数据库三大范式是否遵守
- 每一列字段应该不可再分,职责单一
- 要有主键,最好是与业务无关的自增id
- 不要有冗余字段,为了避免数据更新不一致,应该拆成两张表,用(逻辑)外键关联
- 但不论范式化设计还是反范式化设计,都不能过度:
- 完全遵守第三范式,有时会让查询变得非常麻烦,要么JOIN,要么内存中排序,有时甚至单表根本无法完成
打破第三范式后,需要主动维护冗余数据,一不小心可能导致数据不一致
数据类型,字段类型怎么选
整数类型
- 如果业务允许,尽量设置unsigned,去除符号,范围翻倍
- int(11)里的11和占用字节大小无关
- 注意各个类型的选取标准
- 定长,没有国家/地区之分,没有字符集的差异 | 数据类型 | 占据空间 | 范围(有符号) | 范围(无符号) | 描述 | | —- | —- | —- | —- | —- | | tinyint | 1 个字节 | -2^7 ~ 2^7-1 | 0 - 255 | 小整数值 | | smallint | 2 个字节 | -2^15 ~ 2^15-1 | 0 - 65535 | 大整数值 | | mediumint | 3 个字节 | -2^23 ~ 2^23-1 | 0 - 16777215 | 大整数值 | | int | 4 个字节 | -2^31 ~ 2^31-1 | 0 - 4294967295 | 大整数值 | | bigint | 8 个字节 | -2^63 ~ 2^63-1 | 0 - 18446744073709551615 | 极大整数值 |
字符类型
括号里面的数字是多少,就代表是几个字符
mysql5.0以后,代表几个字符
而字符和字节的换算,则与编码方式有关,不同的字符所占的字节是不同的。:
- ASCII码:
一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。如一个ASCII码就是一个字节。 - UTF-8编码:
一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。 - Unicode编码:
一个英文等于两个字节,一个中文(含繁体)等于两个字节。
- 字符类型的数字和实际大小有关,准确地说这里的数值和实际存储大小的上限有关。比如char(3),表示会固定占用3个字符空间,即使存储的值不够3个字符,照样会占着那块空间,但不能超过3个字符:
- char->定长
- 读写效率高于varchar,适合存储长度固定、频繁读写的数据
- 定长, 考虑字符集和(排序)校对集
- vachar->变长
- 通过varchar(10)的方式指定上限,适合存储长度波动、更新不频繁的数据
- varchar则需要浪费1~2个字节来存储当前值的实际长度,且更新会导致重新计算
- 不定长 要考虑字符集的转换与排序时的校对集,速度慢
- text/blob
时间类型
| 数据类型 | 占据空间 | 取值范围 |
|---|---|---|
| date | 3个字节 | 1000-01-01 ~ 9999-12-31 |
| time | 3~6个字节 | -838:59:59 ~ 838:59:59 |
| datetime | 5~8个字节 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| timestamp | 4~7个字节 | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 |
关于mysql存储时间的大佬建议
All date and time columns shall be INT UNSIGNED NOT NULL, and shall store a Unix timestamp in UTC.
类型总结
优先级
整型 > date,time > enum,char>varchar > blob
用的少的:
time定长,运算快,节省空间. 考虑时区,写sql时不方便 where > ‘2005-10-12’;
enum: 能起来约束值的目的, 内部用整型来存储,但与char联查时,内部要经历串与值的转化
尽量避免用NULL
原因: NULL不利于索引,要用特殊的字节来标注.
