本节主要讲解:
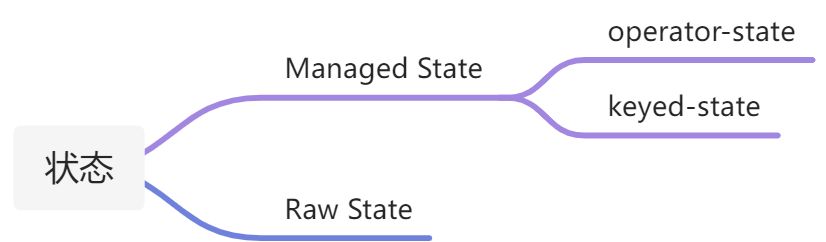
- Flink 用于处理内置、keyed状态的 API(managed, keyed state)
- 如何将流连接在一起,并让它们共享状态
托管状态managed state
- 本地、快速:在内存里或本地磁盘上
- 持久化:checkpoints机制
- 垂直可扩展:RocksDB
- 水平可扩展(可重复可分配):keyspace是按照集群来分片的
- 可查询:可查询的state API
举个简单的例子:想在处理每个用户第一次事件消息时,做一些特别的事情。这显然需要一些状态。首先想到的可能是可以把这个状态保存在一个局部变量中。
但是我们在这里处理的是分布式系统,随着系统的扩展,出现故障的可能性越来越大。 但是即使你假设你的应用程序永远不会失败,那么重新部署呢? 我们仍然需要一些方法来进行快照和恢复状态。
此外,在集群中,每个节点需要为在该节点上处理的users维护一个状态的key/value的map。当集群扩容或缩容时,也需要通过某种方式来重新分布状态。
分布式有状态流处理
- 所有 DataStream 函数都可以是有状态的,filter, map, flatMap, etc
- 对于keyed streams,计算和状态通过相同的key进行分区
- 所有状态是本地化的
- 状态可以是基于堆内内存的,也可以是堆外内存,本地磁盘支持的存储中。
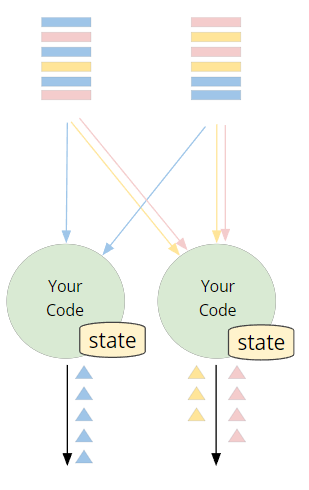
在上一节介绍keyBy的时候,贴过这张图。keyBy 与有状态的流处理一起工作。 例如,想要实现第一次看到新用户时,触发特殊操作的场景。
只有当我们保证每个特定用户的所有event都由同一个算子来处理,我们才能实现这个功能。即:
- 一个用户的所有数据均由同一个单节点来处理
-
Rich Functions
前面我们介绍的都是一些基础functional interfaces,比如filter, map, flatMap。他们的特点是:
单个抽象方法(SAM)
- 支持Java8 lambda表达式
这些函数接口都有一些变形,叫做rich functions。这些rich functions可以支持状态服务。例如
- e.g., RichFlatMapFunction
- 他们有一些额外的函数
- open()
- close()
- getRuntimeContext()
Runtime context
运行时上下文是访问有关作业运行环境的各种有趣信息的门户。当下,我们聚焦于它让我们能够访问状态后端(state backend),这是 Flink 托管状态的存储位置。
Runtime context
- getIndexOfThisSubtask()
- getNumberOfParallelSubtasks()
- getExecutionConfig()
Provides access to key-partitioned state via getState()
Managed, Key-partitioned State
举例:去重
对流去重,仅保留每个key的第一条
private static class Event {public final String key;public final long timestamp;...}public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.addSource(new EventSource()).keyBy(e -> e.key).flatMap(new Deduplicate()).print();env.execute();}public static class Deduplicate extends RichFlatMapFunction<Event, Event> {ValueState<Boolean> seen;@Overridepublic void open(Configuration conf) {ValueStateDescriptor<Boolean> desc = new ValueStateDescriptor<>("seen", Types.BOOLEAN);seen = getRuntimeContext().getState(desc);}@Overridepublic void flatMap(Event event, Collector<Event> out) throws Exception {if (seen.value() == null) {out.collect(event);seen.update(true);}}}
为了设置Flink的内置状态,我们需要:
- 使用一种Rich function
- 创建StateDescriptor,描述我们想要存储的数据
- 绑定本地定义的state变量到由Flink提供和维护的state上
open()在初始化过程中被调用,在这个函数开始处理任何event之前。
我们的信息被打包成一种特定的Flink数据类型,在上面代码示例中是ValueState。ValueState是一种keyed state,意味着Flink为每个单独的key存储一个Boolean值。
这个算子的每个并行实例都会存储该实例维护keys的state。这是一种分片key-value存储。
我们再来看下flatMap内的业务逻辑。对于当前处理的event而言,我们需要看下之前有没有处理过相同的key。要检索状态值,我们调用 .value() 方法。这里有一个容易产生疑惑的地方,当我们调用state的value()和update()方法时,并没有指定是哪个key。在框架调用flatMap() 方法之前,已经自动精准定位到state中当前正在处理的 event的key。
TODO
这里并没有打平操作,为什么要用flatMap,用filter行不行?
