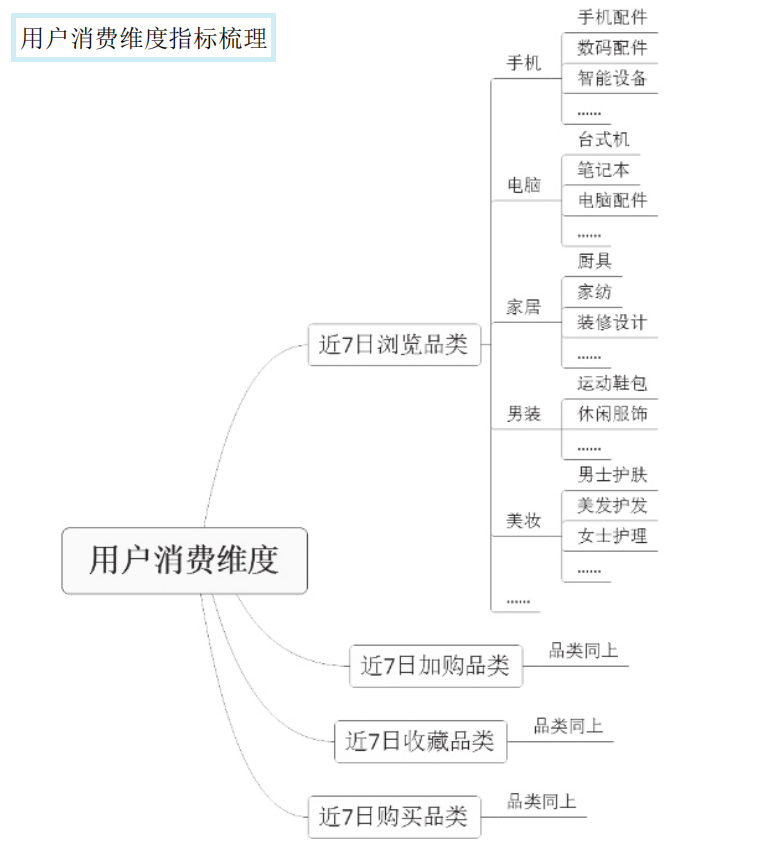
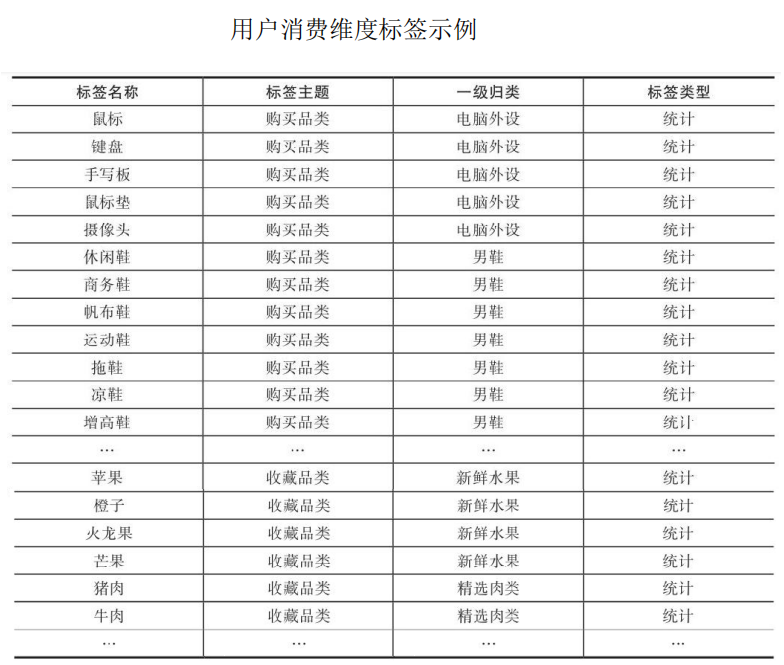
这里通过一个场景来介绍构建用户消费维度的标签的应用。某女装大促活动期间,渠道运营人员需要筛选出平台上的优质用户,并通过短信、邮件、Push等渠道进行营销,可以通过圈选“浏览”“收藏”“加购”“购买”“搜索”与该女装相关品类”的标签来筛选出可能对该女装感兴趣的潜在用户,进一步组合其他标签(如“性别”“消费金额”“活跃度” 等)筛选出对应的高质量用户群,推送到对应渠道。因此将商品品类抽象成标签后,可通过品类+行为的组合应用方式找到目标潜在用户人群。
2.4风险控制维度
互联网企业的用户可能会遇到薅羊毛、恶意刷单、借贷欺诈等行为的用户,为了防止这类用户给平台带来损失和风险,互联网公司需要在风险控制维度构建起相关的指标体系,有效监控平台的不良用户。结合公司业务方向,例如可从账号风险、设备风险、借贷风险等维度入手构建风控维度标签体系。下面详细介绍一些常见的风险控制维度的标签示例。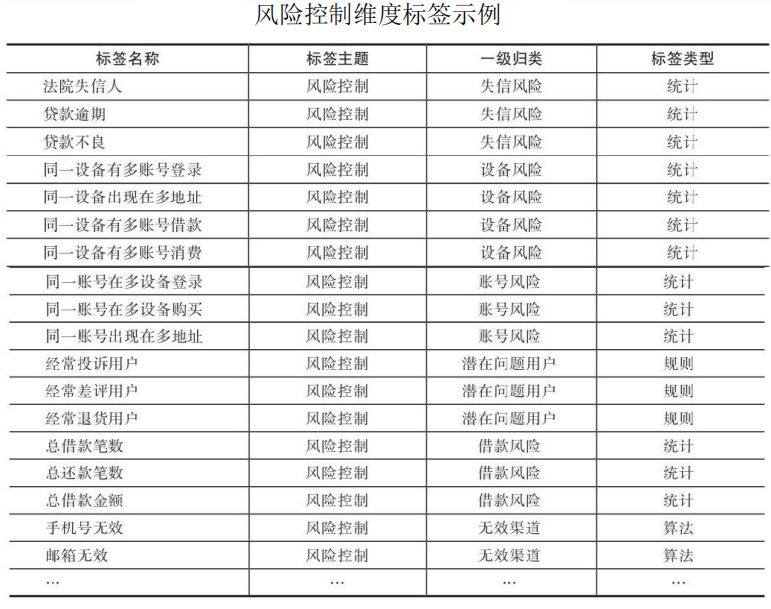
2.5 社交属性维度
社交属性用于了解用户的家庭成员、社交关系、社交偏好、社交活跃程度等方面,通过这些信息可以更好地为用户提供个性化服务。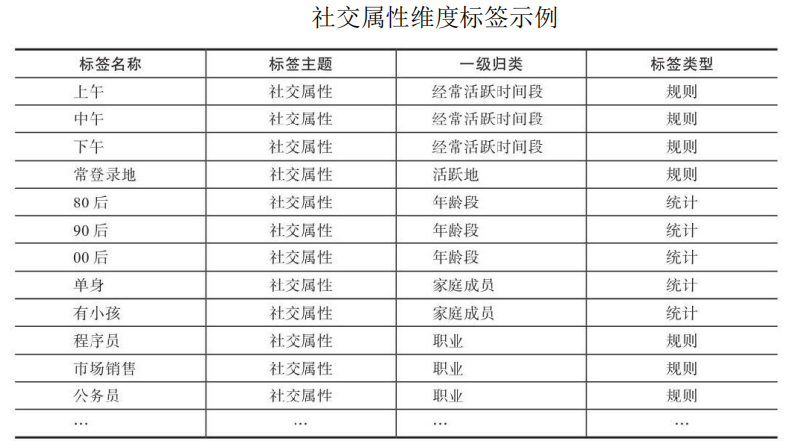
在日常使用社交软件时,我们可以发现社交软件中的信息流广告会结合我们的社交特征进行个性化推送。如图2-2所示,结合我所在城市、经常活跃地段及近期收藏的电脑相关文章,在微信朋友圈给我推送了相关电脑营销的广告。如图2-3所示,基于我的星座和年龄段信息,推送符合我某些特征的婚庆摄影广告。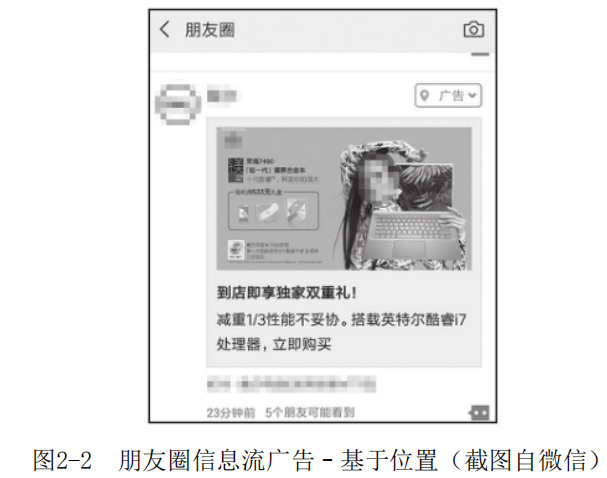

2.6 其他常见标签划分方式
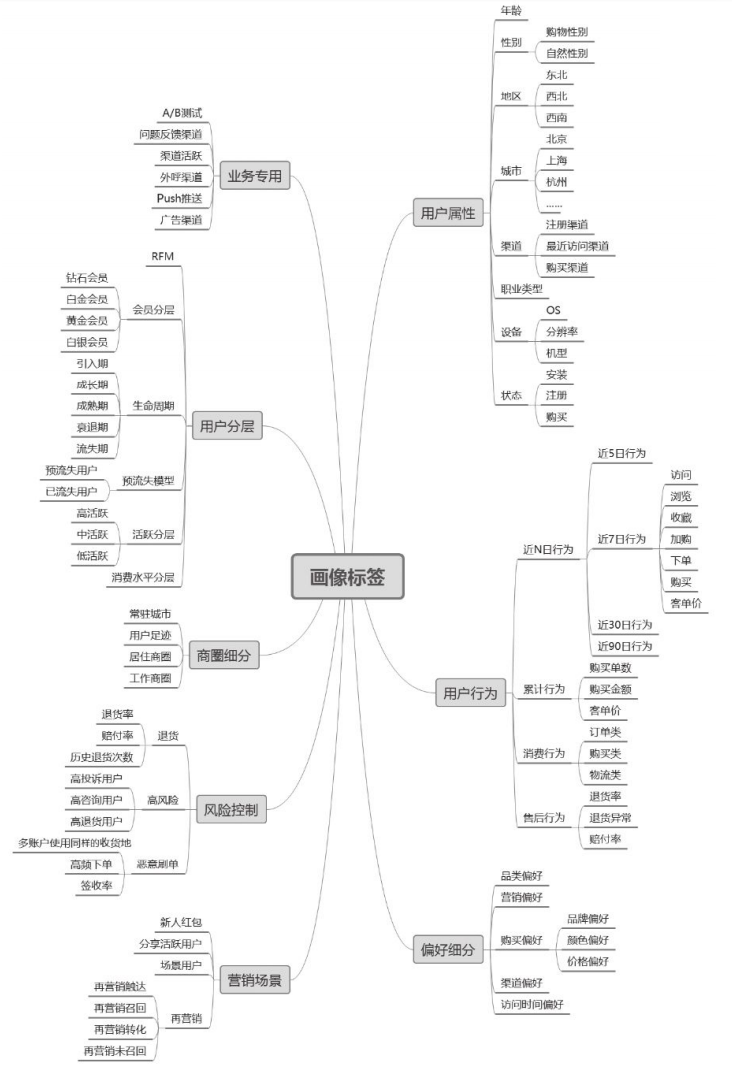
本章前5节从用户属性、用户行为、用户消费、风险控制、社交属性共五大维度划分归类了用户标签指标体系。但对用户标签体系的归类并不局限于此,通过应用场景对标签进行归类也是常见的标签划分方式。图2-4展示了具体的画像标签应用场景划分。
从业务场景的角度出发,可以将用户标签体系归为用户属性、用户行为、营销场景、地域细分、偏好细分、用户分层等维度。每个维度可细分出二级标签、三级标签等。
●用户属性:包括用户的年龄、性别、设备型号、安装/注册状态、职业等刻画用户静态特征的属性。
●用户行为:包括用户的消费行为、购买后行为、近N日的访问、收藏、下单、购买、售后等相关行为。
●偏好细分:用户对于商品品类、商品价格段、各营销渠道、购.买的偏好类型、不同营销方式等方面的偏好特征;
●风险控制:对用户从征信风险、使用设备的风险、在平台消费过程中产生的问题等维度考量其风险程度;
●业务专用:应用在各种业务上的标签,如A/B测试标签、Push系统标签等;
●营销场景:以场景化进行分类,根据业务需要构建一 -系列营销场景,激发用户的潜在需求,如差异化客服、场景用户、再营销用户等;
●地域细分:标识用户的常住城市、居住商圈、工作商圈等信息,应用在基于用户地理位置进行推荐的场景中;
●用户分层:对用户按生命周期、RFM、 消费水平类型、活跃度类型等进行分层划分。
本节提供了一种从业务场景的角度出发对标签体系进行归类的解决方案。为读者构建标签体系提供了另外一种种参考维度。
2.7 标签命名方式
为了便于对诸多标签进行集中管理,需要对每个标签对应的标签id进行命名。例如,对性别为“男”的用户打,上标签“ATTRITUBE_ U _ol_001”, 性别为“女”的用户打上标签“ATTRITUBE _U_01_002”。下面我们详细介绍如何建立起这套标签命名方式。
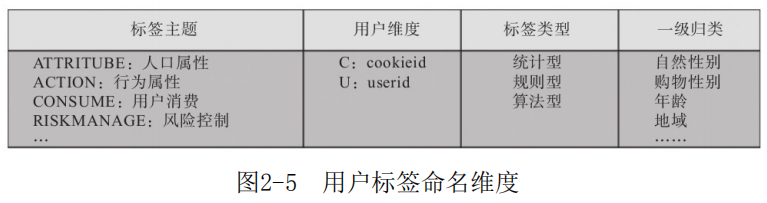
对于一个标签,可以从标签主题、刻画维度、标签类型、一级归类等多角度入手来确定每个标签的唯一名 称,如图2-5所示。
●标签主题:用于刻画属于哪种类型的标签,如人口属性、行为属性、用户消费、风险控制等多种类型,可分别用ATTRITUBE、ACTION、CONSUME、 RI SKMANAGE等单词表示各标签主题。
●用户维度:用于刻画该标签是打在用户唯一标识(userid)上, 还是打在用户 使用的设备(cookieid). 上。可用U、 C等字母分别标识user id和cook iei d维度。
●标签类型:类型可划分为统计型、规则型和算法型。其中统计型开发可直接从数据仓库中各主题表建模加工而成,规则型需要结合公司业务和数据情况,算法型开发需要对数据做机器学习的算法处理得到相应的标签。
●一级维度:在每个标签主题大类下面,进一步细分维度来刻画用户。
参照上面的命名维度和命名方式,下面通过几个例子来讲述如何命名标签。
对于用户的性别标签,标签主题是人口属性,用户维度为userid,标签类型属于算法型。给男性用户打上标签“ATTRITUBE U_01_001”,给女性用户打上标签“ATTRITUBE U 01_002”,其中“ATTRITUBE” 为人口属性主题,“”后面的”U”为userid维度,“_”后面“01”为一级归类,最后面的“001”和“002”为该一级标签下的标签明细,如果是划分高中低活跃用户的,对应级标签下的明细可划分
为“001”“002”“003” 。
标签统一命名后, 维护一张码表记录标签id名称、 标签含义及标签口径等主要信息,后期方便元数据的维护和管理。本节介绍的标签命名方式可作为开发标签过程中的一种参考方式。
