28.计算机网络
第一个计算机网络出现在1950~1960年代
优点:
- 通常在公司或研究室内部使用,为了方便信息交换
- 比把纸卡或磁带送到另一栋楼里更快速可靠
- 共享物理资源
因为电缆是共享的,连在同一个网络里的其他计算机也看得到数据,但不知道数据是给它们的,还是给其他计算机的,为了解决这个问题:
以太网需要每台计算机有唯一的媒体访问控制地址 简称 MAC地址,MAC放在头部,作为数据的前缀发送到网络中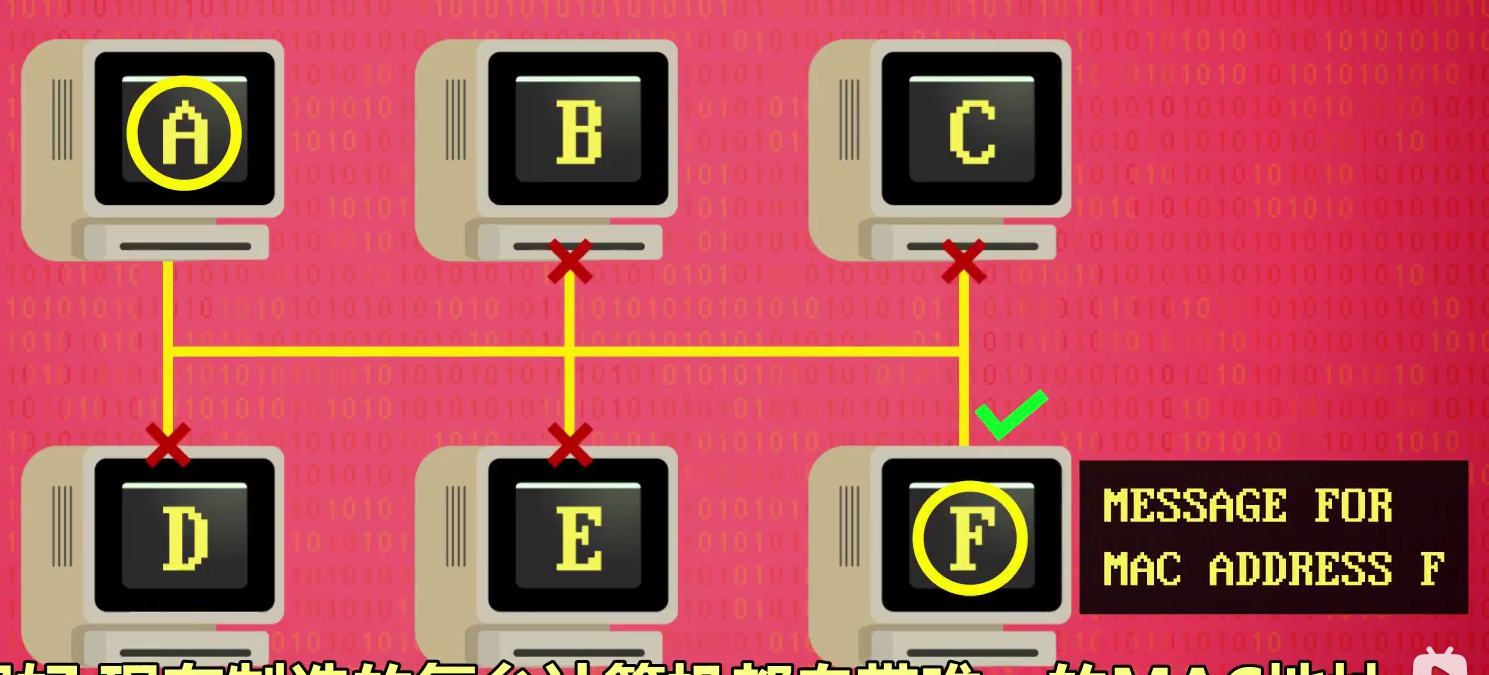
计算机只需要监听以太网电缆只有看到自己的 MAC 地址,才处理数据
这种设计模式不错,所以现在制造的每台计算机都自带唯一的MAC地址,用于以太网和无线网络
载波侦听多路访问CSMA
Carrier Sense Multiple Access
多台电脑共享一个传输媒介,这种方法叫 “载波侦听多路访问” 简称”CSMA”
载体(carrier)指运输数据的共享媒介:
- 以太网的”载体”是铜线
- WiFi 的”载体”是传播无线电波的空气
很多计算机同时侦听载体,所以叫”侦听”和”多路访问”,而载体传输数据的速度叫”带宽”
不幸的是 使用共享载体有个很大的弊端
当网络流量较小时 计算机可以等待载体清空,然后传送数据,但随着网络流量上升 两台计算机想同时写入数据的概率也会上升,这叫冲突,数据全都乱套了,计算机能够通过监听电线中的信号检测这些冲突