在磁盘上占据的空间其实更大
够用就行,不要慷慨
(如smallint,varchar(N)),大的字段浪费内存,影响速度
表设计
定长与变长分离
- 核心表存放int char这种定长的
varchar, text,blob,这种变长字段,适合单放一张表, 用主键与核心表关联起来
常用字段和不常用字段要分离
合理添加冗余字段
主要用的索引
索引类型
normal:普通索引
unique:唯一索引
FullText:全文检索,一般不用索引实现方式
99%用btree
特别注意,这里虽然写的是”BTREE”,但MySQL确实使用的是B+Tree
几种错误用法
在where条件常用的列上都加上索引(正确做法,联合索引)
在多列上建立索引后,查询哪个列,索引都将发挥作用(正确做法:左前缀原则)
索引题目
假设某个表有一个联合索引(c1,c2,c3,c4)一下——只能使用该联合索引的c1,c2,c3部分
A where c1=x and c2=x and c4>x and c3=x
B where c1=x and c2=x and c4=x order by c3
C where c1=x and c4= x group by c3,c2
D where c1=x and c5=x order by c2,c3
E where c1=x and c2=x and c5=? order by c2,c3
分析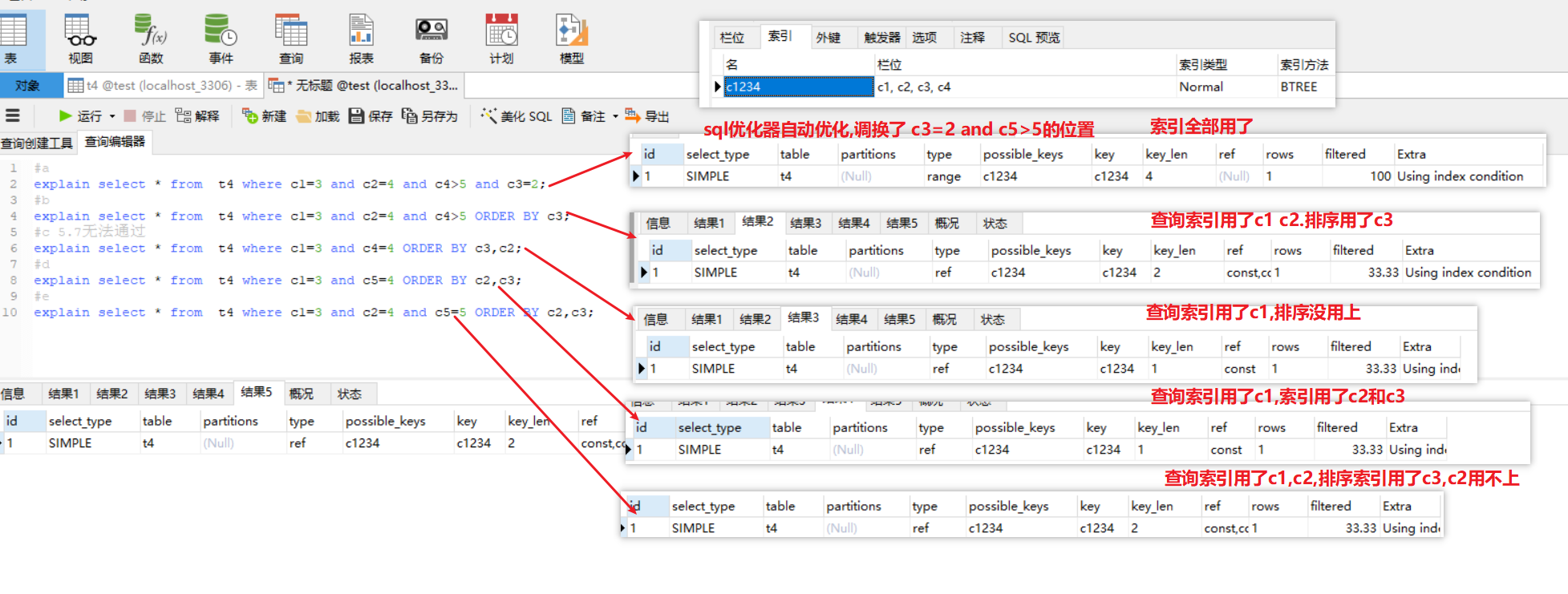
1%用Hash索引
理论查询时间复杂度为O(1)
- hash函数计算后的结果,是随机的,如果是在磁盘上放置数据
- 比主键为id为例, 那么随着id的增长, id对应的行,在磁盘上随机放置
- 不法对范围查询进行优化
- 无法利用前缀索引
- 比如在btree中, field列的值“helloworld”,并加索引查询xx=helloword,自然可以利用索引, xx=hello,也可以利用索引(左前缀索引)
- hash(‘helloword’),和hash(‘hello’),两者的关系仍为随机
- 排序也无法优化
- 必须回行.就是说 通过索引拿到数据位置,必须回到表中取数据
hash索引的优劣势
- 优势:速度非常快,只需一次计算即可得到地址,时间复杂度O(1),而B+树是O(logn)
-
聚簇索引与非聚簇索引
聚簇索引
innoDB采用聚簇索引
主键索引 既存储索引值,又在叶子中存储行的数据
如果没有主键, 则会Unique key做主键
如果没有unique,则系统生成一个内部的rowid做主键.