2.8 本章小结
本章主要介绍了如何结合业务场景去搭建刻画用户的数据指标体系。其中2. 1节到2.5节介绍了一种从用户属性、用户行为、用户消费、风险控制和社交属性5个维度建立用户标签体系的思路,2. 6节提供了一种基于应用场景搭建指标体系的思路。2. 7节介绍了一种规范化命名标签的解决方案,可保证对每一个业务标签打上唯一的标签id。
对于互联网企业来说,其存储的海量用户访问日志数据便于分析用户操作的行为特性;而对于传统企业来说则可以更多地从用户属性维度去丰富指标体系。
3. 标签数据存储
3.1 Hive存储
3.1.1 Hive数据仓库
建立用户画像首先需要建立数据仓库,用于存储用户标签数据。Hive是基于Hadoop的数据仓库工具,依赖于HDFS存储数据,提供的SQL语言可以查询存储在HDFS中的数据。开发时一般使用Hive作为数据仓库,存储标签和用户特征库等相关数据。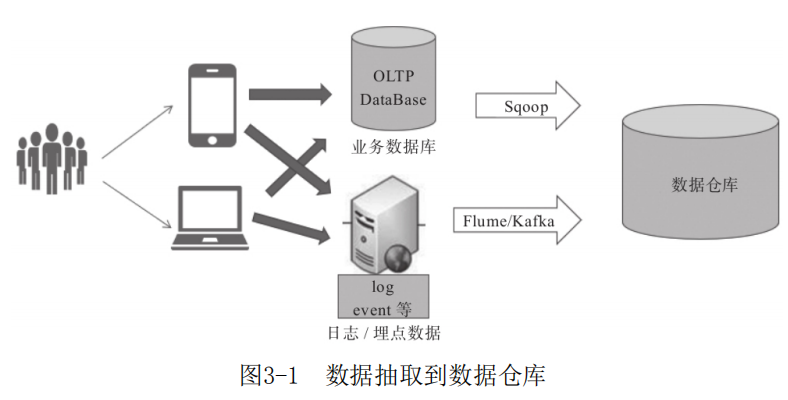
在数据仓库建模的过程中,主要涉及事实表和维度表的建模开发(图3-2)。
事实表主要围绕业务过程设计,就应用场景来看主要包括事务事实表,周期快照事实表和累计快照事实表:
●事务事实表:用于描述业务过程,按业务过程的单一性或多业务过程可进一步分为单事务事实表和多事务事实表。其中单事务事实表分别记录每个业务过程,如下单业务记入下单事实表,支付业务记
入支付事实表。多事务事实表在同一一个表中包含了不同业务过程,如下单、支付、签收等业务过程记录在一张表中, 通过新增字段来判断属于哪一个业务过程。当不同业务过程有着相似性时可考虑将多业务过程放到多事务事实表中。
●周期快照事实表:在一个确定的时间间隔内对业务状态进行度量。例如查看一个用户的近1年付款金额、近1年购物次数、近30日登录天数等。
●累计快照事实表:用于查看不同事件之间的时间间隔,例如分析用户从购买到支付的时长、从下单到订单完结的时长等。一般适用于有明确时间周期的业务过程。
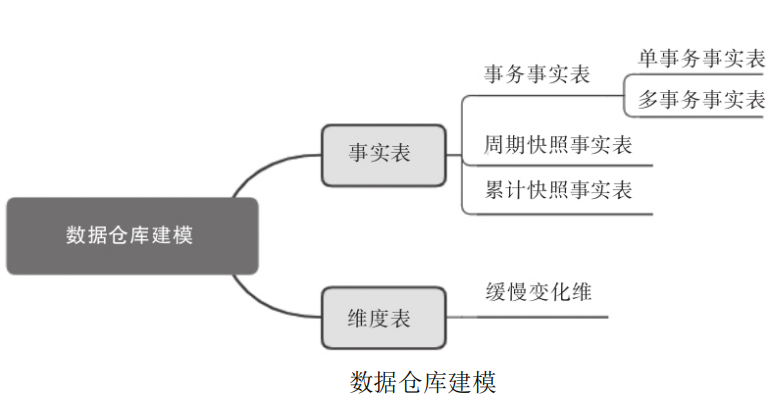
维度表主要用于对事实属性的各个方面描述,例如,商品维度包括商品的价格、折扣、品牌、原厂家、型号等方面信息。
维度表开发的过程中,经常会遇到维度缓慢变化的情况,对于缓慢变化维一般会采用:
①重写维度值,对历史数据进行覆盖;
②保留多条记录,通过插入维度列字段加以区分;
③开发日期分区表,每日分区数据记录当日维度的属性;
④开发拉链表按时间变化进行全量存储等方式进行处理。
在画像系统中主要使用Hive作为数据仓库,开发相应的维度表和事实表来存储标签、人群、应用到服务层的相关数据。
3.1.2 分区存储
如果将用户标签开发成一张大的宽表,在这张宽表下放几十种类型标签,那么每天该画像宽表的ETL作业将会花费很长时间,而且不便于向这张宽表中新增标签类型。
要解决这种ETL花费时间较长的问题,可以从以下几个方面着手:
●将数据分区存储,分别执行作业;
●标签脚本性能调优;
●基于一些标签共同的数据来源开发中间表。
下面介绍一种用户标签分表、分区存储的解决方案。
根据标签指标体系的人口属性、行为属性、用户消费、风险控制、社交属性等维度分别建立对应的标签表进行分表存储对应的标签数据。如图3-3所示。
●人口属性表: dw. userprofileattritube_all;
●行为属性表:dw. userprofile_action_all;
●用户消费表:dw. userprofile_consume_all;
●风险控制表:dw. userprofile_riskmanage_all;
●社交属性表:dw. userprofile social_ all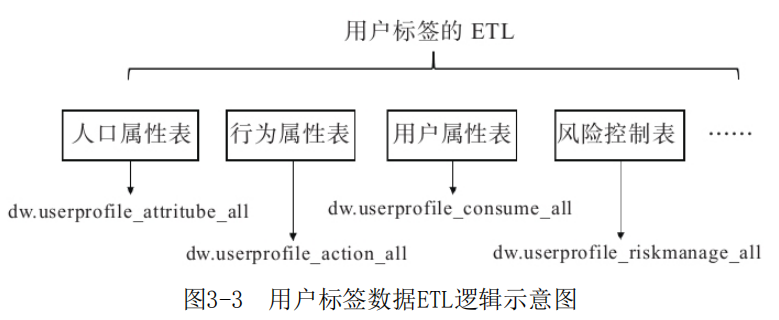
同样的,用户其他id维度(如cookieid、deviceid、 registerid 等)的标签数据存储,也可以使用上面案例中的表结构。
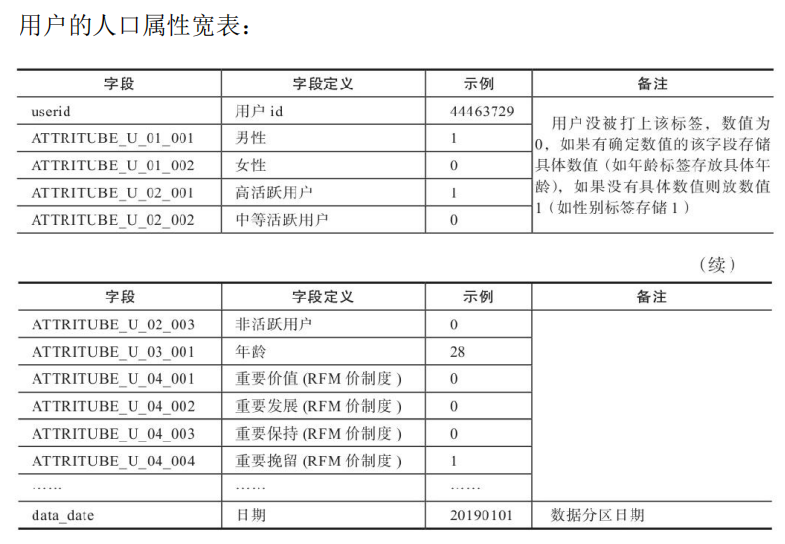
在上面的创建中通过设立人口属性维度的宽表开发相关的用户标签,为为提高数据的插入和查询效率,在Hive中可以使用分区表的方式,将数据存储在不同的目录中。在Hive 使用select查询时一般会扫描整个表中所有数据,将会花费很多时间扫描不是当前要查询的数据,为了扫描表中关心的一部分数据,在建表时引入了partition的概念。在查询时,可以通过Hive的分区机制来控制一次遍历的数据量。
3.1.3 标签汇聚
在3.1.2节的案例中,用户的每个标签都插入到相应的分区下面,但是对一个用户来说,打在他身上的全部标签存储在不同的分区下面。为了方便分析和查询,需要将用户身上的标签做聚合处理。紧接3.1. 2节的案例,下面讲解标签汇聚的开发案例(见图3-4)。
标签汇聚后将一一个每个用户身。上的全量标签汇聚到一个字段中,表结构设计如下: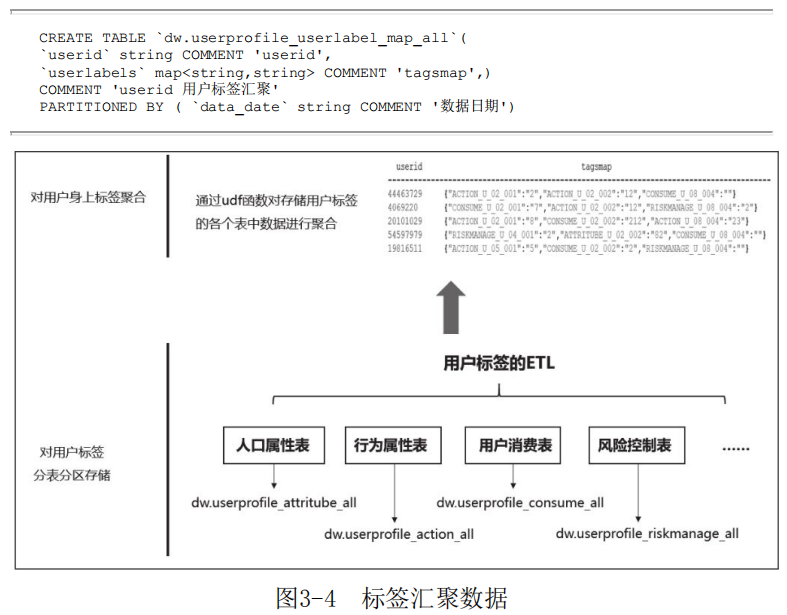
开发udf函数“cast to json”将用户身上的标签汇聚成json字符串,执行命令将按分区存储的标签进行汇聚:
汇聚后用户标签的存储格式如图3-5所示
将用户身上的标签进行聚合便于查询和计算。例如,在画像产品中,输入用户id后通过直接查询该表,解析标id和对应的标签权重后,即可在前端展示该用户的相关信息(如图3-6所示)。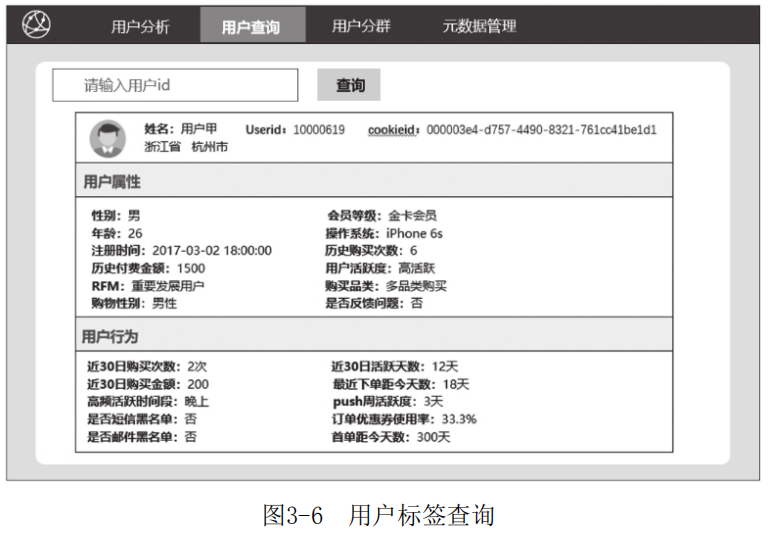
