python数据爬取
安装scrapy
分析网页
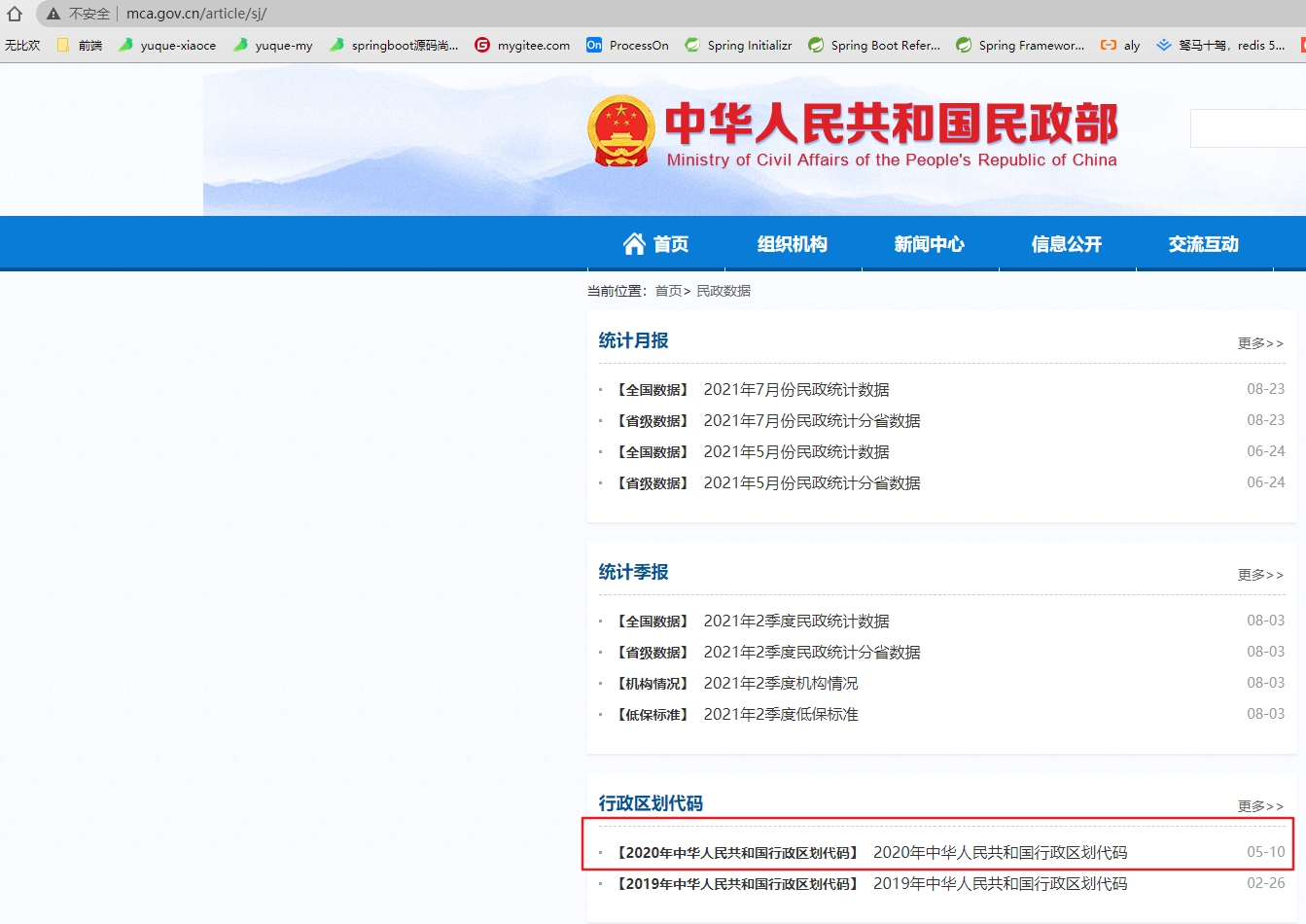
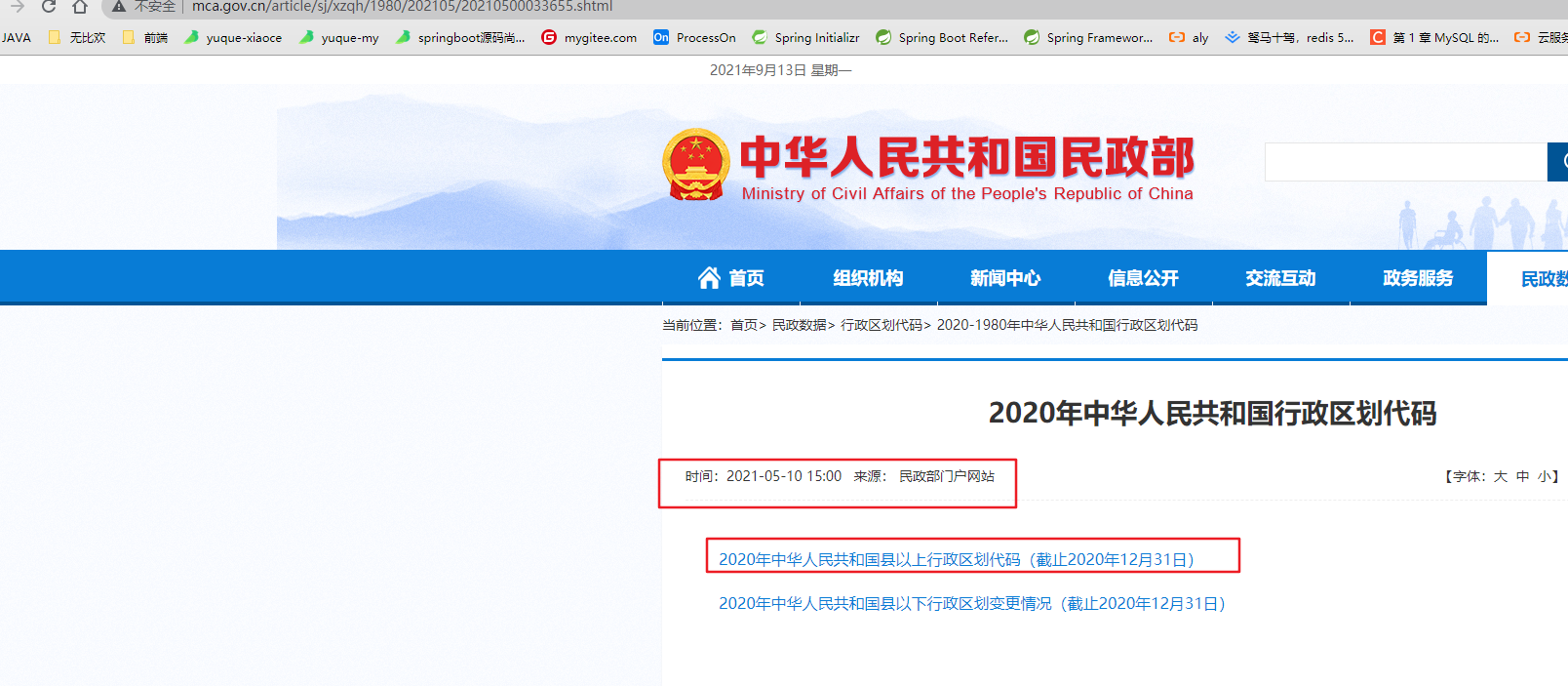
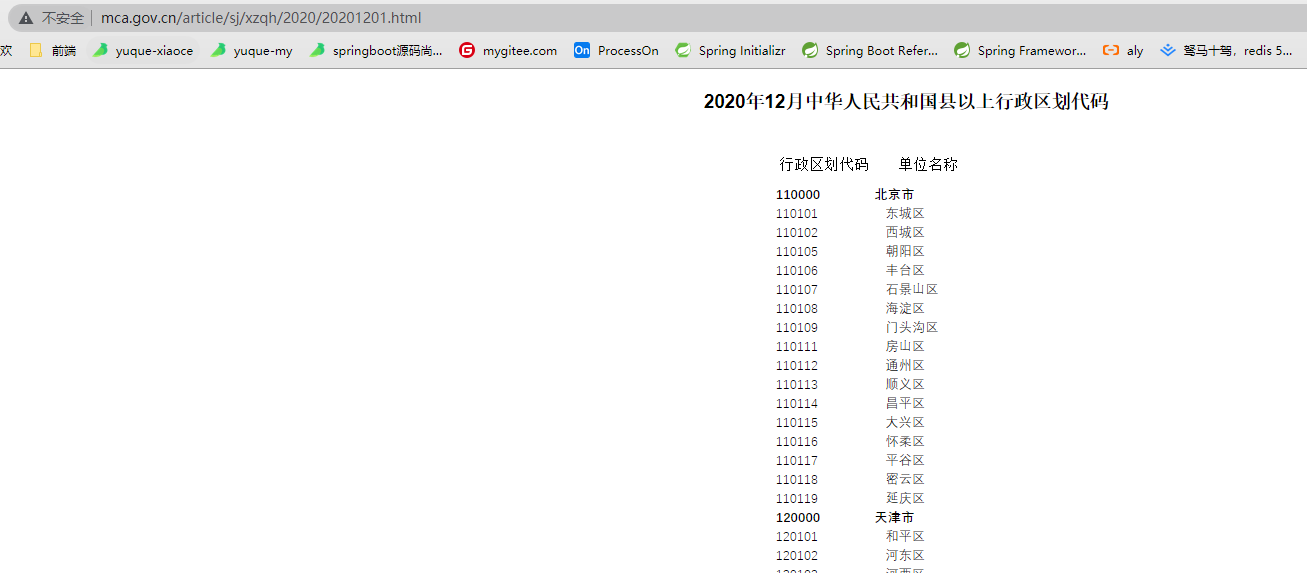
爬虫逻辑
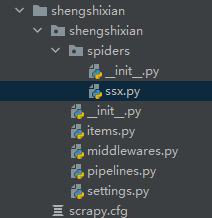
项目结构
主要逻辑
找到name和code
import scrapyfrom shengshixian.items import ShengshixianItemclass SsxSpider(scrapy.Spider):name = 'ssx'allowed_domains = ['www.mca.gov.cn']start_urls = ['http://www.mca.gov.cn/article/sj/xzqh/2020/20201201.html']def parse(self, response):trarray = response.xpath('//tr[@height="19"]')for tr in trarray:code = tr.xpath('./td[2]/text()').get()name = tr.xpath('./td[3]/text()').get()item = ShengshixianItem(name=name, code=code)yield item
保存到json