像innodb中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为聚簇索引
辅助索引只存储索引列+主键,必要时进行“回表”操作
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势: 如果碰到不规则数据插入时,造成频繁的页分裂
如果插入的时候是乱序的,查询出来是有序的!为什么呢 主索引是有序的,索引上面就带着信息
可以理解成插入难,查询简单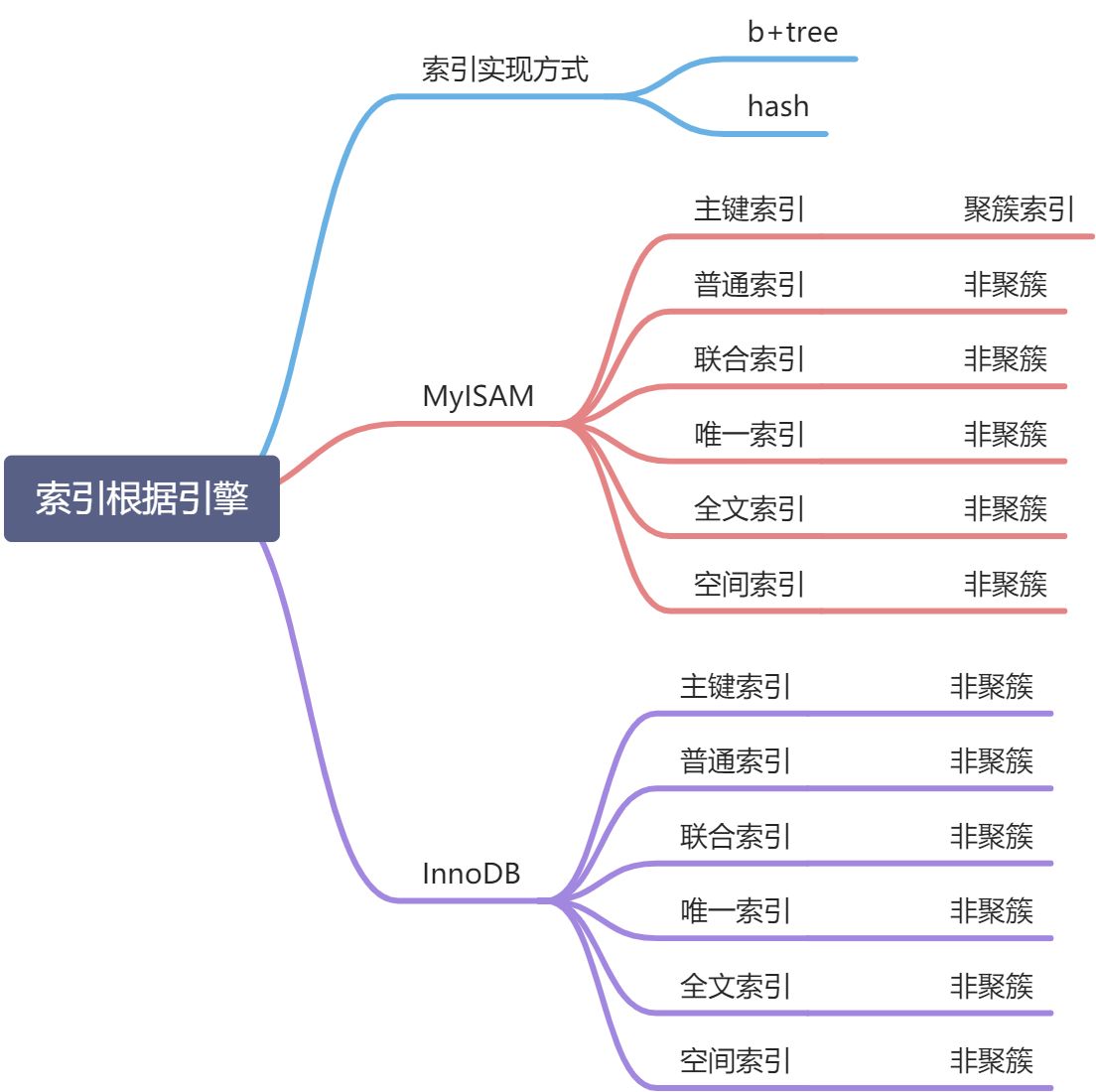
非聚簇索引
myisam采用非聚簇索引
索引树互相不关联
索引指向行在磁盘的位置
如果是乱序插入的,查询出来还是乱序的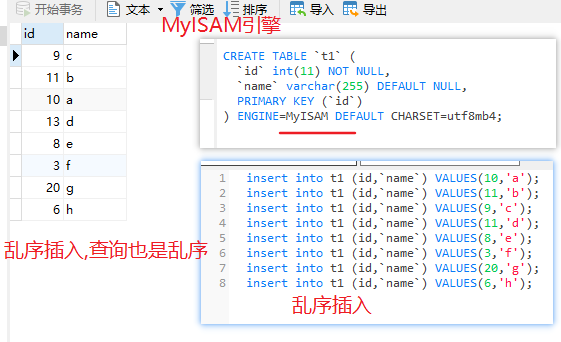
如果把引擎改成InnoDB,自动就变成有序的了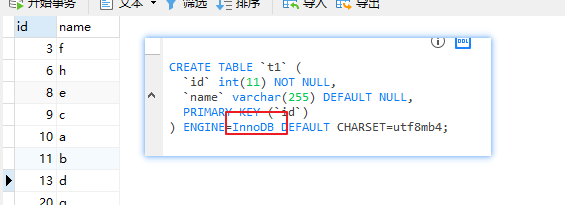
可以理解成插入简单,查询难总结
MyISAM:非聚簇索引,需要回表
- InnoDB:
- 聚簇索引:主键索引,叶子节点是表数据,不需要回表
- 非聚簇索引:辅助索引(唯一索引、普通索引),叶子节点是主键,必要时需要根据主键回表查询
索引覆盖