3.1.4 ID-MAP
开发用户标签的时候,有项非常重要的内容—— ID-MApping, 即把用户不同来源的身份标识通过数据手段识别为同一个主体。用户的属性、行为相关数据分散在不同的数据来源中,通过ID-MApping能够把用户在不同场景下的行为串联起来,消除数据孤岛。图3-7展示了用户与设备间的多对多关系。图3-8展示了同一用户在不同平台间的行为示意图。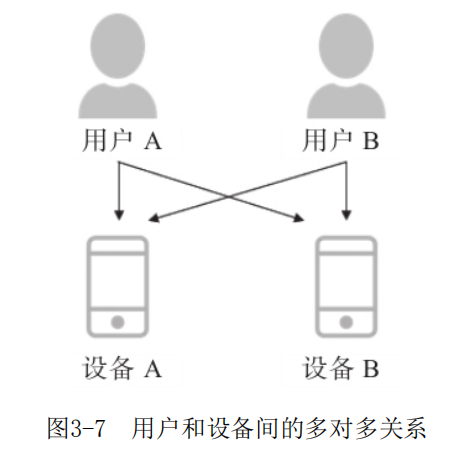
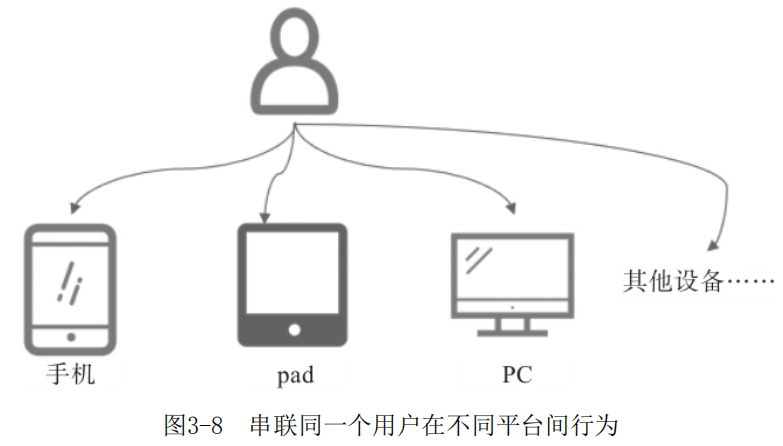
举例来说,用户在未登录App的状态下,在App站内访问、搜索相关内容时,记录的是设备id (即cookieid)相关的行为数据。而用户在登录App后,访问、收藏、下单等相关的行为记录的是账号id (即userid) 相关行为数据。虽然是同一个用户,但其在登录和未登录设备时记录的行为数据之间是未打通的。通过ID-MApping打通userid和cookieid的对应关系,可以在用户登录、未登录设备时都能捕获其行为轨迹。
下面通过一个案例介绍如何通过Hive的ETL工作完成ID-Mapping的数据清洗工作。
缓慢变化维是在维表设计中常见的一种方式,维度并不是不变的,随时间也会发生缓慢变化。如用户的手机号、邮箱等信息可能会随用户的状态变化而改变,再如商品的价格也会随时间变化而调整上架的价格。因此在设计用户、商品等维表时会考虑用缓慢变化维来开发。同样,在设计ID-Mapping表时,由于一个用户可以在多个设备上登录,一个设备也能被多个用户登录,所以考虑用缓慢变化维表来记录这种不同时间点的状态变化(图3-9)。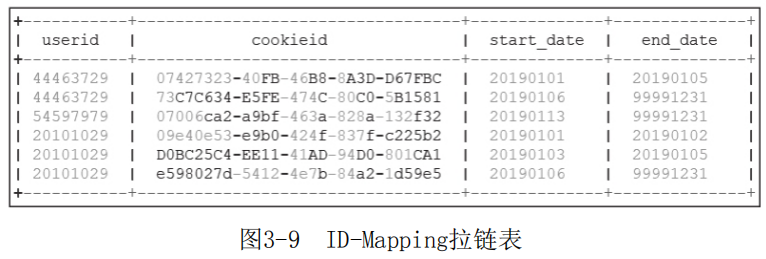
拉链表是针对缓慢变化维表的一种设计方式,记录一个事物从开始到当前状态的全部状态变化信息。
在上图中,通过拉链表记录了userid每一次 关联到不同cookieid的情况。如userid为44463729的用户,在20190101这天 登录某设备,在6号那天变换了另一个设备登录。其中start_ date表 示该记录的开始日期,end_date表示该记录的结束日期,当end_date为99991231时,表示该条记录当前仍然有效。
首先需要从埋点表和访问日志表里面获取到cookieid和userid同时出现的访问记录。下 面案例中,ods. page event log是埋点日志表,ods.pageview log是访问日志表,将获取到的useri d和cookieid信息插入cookieid-userid关系表(ods.cookie_user_signin) 中。代码执行如下: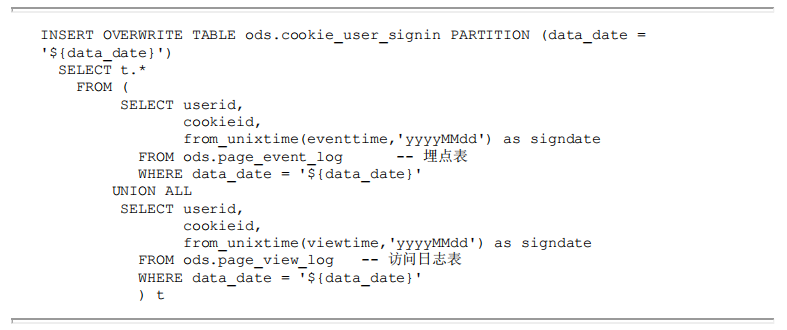
创建ID-Map的拉链表,将每天新增到ods. cookie_user_signin表中的数据与拉链表历史数据做比较,如果有变化或新增数据则进行更新。
创建完成后,每天ETL调度将数据更新到ID-Mapping拉链表中,任务执行如下。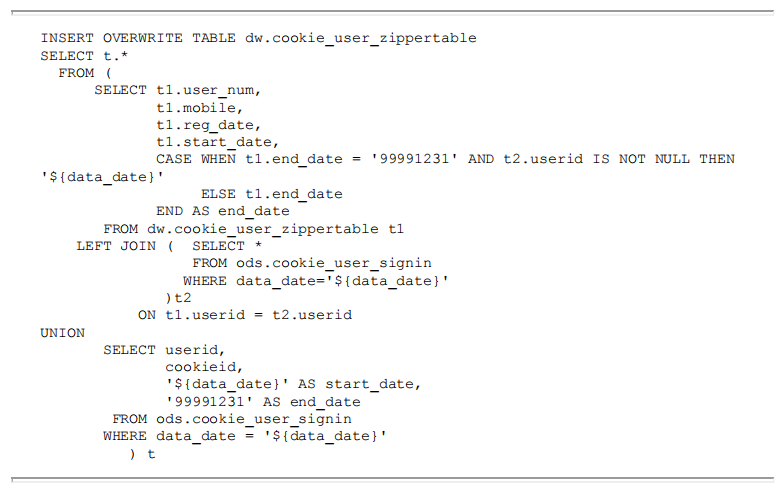
数据写入表中,如图3-9所示。对于该拉链表,可查看某日(如20190801)的快照数据。
例如,目前存在一个记录userid和cookieid关联关系的表,但是为多对多的记录(即一个userid对应多条cookieid记录,以及一条cooki eid对应多条userid记录)。这里可以通过拉链表的日期来查看某个时间点userid对应的cookieid。查看某个用户( 如32101029)在某天(如20190801)关联到的设备id (图3-10)。
上图可看出用户‘32101029’在历史中曾登录过3个设备,通过限定时间段可找到特定时间下用户的登录设备。
在开发中需要注意关于userid与cookieid的多对多关联,如果不加条件限制就做关联,很可能引起数据膨胀问题。
在实际应用中,会遇到许多需要将useri d和cookieid做关联的情况。例如,需要在userid维度开发出该用户近30日的购买次数、购买金额、登录时长、登录天数等标签。前两个标签可以很容易地从相应的业务数据表中根据算法加工出来,而登录时长、登录天数的数据存储在相关日志数据中,日志数据表记录的userid与cookieid为多对多关系。因此在结合业务需求开发标签时,要确定好标签口径定义。
本节中通过案例介绍了将userid和cookieid打通的一种解决方案,实践中还存在需要将用户在不同平台间(如Web端和App端)行为打通的应用场景。
3.2 MySQL存储
MySQL作为关系型数据库,在用户画像中可用于元数据管理、监控预警数据、结果集存储等应用中。下面详细介绍这3个应用场景。
3.2.1元数据管理
Hive适合于大数据量的批处理作业,对于量级较小的数据,MySQL具有更快的读写速度。Web端产品读写MySQL数据库会有更快的速度,方便标签的定义、管理。
在7.2节和7.3节中,我们会介绍元数据录入和查询功能,将相应的数据存储在MySQL中。用户标签的元数据表结构设计会在7.3节进行详细的介绍。这里给出了平台标签视图( 如图3-11所示)和元数据管理页面(如图3-12所示)。
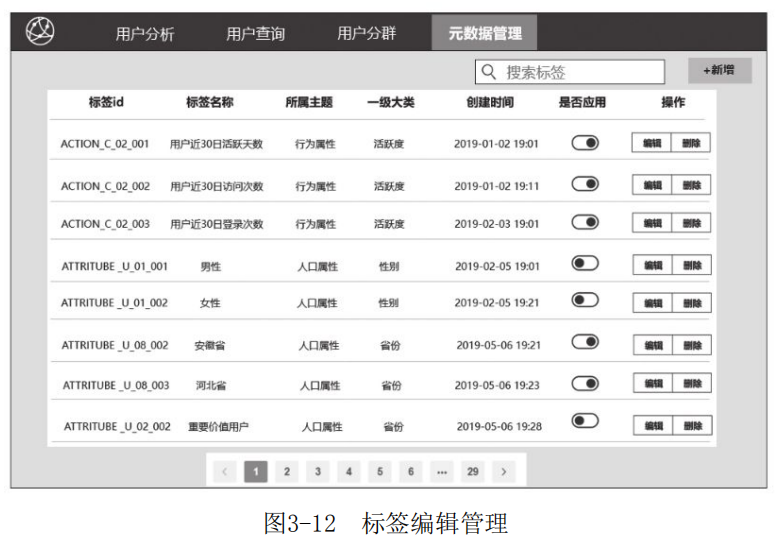
平台标签视图中的标签元数据可以维护在MySQL关系数据库中,便于标签的编辑、查询和管理。
3.2.2 监控预警数据
