先对齐下名称:
application,作业,应用
job,任务
部署模式
Session集群
- 在同一组资源上运行多个作业
- 在提交任何作业之前启动会话集群
优点:
- 快速启动作业,因为集群已预先部署
- 可能更好地利用资源
- 一个地方控制您的所有任务
缺点:
无隔离:多个作业运行在同一个 JVM 中
每个作业都有一个专用集群
好处:
- 严格的工作隔离
- 更可预测的资源消耗
- 可以调整每个作业的配置(一刀切的配置很少是正确的)
缺点:
- 工作启动时间相对更长
- 没有用于控制所有作业的集中式仪表板或 REST endpoint(就是job manager web ui)
- 如果为小型作业运行许多 JM,可能会浪费资源
Application集群
- 由一个应用程序的 main() 方法启动的所有job运行在一个专用集群。
- 将per-job模式的资源隔离与轻量级且可扩展的应用程序提交过程相结合
好处:
- main() 在Job Manager中运行
- 允许客户端或部署程序进程更加轻量级
- 依赖包可以预先上传到群集
- 更快的启动时间
- 可能有几个相关的job可以共享资源
缺点:
- 没有一个对所有应用的集中控制点
应用提交
传统模式:session & Per-job
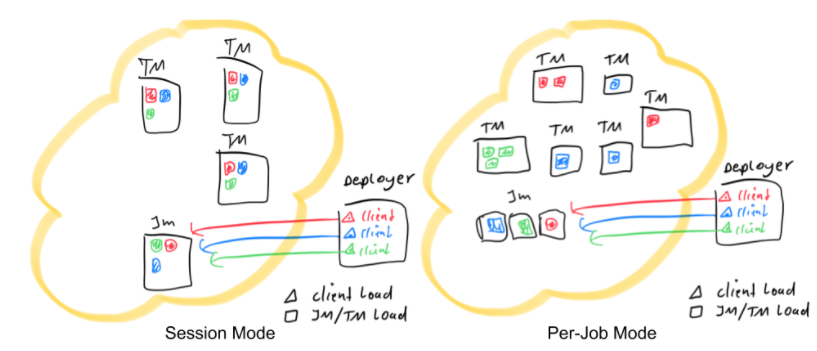
这里显示了 3 个应用(红色、蓝色和绿色),每个应用程序以并行度 3 运行。
Session模式中集群中只有一个JM,所有应用共用这一个JM;而Per-job模式中,每个应用有自己独立的JM。在Session模式中task被随机分配到任意一个TM上,而Per-job模式中一个TM中只会运行一个作业的task。在这两种模式下,部署提交的过程(提交节点)必须包含以下动作:
- 下载依赖包到本地
- 执行main() 来提取job graph
- 传输job graph和dependencies到集群上,用于执行
- 潜在地,等待结果响应
application模式
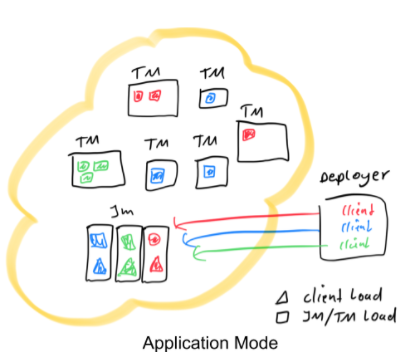
- main() 在JobManager中运行 (不是提交节点或者说客户端)
- main()可以创建不止一个任务
- env.execute() vs. env.executeAsync()
- Flink包和用户jar包可以在远端(remote,即hdfs上):
Deployer 无需花费 CPU 来提取job graph,也无需花费网络带宽在本地下载依赖项并将job graph及其依赖项发送到集群。相反,这个负担被转移到了每个应用程序的 JobManager 上。./bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \-Dtaskmanager.memory.process.size=4096m \-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \"hdfs://myhdfs/jars/MyApplication.jar"
使用阻塞的 execute() 方法建立一个顺序,并将导致“下一个”作业的执行被推迟到“这个”作业完成。相比之下,非阻塞的 executeAsync() 方法会在当前作业一提交就立即继续提交“下一个”作业。
运行main()构建逻辑图logic graph
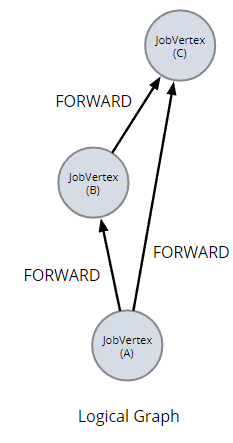
每个顶点(算子)都有一些属性,比如
