- State快照容错
- 精准一次
- 允许和配置Checkpointing
- Checkpoints vs. Savepoints
State快照容错
快照记录输入队列中的偏移量和整个job graph的state。这些state是数据处理在当前点产生的。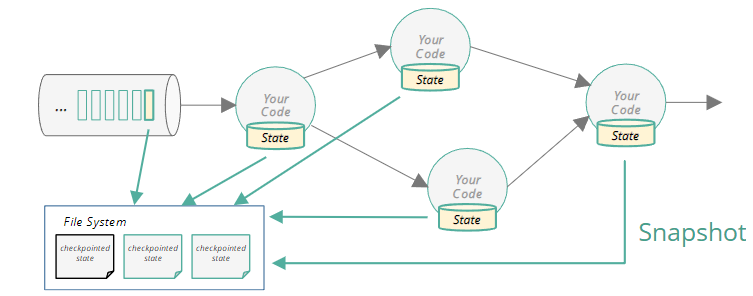
在runtime中,Flink 对作业状态进行一致的、分布式的、异步的快照。这些快照依赖于checkpoint barriers(快照屏障)。快照n的barrier被从源开始插入,并且一直贯穿到整个jobgraph。
当一个算子接收到所有输入的barrier n时,它会生成1个本地快照,然后把它存储在远端、持久化存储中。checkpoint是完整的,并且所有task完成了他们的备份。
Job 生周与容错性
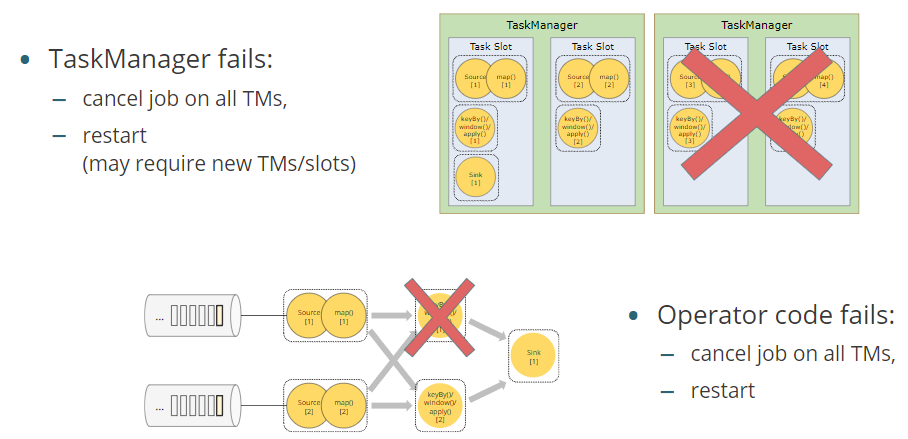
当TaskManager失败了,会根据restart strategy来进行重启。
当JobManager失败了,JobManager High Availability。TM会取消作业。依据配置情况,一个备用的或者新的JobManager。
如果用户代码中存在异常或者是 Flink 内部异常——job将失败,Flink 将取消该job,并根据选择的restart strategy重新启动它。
Recovery
- 重启所有的worker
- 恢复所有状态,包括输入流中的位置
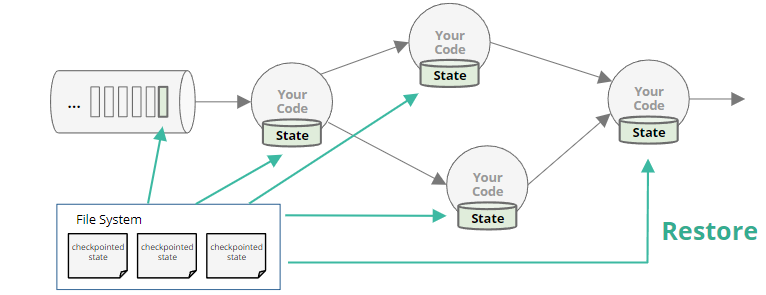
快照策略保证的结果是整个集群状态镜像全局一致性。这意味着通常不能只重启那一个失败的worker(假设只有一个worker失败),整个集群中的所有task都必须从snapshot中的state重置它们的状态。每个worker都以协调的方式一起回滚到输入流中相同的、较早的点。
容错保证
什么是精准一次?
假设一个worker挂了,会发生什么?会怎么影响Flink的状态?