MySQL还可用于存储每天对ETL结果的监控信息。从整个画像调度流的关键节点来看,需要监控的环节主要包括对每天标签的产出量、服务层数据同步情况的监控等主要场景。图3-13所示是用户画像调度流主要模块,下 面详细介绍。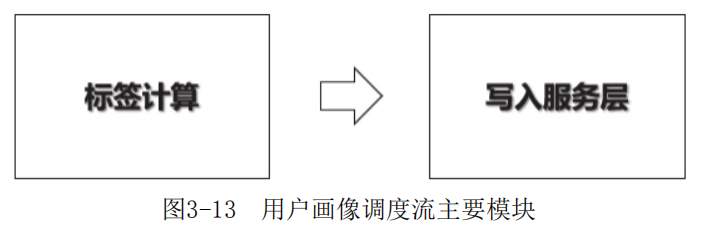
1)标签计算数据监控
主要用于监控每天标签ETL的数据量是否出现异常,如果有异常情况则发出告警邮件,同时暂停后面的ETL任务。
2)服务层同步数据监控
服务层一般采用HBase、Elast icsearch等作为数据库存储标签数据供线上调用,将标签相关数据从Hive数仓向服务层同步的过程中,有出现差错的可能,因此需要记录相关数据在Hive中的数量及同步到对应服务层后的数量,如果数量不一致则触发告警。
在对画像的数据监控中,调度流每跑完相应的模块,就将该模块的监控数据插入MySQL中,当校验任务判断达到触发告警阈值时,发送告警邮件,同时中断后续的调度任务。待开发人员解决问题后,可重启后续调度。
3.2.3 结果集存储
结果集可以用来存储多维透视分析用的标签、圈人服务用的用户标签、当日记录各标签数量,用于校验标签数据是否出现异常。
有的线上业务系统使用MySQL、Oracle等关系型数据库存储数据,如短信系统、消息推送系统等。在打通画像数据与线上业务系统时,需要考虑将存储在Hive中的用户标签相关数据同步到各业务系统,此时MySQL可用于存储结果集。
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互迁移的工具。它可以将一个关系型数据库(如MySQL、Oracle、PostgreSQL等 )中的数据导入Hadoop的HDPS中,也可以将HDFS中的数据导入关系型数据库中。
下面通过一个案例来讲解如何使用Sqoop将Hive中的标签数据迁移到MySQL中。
电商、保险、金融等公司的客服部门的日常工作内容之一是对目标用户群(如已流失用户、高价值用户等)进行主动外呼,以此召回用户来平台进行购买或复购。这里可以借助用户画像系统实现该功能。
将Hive中存储的与用户身份相关的数据同步到客服系统中,首先在Hive中建立一张记录用户身份相关信息的表(dw. userprofileuserservice_all) 。设置日期分区以满足按日期选取当前人群的需要。
在MySQL中建立一张用于接收同步数据的表(userservice data)。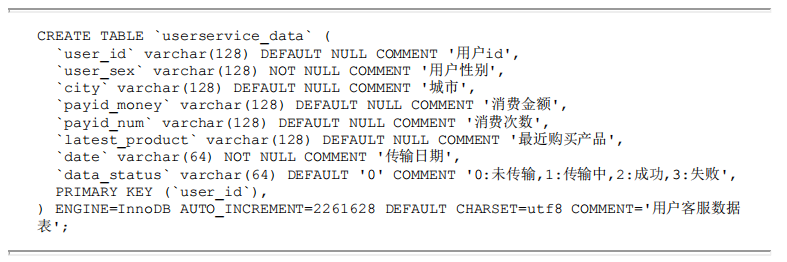
通过Python脚本调用shell命令,将Hive中 的数据同步到MySQL中。执行如下脚本: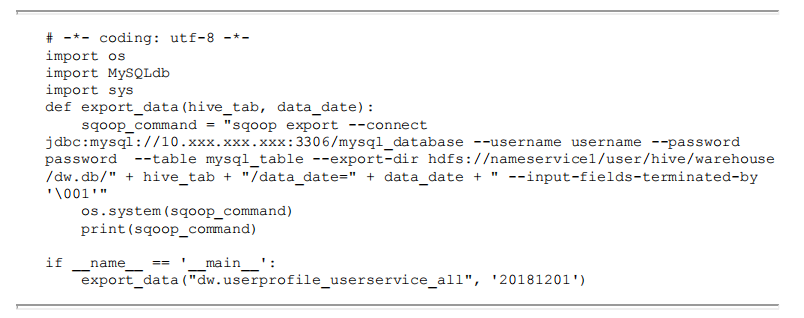
其中用到了sqoop从Hive导出数据到MySQL的命令:
同步后MySQL中的数据如图3-14所示。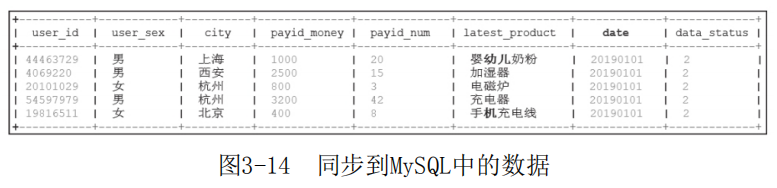
3.3 HBase存 储
3.3.1 HBase简介
HBase是一个高性能、列存储、可伸缩、实时读写的分布式存储系统,同样运行在HDFS之上。与Hive不同的 是,HBase能够在数据库上实时运行,而不是跑MapReduce任务,适合进行大数据的实时查询。
画像系统中每天在Hive里跑出的结果集数据可同步到HBase数据库,用于线上实时应用的场景。
下面介绍几个基本概念:
1)rowkey:用来表示唯一行记录的主键,HBase的数据是按照row key的字典顺序进行全局排列的。访问HBase中的行只有3种方式:
●通过单个row key访问;
●通过row key的正则访问;
●全表扫描。
由于HBase通过rowkey对数据进行检索,而rowkey由于长度限制的因素不能将很多查询条件拼接在rowkey中,因此HBase无法像关系数据库那样根据多种条件对数据进行筛选。一般地,HBase需建立二级索引来满足根据复杂条件查询数据的需求。
Rowkey设计时需要遵循三大原则:
●唯一性原则:rowkey需要保证唯一性,不存在重复的情况。在画像中一般使用用户id作为rowkey。
●长度原则:rowkey的长度一般 为10-100bytes。
●散列原则:rowkey的散列分布有利于数据均衡分布在每个RegionServer,可实现负载均衡。
2)columns family: 指列簇,HBase中的每个列都归属于某个列簇。列簇是表的schema的一部分,必须在使用表之前定义。划分columns family的原则如下:
●是否具有相似的数据格式;
●是否具有相似的访问类型。
常用的增删改查命令如下。
-- 创建一个表,指定表名和列簇名create '<table name>','<column family>'-- 扫描表中数据,并显示其中的10条记录:scan '<table name>' , {LIMIT=>10}-- 使用get命令读取数据:get '<table name>', ' rowl '-- 插入数据:put '<table name>', 'rowl', '<col family:colname>' , '<value> '-- 更新数据:put '<tab1e name>', 'row ', 'Column family:column name', 'new value '-- 在删除表之前先将其禁用,然后删除disable '<table name>'drop '<table name>'
下面通过一个案例来介绍HBase在画像系统中的应用场景和工程化实现方式。
3.3.2 应用场景
