- 分析工具:Python、MySQL、Excel
- 可视化软件: PowerBI、Office套件(PPT、Excel图表)
- 大数据平台:Hadoop (HBASE、Hive SQL)
- 任务:数据清洗、分析、可视化、Tableua可视化报告、解读数据模型结果
- 分析方法:方差分析、假设检验、回归分析、KNN、K-means、季节分析、PSM模型、KANO模型
聚类分析、因子分析、对应分析、相关分析、文本语义分析、文本情感分析
- 行业:娱乐、汽车行业项目经验
PSM模型也即价格敏感度测试模型(Price Sensitivity Measurement),PSM价格敏感度分析方法。
KANO模型是一个典型的定性分析模型,一般不直接用来测量用户的满意度,常用于识别用户对新功能的接受度。帮助企业了解不同层次的用户需求,找出顾客和企业的接触点,挖掘出让顾客满意至关重要的因素。(产品)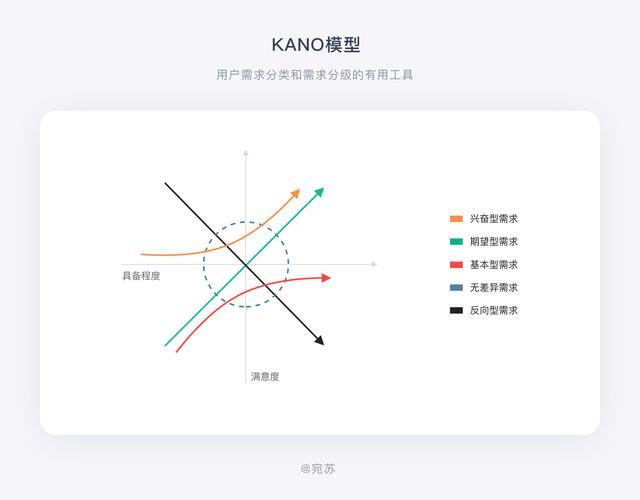
文本分词处理
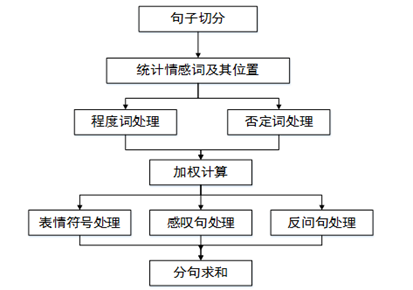
情感分析(Sentiment analysis,SA),又称倾向性分析、意见抽取(Opinion extraction)、意见挖掘(Opinion mining)、情感挖掘(Sentiment mining)、主观分析(Subjectivity analysis)
作者:羋虹光
链接:https://www.jianshu.com/p/1f69920048d5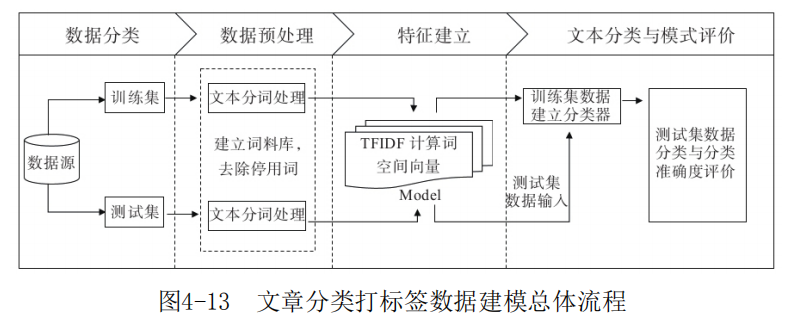
TF: Term Frequency 词频。统计在文档中出现的词汇及其频率或比例。TF = 该词在文档出现的次数 ;
TF = 该词在文档出现的次数 / 文档的总词数;
TF = 该词在文档出现的次数 / 该文档出现次数最大的词的出现次数。
IDF: Inverse Document Frequency 逆文档率。给词汇设置权重,越常见的词汇权重越小。
IDF = log[语料库的文档总数 /(包含该词的文档数 + 1)]
TF-IDF, 既要考虑词汇出现的频次,也要考虑词汇的权重
TF-IDF = TF × IDF
tf-idf 单词的词频和逆文档率