经测试结果flatMap,filter都行。
最后再重申一下:Flink 会为应用管理状态,这意味着它将是容错的,并且可以在单个实例的崩溃时自动恢复。
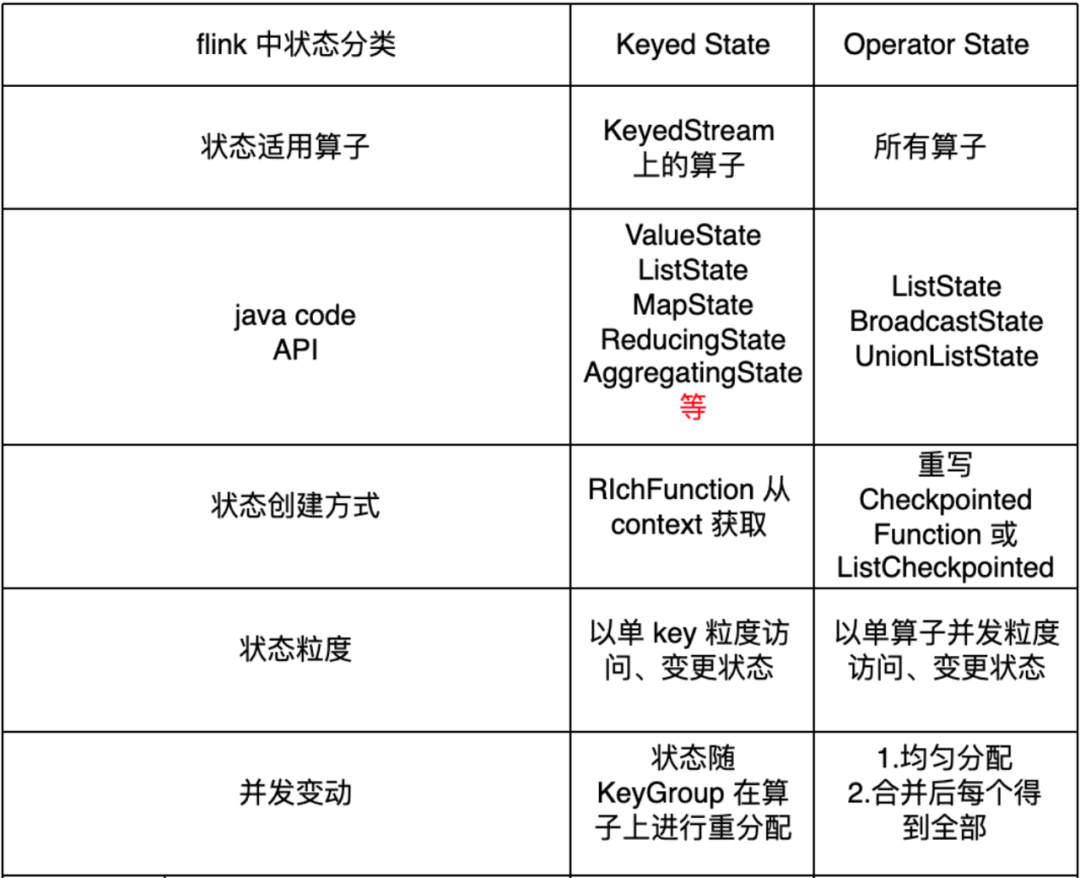
keyed state的类型
- ValueState
- 最简单最通用的state类型
- ListState
- 使用ListState
而不是ValueState
- 使用ListState
- MapState
- 使用MapState
- MapState同样可以由key精准限定,这是一个嵌套Map
- 此类型非常有用,例如,如果我们想为KeyedStream中每个key存储一个开放式属性Hash。
- 另一种常见的模式,在处理乱序事件时间数据时,是使用 MapState 来存储不同时间点的数据。在这些场景中,MapState 条目是一个时间戳,与该时间点相关的数据组成一对。TODO关于这点我们后面在介绍窗口运算函数实现时会再仔细说明。
- 当我们用RocksDB存储时,MapState
- 使用MapState
- ReducingState
- reduce(…)内部使用
AggregatingState
在ProcessFunction中可以使用Timers来清理状态(后面会有实例)
- StateTtlConfig 可用于配置 Flink 何时应自动清除状态
- 通过state descriptor指定
- 通过processing time指定
- 通过最新一次读/写的时间来清理状态
ps:在Flink社区讨论过指定事件时间中的状态保留间隔,但尚未积极开发(截至 2019 年 6 月)
Connected Streams
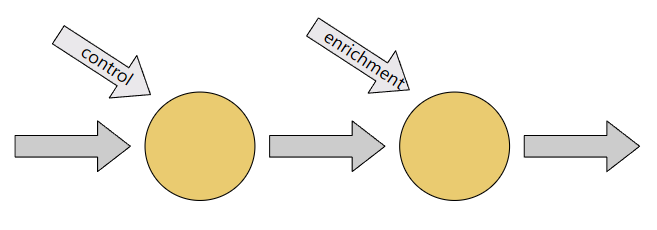
- 连接两个流以一起处理它们
- 已连接流可以共享状态
- 因为两个流共享state是keyed,所以两个keyedStream必须基于同一个key。如果一个stream的key是user_id,另外一个的key是account_id,则没有意义。
场景举例:假设我们有一个上游系统流动态(control stream)的告诉我们哪些值是需要从数据流(data stream)中过滤掉的。
public class StreamingJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> control = env.fromElements("DROP", "IGNORE").keyBy(x -> x);DataStream<String> data = env.fromElements("Flink", "DROP", "Forward", "IGNORE").keyBy(x -> x);control.connect(data).flatMap(new ControlFunction()).print();env.execute();}}
注意,我们两个流都被keyed by 流记录本身,一个String。我们将这两个流关联起来,并且应用一个ControlFunction。