某渠道运营人员为促进未注册的新安装用户注册、下单, 计划通过App首页弹窗(如图3-15所示)发放红包或优惠券的方式进行引导。在该场景中可通过画像系统实现对应功能。
业务逻辑上,渠道运营人员通过组合用户标签(如“未注册用户”和“安装距今天数”小于XX天)筛选出对应的用户群,然后选择将对应人群推送到“广告系统”(产品功能详见7.4节),这样每天画像系统的ETL调度完成后对应人群数据就被推送到HBase数据库进行存储。满足条件的新用户来访App时,由在线接口读取HBase数据库,在查询到该用户时为其推送该弹窗。
下面通过某工程案例来讲解HBase在该触达用户场景中的应用方式。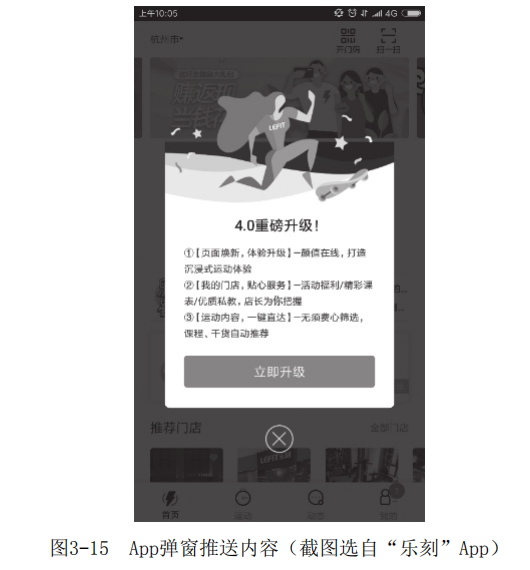
3.3.3 工程化案例
运营人员在画像系统(详见第7章)中根据业务规则定义组合用户标签筛选出用户群,并将该人群上线到广告系统中( 如图3- 16所示)。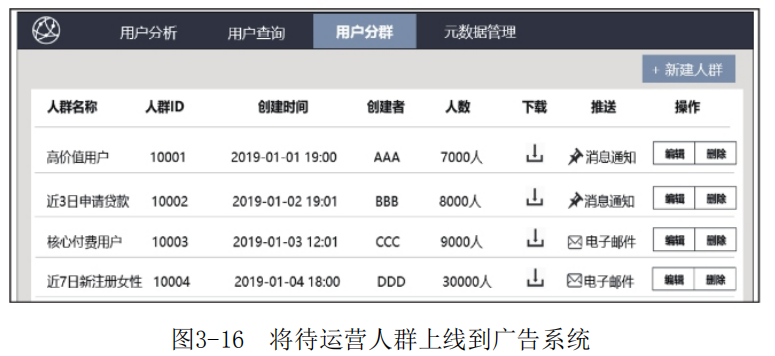
在业务人员配置好规则后,下面我们来看在数据调度层面是如何运行的。
用户标签数据经过ETL将每个用户身上的标签聚合后插入到目标表中,如dw.userprofile_userlabel_map_all (详见3.1.3节)。聚合后数据存储为每个用户id,以及他身上对应的标签集合,数据格式如图3-17所示。
接下来需要将Hive中的数据导入HBase,便于线上接口实时调用库中数据。
HBase的服务器体系结构遵循主从服务器架构(如图3-18所示),同一时刻只有一个HMaster处于活跃状态,当活跃的Master挂掉后,Backup HMaster自动接管整个HBase集群。在同步数据前,首先需要判断HBase的当前活跃节点是哪台机器。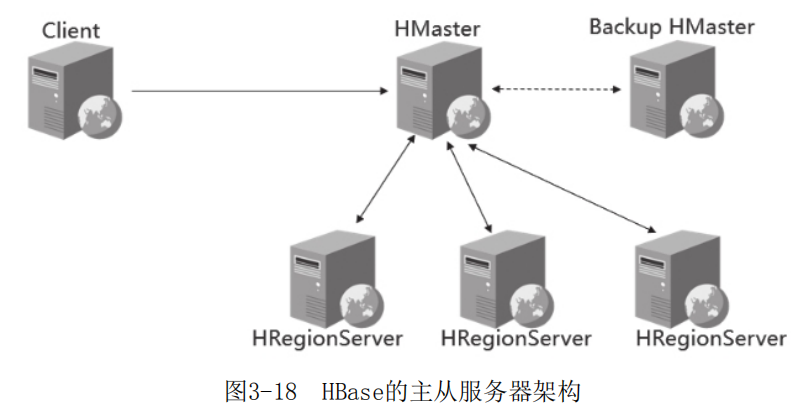
执行如下脚本:
执行完毕后,可通过返回的“State” 字段判断当前节点状态(活跃为“active” ,不活跃为“standby”),如图3-19所示。
为避免数据都写入一个region,造成HBase的数据倾斜问题。在当前HMaster活跃的节点上,创建预分区表:
将待同步的数据写入HFile,HFile中 的数据以key-value键值对方式存储,然后将HF ile数据使用BulkLoad批量写入HBase集群中。Scala脚本执行如下:
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.HBase.client.ConnectionFactory
import org.apache.hadoop.HBase.{HBaseConfiguration, KeyValue, TableName}
import org.apache.hadoop.HBase.io.ImmutableBytesWritable
import org.apache.hadoop.HBase.mapreduce.{HFileOutputFormat2,
LoadIncrementalHFiles}
import org.apache.hadoop.HBase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.sql.SparkSession
object Hive2HBase {
def main(args: Array[String]): Unit = {
// 传入日期参数 和 当前活跃的master节点
val data_date = args(0)
val node = args(1) //当前活跃的节点ip
val spark = SparkSession
.builder()
.appName("Hive2HBase")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.config("spark.storage.memoryFraction", "0.1")
.config("spark.shuffle.memoryFraction", "0.7")
.config("spark.memory.useLegacyMode", "true")
.enableHiveSupport()
.getOrCreate()
//创建HBase的配置
val conf = HBaseConfiguration.create()
conf.set("HBase.zookeeper.quorum", "10.xxx.xxx.xxx,10.xxx.xxx.xxx")
conf.set("HBase.zookeeper.property.clientPort", "8020")
//为预防hfile文件数过多无法进行导入,设置参数值
conf.setInt("HBase.hregion.max.filesize", 10737418240)
conf.setInt("HBase.mapreduce.bulkload.max.hfiles.perRegion.perFamily", 3200)
val Data = spark.sql(s"select userid,userlabels from dw.userprofile_usergroup_labels_all where data_date='${data_date}'")
val dataRdd = Data.rdd.flatMap(row => {