解决方法:
- 最明显的解决办法是停止传输,停止时间是一个随机数
- 如果再次发生冲突 表明有网络拥塞,这次不等1秒,而是等2秒,如果再次发生冲突 等4秒 然后8秒 16秒等等,直到成功传输
因为计算机的退避 冲突次数降低了..数据再次开始流动起来 网络变得顺畅
指数退避 Exponential Backoff
这种指数级增长等待时间的方法
以太网和WiFi都用这种方法 很多其他传输协议也用
冲突域 Collision Domain
即便有了”指数退避”这种技巧,想用一根网线链接整个大学的计算机还是不可能的,
为了减少冲突+提升效率,我们需要减少同一载体中设备的数量 ,载体和其中的设备总称 “冲突域”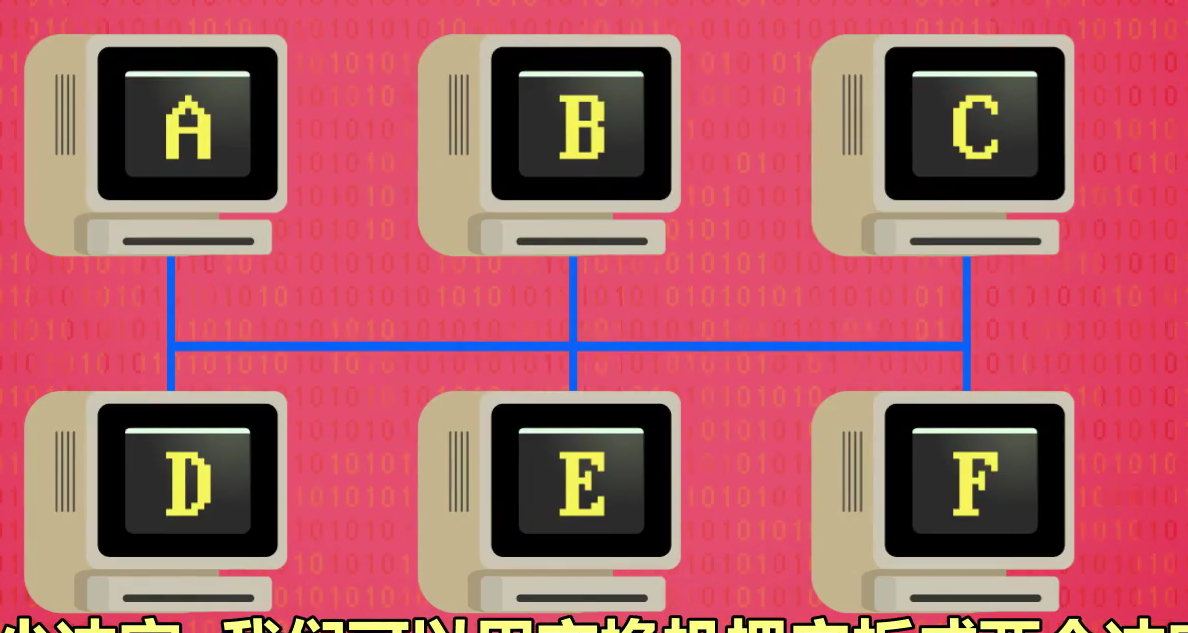

- 根据上图所示,刚开始是6个计算机共享1个载体,
- 改造以后3个共享内部载体,另外3个共享另一个内部载体
- abc内部传输信息,载体是内部的,不影响def
- a如果要传给e,那么就要经过交换机,两个网络都会被短暂占用,
大的计算机网络也是这样构建的,包括最大的网络 - 互联网,也是多个连在一起的稍小一点网络
路由
大型网络从一个地点到另一个地点通常有多条路线