- 并行性
- 要执行的代码
- 连接(图上的边)
- 逻辑图还有一组附加的 JAR 文件
现在深入研究一下,我们看到描述作业的图由一组作业顶点组成。每个 JobVertex 对应一个算子,具有一组属性,并产生一组结果。
我们将此版本的job graph称为logic graph。 该图是执行 Flink API 调用的结果。
JobManager: logical graph → physical graph
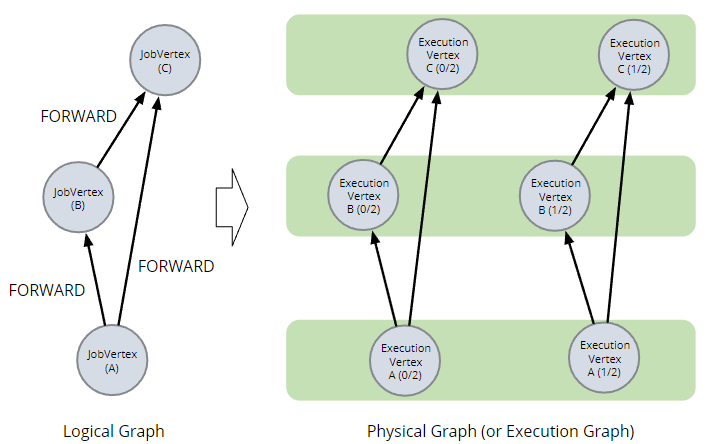
JobManager 获取此逻辑图并将其转换为物理图,有时也称为执行图。物理图是逻辑图的并行版本,可以调度和部署到TM。
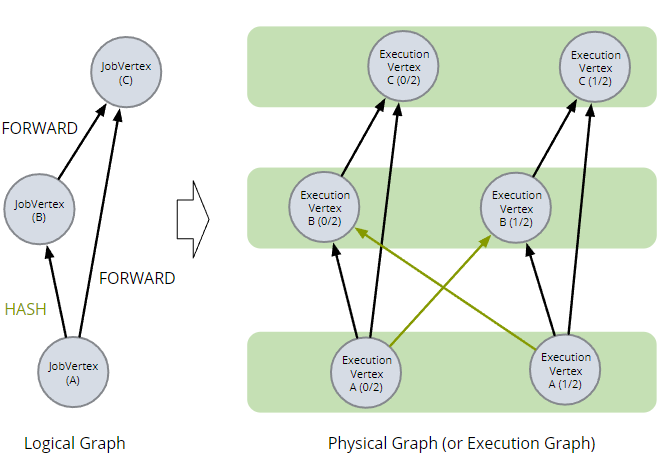
生成的物理图的拓扑受逻辑图中边连接更改的影响。例如,如果我们更改顶点 B 使其进行keyed操作,那么 A 和 B 之间的连接将必须是 HASH 连接而不是 FORWARD 连接,并且物理图将多两条边。
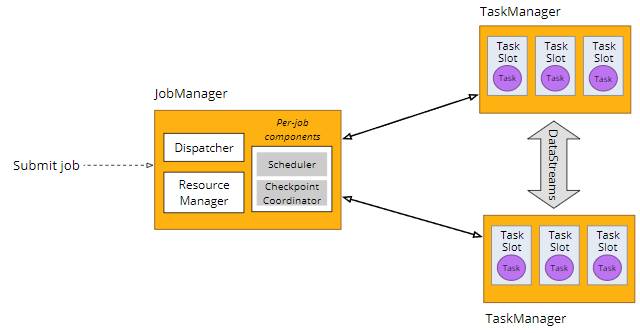
JobManager 将phsical graph分解为task。JobManager 请求并最终获得用于执行这些task的slot。JobManager 将task分配给slot。
JM 通过 Blob Server与 TM 共享信息
- Blob Server是 JobManager 的一个组件,用于存储与逻辑/物理图相关的永久关键信息以及更多临时数据。
- JAR files
- large deployment RPC messages
- log files for the Web UI
- 使用 HA 服务(如果存在)存储非瞬态 blob
- 缓存 BLOB(基于 jobId 和 BlobKey)
决策在哪里提交作业
Local
在单个 JVM 中本地运行 Flink。方便测试和实验。
standalone
一个简单的解决方案,用于在裸机、VM 或使用 Docker 或 Kubernetes 的容器中运行 Flink 集群。
yarn
使用hadoop的资源管理器(yarn)来管理资源
k8s
使用 Kubernetes 的容器编排系统
配置你的集群
重要的配置参数
- JM和TM的内存
- TM卡槽数:taskmanager.numberOfTaskSlots — slots per TM
- 默认并行度:parallelism.default,对那些没有指定的job
- 状态后端:State backend
- RocksDB (如果用了的话)
- 检查点和保存点
- 指标监控者Metrics reporters
- 安全套接字层(SSL)
- 高可用(JM 故障转移)
说明:高可用性:我们在这里使用这个术语是因为它出现在 Flink 文档和配置选项的名称中。但这实际上只是指 Job Manager 故障转移。如果TM发生故障,无论您可能进行了何种“高可用性”配置,仍然会重新启动。
配置JM memory
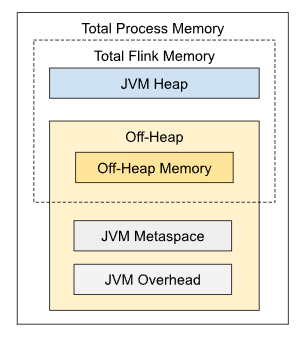
- 最简单的方法是设置:
- jobmanager.memory.process.size
- 其他的设置采用默认值/比例
- 但是你可以控制每个组件大小
- heap, off-heap, metaspace, overhead
- 详细参考
Flink 1.11相比之前的版本内存模型有大的变化,查阅相关文献时需要注意版本。
配置TM memory