val rowkey = row.getAs[String]("userid".toLowerCase)
val tagsmap = row.getAs[Map[String, Object]]("userlabels".toLowerCase)
val sbkey = new StringBuffer() // 对MAP结构转化 a->b 'a':'b'
val sbvalue = new StringBuffer()
for ((key, value) <- tagsmap){
sbkey.append(key + ":")
val labelght = if (value == ""){
"-999999"
} else {
value
}
sbvalue.append(labelght + ":")
}
val item = sbkey.substring(0,sbkey.length -1)
val score = sbvalue.substring(0,sbvalue.length -1)
Array(
(rowkey,("f","i",item)),
(rowkey,("f","s",score))
)
})
// 将rdd替换成HFile需要的格式
val rdds = dataRdd.filter(x=>x._1 != null).sortBy(x=>(x._1,x._2._1,
x._2._2)).map(x => {
//KeyValue的实例为value
val rowKey = Bytes.toBytes(x._1)
val family = Bytes.toBytes(x._2._1)
val colum = Bytes.toBytes(x._2._2)
val value = Bytes.toBytes(x._2._3.toString)
(new ImmutableBytesWritable(rowKey), new KeyValue(rowKey, family, colum, value))
})
//文件保存在hdfs的位置
val locatedir = "hdfs://" + node.toString + ":8020/user/bulkload/hfile/usergroup_HBase_" + data_date
//在locatedir生成的Hfile文件
rdds.saveAsNewAPIHadoopFile(locatedir,
classOf[ImmutableBytesWritable],
classOf[KeyValue],
classOf[HFileOutputFormat2],
conf)
//HFile导入到HBase
val load = new LoadIncrementalHFiles(conf)
//HBase的表名
val tableName = "userprofile_labels"
//创建HBase的链接,利用默认的配置文件,读取HBase的master地址
val conn = ConnectionFactory.createConnection(conf)
//根据表名获取表
val table = conn.getTable(TableName.valueOf(tableName))
try {
//获取HBase表的region分布
val regionLocation = conn.getregionLocation(TableName.valueOf(tableName))
//创建一个hadoop的mapreduce的job
val job = Job.getInstance(conf)
//设置job名称,任意命名
job.setJobName("Hive2HBase")
//输出文件的内容KeyValue
job.setMapOutputValueClass(classOf[KeyValue])
//设置文件输出key, outkey要用ImmutableBytesWritable
job.setMapOutputKeyClass(classOf[ImmutableBytesWritable])
//配置HFileOutputFormat2的信息
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocation)
//开始导入
load.doBulkLoad(new Path(locatedir), conn.getAdmin, table, regionLocation)
} finally {
table.close()
conn.close()
}
spark.close()
}
}
提交Spark任务,将HFile中 数据bulk load到HBase中。执行完成后,可以在HBase中看到该数据已经写入“userprofile_ labels” 中(图3-20)。
在线接口在查询HBase中数据时,由于HBase无法像关系数据库那样根据多种条件对数据进行筛选(类似SQL语言中的where筛选条件)。一般地HBase需建立二级索引来满足根据复杂条件查询数据的需求,本案中选用Elasticsearch存储HBase索引数据(图3-21)。
在组合标签查询对应的用户人群场景中,首先通过组合标签的条件在Elasticsearch中查询对应的索引数据,然后通过索引数据去HBase中批量获取rowkey对应的数据(Elasti csearch中的document id和HBase中的rowkey都设计为用户id)。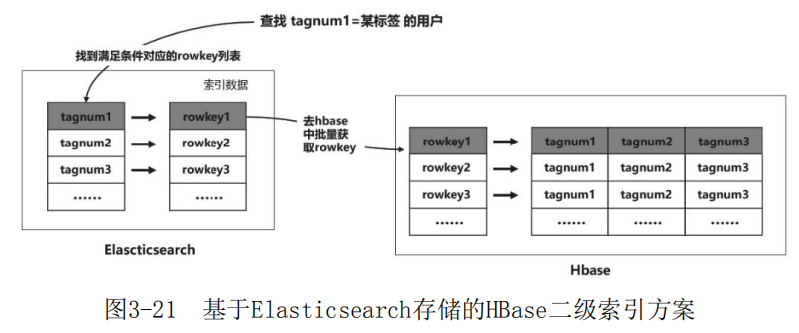