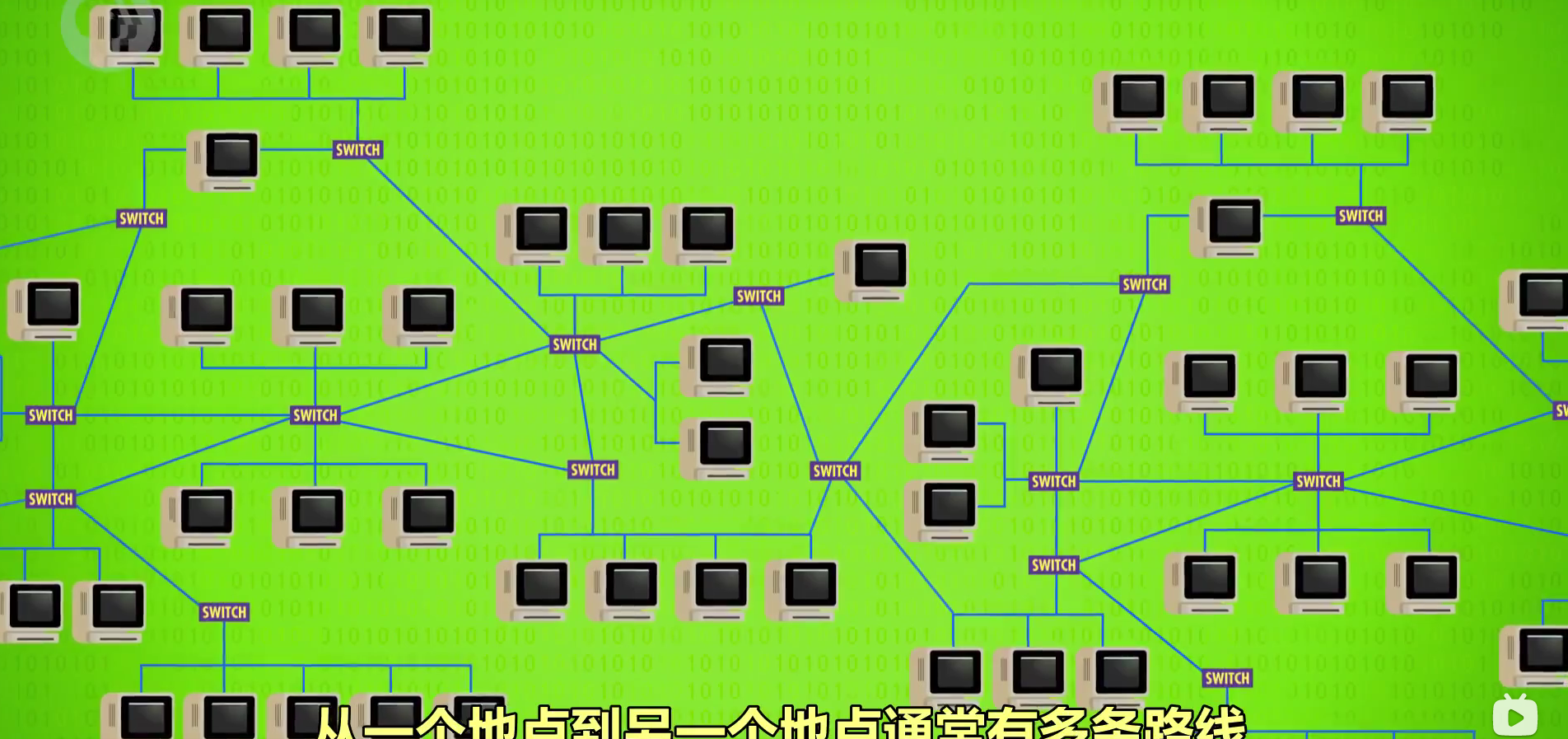
连接两台相隔遥远的计算机或网路,最简单的办法是分配一条专用的通信线路,早起电话系统电路交换 Circuit Switching
把电路连接到正确目的地,能用倒是能用,但不灵活而且价格昂贵 因为总有闲置的线路
好处是 如果有一条专属于自己的线路,你可以最大限度地随意使用,无需共享报文交换 Message Switching
“报文交换” 就像邮政系统一样,不像之前A和B有一条专有线路,消息会经过好几个站点
每个站点都知道下一站发哪里,因为站点有表格,记录到各个目的地,信件该怎么传
报文交换的好处是 可以用不同路由,使通信更可靠更能容错
“跳数”(hop count)
消息沿着路由跳转的次数,记录跳数很有用,因为可以分辨出路由问题
芝加哥认为去米苏拉的最快路线是奥马哈
奥马哈认为去米苏拉的最快路线是芝加哥
报文会在2个城市之间,不停传来传去,不仅浪费带宽 而且这个路由错误需要修复!
这种错误会被检测到,因为跳数记录在消息中,而且传输时会更新跳数,如果看到某条消息的跳数很高 ,就知道路由肯定哪里错了,这叫”跳数限制”
报文交换的缺点之一是有时候报文比较大会堵塞网络 因为要把整个报文从一站传到下一站后,才能继续传递其他报文
即便你只有一个1KB的电子邮件要传输, 也只能等大文件传完,或是选另一条效率稍低的路线