索引覆盖是指如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据.这种查询速度非常快
面试题为什么有索引了还是慢
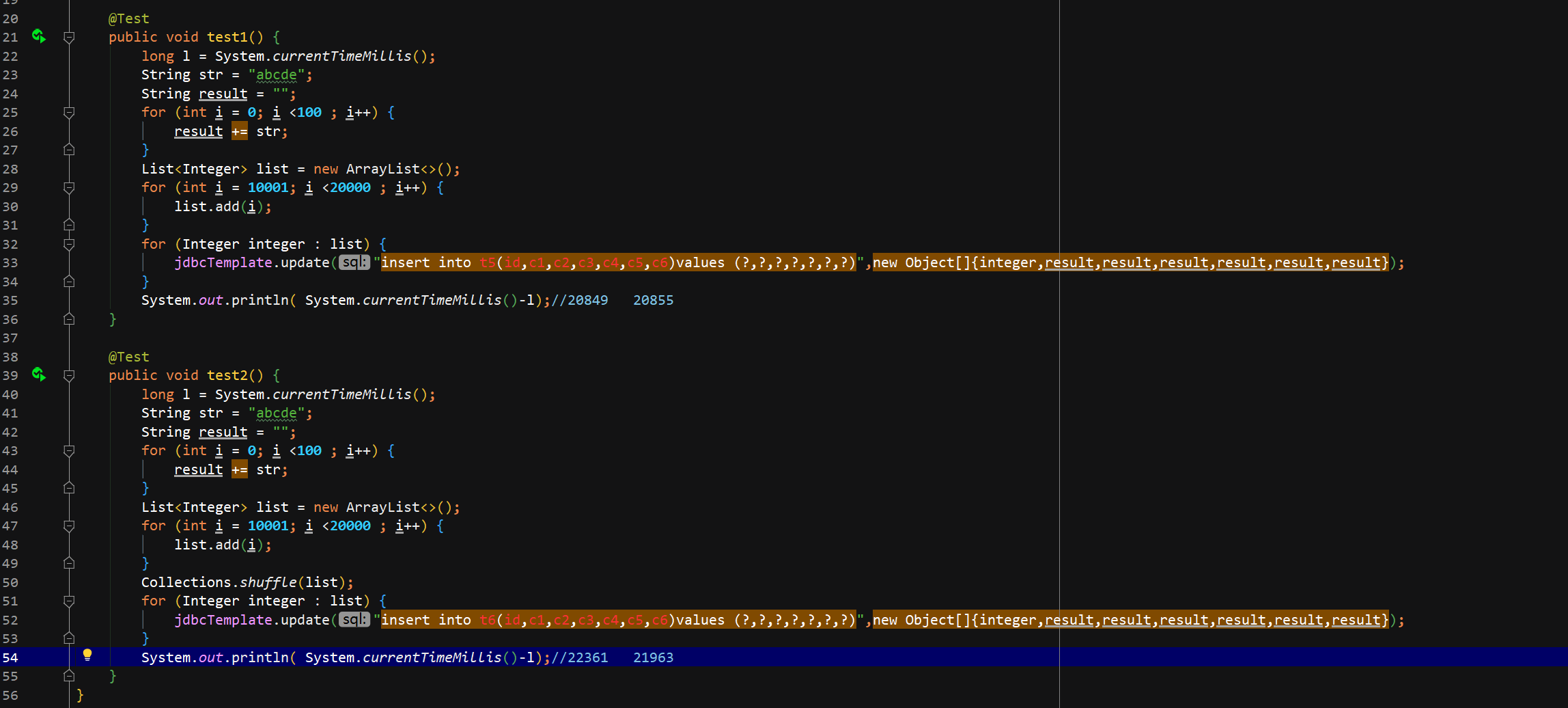
题目:一个表的id和ver加了索引,还有其他几个很大的字段
执行查询 select id from t8 order by id;很慢
执行查询 select id from t8 order by id,ver;很快
代码和sql模拟: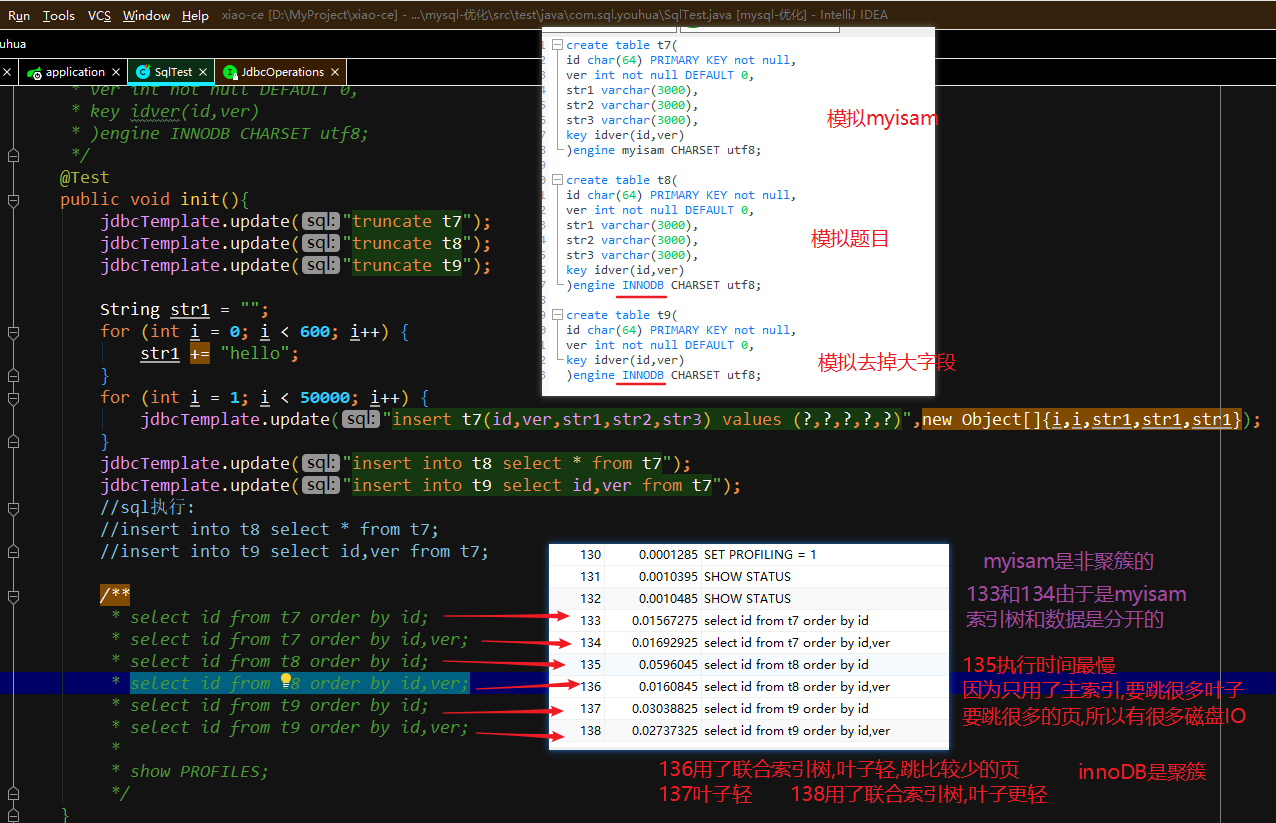
面试结论:
innoDB如果一行有很大的字段,哪怕加了索引查也很慢,这时候用联合索引和索引覆盖可以避开
当然最好还是不要把大的字段放在一个表里面
myisam如果有主键索引,根据主键排序和查询的话 可以无视其他很大的字段,因为索引和数据分开的(非聚簇)
理想的索引
- 查询频繁
- 区分度高
- 针对列中的值,从左往右截取部分,来建索引
截的越短, 重复度越高,区分度越小, 索引效果越不好
截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大—增删改变慢,并间影响查询速度.
- 长度小
- 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多).