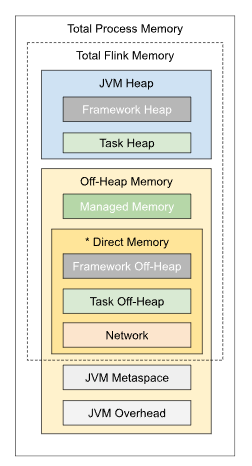
- 同JM的层次分布比较像
- 简单的设置
- taskmanager.memory.process.size
- 细粒度控制是可能的,可以关注:
- Task Heap
- 预留给用户代码的JVM堆空间
- Managed (Off-Heap) Memory 可以被用于
- streaming: RocksDB state backend
- batch: sorting, hash tables, caches
- Task Heap
- 详细参考
RocksDB 可能存在内存碎片问题,导致它使用的内存超出您的预期,从而导致 OOM 错误。在 Flink 1.12 中进行了更改以改进这一点,但 RocksDB 仍然可以超越其界限并且无法将自身限制在分配给它的内存中。
容器化部署
- Docker Hub 上有官方的 Apache Flink 镜像
- https://hub.docker.com/_/flink (官方Docker images)
- https://hub.docker.com/r/apache/flink (由 Flink社区发布)
- 这些镜像可以作为JM/TM运行
- 这些镜像很容易自定义
- 更改配置选项
- 提供你自己的配置文件
- 添加插件
- 安装自定义软件
- 为构建自定义 Docker 镜像,查看flink-docker
通常建议使用官方的 docker 镜像,但可能会出现延迟和其他问题阻止它们的发布,在这种情况下 apache/flink 镜像是一个很好的后备
K8s部署
使用 Kubernetes 进行容器编排.
- 声明式配置
- 告诉 K8s 想要的状态,一个后台进程让它发生
- 此容器的 3 个副本应保持运行
- 应该存在一个负载均衡器,侦听端口 443,由具有此标签的容器支持
- 告诉 K8s 想要的状态,一个后台进程让它发生
- 基本的资源类型
- Pod:一组容器(1个或多个)
- Job:保持pod(s) 运行,直到结束
- Deployment:保持n pods无限期运行
- Service:由一组 pod 支持的REST对象
- Persistent Volume Claim:生命周期不与任何一个pod耦合的存储
对于JM,您可以使用围绕 k8s job包装的 k8s service。这是合理的,因为只要 Flink 作业正在运行,JM就应该继续运行——这可能是无限期的,或者它可能会在某个时候完全终止。
TM自然对应到k8s Deployment。
可以用volume claim做checkpoint,高可用存储。
高可用
- TaskManager 失败由 JobManager 解决
- JobManager 故障由以下任一方式解决:
- 运行备用 JobManagers(依靠 ZooKeeper 进行领导者选举),或者
- 集群管理框架,例如 Yarn 或 K8s
高可用服务提供者
管理有关必须在 JM 重新启动/故障转移后幸存下来的作业和检查点的元数据
- Apache Flink 包含两种实现
- 任何人都可以使用的基于 ZooKeeper 的实现,包括在yarn/k8s
- Flink 1.12 中添加了基于 ConfigMap 对象的 Kubernetes 替代方案
或者你可以实现自定义HighAvailabilityServicesFactory
更多学习资源
Flink Forward Video
- blog
- Docs

若有收获,就点个赞吧
0 人点赞