解决办法:
将大报文分成很多小块,叫”数据包”
就像报文交换 每个数据包都有目标地址,因此路由器知道发到哪里,报文具体格式由”互联网协议”定义,简称 IP,这个标准创建于 1970 年代,每台联网的计算机都需要一个IP地址,172.217.7.238 是 Google 其中一个服务器的IP地址
数百万台计算机在网络上不断交换数据 ,瓶颈的出现和消失是毫秒级的,路由器会平衡与其他路由器之间的负载以确保传输可以快速可靠,这叫”阻塞控制”
有时,同一个报文的多个数据包会经过不同线路,到达顺序可能会不一样,这对一些软件是个问题,幸运的是,在 IP 之上还有其他协议,比如 TCP/IP, 可以解决乱序问题分组交换 Packet Switching
将数据拆分成多个小数据包,然后通过灵活的路由传递,非常高效且可容错,如今互联网就是这么运行的
有个好处是 它是去中心化的,没有中心权威机构 没有单点失败问题,因为冷战期间有核攻击的威
如今,全球的路由器协同工作,找出最高效的线路,用各种标准协议运输数据
比如 “因特网控制消息协议”(ICMP)和 “边界网关协议”(BGP)以及现代互联网的祖先是 ARPANET29.互联网
如何连接
计算机为了获取这个视频(联网)首先要连到局域网,也叫 LAN,你家 WIFI 路由器连着的所有设备,组成了局域网.