from scrapy.exporters import JsonItemExporterclass ShengshixianPipeline:def __init__(self):self.fp = open('region.json', 'wb')self.exporter = JsonItemExporter(self.fp, ensure_ascii=False, encoding='utf8')self.exporter.start_exporting()def open_spider(self, spider):print('begin')def process_item(self, item, spider):self.exporter.export_item(item)return itemdef close_spider(self, spider):self.exporter.finish_exporting()print('end')self.fp.close()
java数据处理并入库
发现问题
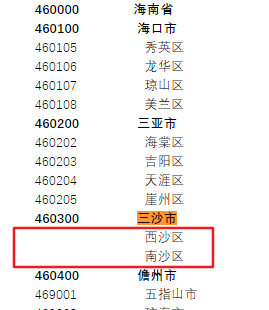
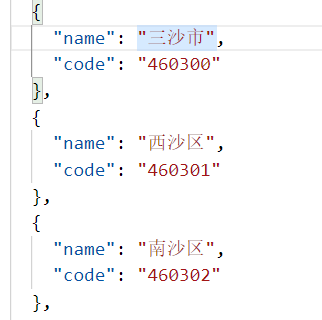
1.三沙市的两个区没有code
2.新疆的石河子等十个市没有父级,还有神农架,海南也有这种直辖市
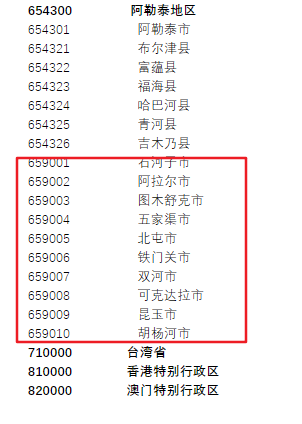
解决办法:手动加个父节点,百度一下,发现这些算是直属的市,但是编号比较奇怪,像区和县一样,利用代码判断这些特殊的省级直辖市
3.四个直辖市结构不一样
java代码