# 清洗文本def clearTxt(line:str):if(line != ''):line = line.strip()# 去除文本中的英文和数字line = re.sub("[a-zA-Z0-9]", "", line)# 去除文本中的中文符号和英文符号line = re.sub("[\s+\.\!\/_,$%^*(+\"\';:“”.]+|[+——!,。??、~@#¥%……&*()]+", "", line)return linereturn None#文本切割def sent2word(line):segList = jieba.cut(line,cut_all=False)segSentence = ''for word in segList:if word != '\t':segSentence += word + " "return segSentence.strip()
用sklearn进行TF-IDF预处理
第一种方法是在用 CountVectorizer 类向量化之后再调用 TfidfTransformer 类进行预处理。
from sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfTransformer# 读取语料库corpus = open("data.txt", "r", encoding='utf-8').read().split("\n")vectorizer = CountVectorizer(max_features=20000)# 该类会统计每个词语的tf-idf权值tf_idf_transformer = TfidfTransformer()# 将文本转为词频矩阵并计算tf-idftfidf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(corpus))# 获取词袋模型中的所有词语的tf-idf值tfidf_matrix = tfidf.toarray()# 获取词袋模型中的所有词语word = vectorizer.get_feature_names()
第二种方法是直接用 TfidfVectorizer 完成向量化与 TF-IDF 预处理。
from sklearn.feature_extraction.text import TfidfVectorizercorpus = open("data.txt", "r", encoding='utf-8').read().split("\n")vectorizer = TfidfVectorizer()# 加入停用词# vectorizer = TfidfVectorizer(stop_words=stopwords, sublinear_tf=True, max_df=0.5)vectors = vectorizer.fit_transform(corpus)