public static class ControlFunction extends RichCoFlatMapFunction<String, String, String> {private ValueState<Boolean> blocked;@Overridepublic void open(Configuration config) {blocked = getRuntimeContext().getState(new ValueStateDescriptor<>("blocked", Boolean.class));}@Overridepublic void flatMap1(String controlValue, Collector<String> out) throws Exception {blocked.update(Boolean.TRUE);}@Overridepublic void flatMap2(String dataValue, Collector<String> out) throws Exception {if (blocked.value() == null) {out.collect(dataValue);}}}
主要ControlFunction是对RichCoFlatMapFunction的扩展。Rich表示涉及state访问, Co表示这个function被应用到关联流本身。我们需要实现的是两个flatMap函数,分别对应两个需要关联的stream的event到达的处理。
当接收到控制流的事件,即我们应该过滤的单词时,我们只存储一个boolean flag到ValueState。两个流keyed by同一个key,即单词本身。这保证了当这个词到达data stream时,我们将访问这个相同的flag并且只通过没有被阻塞/过滤的词。
Attention
重要提示:这两个流可以相互竞争。因为这两个流中元素处理的时间是无法严格控制的。稍后将讨论 Flink 提供的一些机制,主要是保障处理顺序的确定性。
总结
- Flink的内置keyed state很像是分片的k-v存储
- state是使用它的处理算子所有的节点本地化存储的。
- state保存在状态后端(state backend),状态后端可以存储在JVM heap,也可以存储在硬盘
- Flink本身保障检查点、故障恢复、扩容/缩容
- Flink也管理一些non-keyed state,也叫operator state(算子状态)
- Non-keyed state很少用在应用代码中,大部分情况下,仅会在source和sink的实现中被使用。
- Broadcast state也是一种non-keyed state,常常在框架自身外面使用。TODO我们后面有介绍
- 避免使用带集合的ValueState,而是采用如下方式替代
- ListState
- MapState
- 具有两个输入流的算子可以在各自的回调函数中共享状态。

若有收获,就点个赞吧
0 人点赞