-
奇怪的索引
crc32 伪哈希索引
倒序索引(网站url)
多列索引原则
要根据业务原则和日志积累,
可以有适当的冗余索引,a&b b&a 但是不要有重复索引 a&b&c a&b修复表
相当于磁盘碎片整理
比如: 表的引擎为innodb , 可以 alter table xxx engine innodb
optimize table 表名 ,也可以修复.
注意: 修复表的数据及索引碎片,就会把所有的数据文件重新整理一遍,使之对齐.
这个过程,如果表的行数比较大,也是非常耗费资源的操作.
所以,不能频繁的修复.
如果表的Update操作很频率,可以按周/月,来修复.
如果不频繁,可以更长的周期来做修复.sql优化
耗时部分:
查 ——> 沿着索引查,甚至全表扫描
取 ——> 查到行后,把数据取出来(sending data)
具体例子
categoryId和其下的商品
如果用left join 就会出现多次catId
可以分成2次查询,有的规定就是禁止多次join
sql语句的优化思路?
答: 不查, 通过业务逻辑来计算,
比如论坛的注册会员数,我们可以根据前3个月统计的每天注册数, 用程序来估算.
少查, 尽量精准数据,少取行. 我们观察新闻网站,评论内容等,一般一次性取列表 10-30条左右.