半监督算法:
把带有“演技”分词的文档作为 LDA 算法模型的训练数据,训练模型。再去预测未带有“演技”分词的文档,预测是否该文档的主题是否为“演技”。
方差分析(ANOVA)
“变异数分析”或“F检验”
本质上,方差分析是一种因果或相关关系有无的判别,用的是假设检验的技术。这是大前提。 小前提是,自变量是分类变量,比如因素水平,性别,颜色等;因变量是数值变量,比如产量,大小,合格率等。 这种场景下,要判断两个变量的因果关系,用假设检验的方差分析技术,再具体点就是F检验。 当然,为了满足F检验条件,还有一系列关于变量分布的假设,比如要求因变量是正态分布,相关关系是线性的等等。若不满足则要么承担这层错误,要么,另行推导。 还有自变量的类型变化时候,这种因果或相关关系的判断也基本有体系了,分别是列联表的卡方,费雪检验;回归方程的参数f,t检验;还有经典的双总体假设检验。加上方差分析一共4个类型,连续和离散变量两个类型的二元元组也是4种,大家对号入座。
知乎作者:magic2728 链接:https://www.zhihu.com/question/61319844/answer/1400654462
ANOVA模型的零假设即为 ,即两样本期望相等。换句话来说,其实方差分析的思想就是假设检验。
,即两样本期望相等。换句话来说,其实方差分析的思想就是假设检验。
那么如何对这一假设进行检验?从直觉上来说,如果两组之间的“变异”相较于组内的“变异”来说很小,那么我们就认为零假设成立,否则选择备择假设。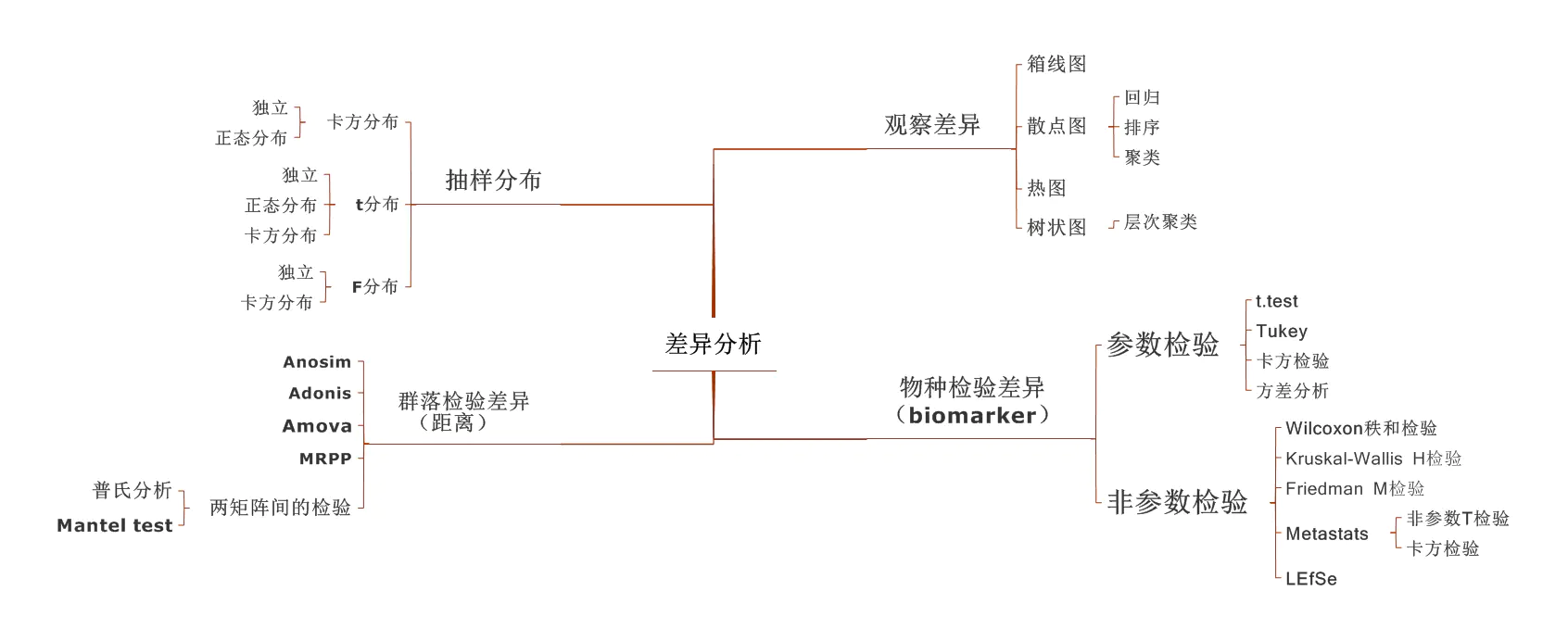
卡方检验
F检验
T检验
假设检验
目的是确定一个观测到的效果是否是由随机性造成的。
显著性检验可以用于确定观测到的效果是否落在零假设模型的随机变异范围内。
点估计量和置信区间是两种估计总体统计量的方法:
点估计量方法可用于估计总体统计量的精确数值,是根据样本数据有可能做出的最好猜测。
置信区间得到的并非总体统计量的精确估计,而是求出总体统计量的一个有较高可信度的数值范围。
假设检验就是在计算样本统计量,是否在总体统计量的置信区间内。(所有的显著性检验都要求指定一个检验统计量去测量所关注的效果,并确定观测到的效果是否落在随机变异的范围内。)
假设检验的6个步骤:
①确定要进行检验的假设。要对其进行试验的断言。 H0, H1。
零假设的逻辑理念体现为没有特殊事件发生,任何观察到的效果都是由随机偶然导致的。
②选择检验统计量。选取最有效地对断言进行检验的统计量。
卡方检验
F检验
T检验
季节性分析
(周期因子?)
