前言
索引的增加和删除以及查询
# 创建索引create index index_name on table_name(field1,field2);# 删除索引drop index index_name on table_name;# 展示索引show index from table_name;
单表
表结构
CREATE TABLE `article` (`id` int unsigned NOT NULL AUTO_INCREMENT,`author_id` int unsigned NOT NULL,`category_id` int unsigned NOT NULL,`views` int unsigned NOT NULL,`comments` int unsigned NOT NULL,`title` varchar(255) NOT NULL,`content` text NOT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
语句
SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
查询分类为1,评论数大于1的,点击量最高的文章
索引方式
1.顺序3个索引
说明:按照where的顺序+order的顺序
create index a on article(category_id,comments,views);
效果如下
分析
用到了category_id
用到了comments 的范围查询
没用到views(效果等同于建了上面2个索引create index a on article(category_id,comments);)
排序没用到:Using filesort;这点可以验证:范围后的索引会导致索引失效
2.where的相等条件和order索引
create index b on article(category_id,views);
说明:等值和排序加上索引
效果如下
分析
用到了category_id
用到views,排序用到了
comments > 1:这个没用到了
Using filesort消失了,算是优化
总结
2种优化方式中,2个效率更好一些
如果表记录多了,可以再试一试
双表
表结构
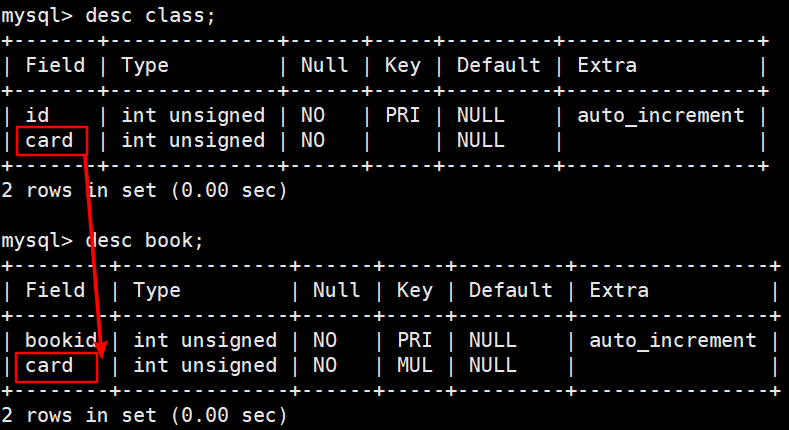
语句
SELECT FROM class LEFT JOIN book ON class.card = book.card;
*左连接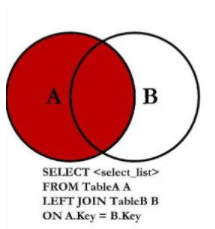
驱动表是左表class
索引方式
1.在右表添加索引
分析

2.在左表添加索引
drop index a on book;
create index b on class(card);
分析

总结
左连接:给右表的字段加索引
右链接:给左表的字段加索引
左连接的话,左表数据相当于for循环外层,右表数据相当于for循环内层
最佳优化就是外循环尽量小,小表(外层)驱动大表,内循环是大表,加上索引,就可以过滤,减少了内循环,总次数降低,没不会产生join buffer
三表
表结构
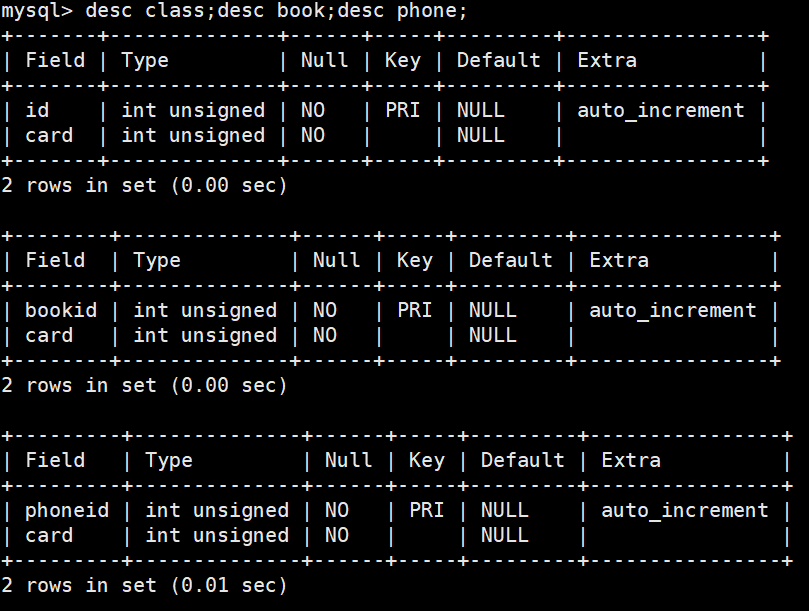
语句
SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;
索引方式
1.参考双表的
create index bi on book(card);
create index pi on phone(card);
给中层循环的关联字段加索引,外层循环的关联字段加索引
分析

总结
将 left join 看作是两层嵌套 for 循环
- 尽可能减少Join语句中的NestedLoop的循环总次数;
- 永远用小结果集驱动大的结果集(在大结果集中建立索引,在小结果集中遍历全表);
- 优先优化NestedLoop的内层循环;
- 保证Join语句中被驱动表上Join条件字段已经被索引;
- 当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置;
- 使用小表驱动大表,这就相当于外层 for 循环的次数少,内层 for 循环的次数多
- 然后我们在大表中建立了索引,这样内层 for 循环的效率明显提高
- 综上,使用小表驱动大表,在大表中建立了索引

若有收获,就点个赞吧
0 人点赞