Exactly-once checkpointing 对正在进行的流处理有一些影响。与at least once相比,可能表现为背压或延迟增加。
不同级别的故障恢复
- Deactivated checkpoints / None / At most once
- 如果checkpoint不活跃的话,故障时,所有的state会丢失。
- At least once
- 每个事件至少作用内部状态一次。
- 可回放的源将被倒带和回放,但是部分event可能会被计算2次
- Exactly once
- 每个事件只作用内部状态一次。
- 这并不意味着每个事件只被处理1次
- 相对于At least once,性能影响大一些
- 故障恢复涉及倒带和重放源,确实需要重新处理输入。能够保证的是,Flink 内部状态只作用一次(或至少一次,如果用户选择较弱的保证)
Exactly once: 端到端
前面我们只是单纯的讨论了flink的state是如何影响和作用的。现在来看看全局的。
- Exactly once: 结果是对的,但是sink端可能是重复发送结果的。注意,flink中的state仍然是准确的
- Exactly once end-to-end: 结果是对的,并且结果也是不重复的。类似于金额类计算,不能接受输出重复,必须采用端到端的精准一次策略。
Exactly once和at least once 都必须保证源端数据是可回放的。
end-to-end exactly once必须保证:
- sink端是支持事务的
或者写操作是幂等的
举个例子:Word Count
| 配置 | 如果有失败,会产生什么结果 |
|---|---|
| no checkpointing | 不正确的结果 |
| at-least-once | 没有单词会丢失,但是部分单词可能会被重复计数。 在故障恢复后,结果可能会被重复发送(2次发送的结果可能不一致) |
| exactly-once | 结果正确,但是恢复后可能会被重复发送 |
| exactly-once end-to-end | 结果正确,且只发送一次 |
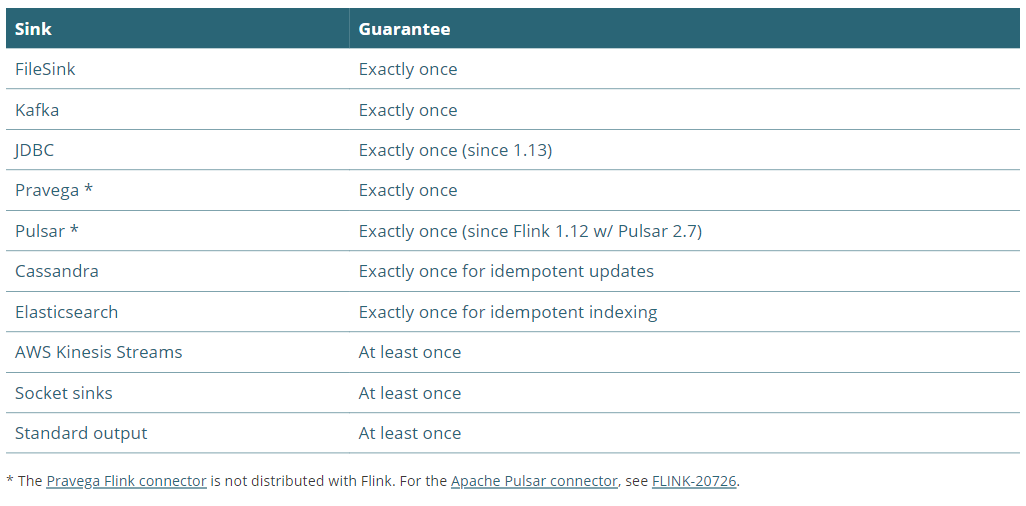
启用和配置checkpointing
- 可以在flink-conf.yaml或者用户代码中配置
里面有很多相关设置项,最重要的几个是:
JobManagerCheckpointStorage(开发测试环境,非生产)
- 默认存储在 JobManager的heap中
FileSystemCheckpointStorage(生产)
设置间隔
execution.checkpointing.interval: 10s
env.enableCheckpointing(10000L);
- 如何考虑设置间隔
- 集群在恢复过程中需要多长时间才能赶上
- 对于事务型sink的消费者而言,延迟体验
- 所涉及的运行时/内核开销
假设有一个近实时的应用,你已经设置你的checkpointing间隔相当长,类似20min。如果作业失败且需要恢复时,可能需要花费较长时间追赶到继续近实时状态,因为需要处理从最近一个checkpoint到现在为止的所有数据。
事务型sink,例如 Kafka 和 FileSink,仅提交事务作为checkpoint的一部分。因此,job输出的下游消费者将会感受到由job的checkpoint间隔控制产生的延迟。
Snapshots, Checkpoints, and Savepoints
- Snapshots是通用术语;Checkpoints和Savepoints都是快照的一种
- 广义上讲
- Checkpoints由Flink来管理,旨在保证容错性
- Savepoints由用户触发并无限期保留,旨在人工操作
- 但Checkpoints也可用于简单的重启和重新缩放
- 从增量checkpoints重新启动可能比从Savepoints重新启动要快得多
- checkpoints VS savepoints
- 存储到硬盘上的格式不同
- Checkpoints围绕快速恢复做了一些优化:采用state-backend-specific格式来写
- 因为对可靠性至关重要,Checkpoints完全由Flink来管理
- savepoints围绕着操作灵活性做了一些优化
- 总是全部快照
- 可以加载到任意状态后端

通过保留的checkpoint,用户可以看到这些checkpoint。这些可用于手动重启和重新缩放,就像savepoints用于这些活动一样。
包括状态类型改变的“变化拓扑图”需要进行状态迁移。
总结
- Flink可以提供(端到端的)精准一次语义保证。
- 这需要可回放的source和事务型sink
- 所有由Flink来管理的状态包括
- keyed state
- operator (non-keyed) state
- source offsets
- transaction IDs (in sinks)
- broadcast state
- timers

若有收获,就点个赞吧
0 人点赞