为了避免从Hive向HBase灌入数据时缺失,在向HBase数据同步完成后,还需要校验HBase和Hive中数据量是否一致,如出现较大的波动则发送告警信息。
下面通过Py thon脚本来看该HBase状态表数据校验逻辑:
# 查询Hive数据
def check_Hive_data(data_date):
r = os.popen("Hive -S -e\"select count(1) from "
"dw.userprofile_usergroup_labels_all where data_date='"+data_date+"'\"")
Hive_userid_count = r.read()
r.close()
Hive_count = str(int(Hive_userid_count))
print("Hive_result: " + str(Hive_count))
print("Hive select finished!")
# 查询HBase中数据
def check_HBase_data(data_date):
r = os.popen("HBase org.apache.hadoop.HBase.mapreduce.RowCounter'userprofile_labels'\" 2>&1 |grep ROWS")
HBase_count = r.read().strip()[5:]
r.close()
print("HBase result: " + str(HBase_count))
print("HBase select finished!")
# 连接 DB,将查询结果插入表
db = MySQLdb.connect(host="xx.xx.xx.xx",port=3306,user="username",
passwd="password", db="xxx", charset="utf8")
cursor = db.cursor()
cursor.execute("INSERT INTO service_monitor(date, service_type, Hive_count,HBase_count)"
"VALUES('"+datestr_+"', 'advertisement',"+str(Hive_userid_count)+","+str(HBase_count)+")")
db.commit()
本案例中将userid作为rowkey存入HBase,-方 面在组合标签的场景中可以支持条件查询多用户人群,另一方面可以支持单个用户标签的查询,例如查看某id用户身上的标签,以便运营人员决定是否对其进行运营操作。
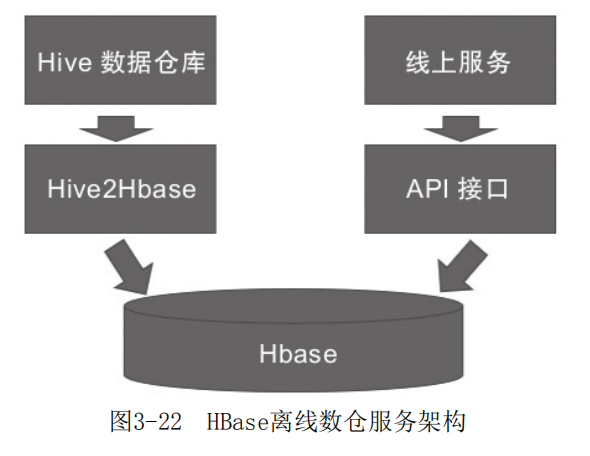
HBase在离线数仓环境的服务架构如图3-22所示。
3.4 Elasticsearch存储
3.4.1 Elasticsearch简介
Elasticsearch是一个开源的分布式全文检索引擎,可以近乎实时地存储、检索数据。而且可扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。对于用户标签查询、用户人群计算、用户群多维透视分析这类对响应时间要求较高的场景,也可以考虑选用Elasticsearch进行存储。
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用json作为文档格式。为了更清晰地理解Elasticsearch查询的一些概念,将其和关系数据库的类型进行对照,如图3-23所示。
在关系型数据库中查询数据时可通过选中数据库、表、行、列来定位所查找的内容,在Elasticsearch中 通过索引(index) 、类型(type)、文档(document) 、字段来定位查找内容。一个Elasticsearch集群可以包括多个索引(数据库),也就是说,其中包含了很多类型(表),这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交 互可以使用Java API,也可以使用HTTP的RESTful API方式。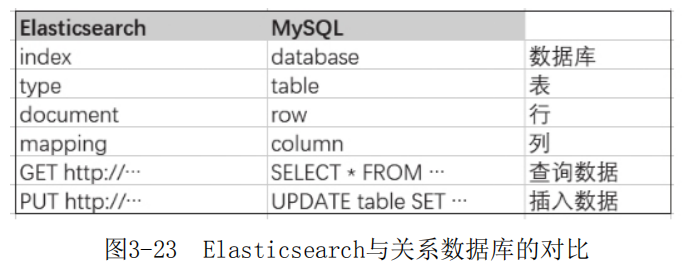
3.4.2 应用场景
基于HBase的存储方案并没有解决数据的高效检索问题。在实际应用中,经常有根据特定的几个字段进行组合后检索的应用场景,而HBase采用rowkey作为- -级索引, 不支持多条件查询,如果要对库里的非rowkey进行数据检索和查询,往往需要通过MapReduce等分布式框架进行计算,时间延迟上会比较高,难以同时满足用户对于复杂条件查询和高效率响应这两方面的需求。
为了既能支持对数据的高效查询,同时也能支持通过条件筛选进行復杂查询,需要在HBase上构建二级索引,以满足对应的需要。在本案中我们采用Elasticsearch存储HBase的索引信息,以支持复杂高效的查询功能。
主要查询过程包括:
1)在Elasticsearch中存放用于检索条件的数据,并将rowkey也存储进去;
2)使用Elasticsearch的API根据组合标签的条件查询出rowkey的集合;
3)使用上一步得到的rowkey去HBase数据库查询对应的结果(见图3-24)。