- 局域网再连到广域网,广域网也叫 WAN,WAN 的路由器一般属于你的”互联网服务提供商”,简称 ISP
- 广域网里,先连到一个区域性路由器,这路由器可能覆盖一个街区。然后连到一个更大的 WAN,可能覆盖整个城市,可能再跳几次,但最终会到达互联网主干
- 互联网主干由一群超大型、带宽超高路由器组成
步骤:
- 数据包(packet)要先到互联网主干
- 沿着主干到达有对应视频文件的 YouTube 服务器
- 先跳4次到互联网主干,2次穿过主干,主干出来可能再跳4次,然后到 Youtube 服务器
通过命令查看跳转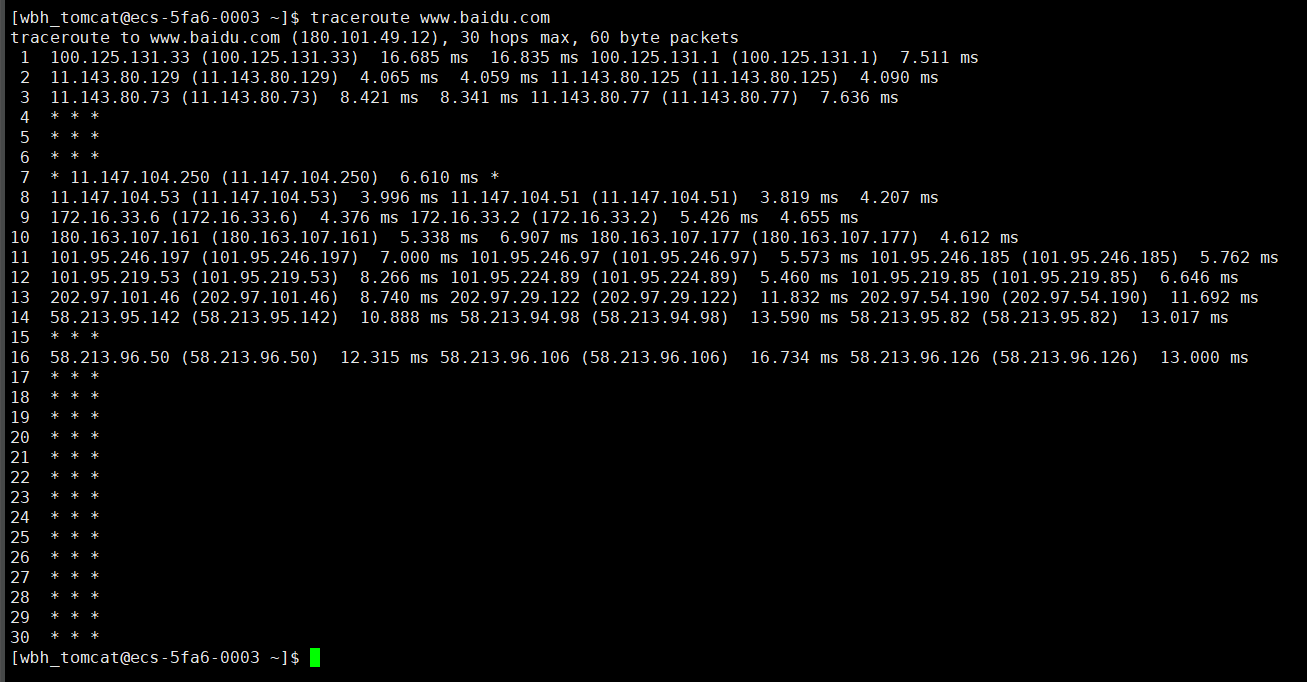
IP - 互联网协议
Internet Protocol
互联网是一个巨型分布式网络,会把数据拆成一个个数据包来传输,如果要发的数据很大,比如邮件附件,数据会被拆成多个小数据包,
数据包(packet)想在互联网上传输,要符合”互联网协议”的标准,简称 IP
IP 是一个非常底层的协议,数据包的头部(或者说前面)只有目标地址,头部存 “关于数据的数据” ,也叫 元数据(metadata)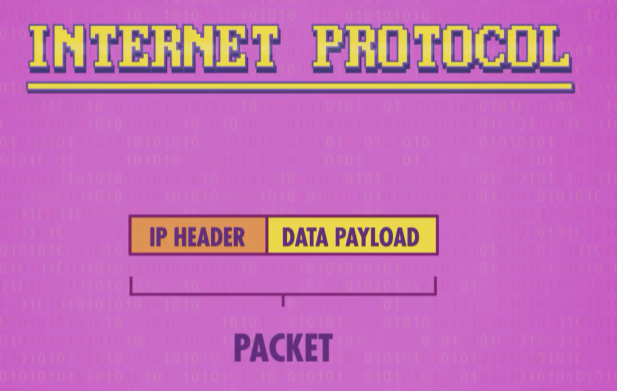
UDP - 用户数据报协议
User Datagram Protocol
UDP 也有头部,这个头部位于数据前面,信息之一是端口号,每个想访问网络的程序都要向操作系统申请一个端口号.