service和mapper就用mybatis-plus通用的那种
使用FileUtil读取json,然后用fastjson处理json,使用mybatis-plus入库mysql
@SneakyThrows@Testpublic void regionJson() {long l = System.currentTimeMillis();String jsonFilePath = "C:\\Users\\leo\\Desktop\\region.json";File file = new File(jsonFilePath );String input = FileUtils.readFileToString(file,"UTF-8");List<ProCityCounty> array = JSONArray.parseArray(input, ProCityCounty.class);Map<Integer, String> map = array.stream().collect(Collectors.toMap(ProCityCounty::getCode, ProCityCounty::getName));for (ProCityCounty proCityCounty : array) {proCityCounty.setId(Long.valueOf(proCityCounty.getCode()));//省逻辑if (proCityCounty.getCode() % 10000 == 0) {proCityCounty.setGrade(1);proCityCounty.setFullname(proCityCounty.getName());}//市逻辑else if (proCityCounty.getCode() % 100 == 0) {proCityCounty.setGrade(2);Integer pCode = proCityCounty.getCode() / 10000;String pname = map.get(pCode*10000);proCityCounty.setPid(pCode*10000);proCityCounty.setFullname(pname+"-"+proCityCounty.getName());}else {Integer pCode=proCityCounty.getCode()/10000;//国的四大直辖市下属区县的逻辑if (NumberUtil.equals(pCode,11)||NumberUtil.equals(pCode,12)||NumberUtil.equals(pCode,50)||NumberUtil.equals(pCode,31)) {proCityCounty.setGrade(2);proCityCounty.setPid(pCode*10000);String pname = map.get(pCode*10000);String fullName=pname+"-"+proCityCounty.getName();proCityCounty.setFullname(fullName);}else {Integer cCode = proCityCounty.getCode() / 