HBase数据存储数据的索引放在E1 ast icsearch中,实现了数据和索引的分离。在Elasticsearch中documentid是文档的唯一标识, 在HBase中rowkey是记录的唯一标识。 在工程实践中,两者可同时选用用户在平台上的唯一标识(如userid或deviceid)作为rowkey或documentid,进而解决HBase和Elasticsearch索引关联的问题。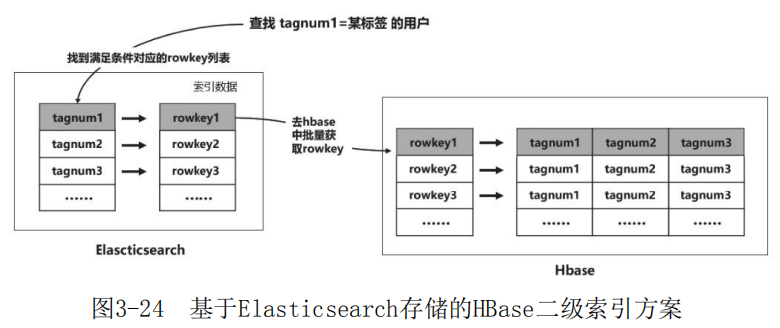
下面通过使用Elasticsearch解决用户人群计算和分析应用场景的案例来了解这一过程。
对汇聚后的用户标签表dw. userprofileuser1abel_map_all (3. 1.3节)中的数据进行清洗,过滤掉一些无效字符,达到导入Elast icsearch的条件,如图3-25所示。
然后将dw.userprofile_userlabel map_all数据写入Elasticsearch中,Scala代码如下:
工程依赖如下:
将该工程打包之后提交任务,传入日期分区参数“20190101”执行。提交命令“spark-submit—class com.example.HiveDataToEs—master yarn—deploy-mode client—executor-memory 2g—num-executors 50—driver-memory 3g—executor-cores 2 spark-hive-to-es.jar 20190101”。
任务执行完毕后,当日userid维度的用户标签数据全部导入Elasticsearch中。使用RESTfulAPI查询包含某个标签的用户量,可实时得到返回结果,如图3-26所示。

从返 回结果中可以看到,用户总量(total) 为100000000人,包含标签“ACTION_U_01_003”的用户有2500000人(doc_count)。
查询人群index查看标签总量:
查询结果:
在人群的计算和分析场景中,经过产品的迭代,前期采用Impala进行计算,一般耗费几十秒到几分钟的时间,在使用Elasticsearch后,实现了对人群计算的秒级响应。
3.4.3 工程化案例
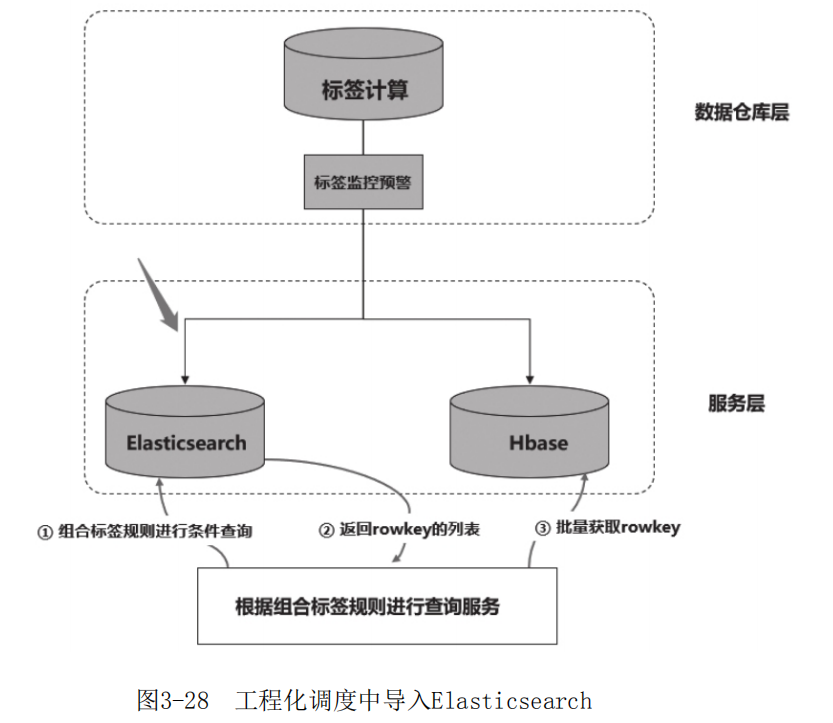
下面通过一个工程案例来讲解实现画像产品中“用户人群”和“人群分析”功能对用户群计算秒级响应的一种解决方案。
在每天的ETL调度中,需要将Hive计算的标签数据导入Elasticsearch中。如图3-28所示,在标签调度完成且通过校验后(图3-28中的“标签监控预警”任务执行完成后),将标签数据同步到Elasticsearch中。
在与Elasticsearch数据同步完成并通过校验后,向在MySQL中 维护的状态表中插入一条状态记录,表示当前日期的Elasticsearch数据可用,线上计算用户人群的接口则读取最近日期对应的数据。如果某天因为调度延迟等方面的原因,没有及时将当日数据导入Elasticsearch中,接口也能读取最近一天对应的数据,是一种可行的灾备方案。
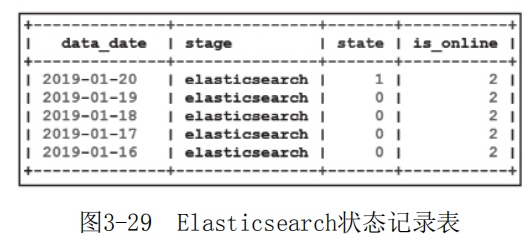
例如,数据同步完成后向MySQL状态表“elasticsearch_ state” 中插入记录(如图3-29所示),当日数据产出正常时,state字段为“0”,产出异常时为“1”。图3-29中1月20日导入的数据出现异常,则“state” 状态字段置1,线上接口扫描该状态记录位后不读取1月20日数据,而是取用最近的1月19日数据。
为了避免从Hi ve向Elast icsearch中灌入数据时发生数据缺失,在向状态表更新状态位前需要校验Elast icsearch和Hive中的数据量是否一致。下面通过Python脚本来看数据校验逻辑:
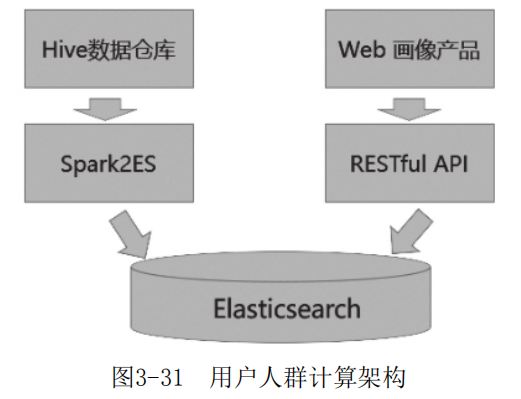
上面介绍了在工程化调度流中何时将Hive中的用户标签数据灌入Elasticsearch中,之后业务人员在画像产品端计算人群或透视分析人群时( 如图3-30所示),通过RESTful API访问Elasticsearch进行计算(如图3-31所示)。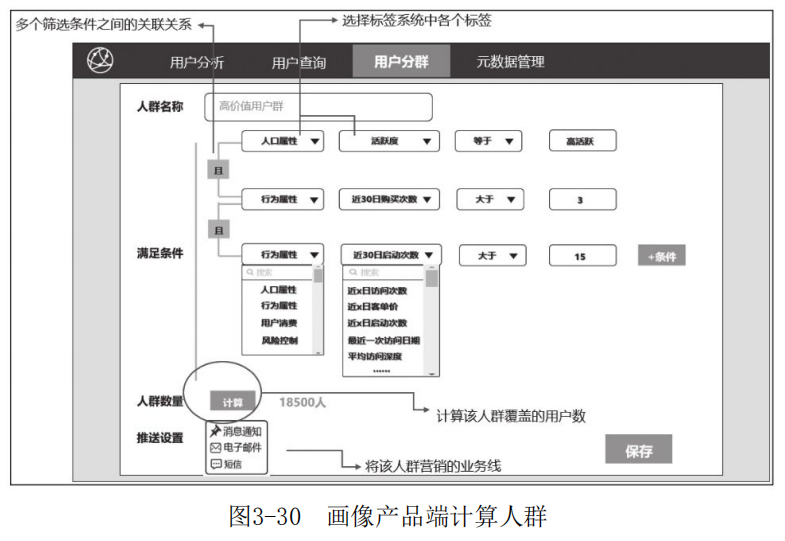
3.5 本章小结
本章讲解了使用Hive、MySQL、 HBase 和E1 asticsearch存储标签数据的解决方案,包括: Hive存储数据相关标签表、人群计算表的表结构设计以及ID-Mapping的一种实现方式;MySQL存储标签元数据、监控
数据及结果集数据; HBase存储线_上接口实时调用的数据;Elasticsearch存储标签用于人群计算和人群多维透视分析。
存储过程中涉及如下相关表。
●dw.userprofile_attritube_all:存储人口属性维度的标签表;
●dw.userprofile_action_all:存储行为属性维度的标签表;
●dw.userprofile_consume_all:存储用户消费维度的标签表;
●dw.userprofile_riskmanage_all:存储风险控制维度的标签表;
●dw.userprofile_social_all:存储社交属性维度的标签表;
●dw.userprofile_userlabel_map_all:汇聚用户各维度标签的表;
●dw.userprofile_usergroup_labels_all: 存储计算后人群数据的表。
面向不同的工程场景使用不同的存储方案,本章通过“工程场景+案例”的形式介绍了一种可实现的用户标签存储解决方案。

若有收获,就点个赞吧
0 人点赞