当一个数据包到达时,接收方的操作系统会读 UDP 头部,读里面的端口号
总结:
- IP 负责把数据包送到正确的计算机
- UDP 负责把数据包送到正确的程序
UDP 头部里还有”校验和”,用于检查数据是否正确
把数据包的二进制求和,算出来校验和,以 16 位形式存储 (就是16个0或1),超过了 16 位能表示的最大值高位数会被扔掉,保留低位
当接收方电脑收到这个数据包,它会重复这个步骤把所有数据加在一起,进行校验
如果不一致,也许传输时碰到了功率波动,或电缆出故障了,不幸的是,UDP 不提供数据修复或数据重发的机制,接收方知道数据损坏后,一般只是扔掉;发送方发了之后,无法知道数据包是否到达目的地
因为 UDP 又简单又快,语音和视频,游戏软件可以接受缺点,享受优点
TCP - 传输控制协议
Transmission Control Protocol
TCP 和 UDP 一样,头部也在存数据前面,因此,人们叫这个组合 TCP/IP,就像 UDP ,TCP 头部也有”端口号”和”校验和”
但 TCP 有更高级的功能:
- TCP 数据包有序号
- 序号使接收方可以把数据包排成正确顺序
- 即使到达时间不同.哪怕到达顺序是乱的,TCP 协议也能把顺序排对
- TCP 要求接收方的电脑收到数据包,并且”校验和”检查无误后(数据没有损坏),给发送方发一个确认码,代表收到了
- “确认码” 简称 ACK,得知上一个数据包成功抵达后,发送方会发下一个数据包
- 假设这次发出去之后,没收到确认码,那么肯定哪里错了
- 如果过了一定时间还没收到确认码 ,发送方会再发一次,如果收到重复的数据包就删掉
- 确认码延误了很久,或传输中丢失了,再次发送,因为收件方有序列号
- TCP 不是只能一个包一个包发,可以同时发多个数据包,收多个确认码,这大大增加了效率,不用浪费事件等确认码
- 确认码的成功率和来回时间,可以推测网络的拥堵程度,TCP 用这个信息,调整同时发包数量,解决拥堵问题
- 优点:TCP 可以处理乱序和丢失数据包,丢了就重发,还可以根据拥挤情况自动调整传输率
- 缺点:那些”确认码”数据包把数量翻了一倍,浪费性能
DNS - 域名系统
Domain Name System
互联网有个特殊服务,负责把域名和 IP 地址一一对应
在浏览器里输 youtube.com ,浏览器会去问 DNS 服务器,它的 IP 地址是多少,一般 DNS 服务器是互联网供应商提供的
DNS 会查表,如果域名存在,就返回对应 IP 地址,然后浏览器会给这个IP地址发 TCP 请求
找不到返回DNS错误
DNS 不是存成一个超长超长的列表,而是存成树状结构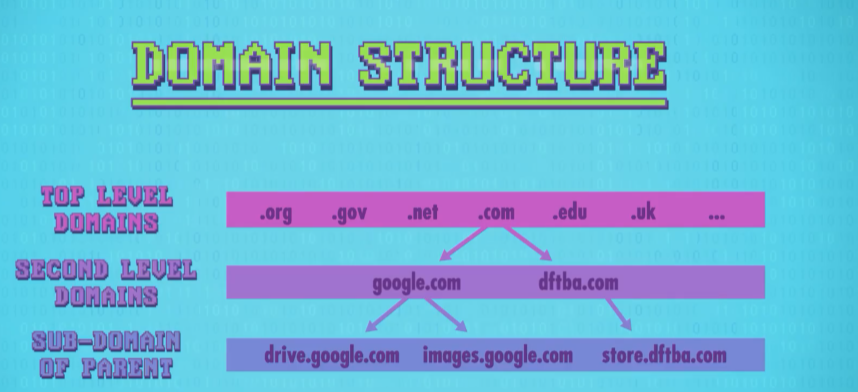
OSI - 开放式系统互联通信参考模型
抽象使得科学家和工程师能分工同时改进多个层,不被整体复杂度难倒.