100;proCityCounty.setGrade(3);String pname = map.get(pCode*10000);//省的直辖市逻辑if (cCode % 100 == 90) {proCityCounty.setPid(cCode*100);proCityCounty.setPid(pCode*10000);String fullName=pname+"-"+proCityCounty.getName();proCityCounty.setFullname(fullName);}else {String cName = map.get(cCode*100);proCityCounty.setPid(cCode*100);String fullName=pname+"-"+cName+"-"+proCityCounty.getName();proCityCounty.setFullname(fullName);}}}}proCityCountyService.saveBatch(array,1000);System.out.println((System.currentTimeMillis()-l)/1000+"秒");}
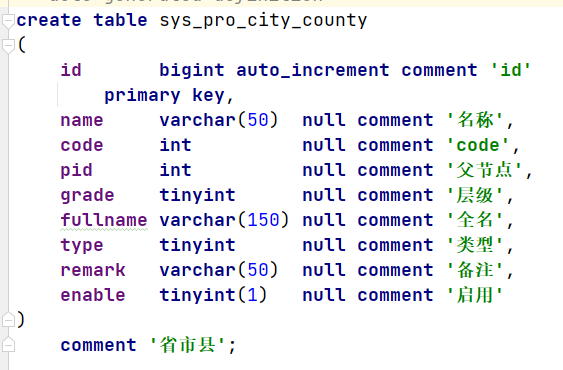
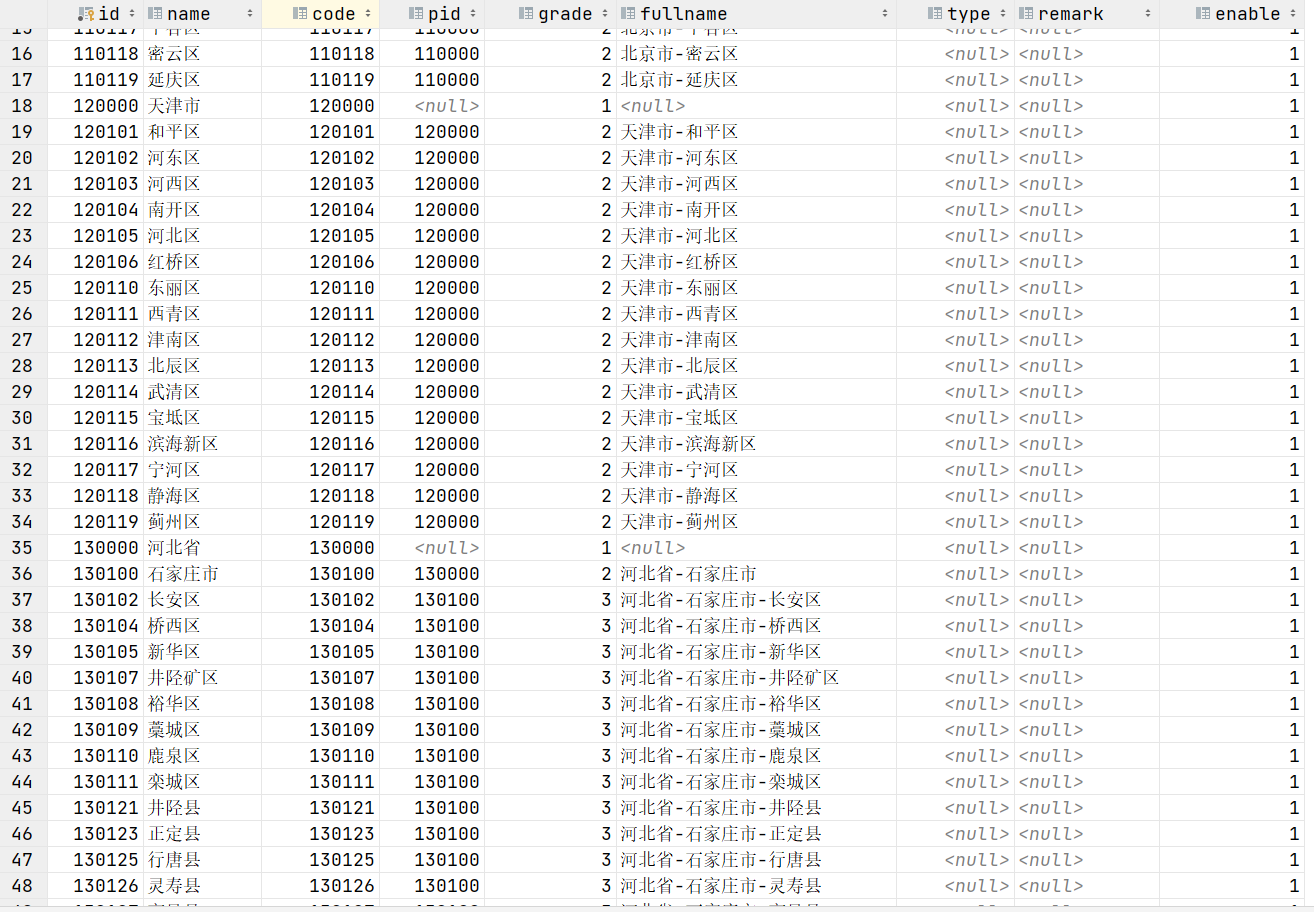
最终数据库
最终前端
前端用ztree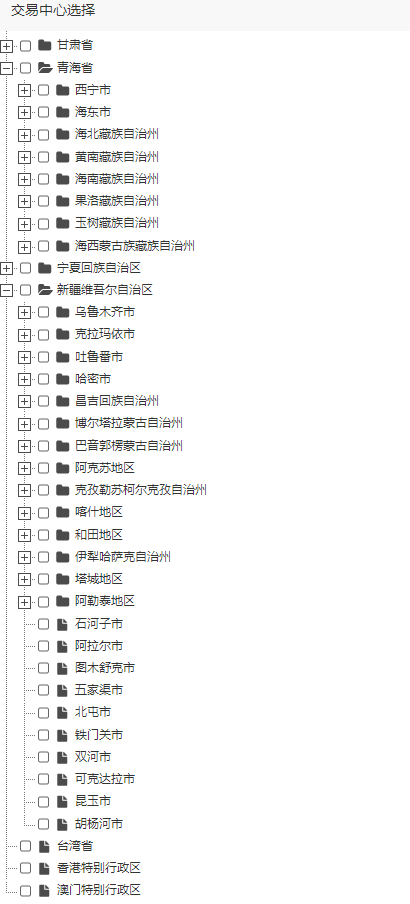

若有收获,就点个赞吧
0 人点赞