必须要查,尽量走在索引上查询行.
取时, 取尽量少的列.explain详解
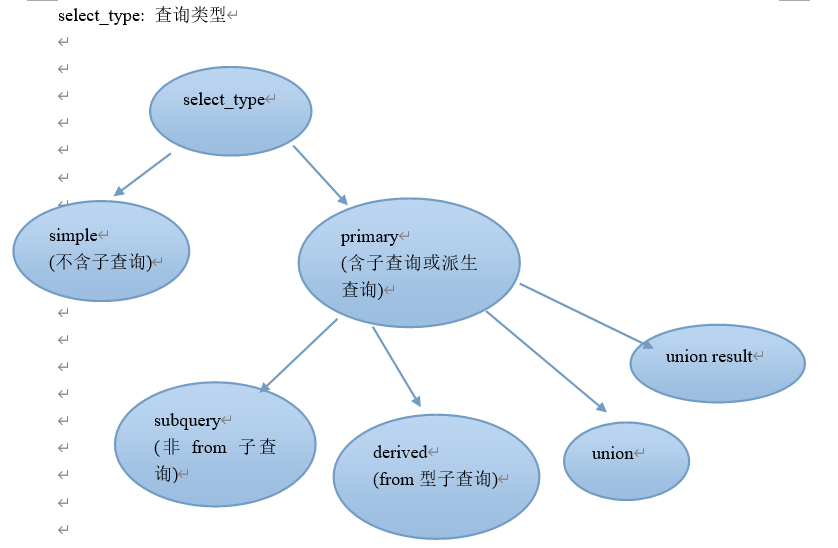
id
代表select 语句的编号, 如果是连接查询,表之间是平等关系, select 编号都是1,从1开始. 如果某select中有子查询,则编号递增
key
key_len
type
是指查询的方式, 非常重要,是分析”查数据过程”的重要依据
可能的值 all: 意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行
- 示例 无索引 where name=’张三’
- index: 比all性能稍好一点,
- 通俗的说: all 扫描所有的数据行,相当于data_all index 扫描所有的索引节点,相当于index_all
- 示例1:查询的列 索引覆盖了,但是where条件有函数计算
- 示例2:查询的列 索引覆盖了,用索引排序了,但是取出全部
- range: 意思是查询时,能根据索引做范围的扫描
- where id>10086
- ref通过索引列,可以直接引用到某些数据行
- where cid=10
- const, system, null这3个分别指查询优化到常量级别,甚至不需要查找时间.