Open System Interconnection
物理层:线路里的电信号,以及无线网络里的无线信号
数据链路层:负责操控”物理层”,媒体访问控制地址(MAC),碰撞检测,指数退避,以及其他一些底层协议
网络层:负责各种报文交换和路由
传输层:UDP TCP负责在计算机之间进行点到点的传输
会话层:使用 TCP 和 UDP 来创建连接,传递信息,然后关掉连接,查询 DNS 或看网页时,就会发生这一套流程
表示层:
应用程序层:30.万维网,
概念
互联网
电线 信号 交换机 数据包 路由器以及协议,它们共同组成了互联网
万维网
万维网在互联网之上运行,互联网是传递数据的管道,各种程序都会用,其中传输最多数据的程序是万维网,分布在全球数百万个服务器上,可以用”浏览器”来访问万维网
万维网的最基本单位,是单个页面
页面有内容,也有去往其他页面的链接,这些链接叫”超链接“hyperlinks /hypertext
统一资源定位器
Uniform Resource Locator
为了使网页能相互连接,每个网页需要一个唯一的地址
HTTP - 超文本传输协议
HyperText Transfer Protocol
举例:访问thecrashcourse.com/courses的顺序
- DNS查找
- 浏览器会打开一个 TCP 连接到这个 IP 地址
- 网络服务器的标准端口是 80 端口
- 服务器请求”courses”这个页面,向服务器发送指令:”GET /courses”
- 服务器会返回该地址对应的网页,然后浏览器会渲染到屏幕上;HTTP添加了状态码
- 高级的还有返回css,js
HTML - 超文本标记语言
HyperText Markup Language
写一个简单网页,用到了
- 标签
诞生了很多服务器和浏览器
Apache ,微软互联网信息服务(IIS)
不断诞生新的网站
搜索引擎
第一代:人工编辑的目录
第二代:
- 爬虫,一个跟着链接到处跑的软件,每当看到新链接,就加进自己的列表里
- 不断扩张的索引,记录访问过的网页上,出现过哪些词
- 查询索引的搜索算法
现代:
主要改进了搜索算法:与其信任网页上的内容不如看其他网站有没有链接到这个网站
网络中立性
应该平等对待所有数据包,不论这个数据包是我的邮件,或者是你在看视频,速度和优先级应该是一样的
但很多公司会乐意让它们的数据优先到达
有的公司既是大型互联网服务提供商又是多家电视频道,有可能让自己的内容优先到达并且节流其他线上视频
节流(Throttled) 意思是故意给更少带宽和更低优先级
诞生了很多服务器和浏览器
Apache ,微软互联网信息服务(IIS)
不断诞生新的网站
搜索引擎
第一代:人工编辑的目录
第二代:
- 爬虫,一个跟着链接到处跑的软件,每当看到新链接,就加进自己的列表里
- 不断扩张的索引,记录访问过的网页上,出现过哪些词
- 查询索引的搜索算法
现代:
主要改进了搜索算法:与其信任网页上的内容不如看其他网站有没有链接到这个网站
网络中立性
应该平等对待所有数据包,不论这个数据包是我的邮件,或者是你在看视频,速度和优先级应该是一样的
但很多公司会乐意让它们的数据优先到达
有的公司既是大型互联网服务提供商又是多家电视频道,有可能让自己的内容优先到达并且节流其他线上视频
节流(Throttled) 意思是故意给更少带宽和更低优先级

若有收获,就点个赞吧
0 人点赞