季节性变动分析( season change analysis)以月份或季度为时间观察单位,对时间序列数据及其随时间变化而呈现周期性变动的规律进行的探索与分析。 ——百度百科
季节性变动,是指客观实物由于自然条件、生产条件和生活习惯等因素的影响,岁这季节的转变而呈现出周期性变动。
季节调整分析的基本思想是:认为时间序列由四部分组成,分别是趋势性T(Trend)、季节性S(Seasonal fluctuation)、周期性P(Periodicity)和不规则波动性I(IrregularVariations)。这四个变量通过不同的组合方式影响时间序列的发展变化。其中最常见的是交乘形式,认为时间序列是由四种特性相乘形成,乘法模型适用于t\s\p\i相关情形,其数学表达式为y=tspi.相应的就有时间序列的加法模型:y=t+s+p+i,认为时间序列是由趋势性、季节性、周期性、不规则波动性相加形成,加法模型适用于t/s/p/i独立的情形。
在该模型基础上,可以通过y/s=tpi将季节性特征从时间序列中分解出去,从而更好的展现时间序列的趋势性、周期性或者其他特点。
*步骤:
1、根据时间序列的趋势图测定数据,判断是否呈现季节性特征。
2、根据加和模型或加乘模型的不同处理方式剔除季节性,使得数据值呈现出长期趋势或其他特征
a.计算不同年份的同月份数据的平均数
b.依据所计算得到的平均值,计算12个月的月均值
c.计算:各月平均数/月均值=季节指数
d.每个月份的原始数据/对应月份的季节指数=当月剔除季节性后反映的数值
3、依据剔除季节性后反应的数据,进一步做时间序列分析(可选择趋势外推模型、移动平均模型、指数平滑模型等作拟合)
4、得到还原前预测值,再乘回季节指数,获得最终的预测值。
因子分析和数据降维的异同
https://blog.csdn.net/taojiea1014/article/details/79683826
1.原理不同:
- 主成分分析(Principal components analysis,PCA)基本原理:利用降维(线性变换)的思想,在损失很少信息的前提下把多个指标转化为几个不相关的综合指标(主成分),即每个主成分都是原始变量的线性组合,且各个主成分之间互不相关,使得主成分比原始变量具有某些更优越的性能(主成分必须保留原始变量90%以上的信息),从而达到简化系统结构,抓住问题实质的目的。
- 因子分析(Factor Analysis,FA)基本原理:利用降维的思想,由研究原始变量相关矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量表示成少数的公共因子和仅对某一个变量有作用的特殊因子线性组合而成。就是要从数据中提取对变量起解释作用的少数公共因子(因子分析是主成分的推广,相对于主成分分析,更倾向于描述原始变量之间的相关关系)。
2.线性表示方向不同:
- 因子分析是把变量表示成各公因子的线性组合;
- 主成分分析中则是把主成分表示成各变量的线性组合。
3.假设条件不同:
- 主成分分析:不需要有假设(assumptions);
- 因子分析:需要一些假设。因子分析的假设包括:各个共同因子之间不相关,特殊因子(specificfactor)之间也不相关,共同因子和特殊因子之间也不相关。
4.求解方法不同:
- 求解主成分的方法:
从协方差阵出发(协方差阵已知),从相关阵出发(相关阵R已知),采用的方法只有主成分法。(实际研究中,总体协方差阵与相关阵是未知的,必须通过样本数据来估计);
注意事项:由协方差阵出发与由相关阵出发求解主成分所得结果不一致时,要恰当的选取某一种方法;
一般当变量单位相同或者变量在同一数量等级的情况下,可以直接采用协方差阵进行计算;对于度量单位不同的指标或是取值范围彼此差异非常大的指标,应考虑将数据标准化,再由协方差阵求主成分。
实际应用中应该尽可能的避免标准化,因为在标准化的过程中会抹杀一部分原本刻画变量之间离散程度差异的信息。此外,最理想的情况是主成分分析前的变量之间相关性高,且变量之间不存在多重共线性问题(会出现最小特征根接近0的情况);
- 求解因子载荷的方法:
主成分法,主轴因子法,极大似然法,最小二乘法,a因子提取法。
5.主成分和因子的变化不同:
- 主成分分析:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的独特的;
- 因子分析:因子不是固定的,可以旋转得到不同的因子。
6.因子数量与主成分的数量
- 主成分分析:主成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等),实际应用时会根据碎石图提取前几个主要的主成分。
- 因子分析:因子个数需要分析者指定(SPSS和SAS根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;
相关分析
散点图
协方差
相关系数
线性回归
信息熵和互信息
对应分析
对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
支持度:支持度可以理解为物品当前流行程度
P(A)
置信度:置信度是指如果购买物品A,有较大可能购买物品B
P(B|A)=P(AB)/P(B)
提升度:提升度指当销售一个物品时,另一个物品销售率会增加多少。
P(B|A)/P(A)

若有收获,就点个赞吧
0 人点赞