- 一般按照主键来查询时,易出现const,system
- 或者直接查询某个表达式,不经过表时, 出现NULL
ref
指连接查询时, 表之间的字段引用关系rows
是指估计要扫描多少行extra
index: 是指用到了索引覆盖,效率非常高
using where 是指光靠索引定位不了,还得where判断一下
using temporary 是指用上了临时表, group by 与order by 不同列时,或group by ,order by 别的表的列.
using filesort : 文件排序(文件可能在磁盘,也可能在内存), 有个命令可以看在磁盘用了文件排序(炸了)text等大字段in 型子查询引出的陷阱
在ecshop商城表中,查询6号栏目的商品, (注,6号是一个大栏目)
最直观的: mysql> select goods_id,cat_id,goods_name from goods where cat_id in (select
cat_id from ecs_category where parent_id=6);
误区: 给我们的感觉是, 先查到内层的6号栏目的子栏目,如7,8,9,11
然后外层, cat_id in (7,8,9,11)
事实: 如下图, goods表全扫描, 并逐行与category表对照,看parent_id=6是否成立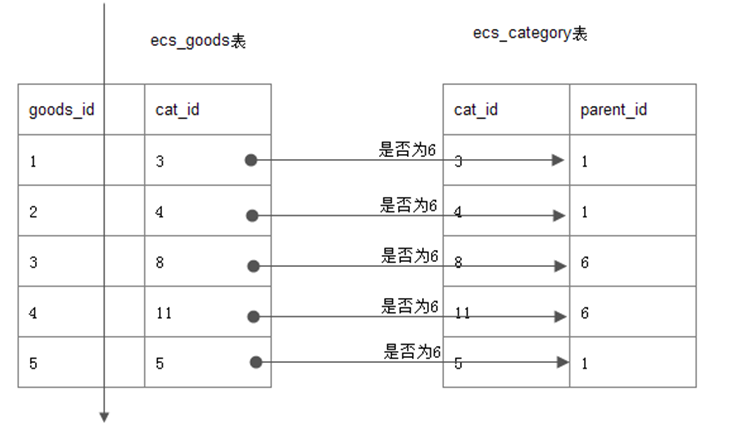
原因: mysql的查询优化器,针对In型做优化,被改成了exists的执行效果.
当goods表越大时, 查询速度越慢.
改进: 用连接查询来代替子查询
explain select goods_id,g.cat_id,g.goods_name from goods as g
inner join (select cat_id from ecs_category where parent_id=6) as t
using(cat_id) \G非常用的技巧
exist子查询
跟in的类似理解from子查询
注意::内层from语句查到的临时表, 是没有索引的.
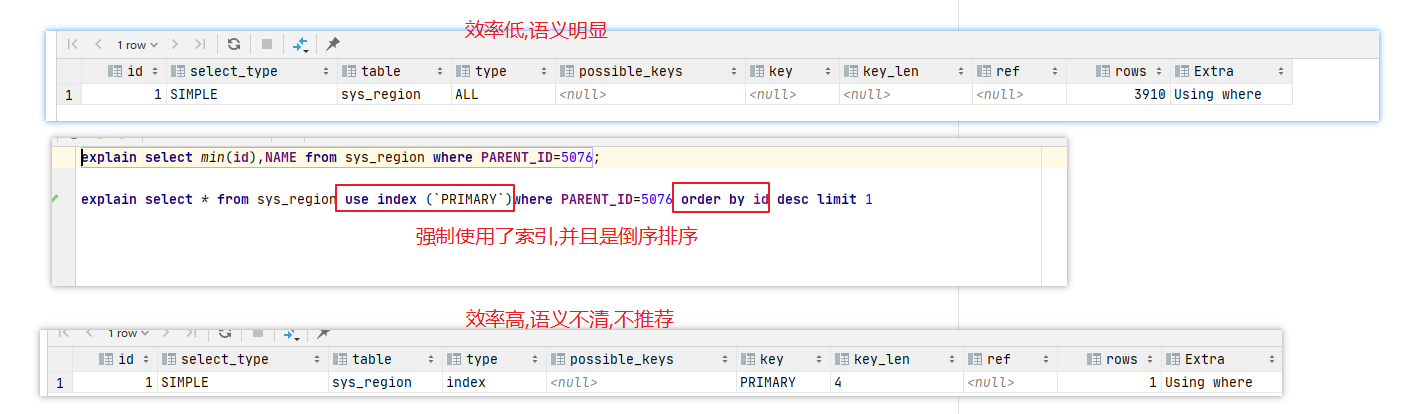
所以: from的返回内容要尽量少.强制使用索引
count() 优化
误区:
1:myisam的count()非常快
答: 是比较快,.但仅限于查询表的”所有行”比较快, 因为Myisam对行数进行了存储.
一旦有条件的查询, 速度就不再快了.尤其是where条件的列上没有索引.
2: 假如,id<100的商家都是我们内部测试的,我们想查查真实的商家有多少?
select count() from lx_com where id>=100; (1000多万行用了6.X秒)
小技巧:
select count() from lx_com; 快
select count() from lx_com where id<100; 快
select count() frol lx_com -select count() from lx_com where id<100; 快
select (select count() from lx_com) - (select count(*) from lx_com where id<100)

group by
注意:
1:分组用于统计,而不用于筛选数据.
比如: 统计平均分,最高分,适合, 但用于筛选重复数据,则不适合.
以及用索引来避免临时表和文件排序
2: 以A,B表连接为例 ,主要查询A表的列,
那么 group by ,order by 的列尽量相同,而且列应该显示声明为A的列
union优化
总是产生临时表
注意: union all 不过滤 效率提高,如非必须,请用union all
因为 union去重的代价非常高, 放在程序里去重.
limit优化
limit offset,N, 当offset非常大时, 效率极低,
原因是mysql并不是跳过offset行,然后单取N行,
而是取offset+N行,返回放弃前offset行,返回N行.
效率较低,当offset越大时,效率越低
优化办法:
1: 从业务上去解决
办法: 不允许翻过100页
以百度为例,一般翻页到70页左右.
1:不用offset,用条件查询.
例:
mysql> select id,name from lx_com limit 5000000,10;
+————-+——————————————————————+
| id | name |
+————-+——————————————————————+
| 5554609 | 温泉县人民政府供暖中心 |
………………
| 5554618 | 温泉县邮政鸿盛公司 |
+————-+——————————————————————+
10 rows in set (5.33 sec)
mysql> select id,name from lx_com where id>5000000 limit 10;
+————-+————————————————————————————+
| id | name |
+————-+————————————————————————————+
| 5000001 | 南宁市嘉氏百货有限责任公司 |
……………..
| 5000002 | 南宁市友达电线电缆有限公司 |
+————-+————————————————————————————+
10 rows in set (0.00 sec)
问题: 2次的结果不一致
原因: 数据被物理删除过,有空洞.
解决: 数据不进行物理删除(可以逻辑删除).
最终在页面上显示数据时,逻辑删除的条目不显示即可.
(一般来说,大网站的数据都是不物理删除的,只做逻辑删除 ,比如 is_delete=1)
3: 非要物理删除,还要用offset精确查询,还不限制用户分页,怎么办?
分析: 优化思路是 不查,少查,查索引,少取.
我们现在必须要查,则只查索引,不查数据,得到id.
再用id去查具体条目. 这种技巧就是延迟索引.
mysql> select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id);

若有收获,就点个赞吧
0 人点赞
